Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Аналіз класів пам’яті зміннихСодержание книги
Поиск на нашем сайте
Аналіз класів пам’яті змінних Кожен об’єкт програми (змінна, функція,...) має свій тип і клас пам’яті (клас зберігання). Тип визначає обсяг пам’яті для об’єкта і операції, що можуть виконуватись над об’єктом, а клас пам'яті задає місце розташування об'єкта (внутрішні регістри мікропроцесора, сегмент даних, сегмент стека тощо) та встановлює для нього час існування, тобто час, протягом якого об‘єкт зберігається в пам‘яті. На відміну від типу, клас пам’яті можна явно не вказувати, тоді він встановлюється компілятором за правилами замовчання, в залежності від розташування ідентифікатора в тексті програми. Із класом пам’яті тісно пов’язані поняття області визначення та області видимості. Областю визначення називається та частина коду програми, в межах якої ідентифікатор може використовуватися для доступу. Є різні області визначення: в межах блоку (локальна область визначення), в межах функції, в межах файлу тексту програми. Область видимості –область вихідного тексту програми, із меж якої можливий коректний доступ до пам’яті або функції з використанням ідентифікатора. Клас пам’яті змінної завжди задається розташуванням її опису або за допомогою ключового слова (специфікатор класу пам’яті), який розташовується перед звичайним описом. Для змінних існує 4 класи пам’яті: § auto - клас за замовчуванням. Автоматичні змінні – це завжди локальні змінні і розташовуються або у стеку, або у регістрах. Час життя таких змінних – це час виконання функції або блока; § register - зберігання змінної у регістрі процесора, дає змогу істотно скоротити час звертання до змінних, за відсутності вільних регістрів змінна буде опрацьовуватись як змінна з класом auto (тобто компілятор не зобов’язаний виконувати умову розташування змінної у регістрах); така змінна не має адреси; § static - статичні змінні існують протягом усього часу виконання програми, проте областю їх дії залишається той блок, у якому вони оголошені; всі глобальні змінні за замовчанням мають цей клас пам’яті, але не будь-яка змінна з цим класом пам’яті глобальна. § extern - змінні є посиланнями на відповідні зовнішні змінні та роблять ці змінні видимими (оголошеними) в межах поточного файлу. Аналіз класів пам’яті функцій.
Для функції існує всього два класи памяті extern та static. Правила визначення області видимості для функцій відрізняються від правил видимості для змінних: - Функція, оголошена як static, видима в межах того файла, в якому вона визначена. Кожна функція може викликати іншу функцію з класом памяті static зі свого вихідного файла, але не може викликати функцію, оголошену з класом static в іншому вихідному файлі. Різні функції з класом пам'яті static, що мають однакові імена, можуть бути визначені в різних вихідних файлах, і це не приведе до конфлікту; - Функція, оголошена з класом памяті extern, видима в межах всіх вихідних файлів програми. Будь-яка функція може викликати функції з класом памяті extern; - Якщо в оголошенні функції відсутній специфікатор класа памяті, то за замовчанням приймається клас extern. Концепція типу у мові програмування. Аналіз відомих методів типізації Тип даних в мові програмування визначає сукупність значень, які може набувати змінна і сукупність дій, які можуть бути виконані. Системи типізації різних мов програмування істотно різняться одна від одної. Найістотніші відмінності полягають в реалізаціях компіляції та поведінки під час виконання програми. У зв’язку із введенням поняття типу даних слід сказати про існування статичної та динамічної типізації. Статична типізація - змінна зв’язується із типом у момент оголошення змінної і тип не може бути змінений пізніше.(приклад - Pascal) Динамічна типізація - змінна зв’язується із типом у момент присвоювання значення, а не у момент оголошення змінної(приклад - JavaScript). Присвоєння типу даних (типізація) надає значення набору бітів. Як правило, типи надаються або значенням в пам'яті, або об'єктам, таким, як змінні. Системи типізації виконують наступні функції: § Безпечність — застосування типів даних дозволяє компілятору знаходити беззмістовний або невірний код. Наприклад, можна визначити вираз "Привіт!" + 3 як невірний, оскільки додавання (в загальному розумінні) рядка до цілого числа не має сенсу. § Оптимізація — статична перевірка типів може повідомити додаткову інформацію компілятору. § Документування — у виразнішіх системах типізації, типи даних можуть служити як вид документації, оскільки вони можуть описувати наміри розробника. Наприклад, довжина може бути підтипом цілих чисел, але, якщо розробник об'являє повертаємий функцією тип даних як довжину, а не просто ціле число, це може частково описувати значення функції.
§ Абстрагування (або модульність) — типи даних дозволяють розробнику розмірковувати про програми на вищому рівні, не звертаючи увагу на деталі реалізації на нижчому рівні. Наприклад, розробник може вважати рядок значенням, замість простого масиву байт. Якщо мова програмування вимагає точного зіставлення типів даних (тобто, дозволяючи лише такі операції автоматичного приведення типів, які не призводять до втрати інформації), така мова програмування має сильну типізацію, в іншому випадку, слабку. Усі типи даних будемо поділяти на базові та складані. Серед базових (або стандартних, або простих, або елементарних) звичайно виділяють такі:
· Boolean - дані логичного типу, з двома значеннями: true та false (правда та хибність). · Char - це множина символів, що можуть бути надруковані. Формально слід розрізнювати цей тип з типом Byte, хоча фактично для зберігання символу у пам'яті використовується рівно один байт, і, таким чином, є деяка відповідність між цими типами даних. Правила формування атрибутів доступу до членів похідного класу в залежності від атрибуту доступу базового класу та заданого атрибуту у списку спадкування. Наведемо таблицю правил формування атрибутів доступу у похідному класі в залежності від атрибуту доступу у базовому класі та атрибуту доступу заданому у базовому списку.
Технічно специфікатор доступу у базовому списку не обов’язковий. Якщо специфікатор доступу не вказаний, а похідний клас визначений ключовим словом class,то базовий за замовчуванням спадкується як закритий. Якщо похідний клас визначений з ключовим словом struct, то базовий клас за замовчанням спадкується, як відкритий. Важливо розуміти, що якщо специфікатор доступу є private, то хоча відкриті члени базового класу стають закритими у похідному, вони залишаються доступними для функцій членів похідного класу. Приклад #include <iostream> public: void setx(int n) { x = n; } void showxO { cout << x << '\n'; } }; class derived: private base { int y; public: void setxy(int n, int m) { setx(n); у = га; } void showxyO { showxf); cout << у << '\n'; } }; int main () { derived ob; ob.setxy(O, 20); ob.showxy(); return 0; } Матриця інцидентності Ребро і її вершина називаються інцидентними. Матриця інцидентності це двовимірний масив розміром N*M:
Статичний: int Graph[N][M]; Динамічний: int** Graph; //масив массивів (тобто двовимірний масив) Graph=new int*[N]; //виділяємо пам’ять для масиву вказівників (на масиви) for (int i=0; i<N; i++) Graph[i]=new int[M]; // виділяємо пам’ять для кожного рядка M кількість ребер. При цьому Graph[i][j] дорівнює 0, якщо вершини i та ребро j не є інцидентними, -1, якщо вершина i є кінцем орієнтованого ребра j, +1, якщо вершина i є початком орієнтованого ребра j. Інколи зручно користуватись означенням, у якому Graph[i][j] рівний вазі ребра (дуги) j, що є інцидентним вершині i.
Матриця інцидентності найкраще підходить для операції перерахування ребер, що є інцидентними вершині x. Списки суміжності Список суміжності це послідовність (масив, список) розміром N, кожен елемент якої є списком вершин суміжних з даною: Статична структура: struct NodeType { int count; //кількість вершин суміжних з даною struct { int Node; //номер вершини int Weight; //номер ребер } List[N]; //масив суміжних вершин та ваг ребер, що їх з’єднують } Graph[N]; Динамічна(у вигляді масиву однозв’язних списків): struct NodeType { NodeType* next; struct { int Node; int Weight; } item; } *Graph=new NodeType[N]; Цей спосіб збереження найкраще підходить для перерахування усіх вершин суміжних з x. Список ребер Статичний: struct { int Node1; //звідки ребро int Node2; //куди int Weight; //вага } Branches[M]; Динамічний (у вигляді списку): struct NodeType { NodeType* next; struct { int Node1; int Node2; int Weight; } item; } FirstBranch; Як видно з цієї таблиці, цей спосіб збереження графа є особливо зручним, якщо головною операцією є перерахування ребер або пошук вершин і ребер, що знаходяться у відносинах інцидентності. Статичні підходи застосовують тоді, коли кількість ребер відома наперед (відома на етапі компіляції). Динамічний підхід застосовують тоді, коли кількість ребер невідома наперед(визначається в процесі виконання). Приклад 1.
Результати роботи:
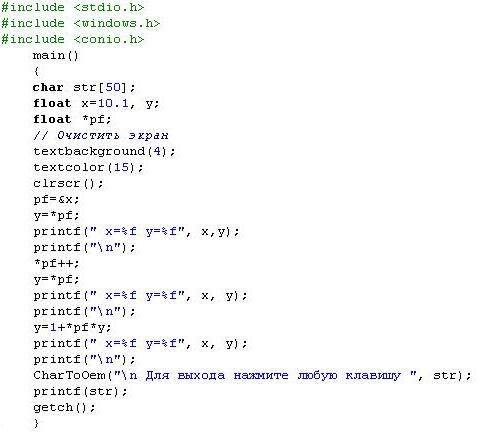
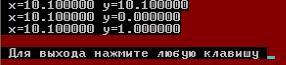
Пояснимо використання команд Команда pf = & x означає "взяти адресу числа, що знаходиться в x і записати його в pf. Наступна команда y = * pf дозволяє записати значення, розташоване за вказаною в pf адресою, в y. Тому в першому рядку результатів зазначеної програми: x = 10.100000 y = 10.100000. Далі в команді * pf + + відбувається зміна адреси. Наступна команда y = * pf дозволяє записати значення, розташоване за адресою, вказаною в pf. Ця адреса щойно була збільшена на 1 у попередній команді. Тому у другому рядку результатів програми в y знаходиться вже інше число, а саме нуль. Наступна команда y = 1 + *pf *y додає до одиниці добуток адреси з pf на вміст y. Як показано в попередньому поясненні, до цього часу в y знаходиться число нуль. Тому в третьому рядку роботи програми маємо саме такі результати. Приклад 2. Вивести значення масиву звичайним способом і з використанням покажчиків. # Include <stdio.h> int a[6] = {10,20,30,40,50,60}; / Оголошення і ініціалізація масиву / main () { int i, * p; for (i = 0; i <6; i + +) printf ("% d", a [i]); / вивід масиву звичайним способом / for (p = & a [0]; p <= & a [5]; p + +) printf ("% d", * p) / вивід масиву з використанням покажчика / for (p = & a [0], i = 0; i <6; i + +) printf ("% d", p [i]); / ще один варіант з використанням покажчика /
} Приклад 3. Задано матриця а. Вивести на екран елементи головної діагоналі, першого рядка і значень перших елементів кожного рядка матриці, застосувавши для цього покажчики. # Include <stdio.h> int a[3][3] = {{10,20,30}, {40,50,60}, {70,80,90}}; /Оголошення і ініціалізація двовимірного масиву / int *pa[3] = {a[0], a[1], a[2]}; / Оголошення і ініціалізація покажчика ра на рядки масиву а і присвоєння початкових значень: pa[0] = a[0]; pa[1] = a[1]; pa[2] = a[2] / int p = a[0]; / оголошення покажчика на нульовий елемент нульової рядка масиву а / main () {Int i; for (i = 0; i <9; i + = 4) printf ("% d", * (p + i)); / вивід на екран елементів головної діагоналі / for (i = 0; i <3; i + +) printf ("% d", * p [i]); / вивід на екран елементів першого рядка / for (i = 0; i <3; i + +) printf ("% d", pa [i]); / вивід на екран перших елементів кожного рядка матриці/ } Зробимо деякі пояснення для першого оператора циклу. Уявімо матрицю у вигляді одновимірного масиву, записаного по рядках: a[0][0], a[0][1], a[0][2], a[1][0], a[1][1], a[1][2], a[2][0], a[2][1], a[2][2].
Поняття об’єкту в мові VHDL Цифрову електронну схему можна уявити як модуль із кількома входами та виходами. Сигнали на виходах являють собою деякі функції вхідних сигналів. У термінології VHDL модуль є об’єктом (entity) проекту. Об’єкт проекту має вказані в його оголошенні входи та виходи, які називаються портами (port) та виконує описані в його архітектурному тілі (architecture) функції. Об’єкти проекту часто відповідають окремим функціонально закінченим модулям, таким як логічні елементи, мікросхеми, плати тощо. Цифрова схема зазвичай розробляється як ієрархічна сукупність модулів. Кожен модуль має набір портів, які складають його інтерфейс. У VHDL об’єкт – такий модуль, він може використовуватися як компонент проекту чи може бути модулем верхнього рівня. Основний синтаксис оголошення об’єкта: оголошення_об’єкта::= entity ідентифікатор is заголовок_об’єкта розділ_оголошень_об’єкта [begin операторна_частина_оголошення_об’єкта ] end [ просте ім’я об’єкта ]; заголовок_об’єкта::= [розділ_формальних_параметрів_настроювання] [розділ_формальних_портів] розділ_параметрів_настроювання::= generic (список_параметрів_настроювання); список_параметрів_настроювання::= інтерфейс ний_список_параметрів_настроювання розділ_портів::= port (список портів); список_портів::= інтерфейсний_список_портів розділ_оголошень_об’єкта::={елемент_оголошення_об’єкта}
У розділі оголошень об’єкта можуть оголошуватися елементи, які використовуватимуться у реалізації цього об’єкта. Частіше вони оголошуються саме у реалізації (в архітектурному тілі об’єкта). Також в оголошення можуть бути розташовані необов’язкові оператори, призначені для контролю за роботою об’єкта. Заголовок об’єкта – найважливіша частина оголошення об’єкта. Він включає специфікацію параметрів настроювання, що використовуються для керування а структурою та поведінкою об’єкта та портів, через які інформація передається в об’єкт і з нього. Усі параметри настроювання мають оголошуватися як інтерфейсні константи. Порти об’єкта визначаються з використанням інтерфейсного списку, подібного до інтерфейсного списку параметрів настроювання, але всі його елементи мають бути сигналами. Змінні не можуть використовуватися в інтерфейсах об’єктів.
Приклад оголошення об’єкта: entity processor is generic (max_clock_freq: frequency:= 30 MHz) port (clock: in bit; address: out integer); end processor; Після оголошення об’єкта його реалізація має бути описана в архітектурному тілі. Одному об’єкту може відповідати кілька архітектурних тіл. Кожне архітектурне туло являє собою різне представлення об’єкта. Наприклад, одне архітектурне тіло може описувати поведінку за допомогою алгоритмічних засобів, інші – можуть описувати структуру об’єкта як ієрархічну сукупність з’єднаних між собою компонентів. Оголошення в архітектурному тілі визначають елементи, що використовуватимуться для створення опису об’єкта. Зокрема, тут можуть бути оголошені сигнали й компоненти, які згодом використовуватимуться для створення структурного опису.
Begin операторна_частина_процесу end process [мітка_процесу]; Розділ оголошень процесу визначає об’єкти, що використовуються локально у межах процесу. Змінні, оголошені у процесі, зберігають свої значення між активаціями процесу й використовуються для збереження стану системи, вони є невидимими в інших процесах. Оператор_призупинення_процесу::= wait [специфікатор_чутливості] [специфікатор_умови] [специфікатор_часу]; специфікатор_чутливості::= on список_чутливості список_чутливості::= ім’я_сигналу{,ім’я_сигналу} специфікатор_умови::= until умова специфікатор_часу::= for вираз_часу Список чутливості оператора wait визначає набір сигналів, до яких процес є чутливим, коли призупинений. Якщо будь-який із цих сигналів змінюється, виконання процесу відновлюється і він перевіряє умову. При істинності (відсутності) умови виконання процесу продовжується із наступного оператора (або початку, якщо оператор wait був останнім), інакше – призупиняється знову. При відсутноті списку чутливості, процес є чутливим до всіх сигналів, згаданих в умові.
Begin u1: n_or – створення примірника u1 компонента n_or generic map (5ns) -- специфікація параметра настроювання port map (a=>s, b=>st2, c=>st1); -- приєднання сигналів до портів компонента U2: n_or – створення примірника u2 компонента n_or generic map (5ns) port map (st1, r, st2); q<= st1; qn<=st2; end structure; У цьому архітектурному тілі спочатку було оголошено компонент n_or, потім два внутрішніх сигнали st1 i st2. Далі створено два примірники компонента n_or та з’єднано їх порти із внутрішніми сигналами та портами об’єкта rstrg. Наприклад, як бачимо для u1 у дужках після port map вказується, що його порт а з’єднується з портом s тригера, а порти b та c зі внутрішніми сигналами st2 та st1 відповідно. Тут з’єднання задаються іменами,а для u2 – позиціями. Тобто на першій позиції стоїть st1, на другій – r. На третій – st2, це означає, що вони будуть з’єднані відповідно з портами a, b і c (в такому порядку як і в оголошенні компонента). Таким чином здійснено структурний опис RS – тригера.
Планування транзакцій та драйвер сигналу в мові VHDL Це питання тісно пов’язано із моделлю дискретного часу, тому не має дивувати певне перекриття матеріалу. Отже, як відомо при моделюванні виконується розрахунок сигналів у дискретні моменти часу. Якщо у деякий момент часу один чи кілька вхідних сигналів об’єкта змінилися, то об’єкт реагує на ці зміни шляхом планування нових значень, що будуть присвоєні сигналам, які з’єднані з його виходами у пізніші моменти часу. Це називається плануванням транзакцій сигналу. Нові значення вихідних сигналів розраховуються шляхом виконання коду, який описує об’єкти. Кожна трансакція характеризується часом, на який вона запланована, і значенням, яке має прийняти сигнал у цей час. Множина запланованих транзакцій складає зміст драйверу. Інформація про нову транзакцію додається до драйверу сигналу оператором присвоювання значення сигналу, в якому вказується значення сигналу, що планується, і затримка між часом, коли виконується цей оператор, і часом, на який буде заплановано цю трансакцію. Якщо затримка явно не вказана в операторі присвоювання значення сигналу, то трансакцію буде заплановано на наступний крок моделювання. Така затримка називається дельта-затримкою. Але у будь-якому випадку трансакція виконується пізніше ніж оператор, що її планує. Для повного розуміння питання непогано було би розглянути більш детально процес моделювання адже поняття трансакції відіграє тут далеко не останню роль. І взагалі цей розгляд дасть можливість практично зрозуміти, де це використовується. (АЛЕ ЦЕ ТІЛЬКИ НА МОЮ ДУМКУ, ВЗАГАЛІ ТЕ ЩО ДАЛІ КРАЩЕ ПИСАТИ ПЕРЕПИТАВШИ У ВИКЛАДАЧА) Таким чином на початку моделювання виконується ініціалізація, а згодом повторюється цикл моделювання, що складається із двох стадій. За ініціалізації всім сигналам присвоюються початкові значення, час моделювання встановлюється на нуль, і один раз виконуються описи всіх об’єктів. Це зазвичай приводить до планування трансакцій хоч одного сигналу на пізнішій момент часу. На першій стадії моделювання імітаційний час просувається до самого раннього часу, на який заплановано будь-яку трансакцію. Усі трансакції, заплановані на цей час, тобто сигналам присвоюються заплановані значення. Сигнал, для якого виконується трансакція, називають активним. Якщо нове значення відрізняється від попереднього, сигнал змінюється, відбувається подія, й інші об’єкти, для яких змінений сигнал є вихідним, активуються. На другій стадії виконуються описи всіх об’єктів, які реагують на події, що відбулися на першій стадії. У більшості випадків це приведе до того, що на наступні моменти часу буде заплановані трансакції деяких сигналів. Коли всі описи виконано, цикл моделювання повторюється. Якщо більше немає запланованих трансакцій, моделювання закінчується. Умовний оператор Умовний оператор дозволяє вибрати групу операторів, що виконуватиметься залежно від однієї чи кількох умов. умовний_оператор::= if умова then посдідовність_операторів { elsif condition then послідовність_операторів } [ else послідовність_операторів ] end if; Умови повинні мати значення типу boolean. Вони обчислюються послідовно, доки не зустрінеться така, значення якої буде істинним (true). Оператор вибору Оператор вибору case дозволяє вибрати групу операторів, що виконуватиметься залежно від значення виразу вибору. Синтаксис оператора case: оператор_вибору::= case вираз is альтернатива_оператора_вибору {альтернатива _.оператора_ вибору} end case; альтернатива_оператора_вибору::= when список_виборів => послідовність операторів список_виборів::= вибір { | вибір } вибір:: = простий_вираз | дискретний діапазон | просте_ім'я _елементу | others Значення виразу вибору має бути дискретного типу або одномірним масивом символів Оператор цикл використовується для створення циклів while, until та for оператор_циклу::= [ мітка_циклу: ] [ схема_ітерацій ] loop послідовність_операторів end loop [ мітка_циклу ]; схема_ітерацій::= while умова | for специфікадія_параметра_циклу специфікація_параметра::= ідентифікатор in дискретний_діапазон Якщо схема ітерацій відсутня, то цикл повторюватиметься нескінченно Оператор повідомлення Використовується для перевірки вказаної умови та повідомлення, якщо вона порушена. Його синтаксис: оператор_повідомлення::= assert умова [ report вираз ] [ severity вираз ]; Коли слово report присутнє, то, якщо умова помилкова, буде виведено вираз, який стоїть після слова report. Якщо слово report відсутнє, то виводиться стандартне повідомлення Часто процес, що створює драйвер сигналу, містить тільки оператор присвоювання сигналу. У VHDL існує зручний засіб для опису таких процесів. Це оператор паралельного присвоювання сигналу: паралельний_оператор_присвоювання_сигналу::= [ мітка: ] оператор_умовного_присвоювання_сигналу | [ мітка: ] опєратор_вибіркового_присвоювання_сигналу Для кожного виду паралельного присвоювання сигналу існує відповідний еквівалентний процес. Умовне присвоювання сигналу Це короткий запис процесу, який містить лише один умовний оператор, у гілках якого стоять тільки оператори присвоювання одному і тому самому сигналу. Його синтаксис: оператор_умовного__присвоювання_сигналу::= адресат <= опції умовна_форма_сигналу; опції::= [ guarded ] [ transport ] умовна_форма_сигналу ::= { форма_сигналу when умова else } форма_сигналу Якщо цей оператор містить слово transport, то присвоювання сигналу в еквівалентному процесі виконуватиметься із транспортною затримкою. Розглянемо таке умовне присвоювання сигналу: s <= форма_сигналу_1 when умова_1 else форма_сигналу_2 when умова_2 else …форма_ сигналу_n; Еквівалентний процес має вигляд: Process if умова_l then s <= форма_сигналу_1; elsif умова_2 then s <= форма_сигналу_2; Elsif.. else s <= форма_сигналу_п; wait [ список_чутливості ]; end process; Якщо жодна із форм сигналів чи умов не містить посилання на сигнал, то після присвоювання процес зупиняється назавжди. Вхідна мова програми Spice До появи засобів автоматизації електронного проектування, які дозволяли створення графічного зображення принципових схем описувалися у вигляді текстового файлу з використанням однієї з мов опису апаратних засобів (Hardware Description Language – HDL). За сутністю такий опис являє собою список всіх компонентів схеми та список їх з’єднань. Як приклад можна розглянути одно розрядний напівсуматор (рис. 1).
Опис цієї схеми мовою апаратних засобів має такий вигляд: Circuit halfadd (a, b, sum, carry) inv(a, f) and2(a, b, f) or2(a, b, f) g1: inv(b, w1) g2: inv(a, w2) g3: and2(a, w1, w3) g4: and2(w2, b, w4) g5: or2(w3, w4, sum) g6: and2(a, b1, carry) end circuit;
У заголовку цього опису вказано назву схеми, її входи та виходи. Після цього наведено список використаних компонентів, а в кінці – список примірників цих компонентів і з’єднань між ними. Аналогічна мова використовується для опису аналогових схем у програмі SPICE. Подібних мов було свого часу створено досить багато. Їх було запропоновано фірмами-розробниками мікросхем, а синтаксичні конструкції мов було тісно пов’язано з технологіями, що реалізують ці фірми. Такі мови опису апаратних засобів дозволяють описати схему на структурному рівні, тобто представити її як сукупність пов’язаних між собою елементів. Відносно нещодавно з’явилися мови опису апаратних засобів, які дозволяють створити поведінковий опис схеми. Це мови VHDL і Verilog. Вони також дозволяють створювати структурний опис схеми, але їх справжня потужність виявляється у можливості синтезу електронної схеми за її технологічно незалежним функціональним описом. Вибір між використанням мов опису апаратних засобів і вводом графічного зображення принципової схеми завжди є складним питанням при виборі методології розробки електронних пристроїв. Досвідчені користувачі мов опису апаратних засобів вважають, що їх використання є найбільш швидшим і зручним методом розробки. Наприклад, створення двадцятирозрядного регістра зсуву при використанні схемного підходу вимагає розміщенні та з’єднання двадцяти тригерів. При використанні мов опису апаратних засобів для опису такого регістру або іншої регулярної структури достатньо кількох рядків коду. Використання засобів синтезу також суттєво спрощує та прискорює розробку систем, які складаються з комбінаційних схем, суматорів, перемножувачів, скінченних автоматів тощо. Проте, використання пакетів створення принципових схем потребує меншої кваліфікації розробника та нетривалого часу навчання користувача. За схемою підходу (завдяки його наочності) пошук, локалізація та виправлення помилок зазвичай вимагає менших втрат часу, ніж при використанні мов опису апаратних засобів. Системна шина IBM PC (8-розрядна ISA) Системна шина ISA (8-розрядна) являє собою розширення шини мікропроцесора Intel 8088. Вона демультиплексована, її можливості розширені шляхом додаткових керуючих сигналів для прямого доступу в пам’ять, обробки переривань та інших функцій. Елементна база сумісна з транзисторно-транзисторною логікою (ТТЛ), всі сигнали мають активний високий рівень за виключенням випадків, що обумовлені окремо. Паралельні комунікаційні порти персонального комп’ютера. Загальні відомості. Призначення ліній інтерфейсу Centronics. Часові діаграми обміну інформацією. Особливості використання інтерфейсу Centronics. Паралельні інтерфейси використовують окремі лінії для передач бітів деякого мінімального пакету даних (наприклад, байта). Таким чином біти цього пакета передаються паралельно (одночасно), а самі пакети послідовно. Зазвичай паралельні інтерфейси застосовують для підключення принтерів. Передача даних може бути одно- (Centronics) та двонапрямленою (Bitronics). Для підключення принтера до ПК введено порт паралельного інтерфейсу, що має назву LPT-порт (Line PrinTer – відрядковий принтер). Найпоширенішими типами паралельних портів є: w однонапрямлений (чотирирозрядний); w двонапрямлений (восьмирозрядний); w поліпшений паралельний порт (EPP – Enhanced Parallel Port); w порт із розширеними можливостями (ECP – Enhanced Capabilities Port). Однонапрямлений паралельний порт (історично був перший) виконує задачу передачі даних на принтер. Однак у деяких випадках існує необхідність обміну даними. З великими обмеженнями, але все ж можливим було витиснути двонапрямлений режим. Швидкість передачі даних чотирирозрядного порту становила 40–60 КБайт/с. Двонапрямлений паралельний порт (1987) може працювати з восьмирозрядним входом і виходом, він став доопрацюванням попереднього, при чому було вирішено залишити розніми і контакти як і було. Швидкість передачі залежить від конкретних характеристик технічних і програмних засобів і становить 80–300 КБайт/с. Поліпшений (EPP - Enhanced Parallel Port) паралельний порт (1991) значно перевершив можливості попередників. Швидкість передачі даних досягала 2 МБайт/с. З’явилася можливість підключати до одного порту до 64 пристроїв, з’єднуючи їх за принципом гірлянди. Інший (ECP - Enhanced Capabilities Port) високошвидкісний паралельний порт (1992) мав забезпечити дешеве підключення високошвидкісних принтерів. Більшість сучасних адаптерів можуть працювати як у режимі ECP, так і EPP. Надалі інтерфейс продовжував еволюцію, тому виникла необхідність об’єднати всі існуючі специфікації під одним стандартом. Таким стандартом став IEEE 1284. Він передбачає роботу паралельного порту в чотирьох режимах: стандартний, двонапрямлений, EPP і ECP. Аналіз класів пам’яті змінних Кожен об’єкт програми (змінна, функція,...) має свій тип і клас пам’яті (клас зберігання). Тип визначає обсяг пам’яті для об’єкта і операції, що можуть виконуватись над об’єктом, а клас пам'яті задає місце розташування об'єкта (внутрішні регістри мікропроцесора, сегмент даних, сегмент стека тощо) та встановлює для нього час існування, тобто час, протягом якого об‘єкт зберігається в пам‘яті. На відміну від типу, клас пам’яті можна явно не вказувати, тоді він встановлюється компілятором за правилами замовчання, в залежності від розташування ідентифікатора в тексті програми. Із класом пам’яті тісно пов’язані поняття області визначення та області видимості. Областю визначення називається та частина коду програми, в межах якої ідентифікатор може використовуватися для доступу. Є різні області визначення: в межах блоку (локальна область визначення), в межах функції, в межах файлу тексту програми. Область видимості –область вихідного тексту програми, із меж якої можливий коректний доступ до пам’яті або функції з використанням ідентифікатора. Клас пам’яті змінної завжди задається розташуванням її опису або за допомогою ключового слова (специфікатор класу пам’яті), який розташовується перед звичайним описом. Для змінних існує 4 класи пам’яті: § auto - клас за замовчуванням. Автоматичні змінні – це завжди локальні змінні і розташовуються або у стеку, або у регістрах. Час життя таких змінних – це час виконання функції або блока; § register - зберігання змінної у регістрі процесора, дає змогу істотно скоротити час звертання до змінних, за відсутності вільних регістрів змінна буде опрацьовуватись як змінна з класом auto (тобто компілятор не зобов’язаний виконувати умову розташування змінної у регістрах); така змінна не має адреси; § static - статичні змінні існують протягом усього часу виконання програми, проте областю їх дії залишається той блок, у якому вони оголошені; всі глобальні змінні за замовчанням мають цей клас пам’яті, але не будь-яка змінна з цим класом пам’яті глобальна. § extern - змінні є посиланнями на відповідні зовнішні змінні та роблять ці змінні видимими (оголошеними) в межах поточного файлу.
|
|||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-07-14; просмотров: 300; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.129.39.54 (0.012 с.) |