Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Кодирование текстовых данныхСодержание книги Поиск на нашем сайте
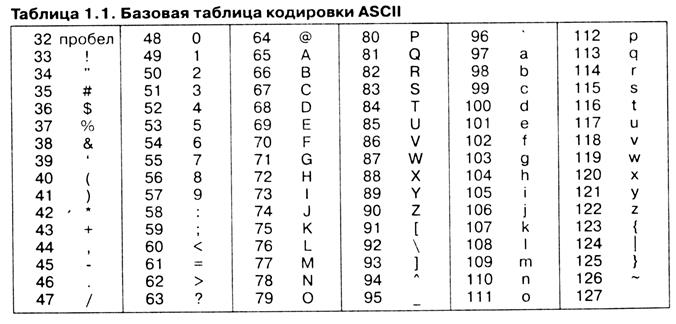
Если каждому символу алфавита сопоставить определенное целое число (например, порядковый номер), то с помощью двоичного кода можно кодировать и текстовую информацию. Восьми двоичных разрядов достаточно для кодирования 256 различных символов. Этого хватит, чтобы выразить различными комбинациями восьми битов все символы английского и русского языков, как строчные, так и прописные, а также знаки препинания, символы основных арифметических действий и некоторые общеприменяемые специальные символы. В таком случае всякий символ будет иметь информационный объем в 1 байт. Для того чтобы весь мир одинаково кодировал текстовые данные, нужны единые таблицы кодирования символов. Для английского языка, захватившего де-факто нишу международного средства общения, противоречия уже сняты. Институт стандартизации США (ANSI—American National Standard Institute) ввел в действие систему кодирования ASCII (American Standard Code for Information Interchange – стандартный код информационного обмена США). В системе ASCII закреплены две таблицы кодирования – базовая и расширенная. Базовая таблица закрепляет значения кодов от 0 до 127, а расширенная относится к символам с номерами от 128 до 255. Первые 32 кода базовой таблицы, начиная с нулевого, отданы производителям аппаратных средств (в первую очередь производителям компьютеров и печатающих устройств). В этой области размещаются управляющие коды, которым не соответствуют никакие символы языков, и, соответственно, эти коды не выводятся ни на экран, ни на устройства печати, но ими можно управлять тем, как производится вывод прочих данных. Начиная с кода 32 по код 127 размещены коды символов английского алфавита, знаков препинания, цифр, арифметических действий и некоторых вспомогательных символов. Базовая таблица кодировки ASCII приведена в таблице 1.1.
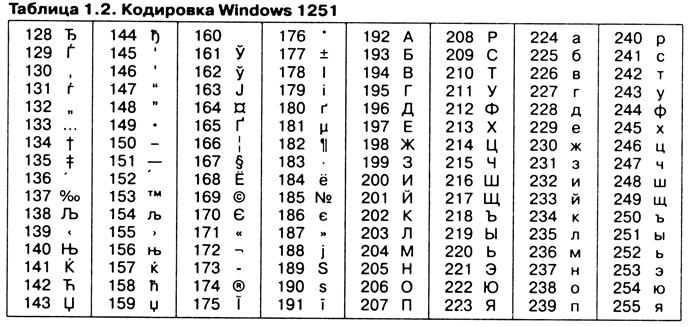
Аналогичные системы кодирования текстовых данных были разработаны и в других странах. Так, например, в СССР в этой области действовала система кодирования КОИ-7 (код обмена информацией, семизначный). Однако поддержка производителей оборудования и программ вывела американский код ASCII на уровень международного стандарта, и национальным системам кодирования пришлось «отступить» во вторую, расширенную часть системы кодирования, определяющую значения кодов со 128 по 255. Отсутствие единого стандарта в этой области привело к множественности одновременно действующих кодировок. Только в России можно указать три действующих стандарта кодировки и еще два устаревших. Так, например, кодировка символов русского языка, известная как кодировка Windows-1251, была введена «извне» — компанией Microsoft, но, учитывая широкое распространение операционных систем и других продуктов этой компании в России, она глубоко закрепилась и нашла широкое распространение (таблица 1.2). Эта кодировка используется на большинстве локальных компьютеров, работающих на платформе Windows.
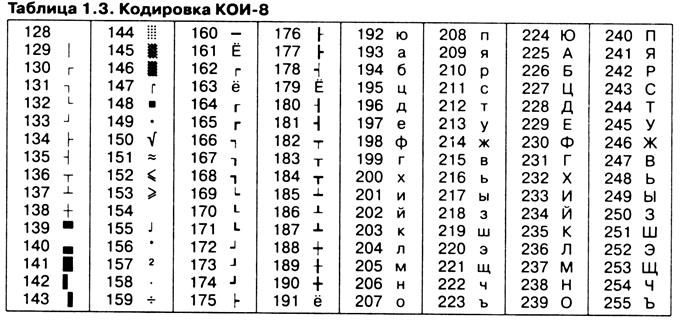
Другая распространенная кодировка носит название КОИ-8 (код обмена информацией, восьмизначный), таблица 1.3. Сегодня кодировка КОИ-8 имеет широкое распространение в компьютерных сетях на территории России и в российском секторе Интернета.
Недостаток таких систем кодирования текстов вызван ограниченным набором кодов (256). Если, например, кодировать символы не восьмиразрядными двоичными числами, а числами с большим количеством разрядов, то и диапазон возможных значений кодов станет намного больше. Так система, основанная на 16-разрядном кодировании символов, получила название универсальной — UNICODE. Шестнадцать разрядов позволяют обеспечить уникальные коды для 256 х 256 = 65 536 различных символов — этого достаточно для размещения в одной таблице символов большинства языков планеты. Оборотной стороной этого является увеличенная информационная емкость одного символа: всякий символ в UNICODE требует для его хранения 2 байта памяти, т. е. в этой системе все текстовые документы автоматически становятся вдвое длиннее. Во второй половине 90-х годов технические средства достигли необходимого уровня обеспеченности ресурсами, и наблюдается постепенный перевод документов и программных средств на UNICODE. Пример 1 из теста Министерства образования и науки РФ
Решение. Количество переданных битов 256 000бит/с* 2*60с = 30 720 000 бит. В байтах 30 720 000 / 8 = 3 840 000 б. В килобайтах 3 840 000 / 1024 = 3750 Кб. Пример 2 из теста Министерства образования и науки РФ
Решение. Объем сообщения изменился на 1024*1024/512 = 2048 б. В UNICODE сообщение занимало 4096 б, а теперь уменьшилось вдвое и занимает 2048 б. В ASCII один символ требует 1 б памяти, следовательно, сообщение содержит 2048 символов. Пример 3 из теста Министерства образования и науки РФ
Решение. (самостоятельно).
|
||||
|
|
Последнее изменение этой страницы: 2016-08-01; просмотров: 252; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.14.249.191 (0.008 с.) |