Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Семафоры. Синхронизация процессов при помощи семафоров.Содержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте Семафоры. Синхронизация процессов при помощи семафоров.
Семафоры
В теории операционных систем семафор представляет собой неотрицательную целую переменную, над которой возможны два вида операций: P и V. P-операция над семафором представляет собой попытку уменьшения значения семафора на 1. Если перед выполнением P-операции значение семафора было больше 0, P-операция выполняется без задержек. Если перед выполнением P-операции значение семафора было 0, процесс, выполняющий P-операцию, переводится в состояние ожидания до тех пор, пока значение семафора не станет большим 0. V-операция над семафором представляет собой увеличение значения семафора на 1. Если при этом имеются процессы, задержанные на выполнении P-операции на данном семафоре, один из этих процессов выходит из состояния ожидания и может выполнить свою P-операцию.
Семафоры являются гибким и удобным средством для синхронизации и взаимного исключения процессов, учета ресурсов, скрытые семафоры также используются в операционных системах как основа для других средств взаимодействия процессов.
Взаимное исключение на семафоре
Для реализации взаимного исключения, например, предотвращения возможности одновременного изменения двумя или более процессами общих данных, создается двоичный (с возможными значениями 0 и 1) семафор S. Начальное значение этого семафора - 1. Критические секции кода (секции, которые могут одновременно выполняться только одним процессом) обрамляются "скобками" P(S) (в начале секции) и V(S) (в конце секции). Процесс, входящий в критическую секцию, выполняет операцию P(S) и переводит семафор в 0. Если в критической секции уже находится другой процесс, то значение семафора уже 0, тогда второй процесс, желающий войти в критическую секцию, блокируется в своей P-операции до тех пор, пока процесс, находящийся в критической секции сейчас, не выйдет из нее, выполнив на выходе операцию V(S).
Синхронизация на семафоре
Для обеспечения синхронизации создается двоичный семафор S с начальным значением 0. Значение 0 означает, что событие, еще не наступило. Процесс, сигнализирующий о наступлении события, выполняет операцию V(S), устанавливающую семафор в 1. Процесс, ожидающий наступления события, выполняет операцию P(S). Если к этому моменту событие уже произошло, ожидающий процесс продолжает выполняться, если же событие еще не произошло, процесс переводится в состояние ожидания до тех пор, пока сигнализирующий процесс не выполнит V(S).
В случае, если одного и того же события ожидают несколько процессов, процесс, успешно выполнивший операцию P(S), должен вслед за ней выполнить V(S), чтобы продублировать сигнал о событии для следующего ожидающего процесса.
Семафор - счетчик ресурсов
Если у нас имеется N единиц некоторого ресурса, то для контроля его распределения создается общий семафор S с начальным значением N. Выделение ресурса сопровождается операцией P(S), освобождение - операцией V(S). Значение семафора, таким образом, отражает число свободных единиц ресурса. Если значение семафора 0, то есть, свободных единиц болше не остается, то очередной процесс, запрашивающий единицу ресурса будет переседен в ожидание в операции P(S) до тех пор, пока какой-либо из использующих ресурс процессов не освободит единицу ресурса, выполнив при этом V(S).
Кольцевой буфер Применение кольцевого буфера (ring buffer) - обычный прием, когда нужно организовать поток данных между асинхронными по отношению друг к другу процессами - например, между получением данных по каналу связи и обработкой этих данных в программе. Кольцевой буфер является упрощенным аналогом очереди (queue), которая применяется в многозадачных операционных системах (Windows, Linux, FreeRTOS и многих других) для организации безопасного (thread-safe) обмена данных между потоками (синхронизации).
Кольцевой буфер может использоваться не только на прием, но и на передачу - например, если нужно быстро подготовленные где-то данные постепенно передавать с течением времени. Кольцевой буфер удобен прежде всего тем, что очень просто производить заполнение буфера, проверку наличия данных в буфере и выборку данных из буфера, при этом не нужно особенно беспокоиться о выходе данных за границу буфера, переполнении памяти и т. п. Кольцевой буфер позволяет корректно обмениваться данными между обработчиком прерывания и основной программой.
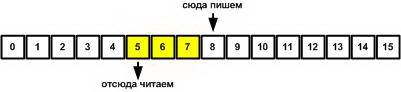
Кольцевой буфер является разновидностью буфера FIFO, First Input First Output (первый зашел - первый вышел). Принцип кольцевого буфера довольно прост - в памяти выделяется непрерывный блок размером обычно равным степени двойки (назовем его buffer), и два индекса (idxIN и idxOUT) - один индекс указывает на место для записи в буфер (idxIN), другой - на место чтения из буфера. Размер буфера, равный степени двойки, выбирается для того, чтобы удобно было манипулировать индексами, указывающими на данные буфера, с помощью инкремента/декремента и наложения маски (это будет понятно далее). Индекс - это обычное число, равное адресу ячейки буфера. Например, на ячейку buffer[0] указывает индекс, равный нулю. Количество бит индекса как раз равно степени двойки размера буфера. Максимально удобны буфера размером 256 байт - в этом случае в качестве индекса можно применить 1 байт, и маску при операциях с указателями уже накладывать не надо. Код получается в этом случае максимально быстрый и компактный. На рисунке показан принцип работы кольцевого буфера на примере буфера в 16 байт (желтым показаны еще не обработанные данные буфера):
Вот так, например, выделяется буфер: #define BUF_SIZE 16 //размер буфера обязательно равен степени двойки! #define BUF_MASK (BUF_SIZE-1)
u8 idxIN, idxOUT; char buffer [BUF_SIZE];
При помещения значения value в буфер используется индекс idxIN. Это делается так: buffer[idxIN++] = value; idxIN &= BUF_MASK;
Значение константы BUF_MASK равно размеру буфера минус 1 (при условии, что размер буфера равен степени двойки). При таком принципе работы с индексом происходит автоматический переход на начало буфера, как только мы достигли его конца.
Операция выборки из буфера происходит похожим образом, только используется индекс idxOUT: value = buffer[idxOUT++]; idxOUT &= BUF_MASK;
Теперь становится понятным, почему при размере буфера 256 байт и байтовом индексе не нужна операция наложения маски - переход в ноль индекса при достижении конца буфера происходит автоматически.
Проверка на наличие данных в буфере происходит очень просто - если idxIN не равен idxOUT, то в буфере есть данные, в противном случае данных в буфере нет. Индекс idxOUT как-бы постоянно догоняет индекс idxIN при работе с данными буфера. Если догнал - значит, считывать из буфера больше нечего. if (idxIN!= idxOUT) { //данные есть, обрабатываем их ... }
Сбросить данные буфера (т. е. удалить их оттуда) тоже очень просто - для этого в idxOUT записывают значение idxIN: idxOUT = idxIN;
Иногда бывает необходимо знать, что не только данные в буфере есть, а еще нужно знать сколько именно байт данных в буфере. Для этого используется довольно простая процедура: u8 idxDiff (u8 idxIN, u8 idxOUT) { if (idxIN >= idxOUT) return (idxIN - idxOUT); else return ((BUF_SIZE - idxOUT) + idxIN);
Бесконечное откладывание
Процессы, ожидающие ресурсов, встают в очереди к этим ресурсам. Такая очередь может обслуживаться любой невытесняющей стратегией планирования. Моментом, когда менеджер ресурса принимает решение об обслуживании, является освобождение ресурса.
Единственной дисциплиной, которая гарантирует, что все процессы в очереди будут в конце концов обслужены, является FCFS. Другие методы базируются на приоритетах - внешних или вычисляемых на основании размера запроса или/и безопасности ситуации. Очередь может быть упорядочена по возрастанию размера запроса, и при освобождении ресурсов последние могут отдаваться по запросу "самого подходящего" размера. Очередь может быть упорядочена в порядке возрастания опасности выделения ресурсов, и освободившийся ресурс может отдаваться тому процессу, запрос которого самый безопасный. При упорядочении очереди, процесс, выдавший самый большой или самый опасный запрос, может надолго в ней застрять, то есть, попасть в ситуацию бесконечного откладывания. С другой стороны, применение FCFS в чистом виде может привести к снижению уровня мультипрограммирования, к опасному состоянию и даже к тупику - если процесс со слишком большим запросом окажется первым в очереди. Отчасти это противоречие может быть сглажено, если мы допустим частичное выделение ресурсов: запрос, стоящий в очереди первым получает столько ресурсов, сколько ему можно выделить, сохраняя ситуацию безопасной, остальные - отдаются следующему в очереди процессу.
Поскольку тупиковая ситуация более опасна, чем бесконечное откладывание, ОС все же отдает предпочтение критериям безопасности, следовательно, заведомо предотвратить бесконечное откладывание невозможно. Бесконечное откладывание процесса устанавливается по времени его пребывания в очереди: если процесс пребывает в очереди дольше некоторого установленного времени, то считается, что он ожидает бесконечно. В зависимости от политики ОС в отношении справедливости обслуживания и от характеристик процесса (если они известны) допустимое время ожидания может устанавливаться большим или меньшим. Если же бесконечное откладывание установлено, то для его ликвидации ОС приостанавливает выдачу ресурсов новым процессам, пока не будет обслужен отложенный процесс.
Проблема тупиков до некоторой степени теряет актуальность в современных ОС, так как они имеют тенденцию к уменьшению количества неразделяемых ресурсов. Одним из способов сделать неразделяемое устройство разделяемым является буферизация, которую мы рассмотрим в следующей главе. Системные структуры данных разделяются с использованием средств взаимного исключения доступа, которым будет посвящена глава 8. Эта проблема, однако, становится все более актуальной для современных СУБД, которые обеспечивают одновременный доступ к ресурсам-данным для тысяч и десятков тысяч пользователей.
Обнаружение тупиков Обнаружение тупика — это установление факта, что возникла тупиковая ситуация, и определение процессов и ресурсов, вовлеченных в эту тупиковую ситуацию. Алгоритмы обнаружения тупиков, как правило, применяются в системах, где выполняются первые три необходимых условия возникновения тупиковой ситуации. Эти алгоритмы затем определяют, не создался ли режим кругового ожидания.
Применение алгоритмов обнаружения тупиков сопряжено с определенными дополнительными затратами машинного времени. Таким образом, здесь мы снова сталкиваемся с необходимостью прибегать к компромиссным решениям, столь распространенным в операционных системах. Будут ли накладные расходы, связанные с реализацией алгоритмов обнаружения тупиковых ситуаций, в достаточной степени оправданы потенциальными выгодами от локализации и устранения тупиков? В данный момент мы этот вопрос рассматривать не будем, а лучше сосредоточим свое внимание на описании алгоритмов, позволяющих обнаруживать тупики.
Обнаружение тупиков
Обнаружение взаимоблокировки сводится к фиксации тупиковой ситуации и выявлению вовлеченных в нее процессов. Для этого производится проверка наличия циклического ожидания в случаях, когда выполнены первые три условия возникновения тупика. Методы обнаружения активно используют графы распределения ресурсов.
Рассмотрим модельную ситуацию. Процесс P1 ожидает ресурс R1. Процесс P2 удерживает ресурс R2 и ожидает ресурс R1. Процесс P3 удерживает ресурс R1 и ожидает ресурс R3. Процесс P4 ожидает ресурс R2. Процесс P5 удерживает ресурс R3 и ожидает ресурс R2.
Вопрос состоит в том, является ли данная ситуация тупиковой, и если да, то какие процессы в ней участвуют. Для ответа на этот вопрос можно сконструировать граф ресурсов, как показано на рис. 7.3. Из рисунка видно, что имеется цикл, моделирующий условие кругового ожидания, и что процессы P2,P3,P5, а может быть, и другие находятся в тупиковой ситуации.
Рис. 7.3. Граф ресурсов
Визуально легко обнаружить наличие тупика, но нужны также формальные алгоритмы, реализуемые на компьютере.
Один из таких алгоритмов описан в [Таненбаум, 2002], там же можно найти ссылки на другие алгоритмы.
Существуют и другие способы обнаружения тупиков, применимые также в ситуациях, когда имеется несколько ресурсов каждого типа. Так в [Дейтел, 1987] описан способ, называемый редукцией графа распределения ресурсов, а в [Таненбаум, 2002] – матричный алгоритм.
Поблочное отображение
Механизм динамического преобразования адресов должен вести таблицы, показывающие, какие ячейки виртуальной памяти в текущий момент времени находятся в реальной памяти и где именно они размещаются. Если бы такое отображение осуществлялось пословно или побайтно, то информация об отображении была бы столь велика, что для ее хранения потребовалось бы столько же или даже больше реальной памяти, чем для самих процессов. Поэтому, чтобы реализация виртуальной памяти имела смысл, необходим метод, позволяющий существенно сократить объем информации отображения.
Поскольку мы не можем идти на индивидуальное отображение элементов информации, мы группируем их в блоки, и система следит за тем, в каких местах реальной памяти размещаются различные блоки виртуальной памяти. Чем больше размер блока, тем меньшую долю емкости реальной памяти приходится затрачивать на хранение информации отображения.
Увеличение размера блоков приводит к уменьшению дополнительных затрат памяти для механизма отображения. Однако крупные блоки требуют большего времени на обмен между внешней и первичной памятью и с большей вероятностью ограничивают количество процессов, которые могут совместно использовать первичную память.
При реализации виртуальной памяти возникает вопрос о том, следует ли все блоки делать одинакового или разных размеров. Если блоки имеют одинаковый размер, они называются страницами, а соответствующая организация виртуальной памяти называется страничной. Если блоки могут быть различных размеров, они называются сегментами, а соответствующая организация виртуальной памяти называется сегментной. В некоторых системах оба этих подхода комбинируются, т. е. сегменты реализуются как объекты переменных размеров, формируемые из страниц фиксированного размера.
Адреса в системе поблочного отображения являются двухкомпонентными («двумерными»). Чтобы обратиться к конкретному элементу данных, программа указывает блок, в котором этот элемент располагается, и смещение этого элемента относительно начала блока (рис 9.6). Виртуальный адрес v указывается при помощи упорядоченной пары (b, d), где b — номер блока, в котором размещается соответствующий элемент, a d — смещение относительно начального адреса этого блока.
Многоуровневая организация основной памяти вычислительной системы, основанной на сочетании программных и аппаратных средств, позволяет значительно ослабить количественные ограничения на основную память. Основная память, моделируемая на внешней памяти (на магнитных дисках), называется виртуальной (в отличие от реальной). Объем виртуальной памяти может значительно превышать объем реальной памяти и ограничивается только размером адреса. Так, для 24-разрядного адреса можно обеспечить пространство виртуальной памяти до 16 Мбайт. В вычислительной системе может существовать либо одно виртуальное адресное пространство для системы и всех пользователей, либо много виртуальных адресных пространств.
31) Системы с комбинированной странично-сегментной организацией. Таблица процессов и преобразование адресов.
9.7 Системы с комбинированной странично-сегментной организацией
9.7.1. Основные концепции
И сегментная, и страничная организации имеют важные достоинства как способы построения виртуальной памяти. Начиная с систем середины 60-х годов, в частности с информационно-вычислительной системы с разделением времени Multics и системы разделения времени TSS корпорации IBM, во многих вычислительных машинах применяется комбинированная странично-сегментная организация памяти. Эти системы обладают достоинствами обоих способов реализации виртуальной памяти. Сегменты обычно содержат целое число страниц, причем не обязательно, чтобы все страницы сегмента находились в первичной памяти одновременно, а смежные страницы виртуальной памяти не обязательно должны оказываться смежными в реальной памяти. В системе со странично-сегментной организацией применяется трехкомпонентная (трехмерная) адресация, т. е. адрес виртуальной памяти v определяется как упорядоченная тройка v = (s, p, d), где s — номер сегмента, р — номер страницы, а d — смещение в рамках страницы, по которому находится нужный элемент (рис. 9.18).
Рис. 9.18 Формат виртуального адреса в странично-сегментной системе
9.7.2. Динамическое преобразование адресов в системах со странично-сегментной организацией
Рассмотрим теперь динамическое преобразование виртуальных адресов в реальные в странично-сегментной системе с применением комбинированного ассоциативно-прямого отображения, как показано на рис. 9.19.
Выполняющийся процесс делает ссылку по виртуальному адресу n = (s, р, d). Самые последние по времени обращения страницы имеют соответствующие строки в ассоциативной таблице. Система производит ассоциативный поиск, пытаясь найти строку с параметрами (s, р) в ассоциативной таблице. Если такая строка здесь обнаруживается, то адрес страничного кадра р', по которому эта страница размещается в первичной памяти, соединяется со смещением d, образуя реальный адрес r, соответствующий виртуальному адресу v, - и на этом преобразование адреса завершается.
В обычном случае большинство запросов на преобразование адресов удается удовлетворить подобным ассоциативным поиском. Если же требуемого адреса в ассоциативной памяти нет, то преобразование осуществляется способом полного прямого отображения. Это делается следующим образом: базовый адрес b таблицы сегментов прибавляется к номеру сегмента s, так что образуется адрес b+s строки для сегмента s в таблице сегментов по первичной памяти. В этой строке указывается базовый адрес s' таблицы страниц для сегмента s. Номер страницы р прибавляется к s', так что образуется адрес p+s' строки в таблице страниц для страницы р сегмента s. Эта таблица позволяет установить, что виртуальной странице р соответствует номер кадра р'. Этот номер кадра соединяется со смещением d, так что образуется реальный адрес r, соответствующий виртуальному адресу v = (s, р, d).
Эта процедура преобразования адресов описана, конечно, в предположении, что каждый необходимый элемент информации находится именно там, где ему положено быть. Однако в процессе преобразования адресов существует много моментов, когда обстоятельства могут складываться не столь благоприятно. Просмотр таблицы сегментов может показать, что сегмента s в первичной памяти нет; при этом возникает прерывание по отсутствию сегмента, операционная система найдет нужный сегмент во внешней памяти, сформирует для него таблицу страниц и загрузит соответствующую страницу в первичную память, быть может, вместо некоторой существующей страницы этого или какого-либо другого процесса. Когда сегмент находится в первичной памяти, обращение к таблице страниц может показать, что нужной страницы в первичной памяти все же нет. При этом произойдет прерывание по отсутствию страницы, операционная система возьмет управление на себя, найдет данную страницу во внешней памяти и загрузит ее в первичную память (быть может, опять-таки с замещением другой страницы). Как и при чисто сегментной системе, адрес виртуальной памяти может выйти за рамки сегмента и произойдет прерывание по выходу за пределы сегмента. Или контроль по битам-признакам защиты может выявить, что операция, выполнение которой запрашивается по указанному виртуальному адресу, не разрешена, вследствие чего произойдет прерывание по защите сегмента. Операционная система должна предусматривать обработку всех этих ситуаций.
Ассоциативная память (или аналогично высокоскоростная кэш-память) играет решающую роль в обеспечении эффективной работы механизма динамического преобразования адресов. Если преобразование адресов производить с помощью чисто прямого отображения с ведением в первичной памяти полного набора таблиц соответствия виртуальных и реальных адресов, типичное обращение к виртуальной памяти потребовало бы цикла памяти для доступа к таблице сегментов, второго цикла памяти для доступа к таблице страниц и третьего для доступа к нужному элементу в реальной памяти. Таким образом, каждое обращение к адресуемому элементу занимало бы три цикла памяти, т. е. реальное быстродействие вычислительной системы составило бы лишь приблизительно треть от номинального значения, а две трети затрачивалось бы на преобразование адресов! Интересно, что при всего лишь восьми или шестнадцати ассоциативных регистрах разработчики добиваются для многих систем показателей быстродействия, составляющих 90 и более процентов полных скоростных возможностей их управляющих (центральных) процессоров.
Рис. 9.19 Преобразование виртуального адреса путем комбинированного ассоциативно прямого отображения в странично-сегментной системе.
Протокол ARP
В этом разделе мы рассмотрим то, как при посылке IP-пакета определяется Ethernet-адрес назначения. Для отображения IP-адресов в Ethernetадреса используется протокол ARP (Address Resolution Protocol - адресный протокол). Отображение выполняется только для отправляемых IP-пакетов, так как только в момент отправки создаются заголовки IP и Ethernet.
ARP-таблица для преобразования адресов Преобразование адресов выполняется путем поиска в таблице. Эта таблица, называемая ARP-таблицей, хранится в памяти и содержит строки для каждого узла сети. В двух столбцах содержатся IP- и Ethernet-адреса. Если требуется преобразовать IP-адрес в Ethernet-адрес, то ищется запись с соответствующим IP-адресом. Ниже приведен пример упрощенной ARP-таблицы.
--------------------------------------------- | IP-адрес Ethernet-адрес | --------------------------------------------- | 223.1.2.1 08:00:39:00:2F:C3 | | 223.1.2.3 08:00:5A:21:A7:22 | | 223.1.2.4 08:00:10:99:AC:54 | --------------------------------------------- Табл.1. Пример ARP-таблицы Принято все байты 4-байтного IP-адреса записывать десятичными числами, разделенными точками. При записи 6-байтного Ethernet-адреса каждый байт указывается в 16-ричной системе и отделяется двоеточием.
ARP-таблица необходима потому, что IP-адреса и Ethernet-адреса выбираются независимо, и нет какого-либо алгоритма для преобразования одного в другой. IP-адрес выбирает менеджер сети с учетом положения машины в сети internet. Если машину перемещают в другую часть сети internet, то ее IP-адрес должен быть изменен. Ethernet-адрес выбирает производитель сетевого интерфейсного оборудования из выделенного для него по лицензии адресного пространства. Когда у машины заменяется плата сетевого адаптера, то меняется и ее Ethernet-адрес.
Порядок преобразования адресов В ходе обычной работы сетевая программа, такая как TELNET, отправляет прикладное сообщение, пользуясь транспортными услугами TCP. Модуль TCP посылает соответствующее транспортное сообщение через модуль IP. В результате составляется IP-пакет, который должен быть передан драйверу Ethernet. IP-адрес места назначения известен прикладной программе, модулю TCP и модулю IP. Необходимо на его основе найти Ethernet-адрес места назначения. Для определения искомого Ethernet-адреса используется ARP-таблица.
Запросы и ответы протокола ARP Как же заполняется ARP-таблица? Она заполняется автоматически модулем ARP, по мере необходимости. Когда с помощью существующей ARP-таблицы не удается преобразовать IP-адрес, то происходит следующее: По сети передается широковещательный ARP-запрос. Исходящий IP-пакет ставится в очередь.
Каждый сетевой адаптер принимает широковещательные передачи. Все драйверы Ethernet проверяют поле типа в принятом Ethernet-кадре и передают ARP-пакеты модулю ARP. ARP-запрос можно интерпретировать так: "Если ваш IP-адрес совпадает с указанным, то сообщите мне ваш Ethernet-адрес". Пакет ARP-запроса выглядит примерно так:
----------------------------------------------------------- | IP-адрес отправителя 223.1.2.1 | | Ethernet-адрес отправителя 08:00:39:00:2F:C3 | ----------------------------------------------------------- | Искомый IP-адрес 223.1.2.2 | | Искомый Ethernet-адрес <пусто> | ----------------------------------------------------------- Табл.2. Пример ARP-запроса
Каждый модуль ARP проверяет поле искомого IP-адреса в полученном ARP-пакете и, если адрес совпадает с его собственным IP-адресом, то посылает ответ прямо по Ethernet-адресу отправителя запроса. ARP-ответ можно интерпретировать так: "Да, это мой IP-адрес, ему соответствует такой-то Ethernet-адрес". Пакет с ARP-ответом выглядит примерно так:
----------------------------------------------------------- | IP-адрес отправителя 223.1.2.2 | | Ethernet-адрес отправителя 08:00:28:00:38:A9 | ----------------------------------------------------------- | Искомый IP-адрес 223.1.2.1 | | Искомый Ethernet-адрес 08:00:39:00:2F:C3 | ----------------------------------------------------------- Табл.3. Пример ARP-ответа
Этот ответ получает машина, сделавшая ARP-запрос. Драйвер этой машины проверяет поле типа в Ethernet-кадре и передает ARP-пакет модулю ARP. Модуль ARP анализирует ARP-пакет и добавляет запись в свою ARP-таблицу.
Обновленная таблица выглядит следующим образом:
--------------------------------------------- | IP-адрес Ethernet-адрес | --------------------------------------------- | 223.1.2.1 08:00:39:00:2F:C3 | | 223.1.2.2 08:00:28:00:38:A9 | | 223.1.2.3 08:00:5A:21:A7:22 | | 223.1.2.4 08:00:10:99:AC:54 | --------------------------------------------- Табл.4. ARP-таблица после обработки ответа
Продолжение преобразования адресов Новая запись в ARP-таблице появляется автоматически, спустя несколько миллисекунд после того, как она потребовалась. Как вы помните, ранее на шаге 2 исходящий IP-пакет был поставлен в очередь. Теперь с использованием обновленной ARP-таблицы выполняется преобразование IPадреса в Ethernet-адрес, после чего Ethernet-кадр передается по сети. Полностью порядок преобразования адресов выглядит так: По сети передается широковещательный ARP-запрос. Исходящий IP-пакет ставится в очередь. Возвращается ARP-ответ, содержащий информацию о соответствии IP- и Ethernet-адресов. Эта информация заносится в ARP-таблицу. Для преобразования IP-адреса в Ethernet-адрес у IP-пакета, постав ленного в очередь, используется ARP-таблица. Ethernet-кадр передается по сети Ethernet. Короче говоря, если с помощью ARP-таблицы не удается сразу осуществить преобразование адресов, то IP-пакет ставится в очередь, а необходимая для преобразования информация получается с помощью запросов и ответов протокола ARP, после чего IP-пакет передается по назначению.
Если в сети нет машины с искомым IP-адресом, то ARP-ответа не будет и не будет записи в ARP-таблице. Протокол IP будет уничтожать IP-пакеты, направляемые по этому адресу. Протоколы верхнего уровня не могут отличить случай повреждения сети Ethernet от случая отсутствия машины с искомым IP-адресом.
Некоторые реализации IP и ARP не ставят в очередь IP-пакеты на то время, пока они ждут ARP-ответов. Вместо этого IP-пакет просто уничтожается, а его восстановление возлагается на модуль TCP или прикладной процесс, работающий через UDP. Такое восстановление выполняется с помощью таймаутов и повторных передач. Повторная передача сообщения проходит успешно, так как первая попытка уже вызвала заполнение ARP-таблицы.
Следует отметить, что каждая машина имеет отдельную ARP-таблицу для каждого своего сетевого интерфейса. Планирование с переключением и без переключения. Интервальный таймер.
Планирование с переключением и без переключения
Если после предоставления ЦП в распоряжение некоторого процесса отобрать ЦП у этого процесса нельзя, то говорят о дисциплине планирования без переключения. Если же ЦП можно отобрать, то говорят о дисциплине планирования с переключением.
Планирование с переключением необходимо в системах, в которых процессы высокого приоритета требуют немедленного внимания. Например, в системах реального времени пропажа одного важного сигнала прерывания может привести к катастрофическим последствиям. В интерактивных системах разделения времени планирование с переключением играет важную роль, поскольку позволяет гарантировать приемлемые времена ответа.
Планирование, требующее контекстных переключений, сопряжено с определенными накладными расходами. Чтобы обеспечить его эффективность, в основной памяти должно размещаться много процессов, с тем чтобы очередной процесс был, как правило, готов для выполнения, когда освобождается ЦП. А размещение неработающих программ в основной памяти также сопряжено с накладными расходами.
В системах планирования без переключения коротким заданиям приходится больше ждать из-за выполнения длительных заданий, однако для всех процессов создаются как бы равные условия. Времена ответа здесь более предсказуемы, поскольку поступающие задания высокого приоритета не могут оттеснять уже ожидающие задания.
Приоритеты. Планирование по сроку завершения.
Приоритеты
Система может присваивать приоритеты автоматически или они могут назначаться извне. Приоритеты могут быть заслуженными («заработанными») или купленными. Они могут быть либо статическими, либо динамическими. Они могут присваиваться по какому-то рациональному принципу или произвольно назначаться в ситуациях, когда системному механизму необходимо каким-то образом различать процессы, однако он не знает, какой из них в действительности более важен.
11.6.1. Статические и динамические приоритеты
Статические приоритеты не изменяются. Механизмы статической приоритетности легко реализовать. Однако они не реагируют на изменения в окружающей ситуации, изменения, которые могут сделать желательной корректировку приоритетов.
Механизмы динамических приоритетов реагируют на изменения в ситуации. Начальное значение приоритета, присвоенное процессу, может действовать в течение лишь короткого периода времени, после чего назначается новое, более подходящее значение. Схемы динамической приоритетности гораздо сложнее в реализации и связаны с большими издержками по сравнению со статическими схемами. Однако предполагается, что эти издержки оправдываются повышением реактивности системы.
11.7 Планирование по сроку завершения
При планировании по сроку завершения принимаются все меры для того, чтобы выполнение определенных заданий заканчивалось к заранее обусловленному времени, или конечному сроку. Результаты этих заданий могут иметь очень важное значение, если они будут получены вовремя, и могут оказаться бесполезными после назначенного срока. Пользователь зачастую с готовностью внесет дополнительную плату, лишь бы система гарантированно завершила выполнение его задания в назначенное время. Планирование по сроку завершения сложно организовать по многим причинам.
· Пользователь должен заранее точно указывать, какие ресурсы потребуются для выполнения его задания. А подобную информацию можно иметь лишь в редких случаях.
· Система должна выполнять задания к сроку без серьезного снижения уровня обслуживания других пользователей.
· Система должна тщательно распределять загрузку своих ресурсов вплоть до указанного срока завершения задания. А это может быть достаточно трудно, поскольку могут поступать новые задания, предъявляющие к системе непредсказуемые требования.
Если приходится иметь дело одновременно со многими заданиями, для которых задается срок выполнения, то планирование может настолько усложниться, что потребуются специальные методы оптимизации, гарантирующие соблюдение всех сроков.
Активное управление ресурсами, необходимое при планировании по сроку завершения, может быть связано с существенными накладными расходами. Хотя пользователи согласны идти на достаточно высокую плату за предоставление услуг, обеспечивающих выполнение их заданий в указанные сроки, общий объем затрачиваемых на это системных ресурсов может оказаться настолько большим, что остальные пользователи, работающие с системой, будут страдать от ухудшенного обслуживания. Разработчики операционных систем должны тщательно учитывать возможность подобных конфликтов.
11.8 Планирование по принципу FIFO («first in - first out» — «первый пришедший обслуживается первым»)
По-видимому, наиболее простой дисциплиной планирования является принцип FIFO («первый пришедший обслуживается первым») (рис. 11.2). Центральный процессор предоставляется процессам в порядке их прихода в очередь готовности. После того, как процесс получает ЦП в свое распоряжение, он выполняется до завершения.
Планирование по принципу FIFO. Размер кванта.
Планирование по принципу FIFO («первый пришедший обслуживается первым»)
Принцип FIFO — это дисциплина планирования без переключения. Если рассуждать формально, то этот принцип можно считать справедливым, однако он все-таки в определенном смысле несправедлив тем, что длинные задания заставляют ждать короткие задания, а менее важные задания — более важные. Принцип FIFO характеризуется относительно небольшими колебаниями времен ответа и поэтому большей предсказуемостью, чем большинство других дисциплин обслуживания. Его не рекомендуется применять при планировании заданий пользователей, работающих в интерактивном режиме, поскольку он не может гарантировать хорошие времена ответа.
В современных системах принцип FIFO редко используется самостоятельно в качестве основной дисциплины обслуживания, а чаще комбинируется с другими схемами. Например, во многих схемах планирования предусматривается диспетчирование процессов в соответствии с их приоритетами, однако процессы с одинаковыми уровнями приоритета диспетчируются по принципу FIFO.
Планирование по принципам SJF, SRT и HRN. Планирование по принципу SJF («кратчайшее задание — первым») Принцип SJF («кратчайшее задание — первым») — это дисциплина планирования без переключения, согласно которой следующим для выполнения выбирается ожидающее задание (или процесс) с минимальным оценочным рабочим временем, остающимся до завершения. Принцип SJF обеспечивает уменьшение среднего времени ожидания по сравнению с дисциплиной FIFO. Однако времена ожидания при этом колеблются в более широких пределах (т. е. менее предсказуемы), чем в случае FIFO, особенно при больших заданиях.
Дисциплина SJF оказывает предпочтение коротким заданиям (или процессам) за счет более длинных.
Механизм SJF выбирает для обслуживания задания таким образом, чтобы очередное задание завершалось и покидало систему как можно быстрее. Благодаря этому обеспечивается уменьшение количества ожидающих заданий, а также количества заданий, стоящих в очереди за длинными заданиями. В результате дис
|
||
|
|
Последнее изменение этой страницы: 2016-08-16; просмотров: 723; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.33 (0.013 с.) |