Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Тема 6. Многопользовательский режим работы с БД. Модели «клиент-сервер» в системах баз данных. Архитектура серверов баз данныхСодержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
84. Может ли быть реализована модель «клиент-сервер» на одном компьютере? Приведите примеры. Да. Клиентский процесс запрашивал некоторые услуги, а серверный процесс обеспечивал их выполнение. При этом предполагалось, что один серверный процесс может обслужить множество клиентских процессов. 85. Где находится СУБД в модели «файл-сервер»?
Процессор управления данными (Database Manager System Processing) — это собственно СУБД, которая обеспечивает хранение и управление базами данных. В идеале функции СУБД должны быть скрыты от бизнес-логики приложения, однако для рассмотрения архитектуры приложения нам надо их выделить в отдельную часть приложения. В централизованной архитектуре (Host-based processing) эти части приложения располагаются в единой среде и комбинируются внутри одной исполняемой про граммы. В децентрализованной архитектуре эти задачи могут быть по-разному распределены между серверным и клиентским процессами. В зависимости от характера распределения можно выделить следующие модели распределений:
86. Каковы основные достоинства и недостатки модели «файл-сервер»?
Модель удаленного управления данными также называется моделью файлового сервера (File Server, FS). В этой модели презентационная логика и бизнес-логика располагаются на клиенте. На сервере располагаются файлы с данными и поддерживается доступ к файлам. Функции управления информационными ресурсами в этой модели находятся на клиенте. Достоинства этой модели в том, что мы уже имеем разделение монопольного приложения на два взаимодействующих процесса. При этом сервер (серверный процесс) может обслуживать множество клиентов, которые обращаются к нему с запросами. Собственно СУБД должна находиться в этой модели на клиенте. Каков алгоритм выполнения запроса клиента? Запрос клиента формулируется в командах ЯМД. СУБД переводит этот запрос в последовательность файловых команд. Каждая файловая команда вызывает перекачку блока информации на клиента, далее на клиенте СУБД анализирует полученную информацию, и если в полученном блоке не содержится ответа на запрос, то принимается решение о перекачке следующего блока информации и т. д. Перекачка информации с сервера на клиента производится до тех пор, пока не будет получен ответ на запрос клиента.
Недостатки этой модели: высокий сетевой трафик, который связан с передачей по сети множества блоков и файлов, необходимых приложению; узкий спектр операций манипулирования с данными, который определяется только файловыми командами; отсутствие адекватных средств безопасности доступа к данным (защита только на уровне файловой системы).
87. В какой из двух моделей RDA – модели или модели «файл-сервер» больше сетевой трафик и за счет чего?
См. пред пункт
88. Опишите работу модели удаленного доступа. Каковы достоинства и недостатки модели удаленного доступа?
В модели удаленного доступа (Remote Data Access, RDA) база данных хранится на сервере. На сервере же находится ядро СУБД. На клиенте располагается презентационная логика и бизнес-логика приложения. Клиент обращается к серверу с запросами на языке SQL. Структура модели удаленного доступа приведена на рис. 6.2.
Рис. 6.2. Модель удаленного доступа (RDA)
Преимущества данной модели: перенос компонента представления и прикладного компонента на клиентский компьютер существенно разгрузил сервер БД, сведя к минимуму общее число процессов в операционной системе; сервер БД освобождается от несвойственных ему функций; процессор или процессоры сервера целиком загружаются операциями обработки данных, запросов и транзакций (это становится возможным, если отказаться от терминалов, не располагающих ресурсами, и заменить их компьютерами, выполняющими роль клиентских станций, которые обладают собственными локальными вычислительными ресурсами); резко уменьшается загрузка сети, так как по ней от клиентов к серверу передаются не запросы на ввод-вывод в файловой терминологии, а запросы на SQL, и их объем существенно меньше. В ответ на запросы клиент получает только данные, релевантные запросу, а не блоки файлов, как в FS-модели. Основное достоинство RDA-модели — унификация интерфейса «клиент – сервер», стандартом при общении приложения- клиента и сервера становится язык SQL. Недостатки данной модели: все-таки запросы на языке SQL при интенсивной работе клиентских приложений могут существенно загрузить сеть; так как в этой модели на клиенте располагается и презентационная логика, и бизнес-логика приложения, то при повторении аналогичных функций в разных приложениях код соответствующей бизнес-логики должен быть повторен для каждого клиентского приложения — это вызывает излишнее дублирование кода приложений;
сервер в этой модели играет пассивную роль, поэтому функции управления информационными ресурсами должны выполняться на клиенте. Действительно, например, если нам необходимо выполнять контроль страховых запасов товаров на складе, то каждое приложение, которое связано с изменением состояния склада, после выполнения операций модификации данных, имитирующих продажу или удаление товара со склада, должно выполнять проверку на объем остатка, и в случае, если он меньше страхового запаса, формировать соответствующую заявку на поставку требуемого товара. Это усложняет клиентское приложение, с одной стороны, а с другой — может вызвать необоснованный заказ дополнительных товаров несколькими приложениями.
89. Опишите работу моделей пассивного и активного сервера баз данных. Что является признаком активного сервера баз данных? 90. Что такое триггер? Чем триггер отличается от хранимой процедуры? Как клиентское приложение может запустить триггер базы данных?
Для того чтобы избавиться от недостатков модели удаленного доступа, должны быть соблюдены следующие условия: Необходимо, чтобы БД в каждый момент отражала текущее состояние предметной области, которое определяется не только собственно данными, но и связями между объектами данных, т. е. данные, которые хранятся в БД, в каждый момент времени должны быть непротиворечивыми. БД должна отражать некоторые правила предметной области, законы, по которым она функционирует (business rules). Например, завод может нормально работать только в том случае, если на складе имеется некоторый достаточный запас (страховой запас) деталей определенной номенклатуры: деталь может быть запущена в производство только в том случае, если на складе имеется в наличии достаточно материала для ее изготовления, и т. д. Необходим постоянный контроль за состоянием БД, отслеживание всех изменений и адекватная реакция на них: например, при достижении некоторым измеряемым параметром критического значения должно произойти отключение определенной аппаратуры; при уменьшении товарного запаса ниже допустимой нормы должна быть сформирована заявка конкретному поставщику на поставку соответствующего товара. Необходимо, чтобы возникновение некоторой ситуации в БД четко и оперативно влияло на ход выполнения прикладной задачи. Одной из важнейших проблем СУБД является контроль типов данных. В настоящий момент СУБД контролирует синтаксически только стандартно-допустимые типы данных, т. е. такие, которые определены в DDL (data definition language) — языке описания данных, который является частью SQL. Однако в реальных предметных областях у нас действуют данные, которые несут в себе еще и семантическую составляющую, например координаты объектов или единицы различных метрик, так, рабочая неделя в отличие от реальной имеет сразу после пятницы понедельник. Данную модель поддерживают большинство современных СУБД: Informix, Ingres, Sybase, Oracle, MS SQL Server. Основу данной модели составляет механизм хранимых процедур как средство программирования SQL-сервера, механизм триггеров как механизм отслеживания текущего состояния информационного хранилища и механизм ограничений на пользовательские типы данных, который иногда называется механизмом поддержки доменной структуры. Модель сервера баз данных представлена на рис. 6.3.
Рис. 6.3. Модель активного сервера БД
В этой модели бизнес-логика разделена между клиентом и сервером. На сервере бизнес-логика реализована в виде хранимых процедур — специальных программных модулей, которые хранятся в БД и управляются непосредственно СУБД. Клиентское приложение обращается к серверу с командой запуска хранимой процедуры, а сервер выполняет эту процедуру и регистрирует все изменения в БД, которые в ней предусмотрены. Сервер возвращает клиенту данные, релевантные его запросу, которые требуются клиенту либо для вывода на экран, либо для выполнения части бизнес-логики, которая расположена на клиенте. Трафик обмена информацией между клиентом и сервером резко уменьшается. Централизованный контроль в модели сервера баз данных выполняется с использованием механизма триггеров. Триггеры также являются частью БД. Термин «триггер» взят из электроники и семантически очень точно характеризует механизм отслеживания специальных событий, которые связаны с состоянием БД. Триггер в БД является как бы некоторым тумблером, который срабатывает при возникновении определенного события в БД. Ядро СУБД проводит мониторинг всех событий, которые вызывают созданные и описанные триггеры в БД, и при возникновении соответствующего события сервер запускает соответствующий триггер. Каждый триггер представляет собой также некоторую программу, которая выполняется над базой данных. Триггеры могут вызывать хранимые процедуры. Механизм использования триггеров предполагает, что при срабатывании одного триггера могут возникнуть события, которые вызовут срабатывание других триггеров. Этот мощный инструмент требует тонкого и согласованного применения, чтобы не получился бесконечный цикл срабатывания триггеров. В данной модели сервер является активным, потому что не только клиент, но и сам сервер, используя механизм триггеров, может быть инициатором обработки данных в БД. И хранимые процедуры, и триггеры хранятся в словаре БД, они могут быть использованы несколькими клиентами, что существенно уменьшает дублирование алгоритмов обработки данных в разных клиентских приложениях. Для написания хранимых процедур и триггеров используется расширение стандартного языка SQL, так называемый встроенный SQL. Встроенный SQL мы рассмотрим далее.
Недостатком данной модели является очень большая загрузка сервера. Действительно, сервер обслуживает множество клиентов и выполняет следующие функции: осуществляет мониторинг событий, связанных с описанными триггерами; обеспечивает автоматическое срабатывание триггеров при возникновении связанных с ними событий; обеспечивает исполнение внутренней программы каждого триггера; запускает хранимые процедуры по запросам пользователей; запускает хранимые процедуры из триггеров; возвращает требуемые данные клиенту; обеспечивает все функции СУБД: доступ к данным, контроль и поддержку целостности данных в БД, контроль доступа, обеспечение корректной параллельной работы всех пользователей с единой БД. Если мы переложили на сервер большую часть бизнес-логики приложений, то требования к клиентам в этой модели резко уменьшаются. Иногда такую модель называют моделью с «тонким клиентом» в отличие от предыдущих моделей, где на клиента возлагались гораздо более серьезные задачи. Эти модели называются моделями с «толстым клиентом».
91. Каким оператором можно предоставить право чтения таблицы, и каким оператором можно запретить постороннему пользователю изменять таблицу в базе, где Вы имеете права владельца?
Пользователи СУБД рассматриваются как основные действующие лица, желающие получить доступ к данным. СУБД от имени конкретного пользователя выполняет операции над базой данных, т. е. добавляет строки в таблицы (INSERT), удаляет строки (DELETE), обновляет данные в строках таблицы (UPDATE). Она делает это в зависимости от того, обладает ли конкретный пользователь правами на выполнение конкретных операций над конкретным объектом базы данных. Объекты доступа — это элементы базы данных, доступом к которым можно управлять (разрешать доступ или защищать от доступа). Обычно объектами доступа являются таблицы, однако ими могут быть и другие объекты базы данных — формы, отчеты, прикладные программы и т. д. Конкретный пользователь обладает конкретными правами доступа к конкретному объекту. Привилегии (priveleges) — это операции, которые разрешено выполнять пользователю над конкретными объектами. Например, пользователю может быть разрешено выполнение над таблицей операций SELECT (ВЫБРАТЬ) и INSERT (ВКЛЮЧИТЬ). Таким образом, в СУБД авторизация доступа осуществляется с помощью привилегий. Установление и контроль привилегий — прерогатива администратора базы данных. Привилегии устанавливаются и отменяются специальными операторами языка SQL — GRANT (РАЗРЕШИТЬ) и REVOKE (ОТМЕНИТЬ). Оператор GRANT указывает конкретного пользователя, который получает конкретные привилегии доступа к указанной таблице. Например, оператор GRANT SELECT, INSERT ON Bills TO bit 123 устанавливает привилегии пользователю c логином bit 123 на выполнение операций выбора и включения над таблицей Bills. Как видно из примера, оператор GRANT устанавливает соответствие между операциями, пользователем и объектом базы данных (таблицей в данном случае).
92. Если Вы не являетесь владельцем БД, можете ли Вы запретить другим пользователям просматривать некоторую информацию из дано БД? да 93. Какие модели организации серверов БД Вы знаете? Каковы недостатки архитектуры сервера БД с виртуальным сервером?
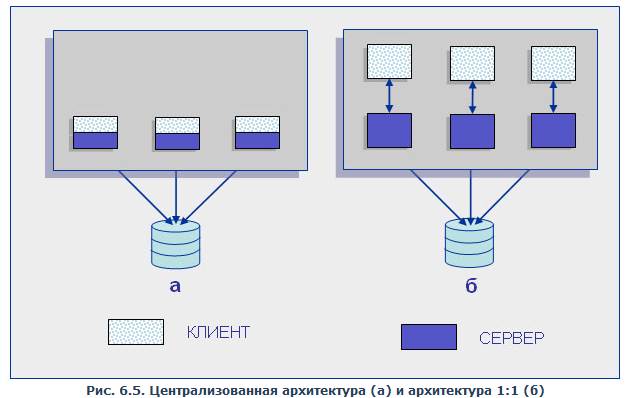
В период создания первых СУБД технология «клиент-сервер» только зарождалась. Поэтому изначально в архитектуре систем не было адекватного механизма организации взаимодействия процессов типа «клиент» и процессов типа «сервер». В современных же СУБД он является фактически основополагающим и от эффективности его реализации зависит эффективность работы системы в целом. Рассмотрим эволюцию типов организации подобных механизмов. В основном этот механизм определяется структурой реализации серверных процессов, и часто называется архитектурой сервера баз данных. Первоначально, как мы уже отмечали, существовала модель, когда управление данными (функция сервера) и взаимодействие с пользователем были совмещены в одной программе. Это можно назвать нулевым этапом развития серверов БД (рис. 6.5, а). Затем функции управления данными были выделены в самостоятельную группу — сервер, однако модель взаимодействия пользователя с сервером соответствовала парадигме «один к одному» (рис. 6.5, б), т. е. сервер обслуживал запросы только одного пользователя (клиента), и для обслуживания нескольких клиентов нужно было запустить эквивалентное число серверных процессов.
Рис. 6.5. Централизованная архитектура (а) и архитектура 1:1 (б)
Выделение сервера в отдельную программу было революционным шагом, который позволил, в частности, поместить сервер на одну машину, а программный интерфейс с пользователем — на другую, осуществляя взаимодействие между ними по сети (рис. 6.6). Однако необходимость запуска большого числа серверов для обслуживания множества пользователей сильно ограничивала возможности такой системы. Для обслуживания большого числа клиентов на сервере должно быть запущено большое количество одновременно работающих серверных процессов, а это резко повышало требования к ресурсам ЭВМ, на которой запускались все серверные процессы. Кроме того, каждый серверный процесс в этой модели запускался как независимый, поэтому если один клиент сформировал запрос, который был только что выполнен другим серверным процессом для другого клиента, то запрос тем не менее выполнялся повторно. В такой модели весьма сложно обеспечить взаимодействие серверных процессов. Эта модель — самая простая, и исторически она появилась первой.
Рис. 6.6. Размещение клиента и сервера на различных машинах
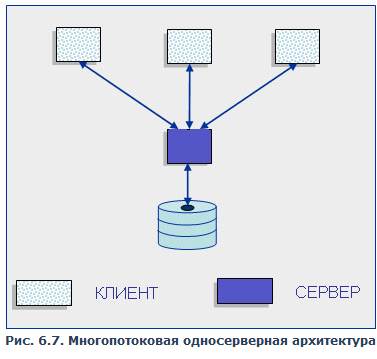
Проблемы, возникающие в модели «один к одному», решаются в архитектуре систем с выделенным сервером, который способен обрабатывать запросы от многих клиентов. Сервер единственный обладает монополией на управление данными и взаимодействует одновременно со многими клиентами (рис. 6.7).
Рис. 6.7. Многопотоковая односерверная архитектура
Логически каждый клиент связан с сервером отдельной нитью (thread), или потоком, по которому пересылаются запросы. Такая архитектура получила название многопотоковой односерверной (multi-threaded). Она позволяет значительно уменьшить нагрузку на операционную систему, возникающую при работе большого числа пользователей. Кроме того, возможность взаимодействия с одним сервером многих клиентов позволяет в полной мере использовать разделяемые объекты (начиная с открытых файлов и кончая данными из системных каталогов), что значительно уменьшает потребности в памяти и общее число процессов операционной системы. Например, системой с архитектурой «один к одному» будет создано 100 копий процессов СУБД для 100 пользователей, тогда как системе с многопотоковой архитектурой для этого понадобится только один серверный процесс. Однако такое решение имеет свои недостатки. Так как сервер может выполняться только на одном процессоре, возникает естественное ограничение на применение СУБД для мультипроцессорных платформ. Если компьютер имеет, например, четыре процессора, то СУБД с одним сервером используют только один из них, не загружая оставшиеся три. В некоторых системах эта проблема решается вводом промежуточного диспетчера. Подобная архитектура называется архитектурой виртуального сервера (virtual server) (рис. 6.8).
Рис. 6.8. Архитектура с виртуальным сервером
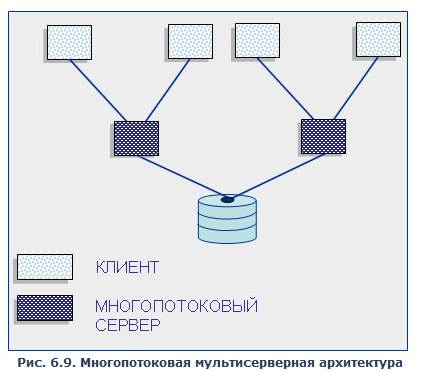
В этой архитектуре клиенты подключаются не к реальному серверу, а к промежуточному звену, называемому диспетчером, который выполняет только функции диспетчеризации запросов к актуальным серверам. В этом случае нет ограничений на использование многопроцессорных платформ. Количество актуальных серверов может быть согласовано с количеством процессоров в системе. Однако и эта архитектура не лишена недостатков, потому что здесь в систему добавляется новый слой, который размещается между клиентом и сервером, что увеличивает трату ресурсов на поддержку баланса загрузки актуальных серверов (load balancing) и ограничивает возможности управления взаимодействием «клиент – сервер». Во-первых, становится невозможным направить запрос от конкретного клиента конкретному серверу; во-вторых, серверы становятся равноправными — нет возможности устанавливать приоритеты для обслуживания запросов. Подобная организация взаимодействия «клиент – сервер» может рассматриваться как аналог банка, где имеется несколько окон кассиров, и специальный банковский служащий — администратор зала (диспетчер) направляет каждого вновь пришедшего посетителя (клиента) к свободному кассиру (актуальному серверу). Система работает нормально, пока все посетители равноправны (имеют равные приоритеты), однако стоит лишь появиться посетителям с высшим приоритетом, которые должны обслуживаться в специальном окне, как возникают проблемы. Учет приоритета клиентов особенно важен в системах оперативной обработки транзакций, однако именно эту возможность не может предоставить архитектура систем с диспетчеризацией. Современное решение проблемы СУБД для мультипроцессорных платформ заключается в возможности запуска нескольких серверов базы данных, в том числе и на различных процессорах. При этом каждый из серверов должен быть многопотоковым. Если эти два условия выполнены, то есть основания говорить о многопотоковой архитектуре с несколькими серверами, представленной на рис. 6.9.
Рис. 6.9. Многопотоковая мультисерверная архитектура
Она также может быть названа многонитиевой мультисерверной архитектурой. Эта архитектура связана с распараллеливанием выполнения одного пользовательского запроса несколькими серверными процессами. Существует несколько возможностей распараллеливания выполнения запроса. В этом случае пользовательский запрос разбивается на ряд подзапросов, которые могут выполняться параллельно, а результаты их выполнения потом объединяются в общий результат выполнения запроса. Тогда для обеспечения оперативности выполнения запросов их подзапросы могут быть направлены отдельным серверным процессам, а потом полученные результаты объединены в общий результат. В данном случае серверные процессы не являются независимыми процессами, такими, как рассматривались ранее. Эти серверные процессы принято называть нитями (treads), и управление нитями множества запросов пользователей требует дополнительных расходов от СУБД, однако при оперативной обработке информации в хранилищах данных такой подход наиболее перспективен.
Тема 7. Транзакции, оперативная обработка транзакций (OLTP)
|
|||||||||
|
|
Последнее изменение этой страницы: 2017-01-27; просмотров: 625; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.117.184.125 (0.012 с.) |