
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Основні поняття теорії мов та граматикСодержание книги
Поиск на нашем сайте
Формальні мови та граматики Мови програмування та їх класифікація Технологія обробки тексту програми Трансляція програм Програма, написана на алгоритмічній мові програмування не може бути безпосередньо виконана на ЕҐОМ – вона містить тільки текст, що описує послідовність дій. Щоб одержати працюючу програму, треба цей текст перевести на машинну мову. Процес перекладу вихідного тексту програми, написаного на мові високого рівня, в машинну мову називається трансляцією (від англ. translation — переклад). Трансляція - це чисто технічна робота і її доручають ПК. Існує два способи трансляції: - інтерпретація (від англ. interpretation) – пооператорний переклад і виконання команд програми. Кожна інструкція програми перекладається в машинний код та виконується, і тільки після цього процесор переходить до обробки наступної інструкції. Процес продовжується до першої помилки або, якщо помилок немає, - до кінця програми. Це гнучка система перекладу, яка реалізовується нескладно; - компіляція (від англ. compile — збирати) - автоматичний переклад усього тексту програми в машинний код і формування об'єктного модуля, який згодом може бути виконаний самостійно. При цьому паралельно здійснюється синтаксичний контроль програми в цілому. Відтрансльована програма не виконується негайно, а зберігається в пам'яті комп'ютера. При перегляді програми компілятор виділяє місце в пам’яті для кожної змінної. Компіляцію можна порівняти з письмовим перекладом книги, інтерпретацію - із синхронним перекладом мови. Кожен із способів трансляції має свої переваги і недоліки. Так відкомпільовані програми виконуються швидше, ніж ті, що інтерпретуються; одного разу відкомпільована програма не вимагає надалі компілятора. Програми ж, написані на мовах, орієнтованих на інтерпретацію, вимагають присутності в пам'яті комп'ютера інтерпретатора, який здійснює трансляцію програми в ході її виконання. Однак, інтерпретатор корисний як при налагодженні, так і при трансляції програм, схильних до частих змін: виправлену програму можна відразу запустити на виконання, щоб перевірити її працездатність. При використанні ж компілятора виправлену програму доводиться перекомпільовувати. Інтерпретатор використовується в тих випадках, коли потрібна простота трансляції (Basic), або там, де інший спосіб перекладу дуже складний або навіть неможливий (Lisp). Для реалізації процесу трансляції служать спеціальні програми - транслятори, які обробляють команди мови програмування, як вхідні дані і, у відповідності з існуючими правилами, переводять їх в еквівалентні машинні коди. Відповідно, транслятори поділяються на дві категорії: інтерпретатори і компілятори. Як компілятор, так і інтерпретатор повинні відповідати правилам конкретної мови високого рівня, яку вони транслюють. Мовами інтерпретуючого типу є BASІC, LISP, Perl, Prolog, Java; компілюючого типу – FORTRAN, Pascal, С, C++. Загалом процес трансляції вихідної програми проходить в чотири етапи. На першому етапі - лексичного аналізу - групи символів тексту програми перетворюються в позначки, зрозумілі транслятору. Потім слідує етап синтаксичного аналізу, коли ці позначки розміщуються в ієрархічному порядку, який відображає логіку програми. На третьому етапі - контролю типів перевіряється узгодженість даних позначок одна з одною, що дозволяє виявити помилки в програмі. І нарешті, генератор коду формує машинні команди процесору. Розглянемо більш детально дані етапи. Лексичний аналіз. Лексичний аналіз є першою фазою трансляції. Його основна задача – перетворити вхідний текст програми, який складається з послідовності одиничних символів, на послідовність спеціальних позначок, які зрозумілі транслятору. Програма чи функція, що здійснює лексичний аналіз, називається лексичним аналізатором або сканером. Сканер читає літери вихідного коду програми одна за одною і відповідно до граматичних правил мови об'єднує їх в групи - лексеми. Лексема - це послідовність з одного або декількох символів, які мають однорідний зміст для мови, яка транслюється. Наприклад, рядок програми на мові С/С++ len = 3.14*r; складається з наступних лексем: len, “=”, 3.14, “*”, r, “;”. При виділенні лексем сканер ігнорує пропуски між ними і здвиги рядків вихідної програми, оскільки ця інформація для трансляції є неістотною. Більшість сформованих сканером лексем мають точно визначений правилами мови зміст: ключові слова (наприклад, if, for, while) вказують на дії, які задаються синтаксисом мови програмування; операції (типу “+”, “*”) вказують на певні дії (арифметичні, логічні тощо) або на пересилку даних; числа задають реальні числові значення (скажімо 5 або 7); знаки пунктуації допомагають транслятору розібратися в структурі програми. Інший різновид лексем - ідентифікатори - не мають точно визначеного правилами мови змісту, наприклад, ім'я програми, імена змінних або констант. Кожна виділена лексема доповнюється спеціальною позначкою – токеном, що визначає тип даної лексеми. У загальному випадку один і той самий токен може відповідати множині лексем. Група таких лексем задається за допомогою шаблона даного токена, який представляє собою формальний опис класу лексем, що мають певне сукупне значення. Наприклад,
Тут шаблон для символу if - це єдиний рядок if, що повторює ключове слово. Шаблоном для символу relation є множина усіх відношень мови програмування (наприклад, < або <= або = або <> або >= або >). Для точного опису шаблонів більш складних токенів, таких як id чи num, використовується нотація регулярних виразів. Токени всіх лексем і їх лексичне значення заносяться у спеціальну таблицю. Для додаткової інформації про лексеми в таблиці залишаються вільні місця. Вони заповнюються на подальших етапах роботи транслятора. Сканер обробляє лише одну лексему за раз. Синтаксичний аналіз (від англ. parsing). Це процес аналізу отриманих на попередньому етапі токенів з метою розбору граматичної структури тексту програми у відповідності із заданою формальною граматикою.
Приклад синтаксичного дерева розбору для виразу:
Побудовою дерева управляє набір явно записаних правил: кожній послідовності токенів відповідає один-єдиний спосіб розміщення їх у дереві. Зустрічаючи послідовність токенів, до якої не підходить жодне правило, синтаксичний аналізатор вважає, що в програмі міститься помилка. У такому разі транслятор посилає повідомлення про помилку, в якому міститься інформація про місце і тип помилки. У компіляторі і інтерпретаторі синтаксичний аналіз (розбір) йде декілька по-різному. У інтерпретаторі відбирається рівно стільки токенів, скільки треба для утворення логічно зв'язаного фрагмента вихідної мови (оператора). Після синтаксичного аналізу цей фрагмент передається на наступний етап транслятора. Черговий фрагмент виділяється лише після завершення обробки і виконання поточного фрагмента. Синтаксичний аналіз в компіляторі обробляє всю програму цілком, не виконуючи її: після розбору вся програма передається на наступний етап. Контроль типів. Після того, як синтаксичний аналізатор згрупує лексеми, транслятор перевіряє зміст як окремих лексем, так і їх груп. Цей вид аналізу направлений в першу чергу на виявлення помилок, тобто пошук частин програми, що порушують правила мови. Один з найбільш важливих видів аналізу помилок - контроль типів. Багато мов програмування, вимагають явного опису типів даних. Якщо ж програма не містить інформації про тип змінної, транслятор повинен визначити її тип по контексту. Якщо типи даних, використані у виразі, не сумісні, то відтрансльована програма не може працювати правильно. Коли такі помилки виявляються при трансляції, надійність програмування підвищується. Якщо типи синів одного батька не збігаються, то транслятор використовує правило, що дозволяє йому продовжити роботу. Наприклад, якщо один із синів має цілий, а інший - дійсний тип, то таке правило може вказувати, що батько повинен мати дійсний тип. Проте можливі недопустимі поєднання типів. На малюнку показаний випадок, коли один син має цілий (I) тип, а другий - літерний (C). Для такої комбінації типів не існує правила дозволу, і тому транслятор видає програмістові повідомлення про помилку. Контроль типів грає ще одну дуже важливу роль: дає транслятору додаткову інформацію про лексему, яка потрібна при генерації коду. Наприклад, операція «+» діє по-різному, а значить, вимагає різного машинного коду - залежно від типів її доданків. Генерація коду. Цепроцесрозбору синтаксичного дерева для отримання машинних команд. Генератор коду вирішує основну задачу транслятора: перетворює лексеми в послідовності машинних команд, керуючих комп'ютером. Він виконує це в процесі обходу синтаксичного дерева. З вузлів дерева в певному порядку витягуються лексеми. Коли набирається кількість, достатня для визначення потрібної операції, відбувається генерація відповідних машинних команд і обхід дерева поновлюється. Як і на попередніх етапах трансляції, обхід дерева здійснюється відповідно до правил мови, на якій написана програма. Обхід починається з верхівки дерева і продовжується в напрямку вниз і вправо по його периметру. Коли зустрічається вузол «батько», перебираються по черзі всі його «сини»; якщо «син» є також і «батьком», то перебираються і його «сини». Так відбувається спуск по дереву, поки не зустрінеться вузол, що не має «синів». З такого вузла береться лексема і розглядається наступний «син». Врешті-решт перебираються всі «сини» на найнижчому рівні в цій гілці дерева. Далі відбувається повернення до «батька», який тепер обробляється. Обійшовши дерево, відповідне одному виділеному фрагменту, інтерпретатор викликає підпрограму на машинній мові, яка і виконує потрібну операцію, перш ніж приступити до розбору наступного фрагменту. Компілятор же обходить дерево всієї програми, генеруючи код і записуючи його в пам'ять для подальшого виконання або обробки.
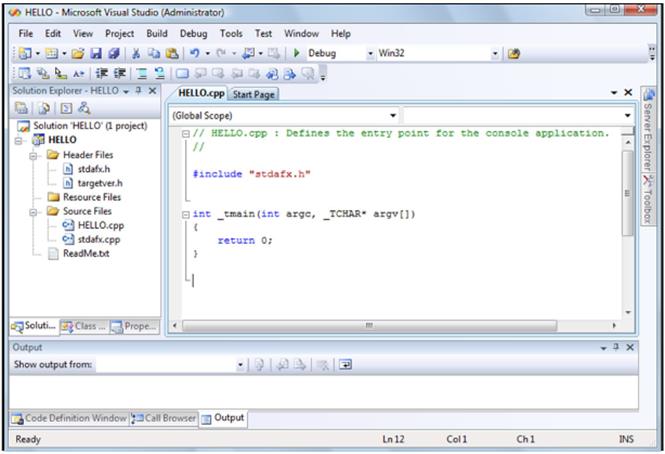
Microsoft Visual Studio Загальні прийоми роботи Microsoft Visual Studio - лінійка продуктів компанії Microsoft, що включають інтегроване середовище розробки програмного забезпечення та ряд інших інструментальних засобів. IDE Visual Studio.NET – це набір інструментів і засобів розробки різного роду застосувань (консольних, Windows, мобільних, Web-застосувань) та сервісів. Visual Studio є мультипрограмним середовищем, що підтримує декілька мов програмування, зокрема, С++, С#. Довідкові відомості про всі розробки компанії Microsoft зібрані в один програмний продукт MSDN (Microsoft Developer Network). У Visual Studio кожне окреме застосування є рішенням (solution), що складається з одного чи декількох проектів (project). Одночасно можна відкрити тільки одне рішення (з розширенням. sln), при роботі над кількома рішеннями одночасно потрібно запускати декілька вікон Visual Studio. Visual Studio надає шаблони для проектів найбільш поширених типів. Використання проектів і їх шаблонів дозволяє користувачеві зосередитися на реалізації окремої функції, в той час як проект буде виконувати загальне управління та завдання побудови. Для створення нового проекту використовується майстер додатків. Майстер створення програм надає користувальницький інтерфейс для створення проекту за шаблоном та створення шаблонів для файлів вихідних текстів. Майстер налаштовує структуру програми, основні меню і панелі інструментів, забезпечує включення деяких заголовних файлів. Запуск середовища здійснюється через відповідний пункт меню Пуск (Пуск4Програми4 Microsoft Visual Studio). Після цього на екрані з’являється стартова сторінка (Start Page) Visual Studio (рис. 3).
Рис. 3. Cтартова сторінка Visual Studio 2008 Елементи графічного інтерфейсу Microsoft Visual Studio характерні для Windows-програм. Розмір і форма вікон визначається конкретною конфігурацією системи. Користувач має можливість змінювати розмір і розташування окремих елементів, згортати їх з тим, щоб збільшити місце для інших, необхідних в даний момент, елементів. У головному вікні Visual Studio можна виділити декілька основних елементів (рис. 4): - меню та набір інструментальних панелей, де зосереджені команди для роботи в IDE; - вікно Провідник рішень (Solution Explorer), що дозволяє переглядати склад проектів, що входять у рішення, у вигляді ієрархічної структури, а також зв'язки між проектами та їх компонентами; - вікно редактора, що служить для набору тексту програми і підтримує автодоповнення та підсвітку ситнаксису; - вікно виведення стану Output, в якому відображається інформація про хід побудови (збірки) програми та виявлені помилки. Розмір цих зон та їх розташування на екрані користувач може налагоджувати за власним бажанням.
Рис. 4. Головне вікно Visual Studio 2008
Засоби налагодження програм Налагодження – це процес пошуку і виправлення помилок в програмі, які перешкоджають її коректній роботі. Налагодження програми є одним із найбільш важливих і трудомістких етапів її розробки. Загалом, налагодження програм передбачає виконання наступних кроків: 1) виявлення факту наявності помилки; 2) визначення місця знаходження помилки (її локалізація); 3) виправлення помилки. Існує три основних типи помилок: - синтаксичні, що виникають в результаті порушення правил написання алгоритмічних конструкцій (речень) мови програмування; - семантичні, зв'язані з недопустимими значеннями параметрів, діями над параметрами (ділення на 0, спроба відкрити неіснуючий файл тощо); - логічні, зв'язані з неправильним використанням алгоритмічних конструкцій, неправильним проектуванням і реалізацією програми. Синтаксичні помилки виявляються на етапі компіляції програми, тому їх ще називають помилками етапу компіляції. Ці помилки відображаються у вікні вихідних даних Output (номер рядка, в якому знайдена помилка, і її опис). Натисення кнопки Go To Next Message (зелена стрілка праворуч у вікні Output) або подвійне клацання лівою кнопкою миші на повідомленні про помилку, переводить курсор на рядок, що її містить. Семантичні помилки виявляються під час роботи програми, тому їх ще називають помилками етапу виконання. При виявленні такої помилки, виконання програми завершується і виводится вікно з повідомленням про тип помилки і адресою інструкції, в якій вона сталася. Наприклад,
Логічні помилки не викликають порушень в роботі програми, але приводять до неправильних результатів (некоректному або непередбачуваному значенню змінних, невиконанню коду, коли це передбачається, тощо). Ці помилки часто важко відслідкувати, оскільки IDE не може знайти їх автоматично, як синтаксичні і семантичні. Логічні помилки, зазвичай, виявляються при тестуванні програми з використанням вбудованого налагоджувача, функції якого реалізуються командами меню Debug. Основні засоби налагодження програм умовно можна розділити на три групи: 1. Трасування програм. Режим трасування передбачає покрокове (пооператорне) виконання програми. Це дозволяє переглянути послідовність виконання операторів програми і зробити висновки про правильність її роботи. При цьому можна простежувати покрокові вихідні результати, зміну значень елементів даних тощо. Програма у покроковому режимі запускається командою Debug4 Step Into (клавіша F11) або Debug4 Step Over (клавіша F10). Команда Step Into застосовується для трасуванням (покрокового виконання) не тільки операторів основної програми, а і тіл функцій в точці їх виклику, тоді як команда Step Over виконує функцію за один крок. Для завершення покрокового виконання програми використовується команда Debug4Stop Debugging або комбінація клавіш Shift+F5. 2. Організація точок переривання. Для детального відстеження дій програми в проблемних місцях, у відповідних рядках програми встановлюють точки переривання (breakpoints). У момент виходу програми на такі точки її виконання припиняється. При цьому можна переглянути значення деяких елементів даних, продовжити виконання збійної ділянки програми в покроковому режимі і т.ін. Задати точку переривання перед деяким оператором можна командою Debug4Toggle Breakpoint, встановивши перед тим курсор на відповідний оператор програми, або подвійним клацанням кнопки миші на сірому полі ліворуч від вибраного рядка коду. Рядок програми, який містить точку переривання, помічається у лівій частині вікна текстового редактора колом червоного кольору:
Видалення точок переривання здійснюється командою Debug4 Delete All Breakpoints або подвійним клацанням кнопки миші на самій точці переривання. Програма, запущена на виконання командою Debug4Start Debugging, досягнувши виділеного рядка, зупиниться. Після зупинки програми можна розпочати її покрокове виконання для аналізу поточних значень змінних в процесі пошуку логічної помилки. Подальше продовження роботи програми до наступної точки переривання здійснюється повторним її запуском. Перегляд поточних значень елементів даних у процесіроботи програми. При покроковому виконанні програми дані, що переглядаються, змінюються, відображаючи поточні зміни в програмі. Непрогнозовані значення означають помилки. Поточні значення змінних відображаються у вікнах WatchХ, які активізуються командою Debug4Windows4Watch4WatchX, де Х — порядковий номер вікна. Для перегляду значень певної змінної її ім’я слід вказати у вікні Watch в колонці Name, її поточні значення виводитимуться у колонці Value. Коли вікно Watch активне, додати до нього змінну можна як у звичайну таблицю, а для видалення змінної слід обрати її ім’я і натиснути клавішу Delete.
Формальні мови та граматики Основні поняття теорії мов та граматик Мова — це система знаків (символів, жестів, положень перемикача і т. д.) для представлення та обміну інформацією. Мови поділяються на природні (українська, російська, англійська тощо) та штучні (формальні). До штучних мов належать мови, створені людьми для розв’язання специфічних задач, зокрема, мова математичних формул, нотна грамота тощо. Формальні мови відіграють важливу роль і в інформатиці. Завдяки ним, інформацію можна представляти у вигляді, придатному для автоматичного аналізу та обробки на комп'ютері. До формальних мов належать і мови програмування. Будь-яка мова –– і природна і штучна –– має набір певних правил. Вони можуть бути явно і строго сформульованими (формалізованими), а можуть допускати різні варіанти їх використання. На відміну від природних мов, що допускають можливість неоднозначного тлумачення складених із них речень, штучні мови мають обмежене число "слів" і дуже строгі правила їх тлумачення і використання. Форма́льна мо́ва — це множина скінчених послідовностей символів (“слів” і “речень”), спосіб побудови яких описується правилами певного виду. Будь-яка формальна мова характеризується:
§ синтаксисом (граматикою) - правилами побудови із символів алфавіту таких мовних конструкцій, як “слова”, “речення” і “тексти”;
Якщо Т — алфавіт мови, то як Т* позначають множину рядків (послідовностей символів), які можуть бути побудовані з символів алфавіту Т. При цьому передбачається, що порожній рядок (позначається як ε) також входить у множину Т*:
де Т+ — множина усіх можливих рядків, складених з символів алфавіту Т, окрім порожнього рядка ε. Кожна мова в алфавіті Т - це підмножина множини Т*. Наприклад, якщо алфавіт заданий як { a, b }, а мова L включає в себе всі слова над ним, то слово ababba належить L. Для задання формальної мови підходить будь-яке математично коректне визначення множини слів в заданому алфавіті. Так формальна мова може бути визначена - простим перерахуванням слів, що входять в дану мову (цей спосіб, в основному, прийнятний для визначення мов простої структури). - за допомогою механізму породження слів (формальної граматики), - словами, породженими регулярним виразом, - словами, породженими БНФ-конструкцією, тощо. Проте, якщо мати на увазі задання мови, при якому можливе алгоритмічне вирішення питання про приналежність слова мові, то потрібні більш обмежені засоби. Найбільш загальним із конструктивних способів задання формальних мов є спосіб породження їх за допомогою формальних граматик. Формальна граматика (граматика формальної мови) — це множина правил породження слів, виразів і речень формальної мови. Ці правила називають ще синтаксисом мови. Формальною граматикою G для породження формальної мови в алфавіті T є набір G = {T, N, P, S}, де · T – множина символів алфавіту (термінальних символів[1]) або термінальний словник мови (її алфавіт). Термін "алфавіт" щодо формальних мов майже повністю відповідає його неформальному визначенню в розмовних мовах і відрізняється лише тим, що включає всі можливі символи, в той час як, наприклад, крапка, кома, знак переносу, знак оклику і т.п. при неформальному визначенні розмовних мов в алфавіт не включаються. З точки зору мов програмування, це - імена змінних, службові слова, знаки операцій тощо. · N – нетермінальний словник або множина нетерміналів, якими позначаються синтаксичні конструкції мови. Нетермінали - це елементи граматики, що мають власні імена і структуру. Кожен нетермін складається з одного або більшої кількості терміналів і/або нетерміналів, поєднання яких визначається правилами граматики. Стосовно розмовних мов це, наприклад, префікс, корінь, підмет, присудок, просте речення і т. ін.; з точки ж зору мов програмування, це її поняття - оператори, списки, блоки тощо. · P – множина правил граматики за допомогою яких будується нетермінальний словник (синтаксичні конструкції). Множину правил граматики ще називають синтаксисом мови. · S - мета граматики (аксіома) - старший нетермінальний символ ( При формальному визначенні граматики мається на увазі, що будь-який нетермінал, у тому числі і мета граматики, є одна, нехай навіть дуже довга, послідовність символів (рядок). Правила граматики описують відношення між нетерміналами і терміналами шляхом визначення нетермінального символа через комбінацію термінальних і нетермінальних символів. Кожне таке правило P має вигляд Правило виводу Якщо У формальних граматиках послідовності символів інтерпретуються як мовні об’єкти різних рівнів. На рівні граматики визначаються поняття (нетермінали), послідовне розкриття яких (їх виведення), в кінці кінців дає їх представлення у вигляді послідовностей термінальних символів. Поняття бувають § осмислені – мовні конструкції, для яких визначена та або інша дія, § допоміжні - потрібні лише для того, щоб зробити текст читабельним (самостійного сенсу вони не мають). Мінімальні осмислені поняття відповідають лексемам; мінімальні допоміжні поняття подібні до знаків пунктуації. Правила граматики (продукції, виводу) фактично визначають одні поняття через інші. Для прикладу опишемо формальну граматику, яка породжує математичні вирази (суми): 1. Сума → Цифра 2. Сума → Сума + Цифра 3. Сума → Сума - Цифра 4. Цифра → 1.. 9 Тут кожен рядок визначає одне правило, термінальні символи мови підкреслені, а нетермінальні виділені курсивом. Аксіомою в цій мові є слово Сума. Виходячи із даної аксіоми та застосовуючи наведені вище правила, можна отримати наступні вирази (рядки):
Порядок застосування правил довільний. Граматика визначає лише правила, які дозволяється використовувати у поточній ситуації, і не дає вказівок, які правила мають бути застосовані. Наприклад, до першого речення (аксіоми) можна застосувати лише правила 1—3, та не можна застосувати правило 4. Починаючи з 4 речення можливе застосування лише правила 4. Процес виводу слова в формальній граматиці може бути графічно представлений у вигляді синтаксичногодерева, кореневою вершиною якого є мета граматики, в проміжних вершинах знаходяться нетермінали, а «листям» є термінали. Розглянемо наступну граматику:
Виведенню
Крона цього дерева виводу - ababab. З математичної точки зору формальна мова Набір правил послідовно визначає всі нетермінальні символи формальної граматики так, що кожен такий символ може бути зведений до комбінації термінальних символів шляхом послідовного (рекурсивного) вживання правил. Теорія формальних граматик сформульована у 50-ті роки американським лінгвістом Хомським (Чомскі).
|
|||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-02-07; просмотров: 307; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.147.46.174 (0.01 с.) |

 Синтаксичний аналізатор отримує від сканера токени і розташовує їх у вигляді синтаксичного дерева - структури, яка дозволяє транслятору розібратися в логіці програми. Токен може бути або «батьком», або «сином», або тим і іншим одночасно. Синтаксичний аналізатор розміщує токен в дереві, аналізуючи його зміст, зміст токена, що передує даному, а інколи і наступного токена. Групи токенів об'єднуються в оператори - основні структурні одиниці програми.
Синтаксичний аналізатор отримує від сканера токени і розташовує їх у вигляді синтаксичного дерева - структури, яка дозволяє транслятору розібратися в логіці програми. Токен може бути або «батьком», або «сином», або тим і іншим одночасно. Синтаксичний аналізатор розміщує токен в дереві, аналізуючи його зміст, зміст токена, що передує даному, а інколи і наступного токена. Групи токенів об'єднуються в оператори - основні структурні одиниці програми.



 ,
, ), що визначає клас мовних об’єктів, для опису яких призначена граматика G. По аналогії з розмовною мовою це, наприклад, текст; в мовах програмування це - програма.
), що визначає клас мовних об’єктів, для опису яких призначена граматика G. По аналогії з розмовною мовою це, наприклад, текст; в мовах програмування це - програма. , де
, де  ,
,  — елементи із словника граматики V = T È N, причому елемент
— елементи із словника граматики V = T È N, причому елемент  , тільки якщо
, тільки якщо  , отриманий заміною будь-якого фрагмента
, отриманий заміною будь-якого фрагмента  . Якщо
. Якщо  , то скорочено це можна записати так:
, то скорочено це можна записати так:  .
.
 відповідає наступне синтаксичнедерево:
відповідає наступне синтаксичнедерево:
 - це множина рядків символів в алфавіті T, які можуть бути отримані із аксіоми
- це множина рядків символів в алфавіті T, які можуть бути отримані із аксіоми  шляхом кінцевого числа застосувань правил P граматики G.
шляхом кінцевого числа застосувань правил P граматики G.


