
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Алфавит, слово, процесс, конструкция
Алфавитом называется любая совокупность символов (не обязательно букв некоторого языка общения), с помощью которых формируются сообщения, актуализируется информация. Основные свойства любого алфавита: · компактность и конечность множества символов; · ясность (понятность слов в этом алфавите любому интерпретатору с него); · информативность (символов, а особенно, слов над данным алфавитом); · уникальность (разные алфавиты имеют хотя бы один отличный символ); · полнота (включает все символы для записи любого сообщения в данном алфавите). Пример. Алфавит десятичных цифр, алфавит комбинаций точек и тире в азбуке Морзе, алфавит жестов у немых, алфавит китайских иероглифов, алфавит флажков у сигнальщиков на боевых кораблях. Буквой или знаком называется любой элемент x конечного алфавита X, x Пример. Знак «+» может означать как операцию сложения чисел, так и операцию соединения текстов, знак «!» - соответствует понятиям: факториал, восклицание, опасность. Из последнего примера видно, что не только элемент x определяет элемент y, но и элемент y может накладывать ограничения на x. Буквы алфавита существуют независимо от информации, которую можно актуализировать этим алфавитом, т.е. они символически самостоятельны, инвариантны. Пример. Знак 5 как элемент алфавита арифметики несет смысловое значение - выражает количество, соответствующее пяти объектам, предметам. Знак Ы - как элемент алфавита русского языка уже не несет смысловой нагрузки - смысловое значение приобретает знак Ы в комбинации с другими символами, в соответствующей структуре, например, в слове СТУДЕНТЫ. Информация – это абстракция (математическая или семантическая) и внешне всегда проявляется в виде сообщения. Пример. Десятичное число 9 выражает информацию о девяти объектах, а цифра 9 - выражение этого количества в виде символа алфавита десятичной системы. Отрезок АВ есть абстракция, соответствующая множеству точек на числовой прямой, а отрезок [0,1] отождествляется с геометрическим отрезком (геометрическим местом точек) длины 1.
В алфавите должен быть определен порядок следования букв (типа «предыдущий элемент – последующий элемент») например, конечный алфавит вида X={ x 1, x 1 ,..., x n }. Слово в алфавите X - любая конечная последовательность букв из x, слово имеет вид: p=x 1 x 2... x m, где x i Длиной | p | слова p называется число составляющих его букв. Слово нулевой длины называется пустым словом: | Разделителем слов называется один символ (несколько символов), отделяющий (отделяющих) последний символ предыдущего слова от первого символа последующего слова. Множество различных слов над алфавитом X обозначим через S(X) и назовем словарным запасом (над алфавитом X). Пример. Пусть X={a,1,2}, тогда словами над X будет а, аа, а112, 1111. Если считать разделителем слов знак пробела, то предложением над X будет ааа а11 222аа. Длины слов: | a | = 1, | a112 | = | aa4a | = 4. Один алфавит может быть информационно богаче другого. При этом не нужно иметь большой алфавит для того, чтобы получить большое множество слов над ним. Пример. Алфавит китайских иероглифов богаче алфавита английского языка, но может быть беднее алфавита художественных образов (рисунков). Два различных знака (точка и тире) в алфавите Морзе и не более чем четырехсимвольная их комбинация позволяют передавать такую же информацию, что и алфавит русского языка. Основная операция, которая определена в любом S(X) – операция конкатенации (присоединения) слов p, q Пример. Алфавит десятичной системы счисления: X={0, 1, 2,..., 9}, p=10299, q=0001; алфавит десятичной арифметики: X={0, 1, 2,..., 9, +, -, *,/, (,)}, p=12+131, q=2(133-9)/32; алфавит латинских букв: X={A, a, B, b,..., Z, z}, p=Word; алфавит русского языка: X = {A, a, Б, б,..., Я, я, -,.,!,?,,,:,;, «, «,...}, p=Республика Кабардино-Балкария, q=Лето. Жарко и светло.; алфавит азбуки Морзе: X ={. |. - |.--| --.|..- |.-.- |...}, p=|. -|.. -|- -..| -..|. Конкатенация может быть правая и левая, а также и двухсторонняя. Пример. Слова, а, следовательно, предложения русского языка образуются правосторонней конкатенацией, а в арабском языке (письме) - левосторонней конкатенацией; в арифметике можно десятичные дроби образовывать двухсторонней конкатенацией (слева и справа от десятичной точки).
Действие (по отношению к некоторой системе) - изменение состояния системы. Имеются два особых действия - начальное и финальное. Процессом, определенным над некоторой операционной средой или алфавитом, назовем систему взаимосвязанных, структурированных, ресурсоориентированных действий от начального (стартового) до конечного (финального) событий. Процесс всегда связан с выбором, актуализацией информации. Реализация процесса – это его выбор, актуализация действий для некоторого алфавита, операционной среды, ресурсов. Один и тот же процесс может быть реализован (актуализирован) различными способами - алфавитами, ресурсами. Реализация заключается в выполнении действий и в обмене ресурсами между ними и сопровождающихся построением правильной цепочки действий, приводящей к цели. Конструктивизм, конструктивность процесса действий определим как приводимость (реализуемость) процесса от начального до конечного действия при любом допустимом входном наборе информации, т.е. возможность получения в результате выполнения этих действий результатов из заранее определенного выходного множества. Конструктивный объект над множеством Х - объект, который можно построить с помощью некоторого конструктивного процесса над Х. Пример. Построение решения квадратного уравнения для класса имен из одних четырех арифметических операций - не конструктивный процесс, а в классе имен, получаемом добавлением к ним операции (функции) извлечения корня до любой заданной степени точности (например, с помощью известного рекуррентного соотношения для вычисления квадратного корня) - конструктивный процесс. При одинаковом наборе входной информации, все конструктивные процессы должны при реализации приводить к конструктивным объектам. Процесс может быть последовательным, параллельным или смешанным - в зависимости от времени или пространства актуализация ресурса (вещества, энергии, информации). Последовательный процесс (последовательно выполняемый процесс) - процесс, в котором каждое не особое действие является действием-предшественником или действием-преемником. Конструктивным словообразующим процессом (процессом словообразования) называется процесс применения операции конкатенации к символам алфавита или к уже полученным в результате предыдущих конструктивных процессов словам над этим алфавитом. Символы алфавита (их копии) могут участвовать в словообразовании сколь угодно раз. Любой процесс словообразования начинается с пустого символа (слова), к которому затем присоединяются другие символы (слова) алфавита. Конструктивное описание конструктивного процесса словообразования будет выглядеть так: 1. Пустое слово 2. Если s Пример. Определим длину слова конструктивным процессом: 1. | 2. Если x
Справедливо следующее очень важное утверждение. Тезис Черча. Все разумные (непротиворечивые, понятные, реализуемые и т.д.) способы определения конструктивных объектов и процедур работы с ними эквивалентны. Пример. Примеры в пользу этого утверждения: все корректные программы решения одних и тех же проблем эквивалентны по выходным результатам; все способы вычисления значений функции на одном и том же допустимом множестве эквивалентны по результатам; все разумные способы повышения производительности (или же эффективности) труда на предприятии эквивалентны, если мера производительности (или же эффективности) труда определена конструктивно, например, как отношение вида «добавленная стоимость на единицу продукции». Если слова, образованные из символов (слов) x и y левой и правой конкатенацией, совпадают, то они коммутативны. Не для всяких алфавитов (или слов) верно правило коммутативности. Пример. Если взять слова 102 и 201 над алфавитом N натуральных чисел, то они не коммутативны. Конкатенация в каких-то алфавитах может удовлетворять правилам, аналогичным правилам действия в арифметике чисел, а в других алфавитах (или же в одном и том же алфавите) – не удовлетворять таким правилам.
Кодирование и декодирование Кодом называется правило, описывающее соответствие данного набора знаков (входного алфавита Х или слов S(X)) другому набору знаков (Y или S(Y)). Слово «код» («code») произошло от слова «кодекс», «свод законов». Кодирование - это представление символов одного алфавита сочетаниями символов другого алфавита. Преобразование сообщений (слов в алфавите), таким образом, сводится к процессу кодирования. Пример. Пусть X=Z, Y ={0, 1,..., 9, -}. Тогда запись любого целого числа из X представляет собой кодирование символов из X символами из Y. Пример. Рассмотрим A={X,O}, B={(,)}. Тогда можно задать кодирование по принципу «визуальной аналогии», поставив в соответствие букве Х последовательность «)(«, а букве О - последовательность «()». Тогда слово ОХОХО над А закодируется как слово ())(())(() над В. Пусть X={x 1, x 2,..., x n }, Y={y 1, y 2,..., y m } - некоторые алфавиты. Кодирование произвольного сообщения x=x 1 x 2... x p Конечный результат Y p и будет являться кодом сообщения x. Если это соответствие имеет однозначное обратное, то это обратное соответствие называется декодированием.
Пример. Рассмотрим так называемое арифметическое кодирование. Пусть заданы алфавиты X={x 1, x 2,..., x n }, Y={y 1, y 2,..., y m }. Например, Х - множество символов на клавиатуре ЭВМ, а Y - двоичный алфавит. Кодирование состоит в переводе произвольного слова, например, x=x 1 x 2 x 5 над Х в элемент (слово, двоичное число y) над Y. Этот перевод осуществляется последовательными применениями к x преобразований R(x 1 ), R(x 2 ), R(x 5 ). Каждое такое преобразование действует на подмножество Y и результат этого действия - новое подмножество Y. Конечный результат этой последовательности преобразований и является кодом х. Расположение некоторого множества слов в соответствии с выбранным кодом называется упорядочиванием по коду. Упорядочение слов по символам некоторого данного алфавита называется лексикографическим упорядочиванием. Пример. Слова «абрикос», «банан», «киви», «тыква» будут лексикографически упорядочены по входному алфавиту русского языка, а слова двоичного алфавита «101»,»011»,»010»,»100» - лексикографически неупорядочены. Пример. Генетический код – чрезвычайно сложная и упорядоченная система записи информации. Информация, заложенная в генетическом коде (по учению Дарвина), накапливалась многие тысячелетия. Хромосомные структуры – своеобразный шифровальный код, и при клеточном делении создаются копии шифра, каждая хромосома удваивается, в каждой клетке имеется шифровальный код, при этом каждый человек получает, как правило, свой набор хромосом (код) от матери и от отца. Шифровальный код разворачивает процесс эволюции человека. Вся жизнь, как отмечал Э. Шредингер, «упорядоченное и закономерное поведение материи, основанное на существовании упорядоченности, которая поддерживается все время». Правила кодирования (шифрования) не могут быть произвольными. Они должны быть такими, чтобы зашифрованное сообщение можно было бы прочесть (расшифровать). Однотипные правила (типа правила Цезаря) можно объединять в классы. Если внутри класса правил выбран некоторый параметр (числовой, табличный и т.д.), изменяя значения которого можно перебрать все правила, то он называется шифровальным ключом. Имеются две группы шифров: шифры перестановки и шифры замены. Шифр перестановки изменяет только порядок следования символов исходного сообщения. Шифр замены заменяет каждый символ кодируемого сообщения на другие символы не изменяя порядка их следования. Пример. Шифр Цезаря - шифр типа перестановки. Шифр состоящий в замене каждого символа алфавита русского языка его двухзначным порядковым номером - шифр типа замены. Восстановление некоторого зашифрованного сообщения по ключу - расшифрование, а восстановление (прочтение) его без известного ключа - вскрытие (взлом) шифра. Кодирование и шифрование - разные вещи. При кодировании нет секретного ключа (достаточно знать соответствие символов), а при шифровании необходимо наличие ключа (нужно знать как шифр, так и ключ к шифру). Кодирование не ставит основной целью недоступность для чтения, а ставит целью более сжатое, компактное и быстрое представление и преобразование текста. Шифрование ставит целью сделать сообщение недоступным для чтения без ключа к шифру.
Важной целью кодирования является сжатие сообщений. Пусть сообщение состоит из n символов и имеет вероятность р появления. Если это сообщение перекодировано в сообщение из m символов, то коэффициент сжатия сообщения равен k=m/n. Если рассматривать все l возможных кодировок n - символьных сообщений с вероятностями p i, i=1, 2,..., l, то среднестатистическое значение таких сообщений равно
Предел s n при n Если при кодировании коды (кодовые слова) отличаются (по порядку кодирования) друг от друга (попарно) только одним символом кода, то такие коды называют одношаговыми кодами или кодами Грея. Пример. АВС, АВВ, AАВ, САВ, ССВ - коды Грея некоторых слов. Для того чтобы декодирование было возможно, необходимо выполнение условия Фано: никакое кодовое слово не является началом другого кодового слова. Пример. Кодировку сообщения можно осуществить простой кодовой системой, называемой кодом Цезаря: каждый символ алфавита, на котором записано сообщение, заменяется другим, определенным символом этого же алфавита, например, отстоящим от него вторым символом алфавита. Этот несложный код можно расшифровать следующим образом: определяют относительные частоты символов закодированного текста, которые затем сравниваются с относительными частотами кодирующего текста; по совпадению этих частот устанавливаются соответствия символов (шифр). Пример. Закодируем, например, текст «Ясная погода» кодом Цезаря, устанавливая соответствия вида: «а» - «б», «б» - «в», «в» - «г» и т.д. Закодированный текст будет иметь вид: «Атоба рпдпеб». Если задан алфавит Х некоторых кодируемых сообщений, то расстоянием (Хэмминга) между двумя словами y 1, y 2 Пример. Если дан алфавит Х={0, 1} и слова x 1 =11001, x 2 =0101, х 3= Коды делятся на классы: коды с обнаружением и коды с исправлением ошибок. Пример. Код, который проверяет передаваемое или принимаемое сообщение на четность (в конце кодового слова передается признак четности или нечетности числа символов закодированного сообщения, а при приеме этот избыточный признак четности проверяется) - код с обнаружением ошибок. Код с двух- или трехкратным повторением символов (групп символов) передаваемого сообщения - код с исправлением (исправление - по максимуму одинаковых символов на соответствующих позициях передаваемых одинаковых групп слов). Контроль четности не может служить надежным способом защиты от искажений (шумов) в кодируемых сообщениях, ибо они с одинаковым успехом могут воспроизводить также и помехи. Пример. Искажения в четном числе разрядов не могут быть обнаружены при проверке кода на четность. Кратность обнаруживаемых искажений двоичных цифр в коде символа зависит от расстояния между словами. Этим, в частности, объясняется тот факт, что при увеличении скорости речи (примерно до 30 букв в сек. или до 40 бит в сек.) речь перестает быть воспринимаемой. Так называемое число Страуда (мысленных различий в сек.) лежит в пределах приблизительно 8-20 символов в сек. Отметим две важные теоремы (без доказательства). Теорема 1. Для того чтобы код позволял обнаруживать ошибки в не более m позициях кодового сообщения, необходимо и достаточно, чтобы наименьшее расстояние между кодовыми словами было не меньше m+1. Теорема 2. Для того чтобы код позволял исправлять все ошибки в не более чем m позициях, необходимо и достаточно, чтобы наименьшее расстояние между кодовыми словами было не меньше 2m+1.
|
|||||||||
|
|
Последнее изменение этой страницы: 2016-08-10; просмотров: 266; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.116.24.105 (0.042 с.) |
 X. Понятие знака неразрывно с тем, что им обозначается, они вместе могут рассматриваться как пара элементов (x,y), где x – знак, y – значение, обозначаемое этим знаком. Одни и те же знаки могут соответствовать различным понятиям.
X. Понятие знака неразрывно с тем, что им обозначается, они вместе могут рассматриваться как пара элементов (x,y), где x – знак, y – значение, обозначаемое этим знаком. Одни и те же знаки могут соответствовать различным понятиям.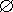 | =0.
| =0. S(X).
S(X).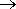 Y 1
Y 1 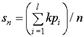
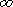 называется коэффициентом сжатия для данного метода (способа) кодирования.
называется коэффициентом сжатия для данного метода (способа) кодирования.


