Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Краткий Обзор статистических программных продуктовСодержание книги
Поиск на нашем сайте
МЕТОДИЧЕСКИЕ УКАЗАНИЯ
к практическим занятиям по дисциплине «СТАТИСТИКА» для студентов всех форм обучения спец. 06.11.00 «Менеджмент» (Корреляционно-регрессионный анализ статистических связей на персональном компьютере)
Калининград Статистика:Методические указания к практическим занятиям по дисциплине «СТАТИСТИКА» для студентов всех форм обучения спец. 06.11.00 «Менеджмент» (Корреляционно-регрессионный анализ статистических связей на персональном компьютере) /Калинингр. ун-т – Сост. Н.Ю. Лукьянова.- Калининград, 1999. - с.
Методические указания разработаны в соответствии с учебным планом специальности «Менеджмент»; содержат основные теоретические положения корреляционно-регрессионного анализа, общие рекомендации по автоматизированному решению соответствующих задач, вопросы для самопроверки, список рекомендуемой литературы.
Составитель: канд.экон.наук, ст. преподаватель Н.Ю. Лукьянова
Резензент: д.э.н., професор кафедры экономико-математических методов и статистики С.-Петербургского государственного аграрного университета М.М.Юзбашев.
ã Калининградский государственный университет, 1999 СОДЕРЖАНИЕ
Введение 1. Краткий обзор статистических программных продуктов 2. Основные теоретические положения корреляционно-регрессионного анализа статистических связей 2.1. Парная корреляция и регрессия 2.2. Множественная корреляция и регрессия 3. Решение задач корреляционно-регрессионного анализа статистических связей признаков на персональном компьютере в среде пакета STATISTICA 3.1. Общие сведения об интегрированном статистическом пакете общего назначения STATISTICA 3.2. Пример решения задачи 3.3. Порядок выполнения индивидуального задания 4. Вопросы для самопроверки Список рекомендуемой литературы Приложение 1.Таблица значений F- критерия Фишера Приложение 2. Значения t- критерия Стьюдента
ВВЕДЕНИЕ В условиях рыночной конкуренции процесс подготовки и принятия решений менеджерами компаний должен включать тщательный анализ имеющихся данных, базирующийся на методах математической статистики. В этой связи существенную помощь в получении необходимой информации могут оказать современные информационные технологии интеллектуального и статистического анализа данных. Оценка кредитных и страховых рисков, прогнозирование тенденций на финансовых рынках, оценка объектов недвижимости, построение профилей потенциальных покупателей определенного товара, анализ продуктовой корзины - вот далеко не полный перечень задач успешно решаемых с помощью систем интеллектуального и статистического анализа данных.
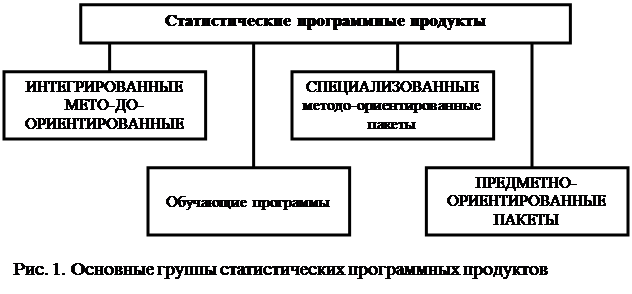
Системы интеллектуального анализа предназначены для автоматизированного поиска ранее неизвестных закономерностей в имеющихся в распоряжении менеджера данных с последующим использованием полученной информации для подготовки решений. Помимо статистических методов базовыми инструментами анализа в таких системах являются нейронные сети, деревья решений и индукция правил. Однако несмотря на то, что в последние годы рынок программных продуктов этого типа активно развивается, они все еще не доступны по цене предприятиям среднего и малого бизнеса. В то же время компаниям такого размера, как правило, не требуется столь мощный аналитический инструментарий, предлагаемый этими системами. Более доступными средствами анализа данных на сегодняшний день являются статистические программные продукты (СПП). В мировой практике компьютерные системы статистического анализа и обработки данных широко применяются, как в исследовательской работе в области экономики, так и в практической деятельности аналитических, маркетинговых и плановых отделов банков, страховых компаний, производственных и торговых фирм. В последние годы заметно возрос спрос на СПП и в нашей стране. СПП позволяют решить широкий спектр задач «разведочного» анализа данных, статистического исследования зависимостей, планирования экспериментов, анализа временных рядов, анализа данных нечисловой природы и т.д. Настоящие методические разработки посвящены вопросам корреляционно-регрессионного анализа статистических связей с использованием одного из самых популярных в России статистических программных продуктов - пакета STATISTICA, функционирующего в среде Windows. Краткий Обзор статистических программных продуктов Рынок СПП необычайно разнообразен. Существует около тысячи распространяемых на мировом рынке пакетов, решающих задачи статистического анализа данных, в среде DOS, OS/2 или Windows. Можно выделить четыре основные группы статистических пакетов (рис.1).
Остановимся подробнее на методо-ориентированных пакетах (табл.1,/1,2/). Таблица 1. Классификация методо-ориентированных статистических программ
В универсальных пакетах, предлагающих широкий диапазон статистических методов, отсутствует ориентация на конкретную предметную область. Из зарубежных универсальных пакетов наибольшую известность получили компьютерные системы SAS, SPSS, SYSTAT, Minitab, Statgraphics, Statistica. Специализированные пакеты, как правило, содержат несколько статистических методов или методы, применяемые в конкретной предметной области. Чаще всего это системы ориентированные на анализ временных рядов, корреляционно-регрессионный, факторный или кластерный аннализ. «Полу-специализированными» и «полу-универсальными» можно считать российские пакеты STADIA, ОЛИМП и белорусский пакет РОСТАН. К этому же классу следует отнести и американские пакеты ODA, WinSTAT, Statit, UNISTAT, Multivariance 7, JMP, SOLO, STATlab. К специализированным пакетам по классификации и снижению размерности, можно отнести такие отечественные системы, как КЛАСС-МАСТЕР, КВАЗАР, PALMODA, Stat-Media, STARC, а также ряд зарубежных пакетов, например, MVSP. Широко известны пакеты, решающие смежные с классификацией задачи: американские системы BMDP/W, SigmaStat, Statistix, TURBO Spring-Stat-Win, а также отечественный пакет «Статистик-Консультант для Windows». Кроме того, на рынке имеются статистические экспертные системы, например, СТАТЭКС, Statistical Navigator Pro. Среди нестатистических пакетов, решающих задачи классификации, можно отметить пакеты PolyAnalyst, ДА-система, АРГОНАВТ, ЛОРЕГ, пакет ОТЭКС и разнообразные нейросетевые пакеты. В состав методо-ориентированных СПП могут входить следующие функциональные блоки. I. Блок описательной статистики и разведочного анализа исходных данных предусматривает: Ø анализ смешанной природы многомерного признака и унификация записи исходных данных; Ø анализ резко выделяющихся наблюдений; Ø восстановление пропущенных наблюдений; Ø проверку статистической независимости наблюдений; Ø определение основных числовых характеристик и частотную обработку исходных данных (построение гистограмм, полигонов частот, вычисление выборочных средних, дисперсий); Ø статистическое оценивание параметров;
Ø вычисление модельных законов распределения вероятностей (нормального, биномиального, Пуассона, хи-квадрат и др.); Ø визуализацию анализируемых многомерных статистических данных и др. II. Блок статистического исследования зависимостей предполагает: Ø корреляционно-регрессионный анализ; Ø дисперсионный и ковариационный анализ; Ø планирование регрессионных экспериментов и выборочных обследований; Ø анализ временных рядов (предварительный анализ временных рядов; выявление тренда временного ряда; выявление скрытых периодичностей, спектральный анализ временного ряда, анализ случайных остатков временного ряда; проверка статистических гипотез: о стационарности ряда, о независимости его членов, об адекватности «подгоняемой» модели) и др. III. Блок классификации и снижения размерности включает: Ø дискриминантный анализ; Ø статистический анализ смесей распределений; Ø кластер-анализ; Ø снижение размерности в соответствии с критериями внешней информативности и автоинформативности и некоторые др. IV. Блок методов статистического анализа нечисловой информации и экспертных оценок. Среди используемого в этом блоке математико-статистического инструментария: анализ таблиц сопряженности, лог-линейные модели, субъективные вероятности, логит- и пробит-анализ, ранговые методы и т.п. V. Блок планирования эксперимента и выборочных обследований VI. Блок вспомогательных программ предусматривает: статистическое моделирование на ЭВМ, включая генерирование одномерных и многомерных наблюдений, «извлеченных» из генеральных совокупностей заданного типа. Одним из наиболее динамично развивающихся универсальных методо-ориентированных статистических пакетов является система Statistica для Windows (далее STATISTICA) американской фирмы StatSoft (http://www.statsoft.com). По результатам многочисленных рейтингов STATISTICA стала мировым лидером на рынке СПП и вошла в число 100 лучших программных продуктов (Windows Magazin, февраль 1995), а также занимает первое место среди СПП по результатам последнего рейтинга (BYTE, сентябрь 1998)
Вывод результатов анализа Вывести результаты анализа можно одним из следующих способов. Ø Численные результаты статистического анализа в системе STATISTICA выводятся в виде специальных электронных таблиц, которые называются таблицами вывода результатов — Scrollsheets ™. Таблицы Scrollsheet могут содержать как числовую, так и текстовую информацию. Обычно даже в результате простейшего статистического анализа выдается большое количество числовой и графической информации. В системе STATISTICA эта информация выводится в виде последовательности, которая состоит из набора таблиц Scrollsheet и графиков.
Ø STATISTICA содержит инструменты для удобного просмотра результатов статистического анализа и их визуализации. Они включают в себя стандартные операции по редактированию таблицы (включая операции над блоками значений, Drag-and-Drop — "Перетащить и опустить", автозаполнение блоков и др.), операции удобного просмотра (подвижные границы столбцов, разделение прокрутки в таблице и др.), доступ к основным статистическим процедурам и графическим возможностям системы STATISTICA. При выводе целого ряда результатов (например, корреляционной матрицы) STATISTICA отмечает значимые параметры (например, коэффициенты корреляции) красным цветом. Ø Если пользователю необходимо провести детальный статистический анализ промежуточных результатов, то можно сохранить таблицу Scrollsheet в формате файла данных STATISTICA и далее работать с ним, как с обычными данными. Ø Кроме вывода результатов анализа в виде отдельных окон с графиками и таблицами Scrollsheet, в системе STATISTICA имеется возможность создания отчета, в окно которого может быть выведена вся эта информация. Отчет — это документ (в формате RTF), который может содержать любую текстовую или графическую информацию. В пакете STATISTICA имеется возможность автоматического создания отчета (автоотчета). При этом любая таблица Scrollsheet или график могут автоматически быть направлены в отчет через команды меню File/Page/Output Setup (см. рис.3). Таким образом,система STATISTICA работает с следующими типами документов: электронной таблицей Spreadsheet (предназначенной для ввода исходных данных), электронной таблицей Scrollsheet (предназначенной для вывода числовых и текстовых результатов анализа), графиком (предназначенным для визуализации численной информации), отчетом (предназначенным для вывода текстовой и графической информации в формате RTF). ПРИМЕР РЕШЕНИЯ ЗАДАЧИ
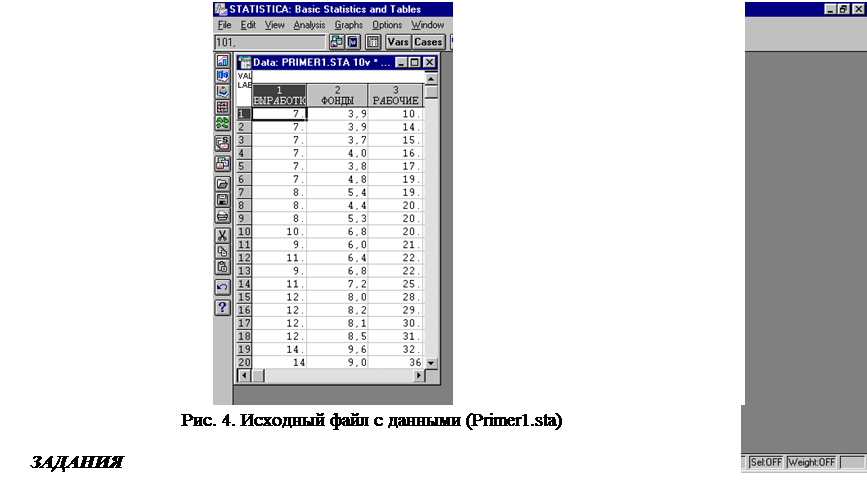
Условие задачи. По 20 предприятиям отрасли изучается зависимость выработки продукции на 1 работника (y), тыс.руб. - " ВЫРАБОТКА " от ввода в действие новых основных фондов в % от стоимости фондов на конец года (x1) - " ФОНДЫ " и от удельного веса рабочих высокой квалификации в общей численности рабочих (x2), % - "РАБОЧИЕ". Данные записаны в файле пакета STATISTICA и представлены на рис.4.
1. Получить дискриптивные статистики по каждому признаку. Оценить показатели вариации каждого признака и сделать вывод о возможностях применения метода наименьших квадратов для их изучения. 2. Составить уравнение множественной регрессии, оценить его параметры, пояснить их экономический смысл. 3. Рассчитать частные коэффициенты эластичности и дать на их основе сравнительную оценку силы влияния факторов на результат. 4. Проанализировать линейные коэффициенты парной и частной корреляции. 5. Оценить значения скорректированного и нескорректированного линейных коэффициентов множественной корреляции.
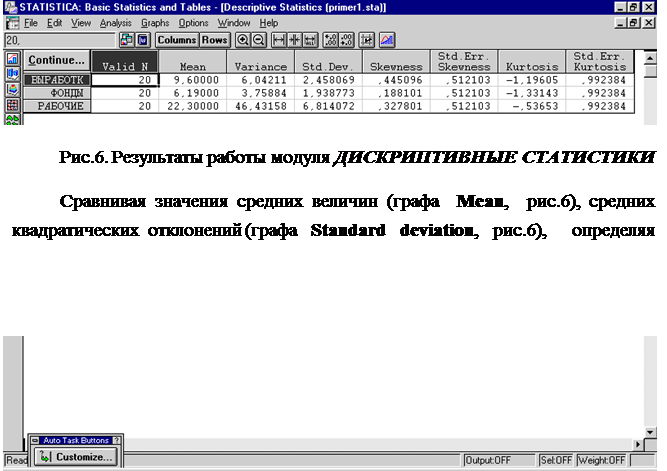
6. С помощью F-критерия Фишера оценить статистическую надежность уравнения регрессии в целом. РЕШЕНИЕ ЗАДАЧИ 1. Для получения дискриптивных статистик необходимо в Переключателе модулей (см. рис.2), появившемся после запуска пакета STATISTICA, выбрать команду Basic Statistics/Tables, при этом на экране появится стартовая панель модуля Основные статистики и таблицы, в которой следует выбрать команду Descriptive statistics. Статистическую обработку данных следует предварить открытием уже существующего файла с данными через команду Open Data (рис.5), или ввести данные в компьютер через команду File/ New Data (рис.4).
Выбрав команду OK, на экране появятся дискриптивные статистики (рис.6), анализ которых следует начать с определения показателей вариации.
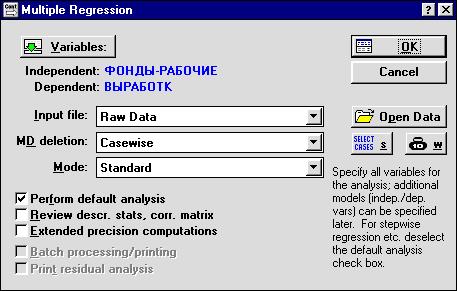
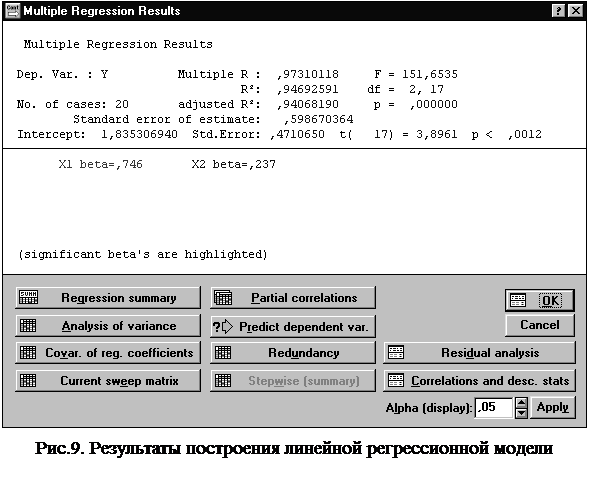
2. Для построения уравнения множественной регрессии необходимо в Переключателе модулей (рис.1) выбрать команду Multiple Regression. При этом на экране появится стартовая панель модуля Множественная регрессия (рис.7).
После выбора команды Variable (рис.7),, следует указать зависимую (ВЫРАБОТКА) и независимые переменные (ФОНДЫ, РАБОЧИЕ). Выбрав команду OK, получаем результаты работы модуля Множественная регрессия (рис.8-9), на основании которых студент строит уравнение линейной множественной регрессии. Свободный член и коэффициенты регрессии представлены в графе B (рис.8): а0 = 1,835; a1 = 0,946; a2 = 0,086. При этом уравнение множественной регрессии примет вид: у =1,835 +0,946 x1+ 0,086x2
Таким образом, статистически значимыми являются коэффициенты а0 и а1, а коэффициент а2 сформирован под влиянием случайных причин. Поэтому фактор x2 можно исключить из модели как неинформативный. Аналогичный вывод можно сделать, сравнивая значения уровня значимости (графа p-level, рис. 8) c принятым нами уровнем a =0,01. Для а0 и а1 показатель вероятности случайных значений параметров регрессии меньше 1% (0,01 • 100%). Поэтому справедлив вывод о том, что полученные коэффициенты статистически значимы и надежны. Для а2 делается вывод о случайной природе его значения, поскольку a =0,175 • 100%=17,5%>1%. Это позволяет рассматривать x2 как неинформативный фактор. Его можно удалить из уравнения для улучшения модели. Свободный член а0 оценивает агрегированное влияние прочих (кроме учтенных в модели x1 и x2) факторов на результат у. Коэффициенты а1 и а2 указывают на то, что с увеличением x1 и x2 на единицу их значений у увеличивается, соответственно, на 0,9459 тыс.руб. и на 0,0856 тыс.руб. Сравнивать эти значения не следует, так как они зависят от единиц измерения каждого признака и потому несопоставимы между собой. Для сравнения можно воспользоваться сравнимыми относительными показателями - b-коэффициентами (графа BETA, рис. 8). 3. Для определения частных коэффициентов эластичности в соответствии с (2.6.) воспользуемся коэффициентами регрессионного уравнения а1 и а2 и значениями средних величин результативного и факторных признаков (графа Mean, рис.6). Ex1 = 0,61 %, Ex2= 0,19 %. Полученные коэффициенты показывают, что с увеличением коэффициента обновления основных фондов (x1) на 1 % от его среднего уровня выработка продукции на 1 работника (y) увеличится на 0,61 %, от своего среднего уровня. Аналогично, с увеличением доли рабочих высокой квалификации в общей численности рабочих (x2) на 1 % от ее среднего уровня выработка продукции на 1 работника (y) увеличится на 0,19 %, от своего среднего уровня. По значениям частных коэффициентов эластичности можно сделать вывод о более сильном влиянии на результат фактора x1 по сравнению с фактором x2. 4. Оценить тесноту парных зависимостей включенных в модель факторов можно через матрицу парных коэффициентов корреляции, а тесноту связи значений двух переменных, исключая влияниевсех других переменных, представленных в уравнении множественной регрессии можно через матрицу линейных коэффициентов частной корреляции. Для построения этих матриц в модуле Множественная регрессия (рис.9) следует последовательно выбрать
команды Correlations and desc.stats (для построения матрицы парных коэффициентов корреляции) Partial correlations (для построения матрицы линейных коэффициентов частной корреляции).
Полученные значения парных коэффициентов корреляции говорят о тесной связи выработки продукции на 1 работника (y) как с коэффициентом обновления основных фондов (x1) - r yx1 = 0,97, так и с долей рабочих высокой квалификации в общей численности рабочих (x2) - r yx2 = 0,94. При этом следует учитывать тесную межфакторную связь x1 с x2 (r x1x2 = 0,94) примерно равную связи y с x2. Поэтому для улучшения модели фактор x2 можно исключить как недостаточно статистически надежный. Коэффициенты частной корреляции дают более точную характеристику тесноты зависимости двух признаков, чем коэффициенты парной корреляции, так как "очищают" парную зависимость от взаимодействия данной пары признаков с другими признаками, представленными в модели. Наиболее тесно показатель выработки продукции на 1 работника (y) связана с коэффициентом обновления основных фондов (x1) - r yx1/ x2 = 0,73 по сравнению со связью y с долей рабочих высокой квалификации в общей численности рабочих (x2) - r yx2/ x1 = 0,32. Этот факт также говорит в пользу исключения фактора x2 из модели. 5. Коэффициенты линейной множественной корреляции (детерминации) представлены на рис.8-9. Коэффициент множественной корреляции R yx1x2 = 0,973 свидетельствует о тесной связи факторных признаков с результативным. Нескорректированный коэффициент множественной детерминации R2 yx1x2 = 0,947 оценивает долю вариации результата за счет представленных в уравнении факторов в общей вариации результата. Он указывает на высокую степень обусловленности вариации результата вариацией факторных признаков. Скорректированный коэффициент множественной детерминации R2 yx1x2 = 0,941 оценивает тесноту связи с учетом степеней свободы (см. п.2.2), что позволяет его использовать для оценки тесноты связи в моделях с разным числом факторов. Значения коэффициентов множественной детерминации позволяют сделать вывод о высокой (более 90%) детерминированности результативного признака y в модели факторными признаками x1 и x2. 6. Оценим статистическую надежность полученного уравнения множественной регрессии с помощью общего F-критерия, который проверяет нулевую гипотезу о статистической незначимости параметров построенного регрессионного уравнения и показателя тесноты связи (H0: a0= a1=a2=0, R yx1x2=0). Фактическое значение F-критерия Фишера - Fр =151,7 (см. рис.8-9). Сравним его с табличным значением F-критерия, определяемым с использованием таблицы приложения 1 по заданным уровню значимости (a = 0,05) и числу степеней свободы (в пакете STATISTICA d.f.1 = m =2 и d.f.2 = n-m-1= 17). Fт = 3,59. Поскольку Fр > Fт, то гипотеза H0 отвергается. Так как вероятность случайного значения Fр значительно меньше 5 % (p<0,000001, см. рис.8-9)., то с вероятностью более чем95 %принимается альтернативная гипотеза. Таким образом признается статистическая значимостьрегрессионного уравнения, его параметров и показателя тесноты связи R yx1x2. 3.3.Порядок выполнения индивидуального задания 1. Ввод исходных данных. Получив индивидуальное задание, студент создает файл с именем *.sta и заносит в него данные. Файл следует сохранить в указанном преподавателем каталоге. 2. Дикриптывно-статистический анализ данных. На данном этапе выполнения работы определяются значения средних величин, средних квадратических отклонений, значения коэффициентов асимметрии, эксцесса и их среднеквадратических ошибок по результативному и факторным признакам. Студенту следует оценить показатели вариации каждого признака и сделать вывод о возможностях применения метода наименьших квадратов для их изучения, а если необходимо, то исключить резко отклоняющиеся единицы совокупности. 3. Построение уравнения множественной регрессии. На этом этапе определяются коэффициенты множественной регрессии, составляется регрессионное уравнение, оцениваются его параметры. 4. Определение частных коэффициентов эластичности. Студент самостоятельно рассчитывает частные коэффициенты эластичности и дает на их основе сравнительную оценку силы влияния факторов на результат. 5. Анализ линейных коэффициентов парной и частной корреляции. Данный этап предусматривает построение матриц коэффициентов парной и частной корреляции и оценку целесообразности включения факторных признаков в модель. 6. Оценка коэффициентов множественной корреляции (детерминации). 7. Оценка статистической надежности полученного уравнения регрессии. 8. Оформление отчета. Титульный лист отчета должен содержать название работы, цель работы, фамилию, инициалы, курс и группу студента, выполнившего индивидуальное задание. В отчете следует отразить основные этапы выполненного задания, полученные результаты и сделать выводы по каждому этапу. Для этой цели можно использовать распечатки отчета, полученного средствами пакета STATISTICA (файл с расширением *.rtf), включая его широкие графические возможности. 9. Защита индивидуального задания. Защита индивидуального задания преследует цель оценить знания студента по вопросам построения регрессионных моделей с помощью СПП STATISTICA и интерпретации результатов корреляционно-регрессионного анализа данных. При подготовке к защите индивидуального задания студенту следует ответить на представленные в п.4 вопросы. Вопросы для самопроверки 1. Дайте определение функциональному, статистическому и корреляционному типам связи. 2. Назовите основные условия применения корреляционно-регрессионного метода анализа статистических связей. 3. Для решения каких типов задач используется корреляционно-регрессионный метод? 4. Приведите примеры различных видов уравнений парной и множественной регрессии. 5. Дайте определение парному и множественному линейным коэффициентам корреляции. 6. Как оценивается значимость коэффициента корреляции? 7. Чем характеризуются функционально связанные между собой факторы? 8. Что характеризуют параметры регрессионного уравнения? Объясните сущность коэффициента парной линейной регрессии. 9. В чем заключается метод наименьших квадратов? Каковы основные условия его применения? 10. Как оценивается значимость параметров регрессионного уравнения? 11. Дайте определение частному коэффициенту эластичности. Что он характеризует? 12. Дайте определение стандартизованному коэффициенту регрессии. Что он характеризует? 13. Что позволяет оценить множественный коэффициент детерминации? 14. Для чего используется корректированный множественный коэффициент детерминации? 15. Как оценить статистическую надежность регрессионного уравнения в целом? СПИСОК РЕКОМЕНДУЕМОЙ ЛИТЕРАТУРЫ
1. Айвазян С.А. Программное обеспечение персональных ЭВМ по статистическому анализу данных. //Компьютер и экономика: экономические проблемы компьютеризации общества. М.: Наука, 1991, с.91–107. 2. Айвазян С.А., Степанов В.С. Инструменты статистического анализа данных. //«Мир ПК», 1997, №8, с.33–41. 3. Боровиков В.П., Боровиков И.П. STATISTICA. Статистический анализ и обработка данных в среде Windows. М.: Филин, 1997. 4. Боровиков В.П. Популярное введение в программу STATISTICA.- М., 1998. 5. Векслер Л.С. Статистический анализ на персональном компьютере. //«Мир ПК», 1992, №2, с.89–97. 6. Елисеева И.И., Юзбашев М.М. Общая теория статистики.- М.: Финансы и статистика, 1998. 7. Ефимова М.Р., Петров Е.В., Румянцев В.Н. и др. Общая теория статистики /Под ред. проф. Ефимовой М.Р., -М.: Инфра-М,1998. 8. Костеева Т.В., Курышева С.В., Михайлов Б.А. Эконометрика: Решение типовых задач. –СПб.: СПбГУЭФ, 1997. 9. Крастинь О.П. Разработка и интерпретация моделей корреляционных связей в экономике. – Рига: Зинате, 1983. 10. Теория статистики: Учебник /Под ред. проф. Шмойловой Р.А. -М.: Финансы и статистика,1998. 11. Тюрин Ю.Н., Макаров А.А. Статистический анализ данных на компьютере. М.: Инфра-М, 1998. Приложение 1 Таблица. Значения F-критерия Фишера при уровне значимости a =0,05
Продолжение табл.
Приложение 2 Таблица. Значения t-критерия Стьюдента при уровне значимости 0,10; 0,05; 0,01 (двухсторонний)
|