
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Тема 2. 3 средства проектирования структур баз данных.
1. Автоматизация проектирования баз данных 2. Case-технология проектирования баз данных Базы данных, как и другие информационные системы, проходят разные этапы своего жизненного цикла, начиная от замысла системы, предпроектного обследования, включая этапы проектирования, эксплуатации, а далее – модернизации системы. Создание крупных проектов практически невозможно без использования автоматизации проектирования. Одним из первых моделей в этой области были форрестеровские модели. Позднее появилась методология автоматизации, на основе которой построены. Позднее Понятие CASE-технологии CASE-технология (Computer-Aided Software/System Engineering) представляет собой совокупность методологий анализа, проектирования, разработки и сопровождения сложных систем и поддерживается комплексом взаимоувязанных средств автоматизации. CASE-технология – это инструментарий для системных аналитиков, разработчиков и программистов, заменяющий бумагу и карандаш компьютером, автоматизируя процесс проектирования и разработки ПО. При использовании методологий структурного анализа появился ряд ограничений (сложность понимания, большая трудоемкость и стоимость использования, неудобство внесения изменений в проектные спецификации и т.д.) С самого начала CASE-технологии и развивались с целью преодоления этих ограничений путем автоматизации процессов анализа и интеграции поддерживающих средств. Они обладают достоинствами и возможностями, перечисленными ниже. Единый графический язык. CASE-технологии обеспечивают всех участников проекта, включая заказчиков, единым строгим, наглядным и интуитивно понятным графическим языком, позволяющим получать обозримые компоненты с простой и ясной структурой. При этом программы представляются двумерными схемами (которые проще в использовании, чем многостраничные описания), позволяющими заказчику участвовать в процессе разработки, а разработчикам – общаться с экспертами предметной области, разделять деятельность системных аналитиков, проектировщиков и программистов, облегчая им защиту проекта перед руководством, а также обеспечивая легкость сопровождения и внесения изменений в систему. Единая БД проекта. Основа CASE-технологии – использование базы данных проекта (репозитория) для хранения всей информации о проекте, которая может разделяться между разработчиками в соответствии с их правами доступа. Содержимое репозитория включает не только информационные объекты различных типов, но и отношения между их компонентами, а также правила использования или обработки этих компонентов. Репозиторий может хранить свыше 100 типов объектов: структурные диаграммы, определения экранов и меню, проекты отчетов, описания данных, логика обработки, модели данных, их организации и обработки, исходные коды, элементы данных и т. п.
Интеграция средств. На основе репозитория осуществляется интеграция CASE-средств и разделение системной информации между разработчиками. При этом возможности репозитория обеспечивают несколько уровней интеграции: общий пользовательский интерфейс по всем средствам, передачу данных между средствами, интеграцию этапов разработки через единую систему представления фаз жизненного цикла, передачу данных и средств между различными платформами. Поддержка коллективной разработки и управления проектом. CASE технология поддерживает групповую работу над проектом, обеспечивая возможность работы в сети, экспорт-импорт любых фрагментов проекта для их развития и/или модификации, а также планирование, контроль, руководство и взаимодействие, т. е. функции, необходимые в процессе разработки и сопровождения проектов. Эти функции также реализуются на основе репозитория. В частности, через репозиторий может осуществляться контроль безопасности (ограничения и привилегии доступа), контроль версий и изменений и др. Макетирование. CASE-технология дает возможность быстро строить макеты (прототипы) будущей системы, что позволяет заказчику на ранних этапах разработки оценить, насколько она приемлема для будущих пользователей и устраивает его. Генерация документации. Вся документация по проекту генерируется автоматически на базе репозитория. Несомненное достоинство CASE- технологии заключается в том, что документация всегда отвечает текущему состоянию дел, поскольку любые изменения в проекте автоматически отражаются в репозитории (известно, что при традиционных подходах к разработке ПО документация в лучшем случае запаздывает, а ряд модификаций вообще не находит в ней отражения).
Верификация проекта. CASE-технология обеспечивает автоматическую верификацию и контроль проекта на полноту и состоятельность на ранних этапах разработки, что влияет на успех разработки в целом Автоматическая генерация объектного кода. Генерация программ в машинном коде осуществляется на основе репозитория и позволяет автоматически построить до 85-90% объектного кода или текстов на языках высокого уровня. Сопровождение. Сопровождение системы в рамках CASE-технологии характеризуется сопровождением проекта, а не программных кодов. Общая характеристика и классификация. Современные CASE-средства охватывают обширную область поддержки многочисленных технологий проектирования ИС: от простых средств анализа и документирования до полномасштабных средств автоматизации, покрывающих весь жизненный цикл ПО. Наиболее трудоемкими этапами разработки ИС являются этапы анализа и проектирования, в процессе которых CASE-средства обеспечивают качество принимаемых технических решений и подготовку проектной документации. При этом большую роль играют методы визуального представления информации. Это предполагает построение структурных или иных диаграмм в реальном масштабе времени, использование многообразной цветовой палитры, сквозную проверку синтаксических правил. Графические средства моделирования предметной области позволяют разработчикам в наглядном виде изучать существующую ИС, перестраивать ее в соответствии с поставленными целями и имеющимися ограничениями. В разряд CASE-средств попадают как относительно дешевые системы для персональных компьютеров с весьма ограниченными возможностями, так и дорогостоящие системы для неоднородных вычислительных плат- форм и операционных сред. Так, современный рынок программных средств насчитывает около 300 различных CASE-средств. При классификации CASE-средств используются следующие признаки: § Ориентация на этапы жизненного цикла; § Функциональная полнота; § Тип используемой модели § Степень независимости от СУБД; Пакет CASE-средств содержит четыре основных компонентов: § Средства анализа, проектирования и разработки. § Средства ввода данных для хранения. § Средства централизованного хранения информации о всём проекте (своеобразная БД проекта). § Средства вывода. По типу используемых моделей CASE – системы условно можно разделить на три основные разновидности: § Структурные. Системы основаны на методах структурного и модульного программирования, структурного анализа. § Объектно-ориентированные. Системы позволяют сократить сроки разработки, а также повысить надёжность и эффективность функционирования ИС. § Комбинированные. Системы поддерживают одновременно структурные и объектно-ориентированные методы. Для CASE-технологии характерны четыре основных типа графических диаграмм: § Функциональное проектирование (DFD). Диаграммы применяются для отображения процессов вход-выход. § Моделирование данных (ERD). § Моделирование поведения (STD). Диаграмма используется для отображения процесса выработки и результатов реализации решений.
§ Структурные диаграммы (карты) – отношения между модулями и внутренняя структура.
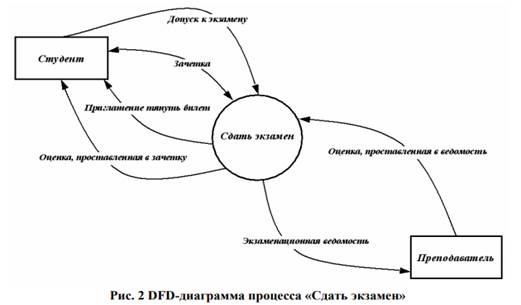
Диаграммы потоков данных. Диаграммы потоков данных (DFD – Data Flow Diagramm) являются основным средством моделирования функциональных требований проектируемой системы. С их помощью эти требования разбиваются на функциональные компоненты (процессы) и представляются в виде сети, связанной потоками данных. Главная цель таких средств – продемонстрировать, как каждый процесс преобразует свои входные данные в выходные, а также выявить отношения между этими процессами. На диаграммах функциональные требования представляются с помощью процессов и хранилищ, связанных потоками данных. Потоки данных являются механизмами, использующимися для моделирования передачи информации (или даже физических компонент) из одной части системы в другую. Важность этого объекта очевидна: он дает название целому инструменту. Потоки на диаграммах обычно изображаются именованными стрелками, ориентация которых указывает направление движения информации. Иногда информация может двигаться в одном направлении, обрабатываться и возвращаться назад в ее источник. Такая ситуация может моделироваться либо двумя различными потоками, либо одним – двунаправленным Назначение функции состоит в продуцировании выходных потоков из входных в соответствии с действием, задаваемым именем функции. Это имя должно содержать глагол в неопределенной форме с последующим дополнением (например, ВЫЧИСЛИТЬ МАКСИМАЛЬНУЮ ВЫСОТУ). Кроме того, каждая функция должна иметь уникальный номер для ссылок на него внутри диаграммы. Этот номер может использоваться совместно с номером диаграммы для получения уникального индекса функции во всей модели. Хранилище позволяет на определенных участках определять данные, которые будут сохраняться в памяти между процессами. Фактически хранилище представляет «срезы» потоков данных во времени. Информация, которую оно содержит, может использоваться в любое время после ее определения, при этом данные могут выбираться в любом порядке. Имя хранилища должно идентифицировать его содержимое и быть существительным. В случае, когда поток данных входит или выходит в/из хранилища и его структура соответствует структуре хранилища, он должен иметь то же самое имя, которое нет необходимости отражать на диаграмме.
Внешняя сущность представляет сущность вне контекста системы, являющуюся источником или приемником системных данных. Ее имя должно содержать существительное, например, СКЛАД ТОВАРОВ. Функции, хранилища и внешние сущности на DFD-диаграмме связываются дугами, представляющими потоки данных. Дуги могут разветвляться или сливаться, что означает, соответственно, разделение потока данных на части, либо слияние объектов При интерпретации DFD-диаграммы используются следующие правила: функции преобразуют входящие потоки данных в выходящие; хранилища данных не изменяют потоки данных, а служат только для хранения поступающих объектов; – преобразования потоков данных во внешних сущностях игнорируются. Помимо этого, для каждого информационного потока и хранилища определяются связанные с ними элементы данных. Каждому элементу данных присваивается имя, также для него может быть указан тип данных и формат. Именно эта информация является исходной на следующем этапе проектирования – построении модели «сущность-связь». Пример. Рассмотрим процесс СДАТЬ ЭКЗАМЕН. У нас есть две сущности СТУДЕНТ и ПРЕПОДАВАТЕЛЬ. Опишем потоки данных, которыми обменивается наша проектируемая система с внешними объектами.
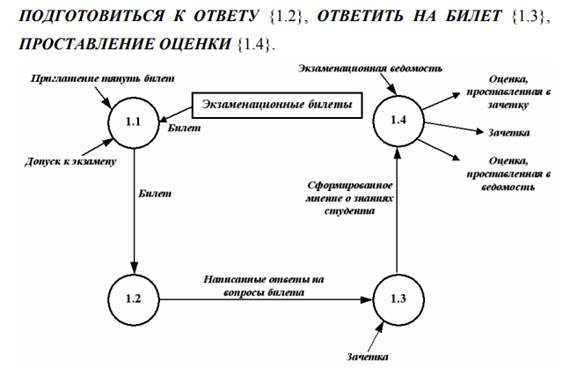
Со стороны сущности СТУДЕНТ опишем информационные потоки. Для сдачи экзамена необходимо, чтобы у СТУДЕНТА была ЗАЧЕТКА, а также чтобы он имел ДОПУСК К ЭКЗАМЕНУ. Результатом сдачи экзамена, т.е. выходными потоками будут ОЦЕНКА ЗА ЭКЗАМЕН и ЗАЧЕТКА, в которую будет проставлена ОЦЕНКА. Со стороны сущности ПРЕПОДАВАТЕЛЬ информационные потоки следующие: ЭКЗАМЕНАЦИОННАЯ ВЕДОМОСТЬ, согласно которой будет известно, что СТУДЕНТ допущен до экзамена, а также официальная бумага, куда будет занесен результат экзамена, т.е. ОЦЕНКА ЗА ЭКЗАМЕН, проставленная в ЭКЗАМЕНАЦИОННУЮ ВЕДОМОСТЬ. Теперь детализируем процесс СДАЧА ЭКЗАМЕНА. Этот процесс будет содержать следующие процессы: ВЫТЯНУТЬ БИЛЕТ {1.1}, 24 ПОДГОТОВИТЬСЯ К ОТВЕТУ {1.2}, ОТВЕТИТЬ НА БИЛЕТ {1.3}, ПРОСТАВЛЕНИЕ ОЦЕНКИ {1.4}.
Технология S TD. Используется для отображения процесса выработки и результатов реализации решений, построения моделей, описывающих функционирование систем.
Рассмотрим рисунок:
Правила интерпретации модели: функциональный блок (функция) преобразует входные объекты в выходные; управление определяет, когда и как это преобразование может или должно произойти; механизм (исполнитель) осуществляет это преобразование. Язык инфологического моделирования. Язык ER-диаграмм типа «сущность — связь» используется для построения инфологических моделей. Базовыми структурами в ER-модели являются «типы сущностей» и «типы связей».
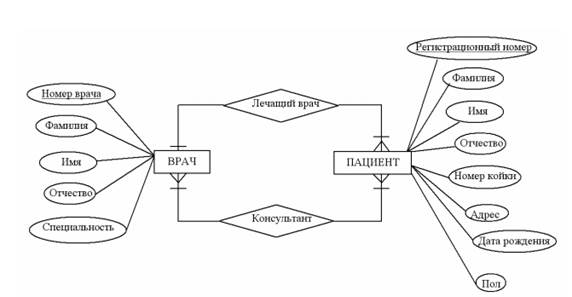
Фрагмент концептуальной схемы:
Пример. М ножества связей между сущностями может быть описан следующим образом: Врач (Номер_врача, Фамилия, Имя, Отчество, Специальность)
Пациент (Регистрационный_номер, Номер койки, Фамилия, Имя, Отчество, Адрес, Дата рождения, Пол)
Лечащий_врач [Врач (1,1), Пациент (1,M)] (Номер_врача, Регистрационный_номер)
Консультант [Врач (1,M),Пациент (1,М)] (Номер_врача, Регистрационный_номер).
Обозначения:
|
||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2021-04-13; просмотров: 1302; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.119.118.99 (0.029 с.) |
||||||||||||||||||||

 Рассмотренные методологии фокусируют внимание на потоках данных, их главное назначение – создание базированных на графике документов по функциональным требованиям. Методологии поддерживаются традиционными методами проектирования спецификаций и обеспечивают один из лучших способов связи между аналитиками, разработчиками и пользователями системы.
Рассмотренные методологии фокусируют внимание на потоках данных, их главное назначение – создание базированных на графике документов по функциональным требованиям. Методологии поддерживаются традиционными методами проектирования спецификаций и обеспечивают один из лучших способов связи между аналитиками, разработчиками и пользователями системы.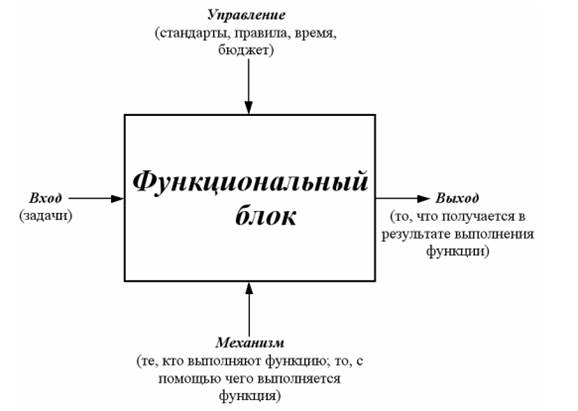
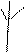
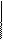
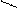
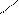


 Связь 1:1 Связь М:М
Связь 1:1 Связь М:М  Связь 1:М Связь обязательная
Связь 1:М Связь обязательная
 Связь с использованием атрибутов связанной сущности
Связь с использованием атрибутов связанной сущности


