
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Інкапсуляція як засіб структуризації.Содержание книги
Поиск на нашем сайте
Перелік питань до іспиту Contents Поняття алгоритмів. 1 Поняття даних. 1 Інкапсуляція як засіб структуризації. 1 Концепція структур даних. 1 Класифікація структур даних. 1 Базові операції над структурами даних. 2 Дані арифметичного типу. 2 Дані перерахованого типу. 2 Властивості статичних структур даних. 3 Масив як структура даних. 3 Розріджені масиви. 3 Множина як структура даних. 3 Структурний тип даних. 3 Об’єднання як структура даних. 4 Бітовий тип даних. 4 Таблиця як структура даних. 4 Особливості напівстатичних структур даних. 4 Стек як структура даних. 4 Черга як структура даних. 5 Дек як структура даних. 5 Лінійні списки. 5 Однонаправлений лінійний список. 5 Двонаправлений лінійний список. 5 Основні поняття мультисписків. 6 Стрічка як структура даних. 6 Зв’язне представлення даних. 6 Представлення графа як структури даних. 7 Дерево як структура даних. 7 33. Принципи формалізації алгоритмів. 10 34. Покрокове проектування алгоритмів. 10 35. Основні характеристики алгоритмів. 10 36. Поняття складності алгоритму. 10 37. Ефективність алгоритмів. 10 38. Правила аналізу складності алгоритмів. 10 39. Постановка задачі сортування. 10 43. Сортування розподілом. 11 45. Принципи рандомізації. 12 46. Постановка задачі пошуку. 12 52. Хешування даних. 13 53. Алгоритми розв’язання колізій при хешуванні. 13 54. Організація даних для пошуку. 13
Поняття алгоритмів. Алгор́итм — послідовність, система, набір систематизованих правил виконання обчислювального процесу, що обов'язково приводить до розв'язання певного класу задач після скінченного числа операцій. При написанні комп'ютерних програм алгоритм описує логічну послідовність операцій. Для візуального зображення алгоритмів часто використовують блок-схеми. Поняття даних. Дані — це інформація (найчастіше цифрова), подана у формалізованому вигляді, прийнятному для обробки автоматичними засобами за можливої участі людини.
Під структурою даних у загальному випадку розуміють множину елементів даних і множину зв’язків між ними. У програмуванні та комп'ютерних науках структу́ри да́них — це способи організації даних в комп'ютерах. Часто разом зі структурою даних пов'язується і специфічний перелік операцій, що можуть бути виконаними над даними, організованими в таку структуру.
Інкапсуляція як засіб структуризації. Ще одним досить продуктивним технологічним методом, який зв’язаний з структуризацією даних є інкапсуляція. Зміст її полягає у тому, що сконструйований новий тип даних – „будівельний блок” – оформляється таким чином, що його внутрішня структура стає недоступною для програміста – користувача цього типу. Концепція структур даних. Будь-яка структура даних може описуватися, таким чином, на трьох різних рівнях: · Функціональна специфікація – вказує для деякого класу імен операції, які дозволені з цими іменами, і властивості цих операцій; · Логічний опис – задає декомпозицію об’єктів на більш елементарні об’єкти і декомпозицію відповідних операцій на більш елементарні операції; · Фізичне представлення – дає метод розміщення в пам’яті комп’ютера тих величин, які складають структуру, і відношення між ними, а також спосіб кодування операцій на мові програмування. Класифікація структур даних. Розрізняються прості (базові) структури даних і інтегровані (структуровані). Простими називаються такі структури даних, які не можуть бути розділені на складові частини більші, ніж біти. Інтегрованими називаються такі структури даних, складовими частинами яких є інші структури даних – прості, але в свою чергу інтегровані. Інтегровані структури даних конструюються програмістом з використанням засобів інтеграції даних, які представляються мовами програмування. Залежно від наявності чи відсутності явно заданих зв’язків між елементами даних потрібно розрізняти незв’язні структури і зв’язні структури. Досить важлива ознака структури даних – її змінність – зміна кількості елементів і/або зв’язків між елементами структури.За ознакою змінності розрізняють структури статичні, напівстатичні, динамічні. Ще одна важлива ознака структури даних – характер впорядкованості її елементів. За цією ознакою структури можна поділити на лінійні й нелінійні структури. Базові операції над структурами даних. Над будь-якими структурами даних можуть виконуватися чотири загальні операції: створення, знищення, вибір (доступ), поновлення. Операція створення полягає у виділенні пам’яті для зберігання структури даних. Операція знищення структур даних протилежна до операції створення – вона звільнює пам’ять, яку займала структура, для подальшого використання. Операція вибору використовується програмістами для доступу до даних в самій структурі. Операція поновлення дозволяє змінити значення даних в структурі даних. Прикладом операції поновлення є операція присвоєння, або, більш складна форма – передача параметрів. Дані арифметичного типу. Стандартні типи даних часто називають арифметичними, оскільки їх можна використовувати в арифметичних операціях. Для опису основних типів визначено ключові слова: цілий, символьний, логічний, дійсний. За допомогою цілих чисел можна представити кількість об’єктів, яка є дискретною за своєю природою (тобто кількість об’єктів можна перерахувати). Внутрішнє представлення величин цілого типу – ціле число в бінарному коді. Внутрішнє представлення дійсного типу складається з двох частин – мантиси і порядку. Результати логічного типу отримуються при порівнянні даних будь-яких типів. Величини логічного типу можуть приймати тільки значення true і false. Внутрішня форма представлення значення false – 0 (нуль). Будь-яке інше значення інтерпретується як true. Значенням символьного типу є символи з деякої наперед визначеної множини. Ще одна група операцій над арифметичними типами – операції порівняння: „рівно”, „не рівно”, „більше”, „менше” і т.п. Дані перерахованого типу. Перерахований тип представляє собою впорядкований тип даних, який визначається програмістом, тобто програміст перераховує всі значення, які може приймати змінна цього типу. Діапазон значень перечислень визначається кількістю біт, які необхідні для представлення всіх його значень. Будь-яке значення цілого типу можна явно привести до перерахованого типу, але при виході за межі його діапазону результат буде невизначеним. При відсутності ініціалізації перша константа приймає нульове значення, а кожній наступній присвоюється на одиницю більше значення від попереднього. Властивості статичних структур даних. Статичні структури відносяться до класу структур, які представляють собою структуровану множину примітивних, базових структур. Оскільки статичні структури відрізняються відсутністю змінності, пам’ять для них виділяється автоматично – як правило, на етапі компіляції, або при виконанні – в момент активізації того програмного блоку, в якому вони описані. Масив як структура даних Масив – це така структура даних, яка характеризується:фіксованим набором елементів одного і того ж типу;кожний елемент має унікальний набір значень індексів;індекси визначають мірність масиву;звернення до елемента масиву виконується за ім’ям масиву і значенням індексів для даного елемента. Розріджені масиви. Розріджений масив – це масив, більшість елементів якого ОДНАКОВІ, так що зберігати в пам’яті достатньо лише невелику кількість значень, які вирізняються від «фонового» значення інших елементів. Розрізняють два типи розріджених масивів:масиви, в яких розташування елементів із значеннями, відмінними від фонового, можуть бути описані математично;масиви з випадковим розташуванням елементів. До масивів з математичним описом розташування елементів відносять масиви, в яких існують закономірності в розташуванні елементів зі значеннями, відмінними від фонового. До масивів з випадковим розташуванням елементів відносяться масиви, в яких не існує закономірностей у розташуванні елементів із значеннями відмінними від фонового. Множина як структура даних. Множина – така структура, яка є набором даних одного і того ж типу, що не повторюються (кожен елемент множини є унікальним). Порядок слідування елементів множини на має принципового значення. Над множинами визначені наступні специфічні операції: 1. Об’єднання множин. 2. Перетин множин. 3. Різниця множин. Результатом є множина, яка містить елементи першої множини, які не входять в другу множину. 4. Симетрична різниця. Результатом є множина, яка містить елементи, які входять до складу однієї або другої множини (але не обох). 5. Перевірка на входження елемента в множину.
Структурний тип даних. На відміну від масивів чи множин, усі елементи яких однотипні, структура може містити елементи різних типів.Елементи структури називаються полями структури і можуть мати довільний тип, крім типу цієї ж структури, але можуть бути покажчиками на неї. Самою найважливішою операцією для структури є операція доступу до вибраного поля структури – операція кваліфікації.
Бітовий тип даних. Бітові поля – це особливий вид полів структури. Вони використовуються для компактного розміщення даних, наприклад, прапорців типу „так/ні”. Мінімально адресована комірка пам’яті – 1 байт, а для зберігання прапорця достатньо одного біта. Бітові поля описуються за допомогою структурного типу. Над бітовими типами можливі три групи специфічних операцій: операції алгебри логіки, операції зсуву, операції порівняння.
Таблиця як структура даних. Елементами векторів і масивів можуть бути інтегровані структури. Одна з таких складних структур – таблиця. З фізичної точки зору таблиця є вектором, елементами якого є структури. Характерною логічною особливістю таблиць є те, що доступ до елементів таблиці проводиться не за номером (індексом), а за ключем – значення однієї з властивостей об’єкту, який описується структурою-елементом таблиці. Ключ – це властивість, що ідентифікує дану структуру в множині однотипних структур і є, як правило, унікальним в даній таблиці. Ключ може включатися до складу структури і бути одним з його полів, але може і не включатися в структуру, а обчислюватися за деякими її властивостями. Таблиця може мати один або декілька ключів. Стек як структура даних. Стек (стос, стіс) в програмуванні — різновид лінійного списку, структура даних, яка працює за принципом (дисципліною) «останнім прийшов — першим пішов» (LIFO, англ. last in, first out). Всі операції (наприклад, видалення елементу) в стеку можна проводити тільки з одним елементом, який знаходиться на верхівці стеку та був введений в стек останнім. Стек можна розглядати як певну аналогію до стопки тарілок, з якої можна взяти верхню, і на яку можна покласти верхню тарілку (інша назва стеку — «магазин», за аналогією з принципом роботи магазину в автоматичній зброї. Основні операції над стеком – включення нового елемента (push – заштовхувати) і виключення елемента зі стеку (pop – вискакувати). Черга як структура даних. Черга (queue) - динамічна структура даних, що працює за принципом «перший прийшов — перший пішов» (FIFO — first in, first out). У черги є голова (head) та хвіст (tail). Елемент, що додається до черги, опиняється в її хвості. Елемент, що видаляється з черги, знаходиться в її голові. Така черга повністю аналогічна звичній «базарній» черзі, в якій хто перший встав в неї, той першим буде обслуженим.
Дек як структура даних. Дек – особливий вид черги. Дек (deq – double ended queue, тобто черга з двома кінцями) – це такий послідовний список, в якому як включення, так і виключення елементів, може здійснюватися з будь-якого з двох кінців списку. Так само можна сформулювати поняття деку, як стек, в якому включення і виключення елементів може здійснюватися з обох кінців. Дек як двобічна черга— абстрактна структура даних, елементи якої можуть додаватись як на початок, так і в кінець. Лінійні списки. Лінійний список – це скінчена послідовність однотипних елементів (вузлів), можливо, з повторенням. Кількість елементів у послідовності називається довжиною списку. Вона в процесі роботи програми може змінюватися. Дерево як структура даних. Дерево – це граф, який характеризується наступними властивостями: · Існує єдиний елемент (вузол або вершина), на який не посилається ніякий інший елемент, – він називається коренем. · Починаючи з кореня і слідуючи по певному ланцюжку покажчиків, що містяться в елементах, можна здійснити доступ до будь-якого елемента структури. · На кожний елемент, крім кореня, є єдине посилання, тобто кожний елемент адресується єдиним покажчиком. 29. Алгоритм перетворення дерева в бінарне. Правило побудови бінарного дерева з будь-якого дерева: 1. В кожному вузлі залишити тільки гілку до старшого сина; 2. З’єднати горизонтальними ребрами всіх братів одного батька; 3. Таким чином перебудувати дерево за правилом: лівий син – вершина, розташована під даною; правий син – вершина, розташована праворуч від даної (тобто на одному ярусі з нею). 4. Розвернути дерево так, щоб усі вертикальні гілки відображали лівих синів, а горизонтальні – правих. У результаті перетворення будь-якого дерева, в бінарне, виходить дерево у вигляді лівого піддерева, підвішеного до кореня. 30. Представлення дерев у пам’яті. Представити m -арне дерево в пам’яті комп’ютера складно, так як кожен елемент дерева повинен містити стільки покажчиків, скільки ребер, виходить з вузла. Це приведе до підвищеної витрати пам’яті, різноманітності початкових елементів і ускладнить алгоритми обробки дерева. Тому m -арні дерева, ліс необхідно привести до бінарних для економії пам’яті і спрощенню алгоритмів. Усі вузли бінарного дерева представляються в пам’яті однотипними елементами з двома покажчиками, крім того, операції над бінарними деревами виконуються просто і ефективно. Дерева можна представляти за допомогою зв’язних списків і масивів (або послідовних списків). Частіше всього використовується зв’язне представлення дерев, так як воно дуже сильно нагадує логічне. Зв’язне зберігання полягає в тому, що задається зв’язок від батька до синів. В бінарному дереві є два покажчики, тому зручно вузол представити у вигляді структури в якій left – покажчик на ліве піддерево, right – покажчик на праве піддерево, inf – містить інформацію, яка зв’язана з вершиною і має наперед визначений тип – data. 31. Операції над деревами. Над деревами визначені наступні основні операції: 1) Пошук вузла із заданим ключем. 2) Додавання нового вузла. 3) Видалення вузла (піддерева). 4) Обхід дерева в певному порядку: Низхідний обхід; Змішаний обхід; Висхідний обхід. 32. Алгоритми обходу дерева. Схемно алгоритм обходу бінарного дерева відповідно до низхідного способу може виглядати таким чином: 1. В якості чергової вершини взяти корінь дерева. Перейти до пункту 2. 2. Провести обробку чергової вершини відповідно до вимог задачі. Перейти до пункту 3. 3.а) Якщо чергова вершина має обидві гілки, то в якості нової вершини вибрати ту вершину, на яку посилається ліва гілка, а вершину, на яку посилається права гілка, занести в стек; перейти до пункту 2; 3.б) якщо чергова вершина є кінцевою, то вибрати в якості нової чергової вершини вершину із стека, якщо він не порожній, і перейти до пункту 2; якщо ж стек порожній, то це означає, що обхід всього дерева закінчений, перейти до пункту 4; 3.в) якщо чергова вершина має тільки одну гілку, то в якості чергової вершини вибрати ту вершину, на яку ця гілка вказує, перейти до пункту 2. 4. Кінець алгоритму. Алгоритм істотно спрощується при використовуванні рекурсії. Так, низхідний обхід можна описати таким чином: 1). Обробка кореневої вершини; 2). Низхідний обхід лівого піддерева; 3). Низхідний обхід правого піддерева. Змішаний обхід можна описати таким чином: 1) Спуститися по лівій гілці із запам’ятовуванням вершин в стеку; 2) Якщо стек порожній те перейти до п.5; 3) Вибрати вершину із стеку і обробити дані вершини; 4) Якщо вершина має правого сина, то перейти до нього; перейти до п.1. 5) Кінець алгоритму. Рекурсивний змішаний обхід описується таким чином: 1) Змішаний обхід лівого піддерева; 2) Обробка кореневої вершини; 3) Змішаний обхід правого піддерева. Алгоритм висхідного обходу можна представити таким чином: 1) Спуститися по лівій гілці із запам’ятовуванням вершини в стеку як 1-й вид стекових записів; 2) Якщо стек порожній, то перейти до п.5; 3) Вибрати вершину із стека, якщо це перший вид стекових записів, то повернути його в стек як 2-й вид стекових записів; перейти до правого сина; перейти до п.1, інакше перейти до п.4; 4) Обробити дані вершини і перейти до п.2; 5) Кінець алгоритму. Рекурсивний змішаний обхід описується таким чином: 1). Висхідний обхід лівого піддерева; 2). Висхідний обхід правого піддерева; 3). Обробка кореневої вершини. Ефективність алгоритмів. Сортування розподілом. 44. Сортування злиттям. В основі цього способу сортування лежить злиття двох упорядкованих ділянок масиву в одну впорядковану ділянку іншого масиву. Злиття двох упорядкованих послідовностей можна порівняти з перебудовою двох колон солдатів, вишикуваних за зростом, в одну, де вони також розташовуються за зростом. Якщо цим процесом керує офіцер, то він порівнює зріст солдатів, перших у своїх колонах і вказує, якому з них треба ставати останнім у нову колону, а кому залишатися першим у своїй. Так він вчиняє, поки одна з колон не вичерпається — тоді решта іншої колони додається до нової. Принципи рандомізації. Постановка задачі пошуку. 47. Послідовний пошук. Найпростішим методом пошуку елемента, який знаходиться в неврегульованому наборі даних, за значенням його ключа є послідовний перегляд кожного елемента набору, який продовжується до тих пір, поки не буде знайдений потрібний елемент. Якщо переглянуто весь набір, і елемент не знайдений – значить, шуканий ключ відсутній в наборі. Цей метод ще називають методом повного перебору. 48. Бінарний пошук. Іншим, відносно простим, методом доступу до елемента є метод бінарного (дихотомічного) пошуку, який виконується в явно впорядкованій послідовності елементів. Оскільки шуканий елемент швидше за все знаходиться „десь в середині”, перевіряють саме середній елемент: a[N/2]==key? Якщо це так, то знайдено те, що потрібно. Якщо a[N/2]<key, то значення i=N/2 є замалим і шуканий елемент знаходиться „праворуч”, а якщо a[N/2]>key, то „ліворуч”, тобто на позиціях 0…i. Для того, щоб знайти потрібний запис в таблиці, у гіршому випадку потрібно log2(N) порівнянь. Це значно краще, ніж при послідовному пошуку. 49. Пошук методом інтерполяції. Якщо немає ніякої додаткової інформації про значення ключів, крім факту їхнього впорядкування, то можна припустити, що значення key збільшуються від a[0] до a[N-1] більш-менш „рівномірно”. Це означає, що значення середнього елементу a[N/2] буде близьким до середнього арифметичного між найбільшим та найменшим значенням. Але, якщо шукане значення key відрізняється від вказаного, то є деякий сенс для перевірки брати не середній елемент, а „середньо-пропорційний”. Вираз для поточного значення i одержано з пропорційності відрізків:
В середньому цей алгоритм має працювати швидше за бінарний пошук, але у найгіршому випадку буде працювати набагато довше. 50. Пошук методом „золотого перерізу”. Деякий ефект дає використання так званого „золотого перерізу”. Це число
Доданій корінь Згідно цього алгоритму відрізок слід ділити не навпіл, як у бінарному алгоритмі, а на відрізки, пропорційні 51. Алгоритми пошуку послідовностей. КМП-пошук дає справжній виграш тільки тоді, коли невдачі передувала деяка кількість збігів. Лише у цьому випадку слово зсовується більше ніж на одиницю. На жаль, це швидше виняток, ніж правило: збіги зустрічаються значно рідше, ніж незбіги. Тому виграш від практичного використання КМП-стратегії в більшості випадків пошуку в звичайних текстах досить незначний. Метод, який запропонували Р. Боуєр і Д. Мур в 1975 р., не тільки покращує обробку самого поганого випадку, але й дає виграш в проміжних ситуаціях. БМ-пошук базується на незвичних міркуваннях – порівняння символів починається з кінця слова, а не з початку. Як і у випадку КМП-пошуку, слово перед фактичним пошуком трансформується в деяку таблицю. Нехай для кожного символу x із алфавіту величина dx – відстань від самого правого в слові входження x до правого кінця слова. Уявимо, що виявлена розбіжність між словом і текстом. У цьому випадку слово відразу ж можна зсунути праворуч на dpM-1 позицій, тобто на кількість позицій, швидше за все більше одиниці. Якщо символ, який не збігся, тексту в слові взагалі не зустрічається, то зсув стає навіть більшим, а саме зсовувати можна на довжину всього слова. Хешування даних. Перелік питань до іспиту Contents Поняття алгоритмів. 1 Поняття даних. 1 Інкапсуляція як засіб структуризації. 1 Концепція структур даних. 1 Класифікація структур даних. 1 Базові операції над структурами даних. 2 Дані арифметичного типу. 2 Дані перерахованого типу. 2 Властивості статичних структур даних. 3 Масив як структура даних. 3 Розріджені масиви. 3 Множина як структура даних. 3 Структурний тип даних. 3 Об’єднання як структура даних. 4 Бітовий тип даних. 4 Таблиця як структура даних. 4 Особливості напівстатичних структур даних. 4 Стек як структура даних. 4 Черга як структура даних. 5 Дек як структура даних. 5 Лінійні списки. 5 Однонаправлений лінійний список. 5 Двонаправлений лінійний список. 5 Основні поняття мультисписків. 6 Стрічка як структура даних. 6 Зв’язне представлення даних. 6 Представлення графа як структури даних. 7 Дерево як структура даних. 7 33. Принципи формалізації алгоритмів. 10 34. Покрокове проектування алгоритмів. 10 35. Основні характеристики алгоритмів. 10 36. Поняття складності алгоритму. 10 37. Ефективність алгоритмів. 10 38. Правила аналізу складності алгоритмів. 10 39. Постановка задачі сортування. 10 43. Сортування розподілом. 11 45. Принципи рандомізації. 12 46. Постановка задачі пошуку. 12 52. Хешування даних. 13 53. Алгоритми розв’язання колізій при хешуванні. 13 54. Організація даних для пошуку. 13
Поняття алгоритмів. Алгор́итм — послідовність, система, набір систематизованих правил виконання обчислювального процесу, що обов'язково приводить до розв'язання певного класу задач після скінченного числа операцій. При написанні комп'ютерних програм алгоритм описує логічну послідовність операцій. Для візуального зображення алгоритмів часто використовують блок-схеми. Поняття даних. Дані — це інформація (найчастіше цифрова), подана у формалізованому вигляді, прийнятному для обробки автоматичними засобами за можливої участі людини.
Під структурою даних у загальному випадку розуміють множину елементів даних і множину зв’язків між ними. У програмуванні та комп'ютерних науках структу́ри да́них — це способи організації даних в комп'ютерах. Часто разом зі структурою даних пов'язується і специфічний перелік операцій, що можуть бути виконаними над даними, організованими в таку структуру.
Інкапсуляція як засіб структуризації. Ще одним досить продуктивним технологічним методом, який зв’язаний з структуризацією даних є інкапсуляція. Зміст її полягає у тому, що сконструйований новий тип даних – „будівельний блок” – оформляється таким чином, що його внутрішня структура стає недоступною для програміста – користувача цього типу. Концепція структур даних. Будь-яка структура даних може описуватися, таким чином, на трьох різних рівнях: · Функціональна специфікація – вказує для деякого класу імен операції, які дозволені з цими іменами, і властивості цих операцій; · Логічний опис – задає декомпозицію об’єктів на більш елементарні об’єкти і декомпозицію відповідних операцій на більш елементарні операції; · Фізичне представлення – дає метод розміщення в пам’яті комп’ютера тих величин, які складають структуру, і відношення між ними, а також спосіб кодування операцій на мові програмування.
|
||||
|
|
Последнее изменение этой страницы: 2016-08-01; просмотров: 315; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.15.26.231 (0.018 с.) |


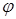 , що має властивість:
, що має властивість:
 і є золотим перерізом.
і є золотим перерізом.


