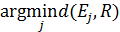Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Метод нелинейного растяжения-сжатия оси времениСодержание книги
Поиск на нашем сайте
Для учёта нелинейного изменения темпа произнесения команд человеком проводят временную нормализацию речевых единиц с помощью метода нелинейного растяжения-сжатия оси времени – DTW. В данном методе словарь команд W представлен множеством эталонов Ei, каждый из которых является последовательностью векторов признаков e j Обучение системы состоит в запоминании для каждой команды эталона в виде последовательности векторов признаков, построенных по соответствующему команде РС. Распознавание состоит в вычислении меры расхождения между распознаваемым сигналом и эталонами словаря команд и определении номера эталона, чья мера расхождения к распознаваемому сигналу будет минимальной. Вычисление меры расхождения между текущим эталоном E ираспознаваемым сигналом R= r 1, r 2,... rj,... rm, представленным последовательностью векторов признаков rj, производят путём вычисления матрицы расстояний D между векторами эталона ei и распознаваемого сигнала rj D = Далее, по матрице D вычисляют элементы DTW-матрицы K K = по рекуррентным формулам k 11 = d 11 k 1 j = d 1 j + k 1(j -1), j Î[2; m ] ki 1 = di 1 + k (i -1)1, i Î[2; n ] kij = dij + min(k (i- 1)(j -1), k (i- 1) j , ki (j -1)), i, j Î[2; n ] Меру расхождения между эталоном E исигналом R определяют как: d(E,R)= knm Кроме определения меры расхождения между эталоном E исигналом R, полученная DTW-матрица K, позволяетопределить множество M пар номеров (p, q) соответствующих друг другу векторов ei и rj :
где H –количество соответствующих друг другу пар векторов. Эти пары определяются итеративно по формулам: pH = n, qH = m, где Pk ={(p ′ ,q ′): pk -1£ p ′£ pk, q -1£ q ′£ qk, p ′¹ i ∩ q ¢¹ j }) p 1 = 1, q 1 = 1 Как следует из этих формул, определение пар номеров соответствующих векторов возможно после вычисления всех элементов матрицы K. Результатом распознавания считают номер эталона, мера расхождения которого к распознаваемому сигналу будет минимальной: res = Метод DTW являлся доминирующей парадигмой для распознавания изолированных слов с малым словарём распознавания. DTW в своей области применения давал очень хорошие результаты и фактически превосходил скрытые модели Маркова. От DTW по существу отказались из-за следующих проблем: введение модели языка не было естественным; задача построения синтетических эталонов осталась нерешенной; не было найдено единой статистическая формулировки распознавания, включающей все модули распознавания речи. Известно также о других проблемах метода распознавания по алгоритму DTW. Существует также проблема большого разброса длин эталонов: если длина одного из эталонных сигналов значительно меньше длин остальных, мера расхождения от него до распознаваемого сигнала будет минимальной. Следующая проблема метода формулируется так: «корректное временное выравнивание двух произнесений различных слов не является чётко определённой лингвистической концепцией». Кроме того, алгоритм DTW имеет тенденцию к пропуску отличающихся элементов и учёту сходных, что при оотсутствиии ограничений на длительность соответствующих друг другу элементов речевого сигнала снижает значимость полученной меры расхождения.
Проблему отсутствия ограничений на длительность соответствующих друг другу элементов речевого сигнала и большого разброса длин эталонов решают путём искусственных ограничений на область индексов элементов, участвующих в формировании меры расхождения (могут принадлежать пути выравнивания), и использования различных способов взвешивания меры расхождения. Сочетание предлагаемых ограничений на путь выравнивания и способов взвешивания меры расхождения порождает множество модификаций метода DTW. Данных о модификации DTW, обеспечивающей наилучшие показатели распознавания в литературе обнаружить не удалось. Этап обучения требует хотя бы однократного произнесения каждой команды словаря. Поэтому метод пригоден только для распознавания команд малого словаря в силу больших затрат времени на создание словаря команд, памяти на его хранение и значительных вычислительных и временных затрат на распознавание. Для сокращения памяти на хранение словаря команд, вычислительных и временных затрат на распознавание применяют технику квантования векторов. Она состоит в кластеризации множества эталонных векторов признаков с последующей заменой этих векторов признаков центроидами кластеров. Но, это не сокращает временные затраты на создание словаря команд, т.к. для метода DTW не решена проблема представления словаря команд на основе более мелких структурных единиц, эталоны которых можно было бы использовать при распознавании. Такой более мелкой единицей может выступать фонема – группа звуков, обладающих определенной артикуляторно-слуховой общностью и функционально друг другу не противопоставленных, т.е. не встречающихся в одинаковом положении в фонетической структуре слова. С одной стороны, РС можно поставить в соответствие последовательность фонем, с другой стороны написанию некоторого слова или последовательности слитно произносимых слов можно поставить в соответствие фонетическую транскрипцию.
|
||||||
|
|
Последнее изменение этой страницы: 2022-09-03; просмотров: 36; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.191.144.15 (0.009 с.) |

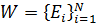 , Ei= e 1, e 2,... ej,... en ,
, Ei= e 1, e 2,... ej,... en , 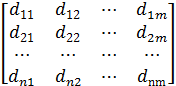 , dij = d (ei, rj).
, dij = d (ei, rj). 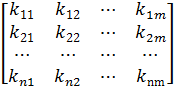 ,
, 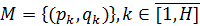 ,
, 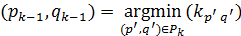 ,
,