
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Вычисление среднего возраста посетителей библиотекиСодержание книги
Поиск на нашем сайте
Среднее обладает рядом важных свойств. В частности, если сложить все значения отклонений от среднего значения, т. е. разности между X и X 1 X2... X i(которые могут быть и положительными, и отрицательными), то сумма отклонений будет равна нулю. Кроме того, сумма квадратов отклонений наблюдаемых значений от их арифметического среднего меньше суммы квадратов отклонений от любой другой точки[28]. Эти свойства среднего определяют его уникальную роль в решении ряда статистических задач, о которых мы будем говорить ниже. Сейчас достаточно отметить то обстоятельство, что при использовании среднего в качестве «представителя» (т. е. статистической оценки) каждого из наблюдаемых значений, ошибка, определяемая как сумма квадратов отклонений, будет минимальной. Не стоит, однако, забывать о том, что и минимальная ошибка может быть достаточно большой. Так, для малых выборок, имеющих более чем одну моду, любая мера центральной тенденции, включая среднее, будет недостаточно хороша. Центральной тенденции в таком распределении просто не существует. Выбирая меру центральной тенденции, нужно руководствоваться знанием ее свойств, общей формой распределения и, наконец, здравым смыслом. Если при взгляде на гистограмму исследователь обнаруживает, что имеет дело сунимодальным симметричным распределением (половины гистограммы слева и справа от модального значения зеркально совпадают), то среднее, медиана и мода будут равны между собой. Если речь идет о выборке из большой совокупности, где интересующая исследователя переменная-признак распределена нормально (т.е. большие и малые крайние значения встречаются редко, а средние — часто), наилучшим показателем будет среднее. Если в унимодальном распределении встречаются крайние значения, могущие значительно повлиять на среднее (см. пример с возрастом, табл. 8.2), нужно отдать предпочтение медиане. Вопрос о сравнимости средних значений не так тривиален, как это может показаться. Сравнение значений средних показателей для различных выборок или для одной и той же выборки в разные моменты времени — весьма распространенный способ анализа результатов. Не только в научных журналах, но и в газетах мы постоянно находим сведения о сравнительной величине душевого дохода в разных регионах, о различиях в среднем числе автомобилей, приходящихся на одну семью и т. п. Следует, однако, помнить о том, что заведомо некорректны сравнения различных мер центральной тенденции, например медианы и среднего. Причина здесь в том, что различные меры описывают разные характеристики распределения: медиана — среднее положение, мода — самое часто встречающееся значение и т. д. Кроме того, даже две одинаковые меры центральной тенденции не всегда сравнимы. Средние двух распределений имеет смысл сравнивать лишь в том случае, если во всех других отношениях распределения одинаковы, имеют сходную форму. Если исследователь говорит о равенстве средних значений, забыв упомянуть о том, что одно распределение симметрично, а другое — скошено вправо или влево из-за присутствия очень больших либо очень малых значений в его «хвостовых» частях, то он подталкивает читателя к заведомо неверному выводу о том, что анализируемая переменная распределена в двух выборках совершенно одинаково. Среднее распределения с очень длинным правым «хвостом» может оказаться равным среднему распределения, скошенного влево, где встречаются крайне малые значения признака. Но этим сходство будет исчерпываться: что общего (кроме величины среднего) у группы, включающей много людей с очень низким доходом, коэффициентом интеллекта и т. п., с другой группой, включающей много наблюдений с очень высокими значениями переменной-признака? Очевидно, важно не только знать, что типично для выборки наблюдений, но и установить, насколько выражены отклонения от типичных значений. Чтобы определить, насколько хорошо та или иная мера центральной тенденции описывает распределение, нужно воспользоваться какой-либо мерой изменчивости, разброса. Самая грубая мера изменчивости — размах (диапазон) значений. Эта мера не учитывает индивидуальные отклонения значений, описывая лишь диапазон их изменчивости. Под размахом понимают разность между максимальным и минимальным наблюдаемым значением. Если количество карманных денег в группе из десяти субъектов варьирует от 100 рубл. (1 человек) до 100000 рубл. (2 человека), размах будет равен 100000-100 = 99900. Еще одна грубая мера разброса значений — это коэффициент вариации (V), который определяется просто как процент наблюдений, лежащих вне модального интервала, т. е. процент (доля) наблюдений, не совпадающих с модальным значением. Если от модального отличаются 60% значений, то V = 60% (или V = 0,6). Рассказывая о процедуре построения шкалы Терстоуна, мы описали, как вычислить междуквартилъный размах — очень удобный показатель разброса значений для ординальной переменной. Напомним, что нижний, первый, квартиль (Q 1 ) отсекает 25% наблюдений, а ниже третьего квартиля (Q 3) лежат уже 75% случаев. Полумеждуквартилъный размах равен половине расстояния между третьим и первым квартилями:
Если распределение приблизительно симметрично, то можно считать, что полумеждуквартильный размах указывает границы, в которых лежит 50% данных по обе стороны медианы или среднего. Все эти меры изменчивости, как уже говорилось, можно считать скорее грубыми и приблизительными. Ни одна из них не уделяет должного внимания информации об отклонениях каждого отдельного наблюдаемого значения от среднего, хотя эта информация в большинстве случаев может быть получена из анализа распределения. Информацию о вариации некоторой совокупности значений относительно среднего несут значения отклонений от среднего, о которых мы уже говорили. Однако, просуммировав все значения отклонения (
Рис. 17. Распределение, скошенное вправо
Именно так и получают важнейшую меру рассеяния — дисперсию (s2). Если
Для того чтобы вычислить значение дисперсии, нужно вычесть из каждого наблюдаемого значения среднее, возвести в квадрат все полученные отклонения, сложить квадраты отклонений и разделить полученную сумму на объем выборки.
Стандартные отклонения Рис. 18. Определение площади нормальной кривой для разных значений стандартного отклонения
Величина, равная квадратному корню из дисперсии, называется стандартным отклонением (s x), т.е.:
Совершенно очевидной интерпретацией стандартного отклонения является его способность оценивать «типичность» среднего: стандартное отклонение тем меньше, чем лучше среднее суммирует, «представляет» данную совокупность наблюдений. Еще одно важное применение стандартного отклонения связано с тем, что оно, наряду со средним арифметическим, позволяет определить самые существенные характеристики нормального распределения. Графически нормальному распределению частот наблюдений соответствует, как известно, симметричная колоколообразная кривая. Свойства нормального распределения прекрасно изучены, что позволяет делать важные выводы относительно самых разных распределений, не обязательно нормальных. В частности, известно, что 68% наблюдений (точнее, 68% общей площади) будет заключено в пределах ±1 стандартное отклонение от среднего значения. Если, скажем, среднее нормального распределения равно 200, а стандартное отклонение — 4, то можно заключить, что не менее 68% наблюдений лежит между значениями 196 и 204 (т. е. 200 ±4). Соответственно не менее 32% случаев будут лежать за этими пределами, в левом и правом «хвостах» распределения. Из теории вероятности известно также, что в пределах ±3 стандартных отклонений окажется около 99,73% общего числа наблюдений (см. рис. 18). Для любого унимодального симметричного распределения, даже если оно отличается от нормального, не менее 56% наблюдений будут попадать в промежуток ±1 стандартное отклонение от среднего арифметического значения, для ±3 стандартных отклонений внутри указанного интервала окажутся не менее 95% наблюдений. Очевидно, что стандартное отклонение — это прекрасный показатель положения любого конкретного значения относительно среднего, поэтому часто возникает необходимость выразить «сырые» оценки (баллы теста, величины дохода и т. п.) в единицах стандартного отклонения от среднего. Получаемые в результате оценки называют стандартными, или Z-оценками. Для любой совокупности из N наблюдений распределение со средним X и стандартным отклонением 5 можно преобразовать в распределение со средним, равным 0, и стандартным отклонением, равным 1. Преобразованные таким образом индивидуальные значения будут непосредственно выражаться в отклонениях «сырых» значений от среднего, измеренных в единицах стандартного отклонения. Чтобы осуществить такое преобразование, нужно из каждого значения X вычесть среднее и разделить полученную величину на стандартное отклонение, т. е. Z-оценки получают по простой формуле:
Использование Z-оценок не сводится к описанию положения некоторого значения относительно среднего в масштабе единиц стандартного отклонения. Стандартные оценки позволяют перейти от множества «сырых» значений к произвольной шкале с удобными для расчетов характеристиками среднего и стандартного отклонения. Домножая Z на константу с, мы можем получить распределение со стандартным отклонением (s x ). Множество данных можно расположить на любой шкале с удобным средним (например, равным 100, как во многих тестах интеллекта) и стандартным отклонением. Другие применения Z-оценок связаны со сложными методами анализа данных, о которых мы будем говорить в дальнейшем. Описанные процедуры анализа одномерного распределения относятся к дескриптивной статистике. Если мы стремимся обобщить данные, полученные на отдельных выборках, чтобы описать свойства исходной генеральной совокупности, необходимо, как уже говорилось, обратиться к методам индуктивной статистики, к теории статистического вывода. Переход от числовых характеристик выборки к числовым характеристикам генеральной совокупности называется оцениванием. При одномерном анализе данных чаще всего решают задачу интервального оценивания. Если переменная измерена на уровне не ниже интервального (доход, продолжительность образования и т. п.), мы легко можем получить выборочную оценку среднего. Но как узнать, насколько близка наша выборочная оценка, например, дохода, к истинному значению этого параметра, которое мы получили бы, располагая возможностью обследовать всю совокупность? Если наша выборка была случайной, на этот вопрос можно ответить. Чтобы перейти от выборочной оценки (статистики) к характеристике генеральной совокупности (параметру), можно, в частности, определить числовой интервал, в который с заданной вероятностью «укладывается» интересующий нас параметр. Чтобы понять идею интервального оценивания, достаточно вспомнить о том, что оценки, получаемые для множества выборок из одной совокупности, будут также распределены нормально, т. е. большая их часть будет попадать в область, близкую к истинному среднему, и лишь немногие окажутся в «хвостах» распределения, отклоняясь от этого значения. Для любой отдельно взятой выборки шансы оказаться близко к параметру совокупности значительно выше вероятности оказаться в «хвосте». Чтобы оценить степень этой близости, используют очень важную величину — стандартную ошибку средней. Стандартную ошибку обозначают как S М,
где sх — это стандартное отклонение, а N — объем выборки. Подсчитав эту величину для наших данных, мы всегда можем определить с заданной вероятностью, в каких пределах будет лежать среднее совокупности. Совершенно аналогично приведенным выше рассуждениям для среднего отклонения можно сказать, что 95% выборочных средних будет лежать в пределах ±2 стандартные ошибки среднего генеральной совокупности (т. е. для 95 выборок из 100 выборочное среднее попадет в указанный интервал). Следовательно, любая конкретная единичная выборка, использованная в данном исследовании, с 95%-й вероятностью даст оценку, лежащую в интервале ±2 стандартных ошибок среднего совокупности. Заданный таким образом интервал для выборочных оценок называется доверительным интервалом, а та вероятность, с которой мы «попадаем» в этот интервал (например, 95% или 99%), называется доверительной вероятностью. Если, например, мы рассчитали, что для случайной выборки горожан средняя квартирная плата составляет 20000 рублей, а стандартная ошибка — 500 рублей, то можно с 95-процентной уверенностью утверждать, что для всех горожан средняя квартплата окажется в интервале 19000—21000 рублей. Задав интервал в 3 стандартные ошибки, мы сможем достичь уровня доверительной вероятности, равного 99,73% (см. рис. 18). Полезно помнить о том, что чем больше используемая выборка (чем больше N), тем меньше будет sm (см. формулу) и, следовательно, тем уже будет доверительный интервал. Задачу интервального оценивания можно решить и для тех переменных, уровень измерения которых ниже интервального. Для этого в статистике используют свойства другого распределения — биноминального. Здесь мы не будем анализировать эти свойства. Достаточно отметить, что биномиальным называют распределение исхода событий, которые могут случиться или не случиться, т.е. в общей форме могут быть классифицированы как положительные или отрицательные. При этом наступление одного события автоматически означает, что другое не случилось. Степень интенсивности события (признака) просто не принимается в расчет. Классический пример — бросание монеты, которая может выпасть «орлом» или «решкой». Чтобы использовать это распределение для интервального оценивания, нужно превратить анализируемую переменную в дихотомическую, имеющую две категории (если, конечно, она таковой не являлась с самого начала). Примеры дихотомических переменных — пол, голосование «за» или «против» и т. п. Для дихотомической переменной стандартную ошибку можно вычислить по формуле:
где Sbin — стандартная ошибка для биномиального распределения, Р — процент наблюдений в первой категории, Q — процент наблюдений во второй категории, N — объем выборки. Если, например, нас интересует, насколько близок к истинному значению для генеральной совокупности тот процент ответов, который мы получили при опросе некоторой выборки, мы снова можем использовать интервальную оценку. Пусть, например, в выборке объемом 1000 человек 60% высказались против призыва студентов на воинскую службу, а 40% — за. Стандартная ошибка составит:
Если добавить (и отнять) 2 стандартные ошибки[31] к полученной выборочной оценке, можно построить доверительный интервал, в который интересующая нас величина попадет с 95%-й вероятностью (т. е. вероятность ошибки не превысит 5%). С вероятностью 95% доля противников обязательного призыва студентов составит 60±3,1%.
|
||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-12-13; просмотров: 249; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.222.113.226 (0.01 с.) |


 (где i = 1...7 — число различных значений)
(где i = 1...7 — число различных значений)

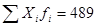

 ), мы получим нуль. Положительные и отрицательные отклонения будут взаимоуничтожаться. Если же мы возведем в квадрат каждое отклонение и просуммируем квадраты отклонений, то мы получим хорошую меру рассеяния, которая будет маленькой, когда данные однородны, и большой, когда данные неоднородны. Чтобы суммы квадратов отклонений для выборок разного размера можно было сравнивать, нужно поделить каждую из них на N, где N — объем выборки[29].
), мы получим нуль. Положительные и отрицательные отклонения будут взаимоуничтожаться. Если же мы возведем в квадрат каждое отклонение и просуммируем квадраты отклонений, то мы получим хорошую меру рассеяния, которая будет маленькой, когда данные однородны, и большой, когда данные неоднородны. Чтобы суммы квадратов отклонений для выборок разного размера можно было сравнивать, нужно поделить каждую из них на N, где N — объем выборки[29].










