Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Тема № 1. Структура и классификация информационных системСодержание книги
Поиск на нашем сайте Тема № 2. Основные понятия информационного обеспечения автоматизированных систем управления (АСУ) База данных это часть внутримашинной информационной базы, представляющая совокупность массивов (файлов, сегментов и т.д.) и выделенная для реализации определенных; функций АСУ. База знаний это связанная в семантическую сеть совокупность высказываний Внемашинное информационное обеспечение включает: систему классификации и кодирования информации; систему конструкторской, технологической и технической производственной документации (нормативно-справочной); оперативную документацию; систему организации ведения, хранения, внесения изменений в нормативную документацию. Внешняя выходная информация делится на учетно-расчетную и справочную. Справочная информация представляет собой различного рода справки вышестоящим уровням управления о ходе выполнения производственного задания. Внутренняя входная информация подразделяется на три группы: информация о продукции; о процессах; о внутренних возмущениях. Внутренняя выходная информация подразделяется на несколько групп: плановая (для участков и рабочих мест); транспортные команды; технические задания мастерам, работникам ОТК; рабочие команды на ликвидацию внутренних возмущений. Внутримашинное обеспечение содержит: систему программ организации, накопления, ведения и доступа к данным; массивы данных на машинных носителях. Вторичная информация получается в результате обработки первичной информации и может быть промежуточной или результатной. Документ представляет собойинформационную совокупность, которая имеет вполне самостоятельное смысловое значение и характеризуется полным набором реквизитов и показателей. Данная информационная совокупность должна быть зафиксирована на материальном носителе в соответствии с существующими правилами и иметь юридическую силу. Совокупность однородных документов представляет собой массив документов. Переменная информация отражает фактические количественные и качественные характеристики производственно-хозяйственной деятельности объекта. Она может меняться для каждого фиксируемого случая как по названиям реквизитов признаков, так и по количественной величине реквизитов оснований. Переменная информация, как правило, участвует в одном цикле обработки, поэтому ее еще называют разовой. Позиция — это отдельный элемент номенклатуры, например номенклатурный номер материала. Показатель. Основание с относящимися к нему признаками, образующими информационную совокупность с минимальным составом, достаточным для образования документа, называется показателем: основание + k признаков = показатель Постоянная информация остается неизменной в течение длительного времени, многократно используется при обработке переменной информации. Постоянство информации характеризуется коэффициентом стабильности, который определяется отношением количества позиций номенклатуры, не изменяющейся в течение определенного периода Н, к общему количеству позиций этой номенклатуры на начало данного периода Л, т.е. К==Н/П. Коэффициент стабильности показывает, какая часть массива остается длительно неизменной в течение определенного периода. Признаки характеризуют качественные свойства сущностей (время и место событий, обстоятельства, при которых были получены числа-основания). Реквизит - информационная совокупность, которая не поддается дальнейшему расчленению на единицы информации и характеризует отдельное свойство сущности. Реквизиты являются минимальными единицами информации, на которых образуются все СЕИ. Сообщение - Совокупность информации, достаточная для выработки какого-либо суждения о конкретном явлении, факте, процессе Составная единица информации. Информационные системы к - го уровня являются информационной совокупностью, представляющей экономическую информацию массива документов некоторой формы. Такая информационная совокупность принимается за единицу информации, которая называется составной единицей информации (СЕИ). Экономическая информация представляет собой совокупность различных сведений экономического характера, возникающих при подготовке производства, в процессе производственно-хозяйственной деятельности и в управлении этой деятельностью. Экономическая информация является объектом сбора, регистрации, передачи, хранения, обработки и используется для осуществления функций управления народным хозяйством и его отдельными звеньями различного уровня Информационная совокупность - это полный набор информации, достаточный для всесторонней характеристики объекта за некоторый отрезок времени. Номенклатура —это универсальное множество данной информационной совокупности, например перечень всех материалов, потребляемых данным предприятием. Основания характеризуют количественные свойства сущностей, полученные в результате вычислений или измерений. Первичная информация возникает непосредственно в процессе деятельности объекта и регистрируется на начальной стадии процесса управления (стадии первичного учета) Тема № 3. Модели данных Иерархическая модель данных. В иерархической модели связи между данными можно описать с помощью упорядоченного графа (или дерева). Многомерная модель данных. Многомерность модели данных означает не многомерность визуализации цифровых данных, а многомерное логическое представление структуры информации при описании и в операциях манипулирования данными Модель данных представляет собой множество структур данных, ограничений целостности и операций манипулирования данными. Объектно-ориентированная модель данных. В объектно-ориентированной модели при представлении данных имеется возможность идентифицировать отдельные записи базы. Между записями базы данных и функциями их обработки устанавливаются взаимосвязи с помощью механизмов, подобных соответствующим средствам в объектно-ориентированных языках программирования. Постреляционная модель данных представляет собой расширенную реляционную модель, снимающую ограничение неделимости данных, хранящихся в записях таблиц. Реляционная модель данных представляет собой множество элементов, называемых кортежами. Сетевая модель данных Сетевая модель данных позволяет отображать разнообразные взаимосвязи элементов данных в виде произвольного графа, обобщая тем самым иерархическую модель данных КУРС ЛЕКЦИЙ ПО ДИСЦИПЛИНЕ «ИНФОРМАЦИОННОЕ ОБЕСПЕЧЕНИЕ УПРАВЛЕНЧЕСКОЙ ДЕЯТЕЛЬНОСТИ»
Примеры информационных систем Пример. Информационная система по отысканию рыночных ниш. При покупке товаров в некоторых фирмах информационная система регистрирует данные о покупателе, что позволяет: ¾ определять группы покупателей, их состав и запросы, а затем ориентироваться в своей стратегии на наиболее многочисленную группу; ¾ посылать потенциальным покупателям различные предложения, рекламу, напоминания; ¾ предоставлять постоянным покупателям товары и услуги в кредит, со скидкой, с отсрочкой платежей. Пример. Информационные системы, ускоряющие потоки товаров. Предположим, фирма специализируется на поставках продуктов в определенное учреждение, например в больницу. Как известно, иметь большие запасы продуктов на складах фирмы очень невыгодно, а не иметь их невозможно. Для того чтобы найти оптимальное решение этой проблемы, фирма устанавливает терминалы в обслуживаемом учреждении и подключает их к информационной системе. Заказчик прямо с терминала вводит свои пожелания по предоставляемому ему каталогу. Эти данные поступают в информационную систему по учету заказов. Менеджеры, делая выборки по поступившим заказам, принимают оперативныe управленческие решения по доставке заказчику нужного товара за короткий промежуток времени. Таким образом, экономятся огромные деньги на хранение товаров, ускоряется и упрощается поток товаров, отслеживаются потребности покупателей. Пример. Информационные системы по снижению издержек производства. Эти информационные системы, отслеживая все фазы производственного процесса, способствуют улучшению управления и контроля, более рациональному планированию и использованию персонала и, как следствие, снижению себестоимости производимой продукции и услуг. Пример. Информационная система, установленная в фирме по сдаче автомашин внаем, отслеживает местонахождение, стоимость и техническое состояние парка прокатных машин. Это позволяет минимизировать потери от простоя и пустого прогона для каждой автомашины, перераспределяя предложения согласно спросу. Пример. Информационные системы автоматизации технологии ("менеджмент уступок"). Суть этой технологии состоит в том, что, если доход фирмы остается в рамках рентабельности, потребителю делаются разные скидки в зависимости от количества и длительности контрактов. В этом случае потребитель становится, заинтересован во взаимодействии с фирмой, а фирма тем самым привлекает дополнительное число клиентов. Если же клиент не желает взаимодействовать с данной фирмой и переходит на обслуживание другой, то его затраты могут возрасти из-за потери предоставляемых ему ранее скидок. Пример. Информационная система по продаже авиабилетов позволяет проанализировать архивные данные за многие годы, оценить перспективы наполнения салона, назначить разумную цену на каждое место, снизить количество непроданных билетов и пр. Она резервирует каждое место на самолет в США за три месяца до полета 1,5 раза, т.е. два места резервируются за тремя пассажирами. Пример. Информационная система банка обеспечивает все виды оплат по счетам его клиентов. Она умышленно сделана несовместимой с информационными системами других банков. Таким образом, клиент попадает в круг услуг банка, из которого ему трудно выйти. В обмен банк предлагает ему различные скидки и бесплатные услуги.
Тема № 2. Основные понятия информационного обеспечения автоматизированных систем управления (АСУ)
2.1. Понятие экономической информации 2.2. Свойства экономической информации 2.3. Классификация экономической информации 2.4. Понятие информационного обеспечения АСУ 2.5 Организация и обработка внутримашинной информационной базы
Тема №3. Модели данных
3.1. Понятие модели данных. 3.2. Иерархическая модель. 3.3. Сетевая модель. 3.4. Реляционная модель. 3.5. Постреляционная модель. 3.6. Многомерная модель. 3.7.Объектно-ориентированная модель. Понятие модели данных Создавая базу данных пользователь стремится упорядочить информацию по различным признакам и быстро производить выборку с произвольным сочетанием признаков. Большое значение при этом приобретает структурирование данных, то есть введение соглашений о способах представления данных. База данных – это поименованная совокупность данных, отражающая состояние объектов и их отношений в рассматриваемой предметной области. Ядром любой базы данных является модель данных. Модель данных представляет собой множество структур данных, ограничений целостности и операций манипулирования данными. Хранимые в базе данные имеют определенную логическую структуру — иными словами, описываются некоторой моделью представления данных (моделью данных), поддерживаемой СУБД. К числу классических относятся следующие модели данных: - иерархическая, - сетевая, - реляционная. Кроме того, в последние годы появились и стали более активно внедряться на практике следующие модели данных: - постреляционная, - многомерная, - объектно-ориентированная. Разрабатываются также всевозможные системы, основанные на других моделях данных, расширяющих известные модели. В их числе можно назвать объектно-реляционные, дедуктивно-объектно-ориентированные, семантические, концептуальные и ориентированные модели. Некоторые из этих моделей служат для интеграции баз данных, баз знаний и языков программирования.
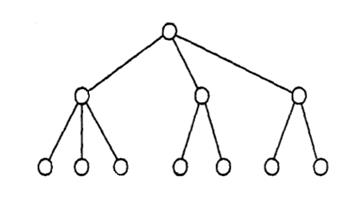
Иерархическая модель В иерархической модели связи между данными можно описать с помощью упорядоченного графа (или дерева). Упрощенно представление связей между данными в иерархической модели показано на рисунке 3.1. Для описания структуры (схемы) иерархической БД на некотором языке программирования используется тип данных «дерево». Тип «дерево» является составным. Он включает в себя подтипы («поддеревья»), каждый из которых, в свою очередь, является типом «дерево». Каждый из типов «дерево» состоит из одного «корневого» типа и упорядоченного набора подчиненных типов. Каждый из элементарных типов, включенных в тип «дерево», является простым или составным типом «запись». Простая «запись» состоит из одного типа, например, числового, а составная «запись» объединяет некоторую совокупность типов, например, целое, строку символов и указатель (ссылку). Пример типа «дерево» как совокупности типов показан на рисунке 3.2
Рис. 3.1. Представление связей в иерархической модели
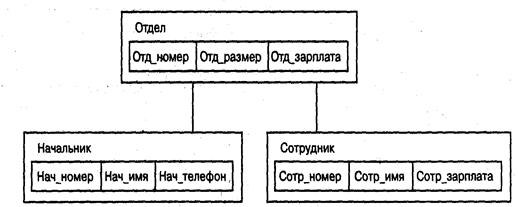
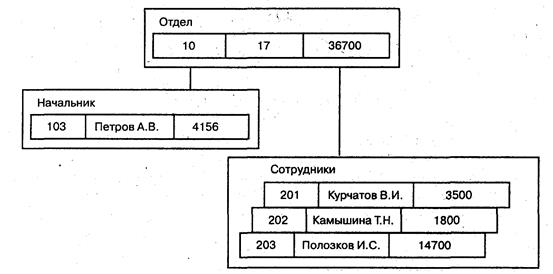
Рис 3.2. Пример типа «дерево» Корневым называется тип, который имеет подчиненные типы, и сам не является подтипом. Подчиненный тип (подтип) является потомком по отношению к типу, который выступает для него в роли предка (родителя). Потомки одного и того же типа являются близнецами по отношению друг к другу. В целом тип «дерево» представляет собой иерархически организованный набор типов «запись». Иерархическая БД представляет собой упорядоченную совокупность экземпляров данных типа «дерево» (деревьев), содержащих экземпляры типа «запись» (записи). Часто отношения родства между типами переносят на отношения между самими записями. Поля записей хранят собственно числовые или символьные значения, составляющие основное содержание БД. Обход всех элементов иерархической БД обычно производится сверху вниз и слева направо. Данные в базе с приведенной схемой (рисунок 3.2) могут выглядеть, например, как показано на рисунке 3.3.
Рис. 3.3. Данные в иерархической базе
Для организации физического размещения иерархических данных в памяти ЭВМ могут использоваться следующие группы методов: - представление линейным списком с последовательным распределением памяти (адресная арифметика, левосписковые структуры); - представление связными линейными списками (методы, использующие указатели и справочники). К основным операциям манипулирования иерархически организованными данными относятся следующие: - поиск указанного экземпляра БД (например, дерева со значением 10 в поле Отд_номер); - переход от одного дерева к другому; - переход от одной записи к другой внутри дерева (например, к следующей записи типа Сотрудники); - вставка новой записи в указанную позицию; - удаление текущей записи и т. д. В соответствии с определением типа «дерево», можно заключить, что между предками и потомками автоматически поддерживается контроль целостности связей. Основное правило контроля целостности формулируется следующим образом: потомок не может существовать без родителя, а у некоторых родителей может не быть потомков. Механизмы поддержания целостности связей между записями различных деревьев отсутствуют. К достоинствам иерархической модели данных относятся эффективное использование памяти ЭВМ и неплохие показатели времени выполнения основных операций над данными. Иерархическая модель данных удобна для работы с иерархически упорядоченной информацией. Недостатком иерархической модели является ее громоздкость для: обработки информации с достаточно сложными логическими связями, а также сложность понимания для обычного пользователя.
Сетевая модель Сетевая модель данных позволяет отображать разнообразные взаимосвязи элементов данных в виде произвольного графа, обобщая тем самым иерархическую модель данных (рисунок 3.4).
Рис. 3.4. Представление связей в сетевой модели
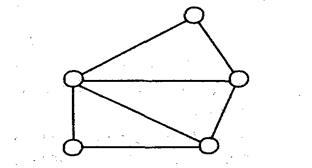
Для описания схемы сетевой БД используется две группы типов: «запись» и «связь». Тип «связь» определяется для двух типов «запись»: предка и потомка. Переменные типа «связь» являются экземплярами связей. Сетевая БД состоит из набора записей и набора соответствующих связей. На формирование связи особых ограничений не накладывается. Если в иерархических структурах запись-потомок могла иметь только одну запись-предка, то в сетевой модели данных запись-потомок может иметь произвольное число записей-предков (сводных родителей). Пример схемы простейшей сетевой БД показан на рисунке 3.5. Типы связей здесь обозначены надписями на соединяющих типы записей линиях. В различных СУБД сетевого типа для обозначения одинаковых по сути понятий зачастую используются различные термины. Например, такие, как элементы и агрегаты данных, записи, наборы, области и т. д. Физическое размещение данных в базах сетевого типа может быть организовано практически теми же методами, что и в иерархических базах данных.
Рис. 3.5. Пример схемы сетевой БД
К числу важнейших операций манипулирования данными баз сетевого типа можно отнести следующие: - переход от предка к первому потомку; - переход от потомка к предку; - создание новой записи; - удаление текущей записи; - обновление текущей записи; - включение записи в связь; - изменение связей и т. д. Достоинством сетевой модели данных является возможность эффективной реализации по показателям затрат памяти и оперативности. В сравнении с иерархической моделью сетевая модель предоставляет большие возможности в смысле допустимости образования произвольных связей. Недостатком сетевой модели данных является высокая сложность и жесткость схемы БД, построенной на ее основе, а также сложность для понимания и выполнения обработки информации в БД обычным пользователем. Кроме того, в сетевой модели данных ослаблен контроль целостности связей вследствие допустимости установления произвольных связей между записями.
Реляционная модель Реляционная модель данных предложена сотрудником фирмы IBM Эдгаром Коддом и основывается на понятии отношение (relation). Отношение представляет собой множество элементов, называемых кортежами. Подробно теоретическая основа реляционной модели данных рассматривается в следующем разделе. Наглядной формой представления отношения является привычная для человеческого восприятия двумерная таблица. Таблица имеет строки (записи) и столбцы (колонки). Каждая строка таблицы имеет одинаковую структуру и состоит из полей. Строкам таблицы соответствуют кортежи, а столбцам — атрибуты отношения. С помощью одной таблицы удобно описывать простейший вид связей между данными, а именно: деление одного объекта (явления, сущности; системы и проч.), информация о котором хранится в таблице, на множество подобъектов, каждому из которых соответствует строка или запись таблицы. При этом каждый из подобъектов имеет одинаковую структуру или свойства, описываемые соответствующими значениями полей записей. Например, таблица может содержать сведения о группе обучаемых, о каждом из которых известны следующие характеристики: фамилия, имя и отчество, пол, возраст и образование. Поскольку в рамках одной таблицы не удается описать более сложные логические структуры данных из предметной области, применяют связывание таблиц. Физическое размещение данных в реляционных базах на внешних носителях легко осуществляется с помощью обычных файлов. Достоинство реляционной модели данных заключается в простоте, понятности и удобстве физической реализации на ЭВМ. Именно простота и понятность для пользователя явились основной причиной их широкого использования. Проблемы же эффективности обработки данных этого типа оказались технически вполне разрешимыми. Основными недостатками реляционной модели являются следующие: отсутствие стандартных средств идентификации отдельных записей и сложность описания иерархических и сетевых связей.
Постреляционная модель Классическая реляционная модель предполагает неделимость данных, хранящихся в полях записей таблиц. Это означает, что информация в таблице представляется в первой нормальной форме (см. тему 6). Постреляционная модель данных представляет собой расширенную реляционную модель, снимающую ограничение неделимости данных, хранящихся в записях таблиц. Постреляционная модель данных допускает многозначные поля — поля, значения которых состоят из подзначений. Набор значений многозначных полей считается самостоятельной таблицей, встроенной в основную таблицу Поскольку постреляционная модель допускает хранение в таблицах ненормализованных данных, возникает проблема обеспечения целостности и непротиворечивости данных. Эта проблема решается включением в СУБД механизмов, подобных хранимым процедурам в клиент-серверных системах. Для описания функций контроля значений в полях имеется возможность создавать процедуры (коды конверсии и коды корреляции), автоматически вызываемые до или после обращения к данным. Коды корреляции выполняются сразу после чтения данных, перед их обработкой. Коды конверсии, наоборот, выполняются после обработки данных. Достоинством постреляционной модели является возможность представления совокупности связанных реляционных таблиц одной постреляционной таблицей. Это обеспечивает высокую наглядность представления информации и повышение эффективности ее обработки. Недостатком постреляционной модели является сложность решения проблемы обеспечения целостности и непротиворечивости хранимых данных.
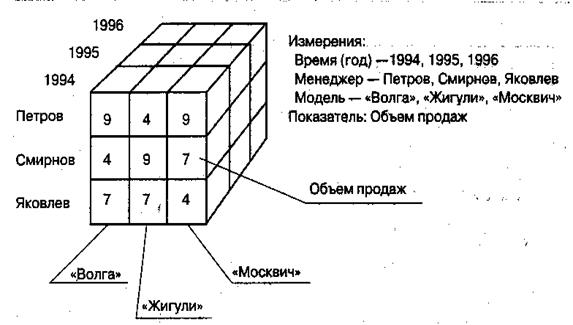
Многомерная модель Многомерный подход к представлению данных в базе появился практически одновременно с. реляционным, но реально работающих многомерных СУБД (МСУБД) до настоящего времени было очень мало. С середины 90-х годов интерес к ним стал приобретать массовый характер. Толчком послужила в 1993 году программная статья одного из основоположников реляционного подхода Э. Кодда. В ней сформулированы 12 основных требований к системам класса OLAP (Online Analytical Processing — оперативная аналитическая обработка), важнейшие из которых связаны с возможностями концептуального представления и обработки многомерных данных. Многомерные системы позволяют оперативно обрабатывать информацию для проведения анализа и принятия решения. В развитии концепций ИС можно выделить следующие два направления: ¾ системы оперативной (транзакционной) обработки; ¾ системы аналитической обработки (системы поддержки принятия решений). Реляционные СУБД предназначались для информационных систем оперативной обработки информации и в этой области были весьма эффективны. В системах аналитической обработки они показали себя несколько неповоротливыми и недостаточно гибкими. Более эффективными здесь оказываются многомерные СУБД (МСУБД), Многомерные СУБД являются узкоспециализированными СУБД, предназначенными для интерактивной аналитической обработки информации. Раскроем основные понятия, используемые в этих СУБД: агрегируемость, историчность и прогнозируемость данных. Агрегируемостъ данных означает рассмотрение информации на различных уровнях ее обобщения. В информационных системах степень детальности представления информации для пользователя зависит от его уровня: аналитик, пользователь-оператор, управляющий, руководитель. Историчность данных предполагает обеспечение высокого уровня статичности (неизменности) собственно данных и их взаимосвязей, а также обязательность привязки данных ко времени. Статичность данных позволяет использовать при их обработке специализированные методы загрузки, хранения, индексации и выборки. Временная привязка данных необходима для частого выполнения запросов, имеющих значения времени и даты в составе выборки. Необходимость упорядочения данных по времени в процессе обработки и представления данных пользователю накладывает требования на механизмы хранения и доступа к информации. Так, для уменьшения времени обработки запросов желательно, чтобы данные всегда были отсортированы в том порядке, в котором они наиболее часто запрашиваются, Прогнозируемость данных подразумевает задание функций прогнозирования и применение их к различным временным интервалам. Многомерность модели данных означает не многомерность визуализации цифровых данных, а многомерное логическое представление структуры информации при описании и в операциях манипулирования данными. По сравнению с реляционной моделью многомерная организация данных обладает более высокой наглядностью и информативностью. Для иллюстрации на рисунке 3.6 приведены реляционное (а) и многомерное (б) представления одних и тех же данных об объемах продаж автомобилей. Если речь идет о многомерной модели с мерностью больше двух, то не обязательно визуально информация представляется в виде многомерных объектов (трех-, четырех- и более мерных гиперкубов). Пользователю и в этих случаях более удобно иметь дело с двухмерными таблицами или графиками. Данные при этом представляют собой «вырезки» (точнее, «срезы») из многомерного хранилища данных, выполненные с разной степенью детализации. а)
б)
Рис. 3.6. Реляционное и многомерное представление данных
Рассмотрим основные понятия многомерных моделей данных, к числу которых относятся измерение и ячейка. Измерение (Dimension) — это множество однотипных данных, образующих одну из граней гиперкуба. Примерами наиболее часто используемых временных измерений являются Дни, Месяцы, Кварталы и Годы. В качестве географических измерений широко употребляются Города, Районы, Регионы и Страны. В многомерной модели данных измерения играют роль индексов, служащих для идентификации конкретных значений в ячейках гиперкуба. Ячейка (Cell) или показатель — это поле, значение которого однозначно определяется фиксированным набором измерений. Тип поля чаще всего определен как цифровой. В существующих МСУБД используются два основных варианта (схемы) организации данных: гиперкубическая и поликубическая. В поликубической схеме предполагается, что в БД может быть определено несколько гиперкубов с различной размерностью и с различными измерениями в качестве граней. В случае гиперкубической схемы предполагается, что все показатели определяются одним и тем же набором измерений. Это означает, что при наличии нескольких гиперкубов БД все они имеют одинаковую размерность и совпадающие измерения. Очевидно, в некоторых случаях информация в БД может быть избыточной (если требовать обязательное заполнение ячеек). В случае многомерной модели данных применяется ряд специальных операций, к которым относятся: формирование «среза», «вращение», агрегация и детализация. «Срез» (Slice) представляет собой подмножество гиперкуба, полученное в результате фиксации одного или нескольких измерений. Формирование «срезов»- выполняется для ограничения используемых пользователем значений, так как все значения гиперкуба практически никогда одновременно не используются. Например, если ограничить значения измерения Модель автомобиля в гиперкубе (рисунке 3.7) маркой «Жигули», то получится двухмерная таблица продаж этой марки автомобиля различными менеджерами по годам.
Рис. 3.7. Пример трехмерной модели
Операция «вращение» (Rotate) применяется при двухмерном представлении данных. Суть ее заключается в изменении порядка измерений при визуальном представлении данных. Так, «вращение» двумерной таблицы, показанной на рисунке 3.6, приведет к изменению ее вида таким образом, что по оси Х будет марка автомобиля, а по оси Y — время. Для иллюстрации смысла операции «агрегация» предположим, что у нас имеется гиперкуб, в котором помимо измерений гиперкуба, приведенного на рисунке 3.7, имеются еще измерения: Подразделение, Регион, Фирма, Страна. Заметим, что в этом случае в гиперкубе существует иерархия (снизу вверх) отношений между измерениями: Менеджер, Подразделение, Регион, Фирма, Страна. Пусть в описанном гиперкубе определено, насколько успешно в 1995 году менеджер Петров продавал автомобили «Жигули» и «Волга». Тогда, поднимаясь на уровень выше по иерархии, с помощью операции «агрегация» можно выяснить, как выглядит соотношение продаж этих же моделей на уровне подразделения, где работает Петров. Основным достоинством многомерной модели данных является удобство и эффективность аналитической обработки больших объемов данных, связанных со временем. При организации обработки аналогичных данных на основе реляционной модели происходит нелинейный рост трудоемкости операций в зависимости от размерности БД и существенное увеличение затрат оперативной памяти на индексацию. Недостатком многомерной модели данных является ее громоздкость для простейших задач обычной оперативной обработки информации.
Понятие предметной области Каждая информационная система в зависимости от ее назначения имеет дело с частью реального мира, которую принято называть предметной областью (ПО) системы. ПО может относится к любому типу организаций: банк, университет, завод, магазин и т.д. Предметная область информационной системы - это совокупность реальных объектов (сущностей), которые представляют интерес для пользователей. Объект (сущность) - предмет, процесс или явление, о котором собирается информация, необходимая для решения задачи. Объектом может быть человек, предмет, событие. Каждый объект характеризуется рядом основных свойств - атрибутов. Атрибутом называется поименованная характеристика объекта. Атрибут показывает, какая информация должна быть собрана об объекте. Например, объект - клиент банка. Атрибуты - номер счета, адрес, сумма вклада.
Логическое проектирование Логическое проектирование представляет собой необходимый этап при создании БД. Основной задачей логического проектирования является разработка логической схемы, ориентированной на выбранную систему управления базами данных (СУБД). Этап логического проектирования в отличие от концептуального проектирования полностью ориентирован на инструментальные средства компьютера. Процесс логического проектирования состоит из следующих этапов: 1. Выбор конкретной СУБД. 2. Отображение концептуальной схемы на логическую схему. 3. Выбор ключей. 4. Описание языка запросов. Одним из основных критериев выбора СУБД является оценка того, насколько эффективно внутренняя модель данных, поддерживаемая системой, способна описать концептуальную схему. Существующие СУБД делятся по типам моделей данных на реляционные, иерархические и сетевые. СУБД, t ориентированные на персональные компьютеры, как правило, поддерживают реляционную модель данных. Подавляющее большинство современных СУБД - реляционные. Если выбрана реляционная система, то концептуальную схему БД предстоит отображать на реляционную. При отображении концептуальной схемы на реляционную модель данных каждый прямоугольник схемы отображается в таблицу. При этом следует учитывать ограничения на размеры таблиц, которые накладывает выбранная СУБД. Отобразим концептуальную схему, изображенную на рисунке 5.5, на реляционную модель. Каждый прямоугольник (сущность) этой схемы будет представлен в виде таблицы. Каждый столбец таблицы предназначен для записи одного атрибута и имеет свое уникальное имя. Представим сущность ПРЕПОДАВАТЕЛЬ (ФИО, должность, звание, кафедра, стаж), в виде таблицы.
ПРЕПОДАВАТЕЛЬ
Определим структуру каждой таблицы, то есть зададим типы и размеры полей.
Можно произвести оценку требуемого объема памяти на хранение данной таблицы. На хранение одной записи необходимо 21+15+10+20+2=68 байт. Всего предусмотрено 100 записей, то есть на хранение таблицы потребуется 6800 байт. Аналогично поступают со всеми остальными сущностями (объектами) концептуальной схемы. Сделаем краткие выводы. Концептуальная модель представляет объекты предметной области и их взаимосвязи без указания способов их физического хранения. Таким образом, концептуальная модель является, по существу, моделью предметной области. При проектировании концептуальной модели все усилия разработчика должны быть направлены в основном на структуризацию данных и выявление взаимосвязей между ними без рассмотрения особенностей реализации и вопросов эффективности обработки. Проектирование концептуальной модели основано на анализе решаемых на этом предприятии задач по обработке данных. Концептуальная модель включает описания объектов и их взаимосвязей, представляющих интерес в рассматриваемой предметной области и выявляемых в результате анализа данных. Концептуальная модель транспонируется затем в модель данных, совместимую с выбранной СУБД. Версия концептуальной модели, которая может быть обеспечена конкретной СУБД, называется логической моделью.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2021-03-09; просмотров: 566; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.102 (0.013 с.) |