Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Тема 1: Вступ. Мета та задачі курсу.Содержание книги
Поиск на нашем сайте
Зміст
Тема 1: Вступ. Мета та задачі курсу. 3 1.1. Інформаційні технології та бази даних. 3 1.2. Історія розвитку технологій баз даних. 3 1.3. Основні тенденції розвитку інформаційних систем.. 6 1.3.1. Розподіл і децентралізація. 6 1.3.2. Неоднорідність. 7 1.3.3. Розвиток стандартів. 7 1.3.4. Моделювання реального світу. 8 1.4. Зв’язок управління інформацією з іншими дисциплінами інформаційних систем.. 8 1.5. Основні перспективні ідеї в технології баз даних. 9 1.5.1. Маніфест систем баз даних третього покоління. 9 1.5.2. Маніфест об’єктно-орієнтованих систем баз даних. 11 1.5.3. Симпозіум Національної наукової фундації США.. 11 Тема 2. Управління розподіленою інформацією.. 13 2.1. Принципи управління розподіленою інформацією.. 13 2.2. Моделі розподілених баз даних. 14 2.2.1. Однорідні і неоднорідні системи. 14 2.2.2. Методи побудови розподілених баз даних „зверху вниз” і „знизу до верху”. 16 Тема 3. Технологія клієнт-сервер в базах даних. 19 3.1. Основи архітектури клієнт-сервер. 19 3.2. Основні принципи і критерії оцінки систем клієнт-сервер. 20 3.3. Стандарти архітектури клієнт-сервер в управлінні інформацією.. 21 3.3.1. SQL Access Group і стандарт DRDA.. 21 3.3.2. Стандарти, засновані на інтерфейсі рівня викликів SAG.. 21 3.4. Програмне забезпечення проміжного шару. 22 Тема 4. Управління розподіленою інформацією.. 23 4.1. Принципи побудови сховищ даних. 23 4.2. Цифрові бібліотеки і інформаційні магістралі 26 Теми 5. Паралельні системи баз даних. 26 5.1. Сучасні підходи до фрагментація і тиражування. 26 5.2. Концепції МРР і паралельних систем баз даних. 26 5.3. Моделі фрагментації для паралельних систем баз даних. 28 5.3. Перспективи розвитку паралельних систем баз даних. 29 5.4. Перспективи тиражування. 30 Тема 6. Об’єктно-орієнтовані бази даних. 32 6.1. Характеристики і мотивація об’єктно-орієнтованих баз даних. 32 6.2. Концепції об’єктно-орієнтованих баз даних. 34 6.2.1. Індивідуальність об’єктів. 34 6.2.2. Атрибути. 34 6.3.3. Методи. 35 6.3.4. Класи. 35 6.3.5. Ієрархії класів і наслідування. 35 6.3.6. Довготривале зберігання. 35 6.4. Співвідношення гібридного і розширеного реляційного підходів. 36 6.5. Об’єктно-орієнтовані механізми управління даними і моделі 38 6.6. Діяльність ODMG по стандартизації 39 Тема 7. Перспективні технології бази даних. 41
7.1. Бази даних з інтегрованим часом.. 41 7.2. Основні принципи часових баз даних. 41 7.3. Моделі даних з часом.. 42 7.4. Часові розширення мов баз даних. 43 7.5. Об’єктно-орієнтовані часові бази даних. 43 7.6. Активні бази даних. 43 7.7. Принципи активних систем баз даних. 44 7.7.1. Обмеження і твердження. 44 7.7.2. Збережувані процедури. 45 7.7.3. Тригери. 45 7.8. Розширення моделей активних баз даних. 45 7.9. Моделі трансакцій і активні бази даних. 45 7.10. Штучний інтелект і технологія баз даних. 46
Тема 1: Вступ. Мета та задачі курсу. Інформаційні технології та бази даних Всім відомий очевидний факт, що крупні системи живуть своїм життям - в будь-якій області людської діяльності - будь то інженерні, фінансові, інформаційні і інші конструкції. Помилки на ранніх стадіях їх побудови є найдорожчими і приводять в кращому разі до подорожчання, перевищення термінів створення і погіршення якісних характеристик цих систем, в гіршому - до повного краху при їх створенні. Людство знає немало таких прикладів. Невеликі і середні системи можуть бути побудовані методом „грубої сили”. Прорахунки, що неминуче виникають при проектуванні, можуть бути усунені згодом, і це не викличе повного руйнування системи. Інша справа - великі і надвеликі системи. Без стратегічного планування їх побудови і упровадження, вони просто приречені на невдачу. Особливо це важливо для інформаційних систем. Інформаційні технології змінюються найбільш динамічно. Підходи, що здавалися перспективними і важливими п’ять-десять років тому, сьогодні можуть привести до побудови „успадкованих систем” і категорично не повинні використовуватися фахівцями. Ціна таких помилок зростає в багато разів.
Не дивлячись на уявну незмінність базових технологій (реляційна модель даних, що служить основою практично всіх сучасних реалізацій систем баз даних, з’явилася майже тридцять років тому), у галузі баз даних відбуваються значні зміни. Концепції сховищ даних, що з’явилися останнім часом, розширення реляційної моделі даних, вживання об’єктно-орієнтованого підходу і інших до побудови СУБД вже зараз значно змінили картину. І швидше за все в найближчому майбутньому ця картина зміниться ще разючіше. Всі провідні виробники програмних продуктів, призначених для побудови сховищ і баз даних, зараз активно займаються реалізацією нових концепцій в промислових розробках.
Актуальність і новизна пов’язаних з цією сферою проблем привернули до них увагу широкого кола фахівців не тільки крупних компаній, що зайняті виробництвом обчислювальної техніки і програмного забезпечення, але і провідних дослідницьких центрів. Це, у свою чергу, сприяло швидкому становленню нової гілки інформатики, що спеціалізується на розробці інструментальних засобів і додатків, а також теоретичних основ систем баз даних. На розвиток цієї гілки інформатики значний вплив мали і продовжують мати досягнення в суміжних напрямах, пов’язаних з операційними системами, мовами і технологіями програмування, штучним інтелектом, обчислювальною і комунікаційною технікою. Проте вже із самого початку стало ясно, що вона володіє, проте, власною проблематикою, пов’язаною із специфікою задач управління узагальненими ресурсами даних в сучасних обчислювальних середовищах з різноманіттям можливостей їх архітектури.
Основні тенденції розвитку інформаційних систем Сильний вплив на багато з перспективних напрямів розвитку в області управління базами даних і управління інформацією мають загальні тенденції розвитку інформаційних систем. Розглянемо чотири головні тенденції і ті їх аспекти, які специфічні для управління інформацією. Цими чотирма тенденціями є: - розподіл і децентралізація ресурсів управління інформацією; - неоднорідність компонентів інформаційних систем; - розвиток стандартів; - включення моделювання реального світу в інформаційні системи.
Розподіл і децентралізація Навряд чи не кожний, що має справу з комп’ютерами добре знайомий з тенденцією щодо розподілу і децентралізації обчислювальних ресурсів. Розукрупнення апаратного забезпечення комп’ютерів стало причиною появи малих за розмірами, проте вельми потужних процесорів і комп’ютерних систем, які стали життєздатною альтернативою великим системам. Такі обчислювальні системи - від настільних персональних комп’ютерів і робочих станцій до систем середнього класу - звичайно зв’язуються за допомогою комунікаційних засобів, наприклад локальних обчислювальних мереж (Local Area Networks, LAN), щоб забезпечити колективні обчислювальні потужності на тому ж, або й на більш високому рівні, ніж при централізованих великих системах недавнього минулого. Розподіл обчислювальних ресурсів супроводжує значно більша децентралізація управління, чим в централізованому середовищі, при якому центр даних, як правило, мав сильний контроль над ресурсами великої обчислювальної системи. Така ситуація зберігається, поки що для компонентів великих обчислювальних систем у багатьох крупних організаціях. Проте настільні персональні комп’ютери (ПК) і робочі станції, разом з системами середнього класу на рівні підрозділу, забезпечили значно більший ступінь управління ресурсами для окремих користувачів. Одним з позитивних аспектів децентралізації є вищий ступінь динамічності в багатьох областях використання обчислювальної техніки в корпораціях, таких, як установка і розробка додатків, підключення периферії, розширення системи і т.п. Негативна сторона, проте, полягає в тому, що швидке збільшення числа додатків, що знаходяться в особистій власності користувачів (наприклад, особистих копій систем електронних таблиць або програмного забезпечення систем баз даних для ПК), приводить до втрати контролю над даними. Окремі користувачі мають більш швидкий доступ до тих даних, якими вони «володіють», ніж вони мали б при централізовано керованих ресурсах, і вони можуть легко і швидко, при необхідності, створювати нові дані. Проте є тенденції до виникнення вельми важких проблем, пов’язаних з несуперечністю колективних даних організації в цілому, оскільки відсутня, наприклад, синхронізація оновлення даних і існує повне замішання щодо того, „хто, чим володіє і де це знаходиться”.
Розподіл і децентралізація мають безпосереднє відношення до управління базами даних і управління інформацією. Хоча більшість організацій і дотепер має корпоративні інформаційні системи з централізованим управлінням інформацією, що базуються на великих обчислювальних системах, з середини 80-х років спостерігається значний прогрес в області створення систем та специфічних додатків на рівні підрозділів, і у використовуванні настільних ПК з персональними додатками, що включають системи управління базами даних. Фактично управління базами даних, обробка текстів, управління електронними таблицями і графіка стали представляти так звану велику четвірку горизонтальних додатків ПК. У більшості організацій спроби центру даних нав’язати у використовуванні ПК і, зокрема, в управлінні даними принципи, подібні до тих, що використовуються на великих обчислювальних системах, зіткнулися з величезним опором. Розподіл і децентралізація надали безпрецедентний контроль над інформацією „корпоративним масам”, і вони не відмовляться від цього контролю.
Неоднорідність Дні використовування середовищ одного постачальника стрімко йдуть геть. Навіть „стандартна” модель центру даних корпорації, що ґрунтується на деякому типі великих обчислювальних систем корпорації IBM і на одному або більше типах операційних систем, набуває рис неоднорідності, оскільки апаратні засоби і програмне забезпечення третьої сторони також знаходять свою дорогу в ці середовища. Більш важливим, ніж навіть сам факт появи нових систем, є вимога до можливості їх з’єднання і інтероперабельності, не дивлячись на існування різних виробників. Модель неоднорідності має також відношення до управління інформацією. Успадковані системи, це, як правило, системи ієрархічних баз даних або системи плоских файлів, які містять і управляють давнішніми даними корпорації. Вони повинні спільно використовувати з реляційними базами даних, що функціонують на тих же самих великих обчислювальних системах, а також з базами даних підрозділів і базами даних, що використовуються на ПК. Усі ці випадки сумісного використовування повинні забезпечуватися незалежно від апаратних моделей і версій програмних продуктів. Інтероперабельність у все більш широких масштабах наводить мости між численними інформаційними моделями (наприклад, комбінуючи реляційні і об’єктно-орієнтовані дані).
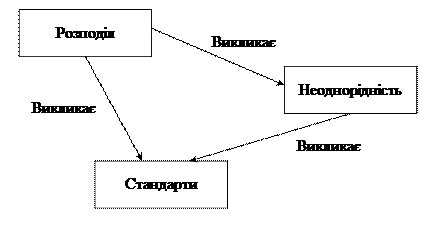
Розвиток стандартів Інтероперабельность неоднорідних середовищ, описаних вище, ґрунтується на стандартах. Стандарти проникають в кожну область використання обчислювальної техніки - від комунікацій, де прикладом може служити еталонна модель взаємодії відкритих систем (Open Systems Interconnection (OSI) Reference Model), до управління базами даних (стандарт мови SQL). Всупереч деяким суперечливим думкам щодо їх ролі в інформаційних системах, стандарти можуть тут застосовуватися головним чином у зв’язку з вимогами користувачів. Самі по собі стандарти мають невелике значення. Проте в контексті двох головних тенденцій, розподіл і неоднорідність, стандарти стають надзвичайно важливими (мал. 1.1). Користувачі хочуть мати свободу заміни апаратних засобів і/або програмного забезпечення в системах, не відмовляючись від всіх інтерфейсів, на які спираються їх середовища. Інакше, наприклад, заміна однієї комерційної СУБД на іншу могла б привести до необхідності переписування коду додатків або коду інших сервісів (служб) середовища, таких, як комунікації або призначені для користувача інтерфейси.
Рис. 1.1. Взаємозв’язок між розподілом, неоднорідністю та стандартами
Моделювання реального світу Протягом всієї історії застосування комп’ютерних систем у комерційній діяльності існував деякий розрив між самими інформаційними системами і конструкціями реального світу, для підтримки яких вони розроблялися. Прикладами такого розриву можуть служити: - множина додатків, які вимагають багатократного повторення введення даних і значного об’єму інформації на паперових носіях, що спільно використовується користувачами в різних областях комерційної діяльності; - сам процес розробки програмного забезпечення і систем з його базовими методологіями і моделями, які вимагали складного, з можливими помилками, відображення між фазою концептуального проектування і реалізацією додатків і систем; 80-ті роки характеризуються більш тісним зближенням парадигм інформаційних систем і тих систем реального миру, які вони представляють і підтримують. До результатів впливу моделей реального світу на світ комп’ютерних систем можна віднести: - графічні інтерфейси користувача (Graphical User Interfaces, GUI), які додали додаткам більш природний вигляд і поліпшили їх сприйняття; - об’єктно-орієнтовані моделі, принципи яких були застосовані до програмування та управління даними і (завдяки таким можливостям, як наслідування і методи) привнесли більш тісний зв’язок між концептуальною стадією і стадією реалізації процесу розробки;
- управління потоками робіт, при якому можуть визначатися і управлятися потоки робіт між користувачами і взаємозв’язки між додатками. Системи, засновані на потоках робіт, дають можливість в термінах потоків керування і даних між додатками і користувачами моделювати природній шлях здійснення комерційної діяльності ретельніше, ніж із застосуванням засобів, що інтенсивно використовують паперові документи і вимагають високого ступеня втручання людини.
Перспективи тиражування Тиражування - цей розподіл даних не на основі моделі їх розбиття (наприклад, горизонтальної або вертикальної фрагментації), а за допомогою їх дублювання. Для управління існуючими в даному середовищі можливостями оновлення копій з боку додатків, а також стратегіями синхронізації копій застосовуються різноманітні моделі (втім, іноді ці можливості відсутні). Основні принципи тиражування даних, перераховані нижче: 1) Повні або часткові копії Стратегії оновлення копій - синхронне; - асинхронное/с розповсюдженням; - активізоване/відкладене. 2) Стратегії доступу до копій - всі копії доступні для оновлень; - деякі копії доступні тільки для читання. Якщо звернутися до довгострокових перспектив, пов’язаних з оптимальними розподіленими середовищами баз даних майбутнього, то тиражування даних представлялося спочатку як деяке проміжне рішення на шляху до створення „остаточної моделі” множини баз даних, що містять досяжні в рамках глобальної мережі (Global Area Network, GAN) фрагменти даних. Хіба лише для прискорення доступу передбачалося розміщувати в стратегічно важливих пунктах в глобальній організації копії даних, до яких можна звертатися тільки для читання, що рідко обновляються.
Тиражування може бути реалізовано різними способами. Найпростіша модель має на увазі наявність програмного інтерфейсу, за допомогою якого прикладні програми самі здійснюють створення копій, а також реалізують стратегії їх координації і синхронізації (мал. 5.7). В більш розвинутих декларативних моделях (мал. 5.8) правила тиражування і управління копіями вбудовуються безпосередньо в саму базу даних.
Мал. 5.7. Програмне управління копіями
Як показано на мал. 5.12, декларативне управління оновленням копій може здійснюватися засобами активних баз даних. Кажучи стисло, активна база даних володіє засобами, наприклад механізмами тригерів і процедур, що зберігаються, які дозволяють автоматизувати виконання деяких дій в базі даних на основі заданих правил, а не засобами програмної логіки управління базою даних з боку додатку або системи. В такому середовищі оновлення якої-небудь з копій об’єкту може, наприклад, активізувати тригер, який забезпечить автоматичне розповсюдження змін по всій решті копій.
Мал. 5.8. Декларативне управління копіями за допомогою активних баз даних
Індивідуальність об’єктів Кожний об’єкт в об’єктно-орієнтованій системі має унікальний ідентифікатор, названий ID об’єкту (від IDentificator) або OID (від Object IDentifier). Унікальність OID повинна підтримуватися навіть у розподілених об’єктних середовищах. Використовування OID дозволяє змінювати значення будь-якого атрибуту об’єкту, у тому числі і тих атрибутів, які утворюють первинний ключ, не порушуючи при цьому посилань на даний об’єкт. Слід зазначити, що концепція унікальних OID берет свій початок в (або, як заявляють деякі експерти, є зворотним кроком від) унікальності, заснованій на значеннях, в реляційній моделі, що використовується. У будь-якому випадку одна з фундаментальних передумов ООБД полягає в наявності унікального немінливого OID (ніяка операція не може коли-небудь змінити асоціацію між об’єктом і його індивідуальністю).
Атрибути Кожен об’єкт завжди має два аспекти: стан і поведінка. Стан об’єкту визначається множиною значень його атрибутів (або властивостей, або змінних екземплярів, або полів - використовується ряд термінів). В об’єктно-орієнтованих середовищах значення будь-якого заданого атрибуту повинно підкорятися деяким правилам, пов’язаним з типом даних (чи визначеним користувачем, чи абстрактним), з діапазоном або списком значень, а також з заданою характеристикою, єдине або множинне значення якої може бути задано, і т.д.
Методи Точно так, як атрибути описують стан об’єкту, методи, звані також процедурами або операціями, описують його поведінку. Якщо наш об’єкт - це CD (компакт-диск), то можна застосувати такі методи: - Метод 1 - введення даних. Перш ніж ввести дані, переконатися, що ID для даного CD, що вводиться є унікальним. - Метод 2 - оновлення продажної ціни. Отримати значення у службовця, що володіє на це повноваженнями, переконатися, що воно належить допустимому діапазону цін, і відновити значення в базі даних. - Метод 3 - зняття з продажу. Понизити ціну на кожний CD цього типу, що є в даний час в магазині, на 40% зараз і додатково на 20% наступного тижня для залишку; більше не замовляти такі CD. Завдяки передачі явних повідомлень між об’єктами системи виклик інкапсульованих методів і доступ до атрибутів заданого об’єкту здійснюються відповідно до правил даної ООСУБД.
Класи Класи, звані також типами, є конструкціями, які є групами об’єктів, що володіють одною і тою ж множиною атрибутів і методів. Класи можуть бути примітивними (всі цілі або всі рядкові об’єкти), і в цьому випадку вони можуть не мати атрибутів. Вони можуть також володіти атрибутами і методами, і в цьому випадку всі об’єкти в цьому класі мають одну і ту ж множину атрибутів і методів (хоча і, мабуть, різні значення атрибутів).
Довготривале зберігання На відміну від реляційних баз даних, що беруть участь в управлінні даними інформаційних систем, корені об’єктно-орієнтованих баз даних великою мірою лежать в мовах програмування. Середовище ООСУБД має наступні характерні риси: - включаюча мова програмування є також і мовою маніпулювання даними (ММД); - моделі, пов’язані з представленням в оперативній пам’яті і в зовнішній пам’яті, зливаються; - не вимагається ніякого перетворення коду між моделями і мовами.
Насправді довготривале зберігання даних в середовищі програмування забезпечується завдяки можливостям ООСУБД. Пригадаємо (див. мал. 8.2), що модель бази даних і реалізація є одними і тими ж, і тому не вимагається ніякого відображення (у тому числі також і для об’єктів реального світу). Створення нового об’єкту, що зберігається тривалий час, у мові програмування породжує об’єкт бази даних, який може використовуватися безпосередньо в програмі без необхідності відображати його в структури пам’яті мови програмування. Одна з переваг довготривалого зберігання даних, що базується на мові програмування, полягає в тому, що воно виключає невідповідність імпедансу між мовою бази даних і середовищем програмування. Потрібно взяти до уваги, що звичайна реляційна СУБД має засновану на SQL мову маніпулювання даними, який підтримує основні типи даних, такі, як цілі і літерні. Більшість ООСУБД використовує включаючі об’єктно-орієнтовані мови програмування (ООМП) C++ або Smalltalk.
Разом з об’єднанням семантичний багатої моделі даних і реалізаційної моделі з довготривалим зберіганням, інкапсуляцією і іншими можливостями, які обговорювалися в цьому розділі, методології розробки систем, застосовні до середовищ ООСУБД, мають і інші значні переваги в порівнянні з їх більш традиційними двійниками.
Моделі даних з часом Один з дослідницьких підходів до тимчасових баз даних був пов’язаний з так званими періодами життя (lifespan), асоційованими з об’єктами баз даних різної гранулярності - від повної бази даних до окремих рядків або кортежів. Періоди життя є відрізками часу, коли мають силу конкретні стани деякого об’єкту. Тому вони можуть служити також параметрами для вибірки інформації. Концепцію періодів життя можна було б також асоціювати з рівнем атрибутів (стовпець в рядку), як показано на мал. 7.1. І тут знов можна провести аналогію між періодами життя на рівні кортежів і на рівні атрибутів з варіантами блокування на рівні рядків і рівні елементів для управління паралельним доступом.
В рамках часової моделі даних такого роду, як HRDM, операції тимчасового зрізу можуть застосовуватися до деякого відношення як обмежуючий критерій пошуку, що задається у фразі WHEN (коли), значною мірою таким же чином (мал. 7.1), яким при операції SELECT використовуються подібні обмеження у фразі WHERE (де).
Іншим архітектурним підходом до тимчасових баз даних, також заснованим на розширенні реляційної моделі, є тимчасова реляційна модель (Temporal Relational Model, TRM). В TRM тимчасова база даних визначається як „об’єднання двох множин відносин Rs і Rt, де Rs - безліч всіх статичних відносин, а Rt - безліч всіх відносин, що змінюються у времени”. Часові інтервали, концептуально подібні періодам життя в HRDM, включають два обов’язкові атрибути - відмітки часу, що представляють початковий час (start time) Ts і кінцевий час (end time) Te, тобто нижню і верхню межі тимчасового інтервалу відповідно. У зв’язку з тим, що тимчасові моделі даних, такі, як TRM, мають реляційні основи, представляється цілком природним, що в них значну роль гратиме нормалізація. В моделі TRM використовується концепція тимчасової нормальної форми TNF (Time Normal Form).
Інша корисна можливість, яку може забезпечити часове вимірювання, - це управління майбутнім часом, як, наприклад, це робиться в моделі HDBMS. У HDBMS підтримуються наступні правила для тимчасових операцій: - Розділення історичних даних, поточних даних і даних майбутнього на різні сегменти так, щоб воно було прозорим для користувача. - Підтримка всіх типів трансакцій над станами і єствами майбутнього. - Відмова від накладення яких-небудь обмежень, що не є необхідними, на впорядкування в часі трансакцій над даними майбутнього (наприклад, основних принципів синхронізації трансакцій).
Активні бази даних При рішенні багатьох обговорюваних в цій книзі проблем, пов’язаних з сховищами даних, репозиторіями і т.д., так само як і при визначенні загальної архітектури додатків, можна отримати користь з властивостей активних баз даних Властивості активних баз даних полягають в тому, що процедурні елементи загального середовища вбудовуються в систему бази даних і управляються декларативним чином Розвиток технології активних баз даних розглядається в даний час як одна з головних тенденцій, яка революціонізує розробку додатків Філософія, на якій була заснована ця технологія, - зберігання операцій над даними і процедур разом з самими даними, - широко використовується в інших областях, наприклад в об’єктно-орієнтованих базах даних
Традиційні бази даних є пасивними. Об’єкти даних звичайно поміщаються в базу даних користувачем або додатком. Вибірка об’єктів здійснюється знову-таки під впливом зовнішніх джерел. Подібним же чином під впливом якого-небудь зовнішнього джерела інформація змінює місце свого зберігання в базі даних (наприклад, переноситься з однієї таблиці в іншу). Бізнес-правила, вживані до вмісту бази даних (наприклад, правила оновлення конкретного елемента даних, подальші за цим дії над іншими елементами як результат такого оновлення), також управляються деяким зовнішнім джерелом. Останніми роками ця роль змінюється, і важливість концепції активних баз даних зростатиме протягом літ поточного десятиріччя, що залишилися. Можна, по суті, затверджувати, що технологія активних баз даних - це брами, що відкривають шлях до баз знань, досліджуваних в області штучного інтелекту (ШІ).
Обмеження і твердження Обмеження є відносно простими конструкціями, що мають вигляд від специфікації зв’язків первинного і зовнішнього ключів, що використовуються в обмеженнях цілісності за посиланням (Referential Integrity), до SQL-подібних обмежень CHECK, що використовуються для перевірки приналежності значення заданому діапазону або списку значений. Обмеження могли б розглядатися як перший засіб для вбудовування бізнес-правил в базу даних замість використовування для цієї мети логіки додатку. Більш загальним типом обмежень, підтримуваним в стандарті SQL-92, є твердження. Твердження є самостійною декларацією в схемі, що використовується для специфікації обмеження, яке може зачіпати більш ніж одну таблицю. Твердження мають важливу перевагу перед основними обмеженнями. Вони є самостійними сутністями, які не обов’язково повинні міститися у визначенні якої-небудь таблиці. Тому бізнес-правила, що зачіпають дві або більш таблиці, можуть бути природним чином представлені в тілі твердження.
Збережувані процедури У багатьох випадках основні конструкції обмежень і тверджень виявляються неадекватними для виразу складних бізнес-правил. СУБД, які підтримують збережувані процедури, тобто програмовану логіку, що міститься в базі даних, мають додаткові можливості для виразу складних бізнес-правил. Збережувана процедура є просто модулем прикладної програми з тією лише різницею, що він „відноситься” до бази даних, а не до зовнішньої програмної системи, що використовує цю базу даних. Збережувані процедури можуть визначатися щодо однієї або більш таблиць бази даних, точно так, як і обмеження і твердження.
Тригери Повинні існувати які-небудь засоби для обчислення (оцінки) бізнес-правил, виражених за допомогою конструкцій бази даних, і для виклику виконання специфікованих дій. Тригери є ключовими компонентами, що забезпечують перетворення бази даних в активне середовище. Після операцій вставки, оновлення і/або видалення може бути запущений тригер, асоційований з деяким об’єктом, який приведе в результаті до обчислення бізнес-правил або до виконання певних дій. СУБД повинна володіти засобами моніторингу свого середовища, виявлення умов, що викликають запуск тригерів і виконання процедурної логіки, що міститься в збережуваних процедурах.
Зміст
Тема 1: Вступ. Мета та задачі курсу. 3 1.1. Інформаційні технології та бази даних. 3 1.2. Історія розвитку технологій баз даних. 3 1.3. Основні тенденції розвитку інформаційних систем.. 6 1.3.1. Розподіл і децентралізація. 6 1.3.2. Неоднорідність. 7 1.3.3. Розвиток стандартів. 7 1.3.4. Моделювання реального світу. 8 1.4. Зв’язок управління інформацією з іншими дисциплінами інформаційних систем.. 8 1.5. Основні перспективні ідеї в технології баз даних. 9 1.5.1. Маніфест систем баз даних третього покоління. 9 1.5.2. Маніфест об’єктно-орієнтованих систем баз даних. 11 1.5.3. Симпозіум Національної наукової фундації США.. 11 Тема 2. Управління розподіленою інформацією.. 13 2.1. Принципи управління розподіленою інформацією.. 13 2.2. Моделі розподілених баз даних. 14 2.2.1. Однорідні і неоднорідні системи. 14 2.2.2. Методи побудови розподілених баз даних „зверху вниз” і „знизу до верху”. 16 Тема 3. Технологія клієнт-сервер в базах даних. 19 3.1. Основи архітектури клієнт-сервер. 19 3.2. Основні принципи і критерії оцінки систем клієнт-сервер. 20 3.3. Стандарти архітектури клієнт-сервер в управлінні інформацією.. 21 3.3.1. SQL Access Group і стандарт DRDA.. 21 3.3.2. Стандарти, засновані на інтерфейсі рівня викликів SAG.. 21 3.4. Програмне забезпечення проміжного шару. 22 Тема 4. Управління розподіленою інформацією.. 23 4.1. Принципи побудови сховищ даних. 23 4.2. Цифрові бібліотеки і інформаційні магістралі 26 Теми 5. Паралельні системи баз даних. 26 5.1. Сучасні підходи до фрагментація і тиражування. 26 5.2. Концепції МРР і паралельних систем баз даних. 26 5.3. Моделі фрагментації для паралельних систем баз даних. 28 5.3. Перспективи розвитку паралельних систем баз даних. 29 5.4. Перспективи тиражування. 30 Тема 6. Об’єктно-орієнтовані бази даних. 32 6.1. Характеристики і мотивація об’єктно-орієнтованих баз даних. 32 6.2. Концепції об’єктно-орієнтованих баз даних. 34 6.2.1. Індивідуальність об’єктів. 34 6.2.2. Атрибути. 34 6.3.3. Методи. 35 6.3.4. Класи. 35 6.3.5. Ієрархії класів і наслідування. 35 6.3.6. Довготривале зберігання. 35 6.4. Співвідношення гібридного і розширеного реляційного підходів. 36 6.5. Об’єктно-орієнтовані механізми управління даними і моделі 38 6.6. Діяльність ODMG по стандартизації 39 Тема 7. Перспективні технології бази даних. 41 7.1. Бази даних з інтегрованим часом.. 41 7.2. Основні принципи часових баз даних. 41 7.3. Моделі даних з часом.. 42 7.4. Часові розширення мов баз даних. 43 7.5. Об’єктно-орієнтовані часові бази даних. 43 7.6. Активні бази даних. 43 7.7. Принципи активних систем баз даних. 44 7.7.1. Обмеження і твердження. 44 7.7.2. Збережувані процедури. 45 7.7.3. Тригери. 45 7.8. Розширення моделей активних баз даних. 45 7.9. Моделі трансакцій і активні бази даних. 45 7.10. Штучний інтелект і технологія баз даних. 46
Тема 1: Вступ. Мета та задачі курсу.
|
|||||||||
|
|
Последнее изменение этой страницы: 2016-07-11; просмотров: 231; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.222.102.248 (0.017 с.) |