Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Алгоритм кластеризации k - meansСодержание книги
Поиск на нашем сайте К наиболее простым и эффективным алгоритмам кластеризации относится k - means, или в русскоязычном варианте k -средних. Он состоит из четырех шагов. 1. Задается число кластеров k, которое должно быть сформировано из объектов исходной выборки. Случайным образом выбирается k записей, которые будут служить начальными центрами кластеров. Начальные точки, и которых потом вырастает кластер, часто называют «семенами». Каждая такая запись представляет собой своего рода «эмбрион» кластера, состоящий только из одного элемента. Для каждой записи исходной выборки определяется ближайший к ней центр кластера. Производится вычисление центроидов – центров тяжести кластеров. Это делается путем определения среднего для значений каждого признака всех записей в кластере. Затем старый центр кластера смещается в его центроид. Таким образом, центроиды становятся новыми центрами кластеров для следующей итерации алгоритма. Шаги 3 и 4 повторяются до тех пор, пока выполнение алгоритма не будет прервано, либо пока не будет выполнено условие в соответствии с некоторым критерием сходимости. Остановка алгоритма производится, когда границы кластеров и расположение центроидов перестают изменяться, т.е. на каждой итерации в каждом кластере остается один и тот же набор записей. Алгоритм k-means обычно находит набор стабильных кластеров за несколько десятков итераций. В качестве критерия сходимости чаще всего используется сумма квадратов расстояний между центроидом кластера и всеми вошедшими в него записями. Алгоритм остановится тогда, когда ошибка Е достигнет достаточно малого значения. Задание на лабораторную работу Разработать программный продукт для реализации методов кластерного анализа на любом языке программирования, позволяющий выполнить кластеризацию объектов по критериям в соответствии с вариантом задания. Предоставить пользователю выбор метода расчета расстояния между объектами (реализовать два из представленных, в соответствии с вариантом задания): 1. Евклидово расстояние. 2. Квадрат евклидова расстояния. 3. Манхэттенское расстояние. 4. Расстояние Чебышева. 5. Степенное расстояние. 6. Процент несогласия.
Использовать один из указанных методов кластеризации: a) Метод ближнего соседа. b) Метод наиболее удаленного соседа. c) Метод кластеризации k-means.
Реализовать один из указанных методов отображения результатов кластеризации (помимо численного): I. Построить дендрограмму. II. Построить диаграмму рассеивания. Варианты заданий:
В отчете отобразить указанный вариант задания, теоретический материал и методы расчета, соответствующие реализованным методам, пример расчета и скриншоты программного продукта с результатами расчетов. Размерность и количество исходных данных можно задать в программе, сами исходные данные пользователь должен иметь возможность выбрать в процессе решения задачи.
4. Контрольные вопросы 1. Группировка данных (постановка задачи и ограничения). 2. Понятие кластерного анализа. 3. Задачи кластерного анализа. 4. Способы отображения результатов кластеризации. 5. Понятие и принцип построения дендрограммы. 6. Методы оценки схожести объектов. 7. Метрика расстояния Махаланобиса. 8. Метод кластеризации k-means. 9. Методы ближайших и удаленных соседей.
Лабораторная работа №4 Методы и алгоритмы сжатия данных
Цель работы Целью работы является изучение алгоритмов сжатия информации.
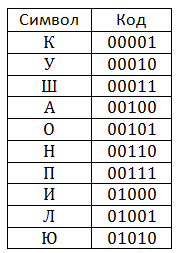
Теоретическая часть Сжатие данных (англ. data compression) — алгоритмическое преобразование данных, производимое с целью уменьшения их объёма. Применяется для более рационального использования устройств хранения и передачи данных. Синонимы — упаковка данных, компрессия, сжимающее кодирование, кодирование источника. Обратная процедура называется восстановлением данных (распаковкой, декомпрессией). В основе любого способа сжатия лежит модель источника данных, или, точнее, модель избыточности. Иными словами, для сжатия данных используются некоторые априорные сведения о том, какого рода данные сжимаются. Не обладая такими сведениями об источнике, невозможно сделать никаких предположений о преобразовании, которое позволило бы уменьшить объём сообщения. Модель избыточности может быть статической, неизменной для всего сжимаемого сообщения, либо строиться или параметризоваться на этапе сжатия (и восстановления). Методы, позволяющие на основе входных данных изменять модель избыточности информации, называются адаптивными. Неадаптивными являются обычно узкоспециализированные алгоритмы, применяемые для работы с данными, обладающими хорошо определёнными и неизменными характеристиками. Подавляющая часть достаточно универсальных алгоритмов являются в той или иной мере адаптивными. Все методы сжатия данных делятся на два основных класса: · Сжатие без потерь · Сжатие с потерями При использовании сжатия без потерь возможно полное восстановление исходных данных, сжатие с потерями позволяет восстановить данные с искажениями, обычно несущественными с точки зрения дальнейшего использования восстановленных данных. Сжатие без потерь обычно используется для передачи и хранения текстовых данных, компьютерных программ, реже — для сокращения объёма аудио- и видеоданных, цифровых фотографий и т. п., в случаях, когда искажения недопустимы или нежелательны. Сжатие с потерями, обладающее значительно большей, чем сжатие без потерь, эффективностью, обычно применяется для сокращения объёма аудио- и видеоданных и цифровых фотографий в тех случаях, когда такое сокращение является приоритетным, а полное соответствие исходных и восстановленных данных не требуется. Алгоритмы сжатия без потерь Алгоритм RLE Все алгоритмы серии RLE основаны на очень простой идее: повторяющиеся группы элементов заменяются на пару (количество повторов, повторяющийся элемент). Рассмотрим этот алгоритм на примере последовательности бит. В этой последовательности будут чередовать группы нулей и единиц. Причём в группах зачастую будет более одного элемента. Тогда последовательности 11111 000000 11111111 00 будет соответствовать следующий набор чисел 5 6 8 2. Эти числа обозначают количество повторений (отсчёт начинается с единиц), но эти числа тоже необходимо кодировать. Будем считать, что число повторений лежит в пределах от 0 до 7 (т.е. нам хватит 3 бит для кодирования числа повторов). Тогда рассмотренная выше последовательность кодируется следующей последовательностью чисел 5 6 7 0 1 2. Легко подсчитать, что для кодирования исходной последовательности требуется 21 бит, а в сжатом по методу RLE виде эта последовательность занимает 18 бит. Хоть этот алгоритм и очень прост, но эффективность его сравнительно низка. Более того, в некоторых случаях применение этого алгоритма приводит не к уменьшению, а к увеличению длины последовательности. Для примера рассмотрим следующую последовательность 111 0000 11111111 00. Соответствующая ей RL-последовательность выглядит так: 3 4 7 0 1 2. Длина исходной последовательности – 17 бит, длина сжатой последовательности – 18 бит. Этот алгоритм наиболее эффективен для чёрно-белых изображений. Также он часто используется, как один из промежуточных этапов сжатия более сложных алгоритмов. Словарные алгоритмы Идея, лежащая в основе словарных алгоритмов, заключается в том, что происходит кодирование цепочек элементов исходной последовательности. При этом кодировании используется специальный словарь, который получается на основе исходной последовательности. Существует целое семейство словарных алгоритмов, но мы рассмотрим наиболее распространённый алгоритм LZW, названный в честь его разработчиков Лепеля, Зива и Уэлча. Словарь в этом алгоритме представляет собой таблицу, которая заполняется цепочками кодирования по мере работы алгоритма. При декодировании сжатого кода словарь восстанавливается автоматически, поэтому нет необходимости передавать словарь вместе с сжатым кодом. Словарь инициализируется всеми одноэлементными цепочками, т.е. первые строки словаря представляют собой алфавит, в котором мы производим кодирование. При сжатии происходит поиск наиболее длинной цепочки уже записанной в словарь. Каждый раз, когда встречается цепочка, ещё не записанная в словарь, она добавляется туда, при этом выводится сжатый код, соответствующий уже записанной в словаре цепочки. В теории на размер словаря не накладывается никаких ограничений, но на практике есть смысл этот размер ограничивать, так как со временем начинаются встречаться цепочки, которые больше в тексте не встречаются. Кроме того, при увеличении размеры таблицы вдвое мы должны выделять лишний бит для хранения сжатых кодов. Для того чтобы не допускать таких ситуаций, вводится специальный код, символизирующий инициализацию таблицы всеми одноэлементными цепочками. Рассмотрим пример сжатия алгоритмом LZW Будем сжимать строку кукушкакукушонкукупилакапюшон. Предположим, что словарь будет вмещать 32 позиции, а значит, каждый его код будет занимать 5 бит. Изначально словарь заполнен следующим образом:
Эта таблица есть, как и на стороне того, кто сжимает информацию, так и на стороне того, кто распаковывает. Сейчас мы рассмотрим процесс сжатия.
В таблице представлен процесс заполнения словаря. Легко подсчитать, что полученный сжатый код занимает 105 бит, а исходный текст (при условии, что на кодирование одного символа мы тратим 4 бита) занимает 116 бит. По сути, процесс декодирования сводится к прямой расшифровке кодов, при этом важно, чтобы таблица была инициализирована также, как и при кодировании. Теперь рассмотрим алгоритм декодирования.
Строку, добавленную в словарь на i-ом шаге мы можем полностью определить только на i+1. Очевидно, что i-ая строка должна заканчиваться на первый символ i+1 строки. Т.о. мы только что разобрались, как можно восстанавливать словарь. Некоторый интерес представляет ситуация, когда кодируется последовательность вида cScSc, где c — это один символ, а S — строка, причём слово cS уже есть в словаре. На первый взгляд может показаться, что декодер не сможет разрешить такую ситуацию, но на самом деле все строки такого типа всегда должны заканчиваться на тот же символ, на который они начинаются. Задание на лабораторную работу 1. Разработать программный продукт для реализации методов сжатия текстовой или графической информации. Реализовать два алгоритма RLE, LZW. 2. На выбор реализовать алгоритм сжатия Хаффмана, либо один из алгоритмов сжатия данных с потерями. 3. Предоставить пользователю возможность выбора файла с изображением или текстом в интерфейсе, либо в командной строке. 4. Выполнить сравнение эффективности степени сжатия с исходным файлом и алгоритмов друг с другом (исходный размер/размер сжатых данных). 4. Дополнительная литература http://habrahabr.ru/post/132289/ http://habrahabr.ru/post/116697/ http://habrahabr.ru/post/141827/ http://algolist.manual.ru/compress/ http://algolist.manual.ru/compress/image/jpeg.php http://algolist.manual.ru/compress/standard/huffman.php http://fic.bos.ru/articles/MLovic_APetrovCodecTest.php https://ru.wikipedia.org/wiki/Код_Хаффмана
5. Контрольные вопросы 1. Понятие сжатия и избыточности данных. 2. Теорема Шеннона. Понятие энтропии. 3. Классификация методов сжатия данных. 4. Алгоритмы сжатия без потерь. 5. Алгоритмы сжатия с потерями. 6. Понятие кодов Хаффмана. 7. Методы, используемые а алгоритме сжатия JPEG. 8. Вейвлет-сжатие.
Лабораторная работа №5
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2021-04-20; просмотров: 331; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.102 (0.009 с.) |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||