
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Понятие баз данных. Концепция БД. Преимущества банковской организации данных.Содержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
Понятие баз данных. Концепция БД. Преимущества банковской организации данных. БД – Представляет собой совокупность специальным образом организованных данных, хранимых в памяти вычислительной системы и отображающих состояние объектов и их взаимосвязей в рассматриваемой предметной области. Концепция баз данных До появления концепции БД и соответствующих этой концепции программных средств управление данными во внешней памяти производилось с помощью файловых систем, которые являются подсистемой ОС. Но их возможности для информационного моделирования ПО ограничены. Основные черты концепции БД: • данные отделяются от прикладной программы (ПП), появляется специальная программная надстройка для управления данными, называемая системой управления базами данных (СУБД); СУБД управляет данными и служит посредником между ними и ПП; ПП упрощаются, освобождаются от функций структуризации, хранения и поиска данных; • появляются стандартизированные данные о фактографических данных – метаданные, управляемые СУБД; метаданные описывают информационные параметры и взаимосвязи фактографических данных о ПО;СУБД совместно с метаданными представляет собой стандартизированное инструментальное средство для моделирования ПО различной природы; • происходит централизация (интеграция) данных, их многоаспектное использование для различных приложений, что сокращает избыточность данных, позволяет обеспечить более высокий уровень достоверности данных и оптимизировать различные процедуры ведения и использования БД. Принято считать, что использование концепции баз данных позволяет: 1. повысить надежность, целостность и сохранность данных; 2. сохранить затраты интеллектуального труда; 3. обеспечить простоту и легкость использования данных; 4. обеспечить независимость прикладных программ от данных (изменений их описаний и способов хранения); 5. обеспечить достоверность данных; 6. обеспечить требуемую скорость доступа к данным; 7. стандартизовать данные в пределах одной предметной области; 8. автоматизировать реорганизацию данных; 9. обеспечить защиту от искажения и уничтожения данных; 10. сократить дублирование информации за счет структурирования данных;
11. обеспечить обработку незапланированных запросов к хранимой информации; 12. создать предпосылки для создания распределенной обработки дaнныx.
Банк данных (БнД) является современной формой организации хранения и доступа к информации. Банк данных – это прежде всего система специальным образом организованных данных (баз данных), программных, технических, языковых, организационно-методических средств, предназначенных для обеспечения централизованного накопления и коллективного многоцелевого использования данных. Банк данных является сложной системой, включающей в себя все обеспечивающие подсистемы, необходимые для функционирования любой системы автоматизированной обработки. Прежде всего это то, что базы данных создаются не для решения какой-либо одной задачи для одного пользователя, а для многоцелевого использования. Другая отличительная особенность банков данных – наличие специальных языковых и программных средств, облегчающих для пользователей выполнение всех операций, связанных с организацией хранения данных, их корректировки и доступа к ним. Такая совокупность языковых и программных средств называется системой управления базой данных (СУБД). Функции СУБД Современная система управления базами данных должна выполнять следующие функции:
Требования к БнД.
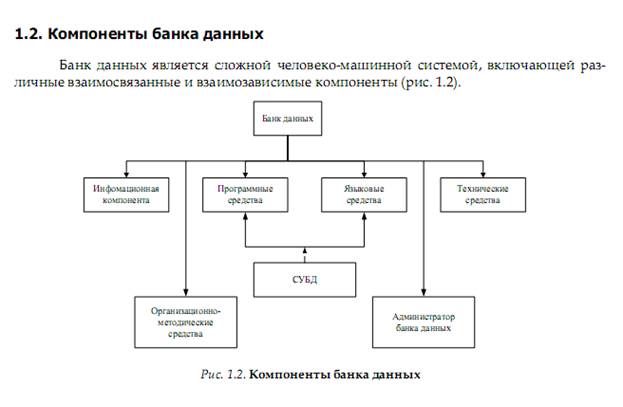
Компоненты БнД.
Классификация СУБД и БД. Под определение СУБД может попасть любой программный продукт, способный поддерживать процессы проектирования, администрирования и использования базы данных, поэтому была разработана классификация СУБД по видам программ: 1) полнофункциональные – самые многочисленные и мощные по своим возможностям программы, например Microsoft Access, Microsoft FoxPro, Clarion Database Developer и др.; Полнофункциональныеявляются наиболее многочисленными и мощными по своим возможностям. Обычно ПФСУБД имеют развитый интерфейс, позволяющий с помощью команд меню выполнять основные действия с БД: создавать и модифицировать структуры таблиц, вводить данные, формировать запросы, разрабатывать отчеты, выводить их на печать и т. и. Для создания запросов и отчетов не обязательно программирование, а удобно пользоваться языком QBE (Query By Example — формулировки запросов по образцу. Многие ПФСУБД включают средства программирования для профессиональных разработчиков.
2) серверы баз данных – применяются для организации центров обработки данных в сетях ЭВМ. Среди них программы Microsoft SQL Server, NetWare SQL фирмы Novell; Серверы БД реализуют функции управления базами данных, запрашиваемые другими (клиентскими) программами обычно с помощью операторов SQL.
3) клиенты баз данных – различные программы (полнофункциональные СУБД, электронные таблицы, текстовые процессоры и т. д.), обеспечивающие большую производительность вычислительной сети, если клиентская и серверная части базы данных будут произведены одной фирмой, но такое условие не является обязательным; В роли клиентских программ для серверов БД в общем случае могут использоваться различные программы: ПФСУБД, электронные таблицы, текстовые процессоры, программы электронной почты и т. д. При этом элементы пары «клиент — сервер» могут принадлежать одному или разным производителям программного обеспечения.
4) средства разработки программ работы с базами данных – предназначены для разработки таких программных продуктов, как клиентские программы, серверы баз данных и их отдельные приложения, а также пользовательские приложения. Средствами разработки пользовательских приложений служат системы программирования, библиотеки программ для различных языков программирования, пакеты автоматизации разработок. Самыми часто используемыми средствами разработки пользовательских приложений являются инструментальные средства Delphi фирмы Borland и Visual Basic фирмы Microsoft. Средства разработки программ работы с БД могут использоваться для создания разновидностей следующих программ: · клиентских программ; · серверов БД и их отдельных компонентов; · пользовательских приложений.
Программы первого и второго вида довольно малочисленны, так как предназначены, главным образом, для системных программистов. Пакетов третьего вида гораздо больше, но меньше, чем полнофункциональных СУБД. По виду применения СУБД подразделяются на персональные и многопользовательские. Персональные СУБД (например, Visual FoxPro, Paradox, Access) используются при проектировании персональных баз данных и недорогих приложений, работающих с ними, которые, в свою очередь, могут применяться в качестве клиентской части многопользовательской СУБД. Многопользовательские СУБД (например, Oracle и Informix) состоят из сервера баз данных и клиентской части и способны работать с различными типами ЭВМ и ОС различных фирм-производителей. Чаще всего информационные системы строятся на основе архитектуры клиент-сервер, в которую входят вычислительная сеть и распределенная база данных. Вычислительная сеть используется для организации научной работы на ПК и в сетях. Распределенная база данных состоит из многопользовательской базы данных, размещенной на компьютере-сервере, и персональной базы данных, находящейся на рабочих станциях. Сервер базы данных осуществляет выполнение основного объема обработки данных. Классификация СУБД и БД 1. По модели данных - иерархические - сетевые - реляционные - объектно-ориентированные - объектно-реляционные - пост-реляционные 2. По степени распределенности - локальные СУБД - распределенные СУБД 3. По способу доступа к БД - файл-серверные - клиент-серверные – встраеваемые 1. В зависимости от размера БД и ее расположения можно выделить - портативные БД, небольшие БД, - сетевые БД, - распределенные БД 2. В зависимости от хранимых данных: - фактографические БД - документальные БД - текстовая база данных - гипертекстовая база данных - полнотекстовая база данных - численно-текстовая база данных 3. В зависимости от модели данных - иерархическая - сетевая - реляционная - многомерная (пост-реляционная) - объектная - объектно-ориентированная - объектно-реляционная 4. В зависимости от технологии хранения: - БД во вторичной памяти - БД в оперативной памяти - БД в третичной памяти
Базы данных Модель структурирования
По типу хранимой информации
По языкам общения По функциям
По сфере применения
По мощности
OLTP и OLAP системы. ROLAP (Relational OLAP) ROLAP-системы позволяют представлять данные, хранимые в классической реляционной базе, в многомерной форме или в плоских локальных таблицах на файл-сервере, обеспечивая преобразование информации в многомерную модель через промежуточный слой метаданных. Агрегаты хранятся в той же БД в специально созданных служебных таблицах. В этом случае гиперкуб эмулируется СУБД на логическом уровне. Преимущества ROLAP.
Недостатки ROLAP.
HOLAP (Hybrid OLAP) Детальные данные остаются в той же реляционной базе данных, где они изначально находились, а агрегатные данные хранятся в многомерной базе данных. Уровни моделей БД. Связи между объектами.
Тип данных Понятие тип данных в реляционной модели данных полностью адекватно понятию типа данных в языках программирования. Обычно в современных реляционных базах данных допускается хранение символьных, числовых данных, битовых строк, специализированных числовых данных (таких как "деньги"), а также специальных "темпоральных" данных (дата, время, временной интервал). Достаточно активно развивается подход к расширению возможностей реляционных систем абстрактными типами данных (соответствующими возможностями обладают, например, системы семейства Ingres/Postgres). В нашем примере мы имеем дело с данными трех типов: строки символов, целые числа и "деньги".
Домен Понятие домена более специфично для баз данных, хотя и имеет некоторые аналогии с подтипами в некоторых языках программирования. В самом общем виде домен определяется заданием некоторого базового типа данных, к которому относятся элементы домена, и произвольного логического выражения, применяемого к элементу типа данных. Если вычисление этого логического выражения дает результат "истина", то элемент данных является элементом домена. Наиболее правильной интуитивной трактовкой понятия домена является понимание домена как допустимого потенциального множества значений данного типа. Например, домен "Имена" в нашем примере определен на базовом типе строк символов, но в число его значений могут входить только те строки, которые могут изображать имя (в частности, такие строки не могут начинаться с мягкого знака). Следует отметить также семантическую нагрузку понятия домена: данные считаются сравнимыми только в том случае, когда они относятся к одному домену. В нашем примере значения доменов "Номера пропусков" и "Номера групп" относятся к типу целых чисел, но не являются сравнимыми. Заметим, что в большинстве реляционных СУБД понятие домена не используется, хотя в Oracle V.7 оно уже поддерживается. Кортеж, отношение Кортеж, соответствующий данной схеме отношения в базе данных, - это множество пар {имя атрибута, значение}, которое содержит одно вхождение каждого имени атрибута, принадлежащего схеме отношения. "Значение" является допустимым значением домена данного атрибута (или типа данных, если понятие домена не поддерживается). Тем самым, степень или "арность" кортежа, т.е. число элементов в нем, совпадает с "арностью" соответствующей схемы отношения. Попросту говоря, кортеж - это набор именованных значений заданного типа. Отношение - это множество кортежей данной базы данных, соответствующих одной схеме отношения. Иногда, чтобы не путаться, говорят "отношение-схема" и "отношение-экземпляр", иногда схему отношения называют заголовком отношения, а отношение как набор кортежей - телом отношения. На самом деле, понятие схемы отношения в базе данных ближе всего к понятию структурного типа данных в языках программирования. Было бы вполне логично разрешать отдельно определять схему отношения, а затем одно или несколько отношений с данной схемой. Однако в реляционных базах данных это не принято. Имя схемы отношения в таких базах данных всегда совпадает с именем соответствующего отношения-экземпляра. В классических реляционных базах данных после определения схемы базы данных изменяются только отношения-экземпляры. В них могут появляться новые и удаляться или модифицироваться существующие кортежи. Однако во многих реализациях допускается и изменение схемы базы данных: определение новых и изменение существующих схем отношения. Это принято называть эволюцией схемы базы данных. Обычным житейским представлением отношения является таблица, заголовком которой является схема отношения, а строками - кортежи отношения-экземпляра; в этом случае имена атрибутов именуют столбцы этой таблицы. Поэтому иногда говорят "столбец таблицы", имея в виду "атрибут отношения". Когда мы перейдем к рассмотрению практических вопросов организации реляционных баз данных и средств управления этими базами данных, мы будем использовать эту житейскую терминологию. Этой терминологии придерживаются в большинстве коммерческих реляционных систем управления базами данных. Реляционная база данных - это набор отношений, имена которых совпадают с именами схем отношений в схеме базы данных. Как видно, основные структурные понятия реляционной модели данных (если не считать понятия домена) имеют очень простую интуитивную интерпретацию, хотя в теории реляционных баз данных все они определяются абсолютно формально и точно. Индексы. Индекс, как и ключ, строится по полям таблицы, однако он может допускать повторение значений составляющих его полей. Поля, по которым построен индекс, называют индексными. Простой индекс состоит из одного поля, а составной (сложный) — из нескольких полей. Использование индекса обеспечивает: 1) увеличение скорости доступа (поиска) к данным; 2) сортировку записей; 3) установление связи между таблицами БД; 4) использование ограничений ссылочной целостности. Использование индекса повышает скорость доступа к данным в таблице на основе того, что доступ выполняется не последовательным, а индексно-последовательным методом. Аномалии обновления Даже одного взгляда на таблицу отношения СОТРУДНИКИ_ОТДЕЛЫ_ПРОЕКТЫ достаточно, чтобы увидеть, что данные хранятся в ней с большой избыточностью. Во многих строках повторяются фамилии сотрудников, номера телефонов, наименования проектов. Кроме того, в данном отношении хранятся вместе независимые друг от друга данные - и данные о сотрудниках, и об отделах, и о проектах, и о работах по проектам. Пока никаких действий с отношением не производится, это не страшно. Но как только состояние предметной области изменяется, то, при попытках соответствующим образом изменить состояние базы данных, возникает большое количество проблем. Исторически эти проблемы получили название аномалии обновления. Попытки дать строгое понятие аномалии в базе данных не являются вполне удовлетворительными [51, 7]. В данных работах аномалии определены как противоречие между моделью предметной области и физической моделью данных, поддерживаемых средствами конкретной СУБД. "Аномалии возникают в том случае, когда наши знания о предметной области оказываются, по каким-то причинам, невыразимыми в схеме БД или входящими в противоречие с ней" [7]. Мы придерживаемся другой точки зрения, заключающейся в том, что аномалий в смысле определений упомянутых авторов нет, а есть либо неадекватность модели данных предметной области, либо некоторые дополнительные трудности в реализации ограничений предметной области средствами СУБД. Более глубокое обсуждение проблемы строгого определения понятия аномалий выходит за пределы данной работы. Таким образом, мы будем придерживаться интуитивного понятия аномалии как неадекватности модели данных предметной области, (что говорит на самом деле о том, что логическая модель данных попросту неверна!) или как необходимости дополнительных усилий для реализации всех ограничений определенных в предметной области (дополнительный программный код в виде триггеров или хранимых процедур). Т.к. аномалии проявляют себя при выполнении операций, изменяющих состояние базы данных, то различают следующие виды аномалий: · Аномалии вставки (INSERT) · Аномалии обновления (UPDATE) · Аномалии удаления (DELETE) В отношении СОТРУДНИКИ_ОТДЕЛЫ_ПРОЕКТЫ можно привести примеры следующих аномалий:
Аномалии вставки (INSERT) В отношение СОТРУДНИКИ_ОТДЕЛЫ_ПРОЕКТЫ нельзя вставить данные о сотруднике, который пока не участвует ни в одном проекте. Действительно, если, например, во втором отделе появляется новый сотрудник, скажем, Пушников, и он пока не участвует ни в одном проекте, то мы должны вставить в отношение кортеж (4, Пушников, 2, 33-22-11, null, null, null). Это сделать невозможно, т.к. атрибут Н_ПРО (номер проекта) входит в состав потенциального ключа, и, следовательно, не может содержать null-значений. Точно также нельзя вставить данные о проекте, над которым пока не работает ни один сотрудник. Причина аномалии - хранение в одном отношении разнородной информации (и о сотрудниках, и о проектах, и о работах по проекту). Вывод - логическая модель данных неадекватна модели предметной области. База данных, основанная на такой модели, будет работать неправильно.
Аномалии удаления (DELETE) При удалении некоторых данных может произойти потеря другой информации. Например, если закрыть проект "Космос" и удалить все строки, в которых он встречается, то будут потеряны все данные о сотруднике Петрове. Если удалить сотрудника Сидорова, то будет потеряна информация о том, что в отделе номер 2 находится телефон 33-22-11. Если по проекту временно прекращены работы, то при удалении данных о работах по этому проекту будут удалены и данные о самом проекте (наименование проекта). При этом если был сотрудник, который работал только над этим проектом, то будут потеряны и данные об этом сотруднике. Причина аномалии - хранение в одном отношении разнородной информации (и о сотрудниках, и о проектах, и о работах по проекту). Вывод - логическая модель данных неадекватна модели предметной области. База данных, основанная на такой модели, будет работать неправильно.
Функциональные зависимости Отношение СОТРУДНИКИ_ОТДЕЛЫ_ПРОЕКТЫ находится в 1НФ, при этом, как было показано выше, логическая модель данных не адекватна модели предметной области. Таким образом, первой нормальной формы недостаточно для правильного моделирования данных. Таблица 3 Отношение ПРОЕКТЫ Отношение ЗАДАНИЯ (Н_СОТР, Н_ПРО, Н_ЗАДАН): Функциональные зависимости: { Н_СОТР, Н_ПРО }
Таблица 4 Отношения ЗАДАНИЯ
Таблица 5 Отношение СОТРУДНИКИ Отношение ОТДЕЛЫ (Н_ОТД, ТЕЛ): Функциональные зависимости: Зависимость номера телефона от номера отдела: Н_ОТД
Таблица 6 Отношение ОТДЕЛЫ Обратим внимание на то, что атрибут Н_ОТД, не являвшийся ключевым в отношении СОТРУДНИКИ_ОТДЕЛЫ, становится потенциальным ключом в отношении ОТДЕЛЫ. Именно за счет этого устраняется избыточность, связанная с многократным хранением одних и тех же номеров телефонов. Вывод. Таким образом, все обнаруженные аномалии обновления устранены. Реляционная модель, состоящая из четырех отношений СОТРУДНИКИ, ОТДЕЛЫ, ПРОЕКТЫ, ЗАДАНИЯ, находящихся в третьей нормальной форме, является адекватной описанной модели предметной области, и требует наличия только тех триггеров, которые поддерживают ссылочную целостность. Такие триггеры являются стандартными и не требуют больших усилий в разработке. Общая характеристика языка Язык SQL предназначен для выполнения операций над таблицами (создание, удаление, изменение структуры) и над данными таблиц (выборка, изменение, добавление и удаление), а также некоторых сопутствующих операций. SQL является непроцедурным языком и не содержит операторов управления, организации подпрограмм, ввода- вывода и т.п. В связи с этим SQL автономно не используется, обычно он погружен в среду встроенного языка программирования СУБД (например, FoxPro СУБД Visual FoxPro, ObjectPAL СУБД Paradox, Visual Basic for Applications СУБД Access). В современных СУБД с интерактивным интерфейсом можно создавать запросы, используя другие средства, например QBE. Однако применение SQL зачастую позволяет повысить эффективность обработки данных в базе. Например, при подготовке запроса в среде Access можно перейти из окна Конструктора запросов (формулировки запроса по образцу на языке QBE) в окно с эквивалентным оператором SQL. Подготовку нового запроса путем редактирования уже имеющегося в ряде случае проще выполнить путем изменения оператора SQL. В различных СУБД состав операторов SQL может несколько отличаться. Язык SQL не обладает функциями полноценного языка разработки, а ориентирован на доступ к данным, поэтому его включают в состав средств разработки программ. В этом случае его называют встроенным SQL. Стандарт языка SQL поддерживают современные реализации следующих языков программирования: PL/1, Ada, С, COBOL, Fortran, MUMPS и Pascal. В специализированных системах разработки приложений типа клиент-сервер среда программирования, кроме того, обычно дополнена коммуникационными средствами (установление и разъединение соединений с серверами БД, обнаружение и обработка возникающих в сети ошибок и т.д.), средствами разработки пользовательских интерфейсов, средствами проектирования и отладки. Различают два основных метода использования встроенного SQL: статический и динамический. При статическом использовании языка (статический SQL) в тексте программы имеются вызовы функций языка SQL, которые жестко включаются в выполняемый модуль после компиляции. Изменения в вызываемых функциях могут быть на уровне отдельных параметров вызовов с помощью переменных языка программирования. При динамическом использовании языка (динамический SQL) предполагается динамическое построение вызовов SQL-функций и интерпретация этих вызовов, например, обращение к данным удаленной базы, в ходе выполнения программы. Динамический метод обычно применяется в случаях, когда в приложении заранее неизвестен вид SQL- вызова и он строится в диалоге с пользователем. Основным назначением языка SQL (как и других языков для работы с базами данных) является подготовка и выполнение запросов. Состав языка SQL. Язык SQL SQL (обычно произносимый как "СИКВЭЛ" или "ЭСКЮЭЛЬ") символизирует собой Структурированный Язык Запросов. Это - язык, который дает Вам возможность создавать и работать в реляционных базах данных, являющихся наборами связанной информации, сохраняемой в таблицах. Информационное пространство становится более унифицированным. Это привело к необходимости создания стандартного языка, который мог бы использоваться в большом количестве различных видов компьютерных сред. Стандартный язык позволит пользователям, знающим один набор команд, использовать их для создания, нахождения, изменения и передачи информации - независимо от того, работают ли они на персональном компьютере, сетевой рабочей станции, или на универсальной ЭВМ. Стандарт SQL определяется ANSI (Американским Национальным Институтом Стандартов) и в данное время также принимается ISO (Международной Организацией по Стандартизации). Однако, большинство коммерческих программ баз данных расширяют SQL без уведомления ANSI, добавляя различные особенности в этот язык, которые, как они считают, будут весьма полезны. Иногда они несколько нарушают стандарт языка, хотя хорошие идеи имеют тенденцию развиваться и вскоре становиться стандартами " рынка " сами по себе в силу полезности своих качеств. Состав языка SQL Язык SQL предназначен для манипулирования данными в реляционных базах данных, определения структуры баз данных и для управления правами доступа к данным в многопользовательской среде. Поэтому, в язык SQL в качестве составных частей входят:
Подчеркнем, что это не отдельные языки, а различные команды одного языка. Такое деление проведено только лишь с точки зрения различного функционального назначения этих команд. Язык манипулирования данными используется, как это следует из его названия, для манипулирования данными в таблицах баз данных. Он состоит из 4 основных команд:
Язык определения данных используется для создания и изменения структуры базы данных и ее составных частей - таблиц, индексов, представлений (виртуальных таблиц), а также триггеров и сохраненных процедур. Основными его командами являются:
Язык управления данными используется для управления правами доступа к данным и выполнением процедур в многопользовательской среде. Более точно его можно назвать "язык управления доступом". Он состоит из двух основных команд:
С точки зрения прикладного интерфейса существуют две разновидности команд SQL:
Интерактивный SQL используется в специальных утилитах (типа WISQL или DBD), позволяющих в интерактивном режиме вводить запросы с использованием команд SQL, посылать их для выполнения на сервер и получать результаты в предназначенном для этого окне. Встроенный SQL используется в прикладных программах, позволяя им посылать запросы к серверу и обрабатывать полученные результаты, в том числе комбинируя set-ориентированный и record-ориентированный подходы. Важное значение имеют разновидности инструкции SELECT—SELECT... INTO... (выбрать из одной или нескольких таблиц набор записей, из которого создать новую таблицу) и UNION SELECT, которая в дополнении с исходной инструкцией SELECT (SELECT... UNION SELECT...) реализует операцию объединения таблиц. Помимо предложения CONSTRAINT в SQL-инструкциях используются следующие предложения: FROM... — указывает таблицы или запросы, которые содержат поля, перечисленные в инструкции SELECT; WHERE ... — определяет, какие записи из таблиц, перечисленных в предложении FROM, следует включить в результат выполнения инструкции SELECT, UPDAТЕ или DELETE; GROUP BY ... — объединяет записи с одинаковыми значениями в указанном списке полей в одну запись; НАVING ... — определяет, какие сгруппированные записи отображаются при использовании инструкции SELECT спредложением GROUPBY; IN ... — определяет таблицы в любой внешней базе данных, с которой ядро СУБД может установить связь; ORDER BY ... — сортирует записи, полученные в результате запроса, в порядке возрастания или убывания на основе значений указанного поля или полей. В качестве источника данных по предложению FROM, помимо таблиц и запросов, могут использоваться также результаты операций соединения таблиц в трех разновидностях— INNER JOIN... ON..., LEFT JOIN. .. ON... и RIGHT JOIN...ON... (внутреннее соединение, левое и правое внешнее соединение, соответственно*). Предикаты используются для задания способов и режимов использования записей, отбираемых на основе условий в инструкции SQL. Такими предикатами являются: ALL ... — отбирает все записи, соответствующие условиям, заданным в инструкции SQL, используется по умолчанию; DISTINCT ... — исключает записи, которые содержат повторяющиеся значения в выбранных полях; DISTINCTROW ... — опускает данные, основанные на целиком повторяющихся записях, а не на отдельных повторяющихся полях; ТОРп... — возвращает п записей, находящихся в начале или в конце диапазона, описанного с помощью предложения ORDER BY; &nbs
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-01-25; просмотров: 2055; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.14.245.172 (0.016 с.) |





















 Н_ЗАДАН
Н_ЗАДАН


