
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
ЛЕКЦИЯ №4 Первичное и эффективное кодированиеСтр 1 из 9Следующая ⇒
ЛЕКЦИЯ №4 Первичное и эффективное кодирование Первичные коды.
Вместо знаков сообщений передают их условные обозначения, представляющие собой комбинации единичных элементов. Эти комбинации принято называть кодовыми комбинациями (N), а отдельные символы, входящие в комбинацию – элементами кода (m). Совокупность всех кодовых комбинаций и соответствующие им знаки сообщения образуют код. Первичные коды (называют также: простые, обыкновенные) используются для первичного преобразования дискретных сообщений в сигналы и получаются на выходе кодера источника сообщения. Простые коды делят на равномерные и неравномерные. Равномерными называются такие коды, в которых все кодовые комбинации имеет одинаковую длину (n), т.е. имеют одинаковое число единичных элементов. Неравномерными называют такие коды, кодовые комбинации которых могут отличаться одна от другой числом единичных элементов. Оценка простых кодов производится по скорости передачи, помехоустойчивости и сложности технической реализации. Равномерные простые коды Максимальная скорость передачи равномерного простого двоичного кода будет тогда и только тогда, когда выполняются условия Однако, тот факт, что каждая кодовая комбинация в равномерных кодах имеет одинаковое количество двоичных элементов, позволяет получать простые правила кодирования и декодирования и, соответственно, простую техническую реализация кодирующих и декодирующих устройств. Кроме того, за счет простых способов определения на приемной стороне начала и конца каждой кодовой комбинации, что является необходимым условием однозначного декодирования, помехоустойчивость равномерных кодов достаточно высокая. Важным фактором является также то, что простые равномерные коды легко преобразуются в корректирующие коды для повышения достоверности информации. Все это привело к тому, что равномерные коды получили широкое применение на практике.
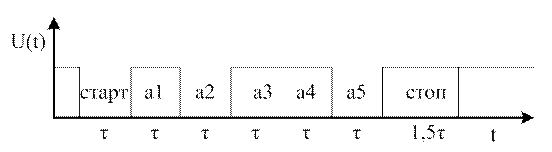
Основу двоичного пятизначного двухрегистрового простого равномерного телеграфного кода МТК№2 составляет код Муррея, в котором при двух регистрах двоичного пятизначного кода всего может быть (2!) вариантов.
Регистр |
МТК№2 | |||||||||||
| Лат. | Рус. | Цифровой | а1 | а2 | а3 | а4 | а5 | ||||||
| 1 | A | А | - | 1 | 1 | 0 | 0 | 0 | |||||
| 2 | B | Б | ? | 1 | 0 | 0 | 1 | 1 | |||||
| 3 | C | Ц | : | 0 | 1 | 1 | 1 | 0 | |||||
| 4 | D | Д | Кто там? | 1 | 0 | 0 | 1 | 0 | |||||
| 5 | E | Е | 3 | 1 | 0 | 0 | 0 | 0 | |||||
| 6 | F | Ф | Э | 1 | 0 | 1 | 1 | 0 | |||||
| 7 | G | Г | Ш | 0 | 1 | 0 | 1 | 1 | |||||
| 8 | H | Х | Щ | 0 | 0 | 1 | 0 | 1 | |||||
| 9 | I | И | 8 | 0 | 1 | 1 | 0 | 0 | |||||
| 10 | J | Й | Ю | 1 | 1 | 0 | 1 | 0 | |||||
| 11 | K | К | ( | 1 | 1 | 1 | 1 | 0 | |||||
| 12 | L | Л | ) | 0 | 1 | 0 | 0 | 1 | |||||
| 13 | M | М | . | 0 | 0 | 1 | 1 | 1 | |||||
| 14 | N | Н | , | 0 | 0 | 1 | 1 | 0 | |||||
| 15 | O | О | 9 | 0 | 0 | 0 | 1 | 1 | |||||
| 16 | P | П | 0 | 0 | 1 | 1 | 0 | 1 | |||||
| 17 | Q | Я | 1 | 1 | 1 | 1 | 0 | 1 | |||||
| 18 | R | Р | 4 | 0 | 1 | 0 | 1 | 0 | |||||
| 19 | S | С | ‘ | 1 | 0 | 1 | 0 | 0 | |||||
| 20 | T | Т | 5 | 0 | 0 | 0 | 0 | 1 | |||||
| 21 | U | У | 7 | 1 | 1 | 1 | 0 | 0 | |||||
| 22 | V | Ж | = | 0 | 1 | 1 | 1 | 1 | |||||
| 23 | W | В | 2 | 1 | 1 | 0 | 0 | 1 | |||||
| 24 | X | Ь | / | 1 | 0 | 1 | 1 | 1 | |||||
| 25 | Y | Ы | 6 | 1 | 0 | 1 | 0 | 1 | |||||
| 26 | Z | З | + | 1 | 0 | 0 | 0 | 1 | |||||
| 27 | Возврат каретки (ВК) | 0 | 0 | 0 | 1 | 0 | |||||||
| 28 | Перевод строки (ПС) | 0 | 1 | 0 | 0 | 0 | |||||||
| 29 | Лат. рег. | 1 | 1 | 1 | 1 | 1 | |||||||
| 30 | Цифр. рег. | 1 | 1 | 0 | 1 | 1 | |||||||
| 31 | Пробел | 0 | 0 | 1 | 0 | 0 | |||||||
| 32 | Рус. рег. | 0 | 0 | 0 | 0 | 0 | |||||||
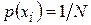 , где
, где 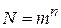 и n - целое число. На практике, как правило, знаки сообщения не равновероятны. Поэтому равномерные коды имеют скорость всегда ниже максимально возможной.
и n - целое число. На практике, как правило, знаки сообщения не равновероятны. Поэтому равномерные коды имеют скорость всегда ниже максимально возможной.Рис.№1.2
 |
На основе американского стандартного кода ASCII в качестве международного телеграфного кода рекомендован семизначный код МТК№5, который имеет 128 кодовых комбинаций, что обеспечивает представление в алфавите знаков управления и препинания, цифр, больших и малых букв. Код относится к разряду безрегистровых, т.е. за каждой кодовой комбинацией закрепляется лишь один символ алфавита.
|
| а7 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | |||
| а6 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | ||||
| а5 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | ||||
| а4 | а3 | а2 | а1 | № | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 0 | 0 | 0 | 0 | 0 | NUL | DLE | SP | 0 | 3) | P | 4) | p |
| 0 | 0 | 0 | 1 | 1 | SON | DC1 | ! | 1 | A | Q | a | q |
| 0 | 0 | 1 | 0 | 2 | STX | DC2 | “6) | 2 | B | R | b | r |
| 0 | 0 | 1 | 1 | 3 | ETX | DC3 | @2) | 3 | C | S | c | s |
| 0 | 1 | 0 | 0 | 4 | EOT | DC4 | $2) | 4 | D | T | d | t |
| 0 | 1 | 0 | 1 | 5 | ENQ | NAK | % | 5 | E | U | e | u |
| 0 | 1 | 1 | 0 | 6 | ACK | SYN | & | 6 | F | V | f | v |
| 0 | 1 | 1 | 1 | 7 | BEL | ETB | ‘6) | 7 | G | W | g | w |
| 1 | 0 | 0 | 0 | 8 | BS | CAN | ( | 8 | H | X | h | x |
| 1 | 0 | 0 | 1 | 9 | NT | EM | ) | 9 | I | Y | i | y |
| 1 | 0 | 1 | 0 | 10 | LF1) | SUB | * | : | J | Z | j | z |
| 1 | 0 | 1 | 1 | 11 | VT1) | ESC | + | ; | K | k | 3) | |
| 1 | 1 | 0 | 0 | 12 | FF1) | ES | ,6) | < | L | l | 3) | |
| 1 | 1 | 0 | 1 | 13 | CR1) | GS | - | = | M | m | 3) | |
| 1 | 1 | 1 | 0 | 14 | SO | RS | . | > | N | ^4) | n | ~4) |
| 1 | 1 | 1 | 1 | 15 | SI | US | / | ? | O | - | o | DEL |
Рис. № 1.3. Код ASCII
Код Грея относится к классу невзвешенных кодов, в нем не присваивается постоянного веса отдельным разрядам, симметричность комбинаций в кодовой таблице проявляется совпадением элементов части разрядов. Комбинации кода рис.№1.4 получены по следующему правилу: кодовая комбинация натурального двоичного кода (НДК) складывается по модулю 2 с такой же комбинацией, сдвинутой на один разряд вправо, при этом младший разряд сдвинутой комбинации отбрасывается.
|
|
| Десятичное число | НДК | Код Грея |
| 0 | 0000 | 0000 |
| 1 | 0001 | 0001 |
| 2 | 0010 | 0011 |
| 3 | 0011 | 0010 |
| 4 | 0100 | 0110 |
| 5 | 0101 | 0111 |
| 6 | 0110 | 0101 |
| 7 | 0111 | 0100 |
| 8 | 1000 | 1100 |
| 9 | 1001 | 1101 |
| 10 | 1010 | 1111 |
| 11 | 1011 | 1110 |
| 12 | 1100 | 1010 |
| 13 | 1101 | 1011 |
| 14 | 1110 | 1001 |
| 15 | 1111 | 1000 |
Преобразование необходимо начинать со стороны старших разрядов. Первая единица с этой стороны остаётся без изменения и становится единицей старшего разряда формируемого двоичного числа. Последующие цифры кода Грея будут переходить в двоичное число тоже без изменений в случае, если в исходном числе слева от переводимой цифры имеется чётное число символов «единица», если число единиц нечётно, то переводимая цифра инвертируется, при этом при подсчёте единиц разряд, содержащий переводимую цифру не учитывается.
Рассмотренный код Грея выгодно использовать в преобразователях геометрических координат, поскольку тогда в ходе считывания цифрового эквивалента аналоговой величины ошибка возникает не более чем в одном разряде.
Рис.№1.4. Код Грея
Неравномерные коды
Неравномерными кодами называют такие коды, которые содержат разное число элементов в кодовых комбинациях.
Эти коды, как и равномерные коды, с точки зрения скорости передачи информации могут оцениваться величиной информационной нагрузки на каждый символ - деля энтропию источника сообщений  на
на  , получаем информацию на один элементарный символ
, получаем информацию на один элементарный символ
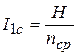 ,
,
где  - средняя длина кодовой комбинации;
- средняя длина кодовой комбинации;
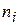 - длина комбинации, соответствующей i -му символу сообщения;
- длина комбинации, соответствующей i -му символу сообщения;
 - вероятность появления i -го символа в сообщении.
- вероятность появления i -го символа в сообщении.
Если более вероятным символам сообщения сопоставить более короткие кодовые комбинации и наоборот, то средняя длина кодовой комбинации будет меньше, т.е. скорость передачи информации таким кодом, по сравнению с равномерным, будет выше.
При построении неравномерных кодов необходимо учитывать требование однозначного декодирования сообщения, первым этапом которого является правильное определение начала и конца каждой кодовой комбинации. Этого можно достичь, если между комбинациями ставить специальные разделительные группы (комбинации начала и конца сообщения) или использовать неприводимые (префексные) коды.
Неприводимость кодов заключается в том, что в них из более длинной комбинации нельзя составить более короткие комбинации. В настоящее время разработан целый ряд неприводимых кодов.
Примером неприводимого кода может служить код, состоящий из следующих комбинация:
11, 10, 011, 001, 000, 00001, 000001
Неприводимость этого кода заключается в том, что короткие кодовые комбинация не могут быть началом более длинных кодовых комбинаций и, следовательно, любая двоичная последовательность однозначно разбивается на указанные кодовые комбинации.
Например, последовательность
1011100000110000101111101000111 - однозначно разбивается на комбинации
10, 11, 10, 00001, 10, 0001, 011, 11, 10, 10, 001, 11.
В последнее время широкое применение получил неравномерный неприводимый код построенный по следующему правилу.
|
|
Элементы сообщения записываются в виде последовательности натуральных десятичных чисел, записанных в двоичной форме, начиная с числа 2 (т.е.10):
10, 11, 100, 101, 110, 111, 1000,...
Полученные комбинации преобразуются в новые комбинации путем добавления в них нулей перед каждым нечетным элементом, начиная с третьего элемента.
Комбинации будут иметь вид
10, 11, 1000, 1001, 1100, 1101, 10000 и т.д.
Полученный таким образом код обладает свойствами:
- каждая комбинация начинается единицей;
- на нечетных позициях стоят нули.
Эти свойства делают код неприводимым и обеспечивают простоту декодирования.
Неравномерный код Морзе имеет два варианта: кабельный двоичный код, в котором символы обозначаются двоичными двухэлементными комбинациями точка - 11, тире - 00, пробел между знаками - 10, в коде одинаковая длительность точек, тире и пробелов между знаками, пробел между словами имеет втрое большую длительность, внутрикомбинационный раздел отсутствует; в троичном кабельном коде символы +1,0,-1 обозначают точку, тире и пробел соответственно (рис. № 1.1. Код Морзе).
| Рус.буквы | Лат.буквы | Код Морзе | Рус.буквы | Лат.букв | Код Морзе |
| А | A | .- | Х | H | …. |
| Б | B | -… | Ц | C | -.-. |
| В | W | .-- | Ч | - | ---. |
| Г | G | --. | Ш | - | ---- |
| Д | D | -.. | Щ | Q | --.- |
| Е | E | . | Ы | Y | -.-- |
| Ж | V | …- | Ь,Ъ | X | -..- |
| З | Z | --.. | Э | - | ..-.. |
| И | I | .. | Ю | - | ..-- |
| Й | J | .--- | Я | - | .-.- |
| К | K | -.- | Цифры | Код Морзе | |
| Л | L | .-.. | 1 | .---- | |
| М | M | -- | 2 | ..--- | |
| Н | N | -. | 3 | …-- | |
| О | O | --- | 4 | ….- | |
| П | P | .--. | 5 | ….. | |
| Р | R | .-. | 6 | -…. | |
| С | S | … | 7 | --… | |
| Т | T | - | 8 | ---.. | |
| У | U | ..- | 9 | ----. | |
| Ф | F | ..-. | 0 | ----- | |
Рис.№1.1. Код Морзе
Словарное сжатие.
Словарный компрессор добивается сжатия заменой группы последовательных символов (фраз) индексами некоторого словаря. Словарь есть список таких фраз, которые, как ожидается, будут часто использоваться. Индексы устроены так, что в среднем они занимают места меньше, чем кодируемые ими фразы, за счет чего и достигается сжатие. Главное достоинство словарных методов заключается не в степени сжатия, а в экономии машинных ресурсов.
Большинство практических словарных кодировщиков реализует алгоритмы, имеющие в своей основе подход, предложенный Лемпелом и Зивом (Lempel, Ziv). Сжатие Лемпела-Зива (LZ-сжатие) осуществляет преобразование блоков данных переменного размера в кодовые слова постоянной длины, когда статистика и вид фраз заранее неизвестны (адаптивное словарное кодирование).
|
|
Сущность LZ-сжатия состоит в том, что фразы сжимаемого сообщения заменяются указателями на те места, где эти фразы можно взять. Конкретизация сказанного нашла отражение в двух вариантах:
1. Кодируемые строки (фразы) заменяются указателями на строки, расположенные в скользящем окне фиксированной длины, хранящем предыдущий текст сообщения. Указатель содержит информацию о расположении строки в окне и ее длине. Этот вариант реализован в алгоритме LZ77.
2. Кодируемые строки заменяются указателями на список уже закодированных строк, хранящихся в словаре кодера. Этот вариант представлен в алгоритме LZ78.
Раскодирование сжатого текста осуществляется напрямую - происходит просто замена указателя той готовой фразой, на которую он указывает.
Широкое применение алгоритмов LZ-сжатия объясняется простатой реализации на современной электронной базе, высоким коэффициентом сжатия, большим разнообразием алгоритмов. Теоретически коэффициент сжатия LZ77 больше, чем LZ78, но реализуется алгоритм LZ77 медленнее. Средства, на основе которых выполняется алгоритм LZ77, асимметричны. Кодер достаточно сложен и выполняет большое количество операций. При этом основные ресурсы тратятся на поиск повторов кодируемой строки в скользящем окне просмотра. Декодер же прост в реализации и может работать с большой скоростью. Алгоритм LZ77 используется тогда, когда сообщение сжимается один раз, а восстанавливается неоднократно.
Алгоритмы LZ-сжатия
LZ77 - это была первая опубликованная версия LZ-сжатия. Алгоритм LZ77 в качестве модели данных использует скользящее по сообщению окно размером в N символов, разделенное на две неравные части. Первая (словарь) в (N - K символов, и большая по размеру (несколько килобайтов), включает часть (строку) уже просмотренного и закодированного сообщения. Вторая, намного меньшая, размером К символов выступает в качестве буфера и содержит еще незакодированные символы (К символов) входного потока. Обычно К имеет размер не более 100 байт.
Осуществляется поиск в словаре самой длинной подстроки, совпадающей с началом (фрагментом) содержимого буфера. Найденное соответствие представляется триадой (i, j, а). В этой триаде i - смещение найденной подстроки от начала буфера, j - длина кодируемого фрагмента, а - символ буфера, расположенный на (j +1)-й позиции, т. е. первый несовпадающий символ, следующий за окончанием кодируемого фрагмента (рис. 4.6). После кодирования окно сдвигается вправо на j +1 символ, втягивая j +1 очередных символов сообщения.
Если на очередном шаге совпадение не обнаружено, алгоритм выдает код (0, 0, первый символ в буфере) и продолжает свою работу. Хотя такое решение неэффективно, оно гарантирует, что алгоритм сможет закодировать любое сообщение.
Недостатки алгоритма LZ77 связаны с проблемой быстродействия, обусловленной необходимостью поиска совпадающей подстроки в словаре. Вторая проблема возникает тогда, когда такого совпадения не находится, и кодер кодирует уже приведенную выше триаду. В этом случае будет иметь место не сжатие, а, наоборот, расширение, что снижает эффективность алгоритма.
|
|

Рис.4.6 Кодирование по алгоритму LZ 77
LZ78 уходит от идеи скользящего по сообщению окна. В отличие от LZ77 в LZ78 словарем является потенциально бесконечный список уже просмотренных фраз, на которые разбивается сжимаемый текст. Текст разбивается на фразы, где каждая новая фраза есть самая длинная из уже просмотренных фраз плюс один символ. Код фразы содержит номер (индекс) фразы плюс значение добавленного символа. Такая фраза присоединяется к списку фраз, на который можно ссылаться при последующем кодировании.
Например, строка сссbbсbссbсссbсb, как показано на рис. 4.7, делится на семь фраз. Каждая из них кодируется как уже встречавшаяся фраза плюс, текущий символ. Например, последние три символа bсb представляются как фраза № 4 bc, за которой следует символ b. Таким образом, запись (i, а) обозначает копирование фразы i перед символом а.
По мере выполнения кодирования происходит накопление фраз, т. е. увеличение словаря и необходимой для его хранения памяти. При заполнении доступной памяти она очищается, и процедура начинается как бы заново с пустым словарем.
| Вход | c | cc | b | bc | bcc | bccc | bcb |
| Номер фазы | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| Выход | (0, c) | (1, c) | (0, b) | (3, c) | (4, c) | (5, c) | (4, b) |
Рис. 4.7 Кодирование по алгоритму LZ78
Сжатие с потерями.
Стандарт MPEG
История создания стандарта MPEG начинается с 1988 года, когда Совместным Техническим Комитетом по Информационной технологии (JTSI) была организована специальная группа MPEG (Motion Pictгme Experls Group - экспертная группа по движущимся изображениям). Перед MPEG была поставлена задача разработки методов сжатия и восстановления цифрового видеосигнала в рамках стандарта, объединяющего потоки видео-, аудио- и иной цифровой информации. Результатом работы MPEG явилось создание международных стандартов для сжатия телевизионного сигнала: MPEG-1, MPEG-2, MPEG-3, MPEG-4. Использование стандартов MPEG позволяет движущиеся изображения обрабатывать и хранить как компьютерные данные, передавать по существующим сетям и каналам связи.
Стандарт MPEG-1 (1992 г.) предназначен для записи видеоданных на компакт-диски и передачи изображения ТВ по сравнительно низкоскоростным (1...3 Мбит/с) каналам связи. В нем используется стандарт развертки с четкостью значительно меньшей, чем в вещательном ТВ: 288 активных строк в кадре с 352 отсчетами а активной строке.
Стандарт MPEG-2 (1994 г.) является основным стандартом и обеспечивает высокую четкость вещательного ТВ: 576 активных строк в кадре и 720 отсчетов в строке. При скоростях передачи 3...10 Мбит/с MPEG-2 обеспечивает качество обычного телевизионного стандарта, а на скоростях 15...30 Мбит/с - качество ТВЧ.
Стандарт MPEG-3 рассматривался как промежуточный вариант и практического применения не получил.
Стандарт MPEG-4 предназначен для передачи видеоданных в низкоскоростных системах мультимедиа и видеоконференций по цифровым телефонным каналам. По своим характеристикам MPEG-4 уступает возможностям MPEG-1, обеспечивая еще меньшую четкость: 144 активных строки в кадре при 176 отсчетах в строке. Это позволяет снизить скорость цифрового потока до 64 кбит/с.
MPEG-2.
Алгоритм, положенный в основу MPEG-2, включает определенный базовый набор последовательных процедур обработки: дискретизацию аналоговогo видеосигнала, предварительную обработку, дискретное косинусное преобразование (ДКП), квантование, кодирование.
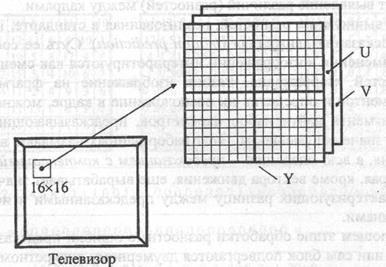 |
В качестве исходного видеосигнала для сжатия выступает компонентный ТВ сигнал RGB, который затем преобразуется в сигнал яркости Y и два цветоразностных сигнала U, V (А-Y, В-Y). Именно эти сигналы (Y, U, V) затем подвергаются дискретизации в формате 4:2:0 или 4:2:2.
После дискретизации осуществляется предварительная обработка, которая имеет целью подготовку массива отсчетов (Y, U, V) для реализации следующих операций. На этом этапе массив отсчетов изображения разбивается на последовательность фрагментов размером (16×16) элементов (пикселов). Каждый фрагмент состоит из блоков яркости (Y) и блоков цвета (U, V) (рис. 7.6). Общее количество блоков, имеющих размер (8×8) и образующих фрагмент изображения, в зависимости от формата дискретизации будет 8 или 6. Из них четыре блока - 4 (8×8) образуют макроблок (16×16) и несут информацию яркости (Y). Каждому сигналу цвета (U, V) в формате 4:2:2 соответствует по два блока (8×8), а в формате 4:2:0 - по одному блоку (8×8).
 |
Рис. 7.6. Разбивка изображения на блоки в MPEG-2 155
Основная компрессия достигается благодаря устранению избыточности ТВ сигнала. Статистическая избыточность предполагает межэлементную корреляцию как внутри кадра, так и между кадрами. В свою очередь, это обеспечивает возможность внутрикадрового и межкадрового предсказания. Для того чтобы реализовать процедуру предсказания, последовательность кадров видеосигнала подразделяется на три типа: опорные, Р-, В-кадры.
Опорные кадры являются основными и предполагают внутрикадровое предсказание, что обеспечивает умеренное сжатие. Все остальные кадры сравниваются с опорными или между собой.
Р-кадры (Predicted Frames) используют межкадровое предсказание «вперед» по предшествующим I- и Р-кадрам. Степень сжатия в них в три раза больше, чем в I-кадрам. Кадры I вида служат опорными для последующих Р-, В-кадров.
В-кадры (Bidirectionally Predicted Frames) применяют для двунаправленного предсказания, т. е. относительно как предыдущих, так и последующих кадров. В-кадры имеют наибольшее сжатие.
Кадры объединяются в группы последовательных кадров. Каждая группа начинается с I-кадра и имеет в своем составе переменное число Р- и В-кадров. I-кадры кодируются (сжимаются) и соответственно декодируются без обращения к другим кадрам. Сжатие Р-, В-кадров предполагает выявление различии (разностей) между кадрами. Техника вычисления разностей, реализованная в стандарте, имеет смысл «предсказания движения» (motion prediction). Суть ее состоит в том, что изменения в изображении интерпретируются как смещение малых областей изображения. Разбив изображение на фрагменты (16×16) элементов и определив их расположение в кадре, можно для каждого фрагмента найти набор параметров, предсказывающий направление и значение смещения. Этот набор данных называют вектором движения, а всю операцию - предсказанием с компенсацией достижения, которая, кроме вектора движения, еще вырабатывает значения ошибок, характеризующих разницу между предсказанными и истинными величинами.
На следующем этапе обработки разностные ошибки предсказания блока (8×8) или сам блок подвергаются двумерному дискретному косинусному преобразованию (DCT-discrete cosine traпsform). ДКП представляет собой разновидность преобразования Фурье и так же, как оно, имеет обратное преобразование (ОДКП), что позволяет переходить от пространственного представления блока к спектральному представлению и обратно. В результате применения ДКП блок (8×8) (рис. 7.7, а) трансформируется в блок (8×8) частотных коэффициентов (см. рис. 7.7, б). Каждый коэффициент характеризует амплитуду определенной частотной составляющей. Причем низкочастотные составляющие расположены ближе к левому верхнему углу блока, а высокочастотные - справа внизу.
Другими словами, ДКП-блок можно трактовать как двумерный частотный спектр изображения в вертикальном и горизонтальном направлениях. При этом основная энергия концентрируется около низкочастотных составляющих. Амплитуды менее значимых высокочастотных составляющих, как правило, малы, поэтому их исключение почти не сказывается на качестве изображения. Таким образом, ДКП позволяет определить, какой частью информации можно безболезненно пренебречь, балансируя между качеством воспроизведения и степенью сжатия. На приеме выполняется обратное ДКП, которое преобразует массив спектральных коэффициентов в массив пространственных коэффициентов, характеризующих исходное изображение.
| ь~и%1~%~~~~.~ iвJr~iJF'L:вJ R1 JГд1Р1 JFJ'F~I и~гиаггЕг~ rr~rrrmrл иггг~гг~ ~~с~с~~~ |

Рис. 7.7. Процесс ДКП, квантования и Z-упорядочивания
Следует заметить, что само ДКП осуществляет преобразование информации без потерь и не осуществляет сжатия. Оно подготавливает данные для реализации сжатия с потерями с помощью квантования частотных коэффициентов n кодирования.
Операция квантования (округления) имеет обычный смысл замены фактических значений коэффициентов целыми числами уровней квантования (см. рис. 7.7,в). Причем с учетом высказанного отношения к высокочастотным компонентам шаг квантования обычно выбирается неравномерным - увеличивается с увеличением частоты, т. е. операция относится к разряду адаптивных. В результате количество значимых чисел резко сокращается.
Формирование последовательности квантованных коэффициентов для подачи на кодер осуществляется с помощью Z-упорядочивания (см. рис. 7.7, в), которое выстраивает коэффициенты в порядке возрастания частоты. Одновременно в последовательности коэффициентов образуются блоки, состоящие из одних нулей. Вид последовательности представлен на рис. 7.7. Здесь же изображен сжатый вид записи этой последовательности в форме повторяющихся одинаковых коэффициентов (RLE).
Тип кодирования в стандарте не определен, что допускает применение различных видов кодов. Это может быть код Хаффмена, арифметический код. Дополнительная компрессия достигается отдельным кодированием больших блоков нулей. Кодер МРЕG-2 должен иметь многокадровый буфер (память), в котором происходит накопление данных до их использования. Поскольку канал связи функционирует с постоянной скоростью, то буфер позволяет устранить флюктуации скорости источника.
Звуковая часть стандарта MPEG-2 регламентирует кодирование многоканального звука. Стандарт поддерживает до 5 полных широкополосных каналов плюс дополнительный низкочастотный канал и (или) до семи многоязычных комментаторских каналов. Общепринятым эталоном высшего качества звука считается качество звука, воспроизводимого с компакт-дисков. Это качество принято и для стандарта MPEG-2, и достигается оно с помощью системы компрессии цифрового сигнала звука MUSICAM. Для двухканального стереофонического сопровождения скорость цифрового потока составляет 256 кбит/с (по 128 кбит/с на моноканал).
Перед подачей в канал связи сигнал транспортного потока подвергается дополнительному помехоустойчивому кодированию и модуляции. Эти операции не входят в стандарт МРЕG. В частности, в стандарте DVB применяется каскадное помехоустойчивое кодирование: внешний код - код Рида - Соломона (204, 188), внутренний код - сверточный с относительной скоростью 1/2, 2/3, 3/4, 5/б, 7/8. Модуляция осуществляется по методу ФМ-4.
Алгоритм JPEG
JPEG - один из самых новых и достаточно мощных алгоритмов. Практически он является стандартом де-факто для полноцветных изображений. Оперирует алгоритм областями 8×8, на которых яркость и цвет меняются сравнительно плавно. Вследствие этого, при разложении матрицы такой области в двойной ряд по косинусам значимыми оказываются только первые коэффициенты. Таким образом, сжатие в JPEG осуществляется за счет плавности изменения цветов в изображении.
Алгоритм разработан группой экспертов в области фотографии специально для сжатия 24-битных изображений. JPEG - Joint Photographic Expert Group - подразделение в рамках ISO - Международной организации по стандартизации. В целом алгоритм основан на дискретном косинусоидальном преобразовании (в дальнейшем ДКП), применяемом к матрице изображения для получения некоторой новой матрицы коэффициентов.
Метод позволяет сжимать некоторые изображения в 10-15 раз без серьезных потерь.

Фрактальный алгоритм
Фрактальная архивация основана на том, что мы представляем изображение в более компактной форме - с помощью коэффициентов системы итерируемых функций (Iterated Function System - IFS).
 Строго говоря, IFS представляет собой набор трехмерных аффинных преобразований, в нашем случае переводящих одно изображение в другое. Преобразованию подвергаются точки в трехмерном пространстве (х-координата, у-координата, яркость).
Строго говоря, IFS представляет собой набор трехмерных аффинных преобразований, в нашем случае переводящих одно изображение в другое. Преобразованию подвергаются точки в трехмерном пространстве (х-координата, у-координата, яркость).
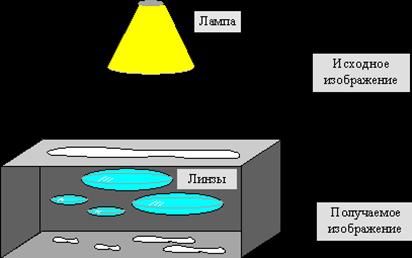
Наиболее наглядно этот процесс продемонстрировал Барнсли в своей книге «Fractal Image Compression». Там введено понятие Фотокопировальной Машины, состоящей из экрана, на котором изображена исходная картинка, и системы линз, проецирующих изображение на другой экран.
Линзы могут проецировать часть изображения произвольной формы в любое другое место нового изображения. Области, в которые проецируются изображения, не пересекаются. Линза может менять яркость и уменьшать контрастность. Линза может зеркально отражать и поворачивать свой фрагмент изображения. Линза должна масштабировать (уменьшать) свой фрагмент изображения.
 Расставляя линзы и меняя их характеристики, мы можем управлять получаемым изображением. Одна итерация работы Машины заключается в том, что по исходному изображению с помощью проектирования строится новое, после чего новое берется в качестве исходного. Утверждается, что в процессе итераций мы получим изображение, которое перестанет изменяться. Оно будет зависеть только от расположения и характеристик линз, и не будет зависеть от исходной картинки. Это изображение называется «неподвижной точкой» или аттрактором данной IFS. Соответствующая теория гарантирует наличие ровно одной неподвижной точки для каждой IFS.
Расставляя линзы и меняя их характеристики, мы можем управлять получаемым изображением. Одна итерация работы Машины заключается в том, что по исходному изображению с помощью проектирования строится новое, после чего новое берется в качестве исходного. Утверждается, что в процессе итераций мы получим изображение, которое перестанет изменяться. Оно будет зависеть только от расположения и характеристик линз, и не будет зависеть от исходной картинки. Это изображение называется «неподвижной точкой» или аттрактором данной IFS. Соответствующая теория гарантирует наличие ровно одной неподвижной точки для каждой IFS.
Поскольку отображение линз является сжимающим, каждая линза в явном виде задает самоподобные области в нашем изображении. Благодаря самоподобию мы получаем сложную структуру изображения при любом увеличении. Таким образом, интуитивно понятно, что система итерируемых функций задает фрактал (нестрого - самоподобный математический объект).
Наиболее известны два изображения, полученных с помощью IFS: «треугольник Серпинского» и «папоротник Барнсли». «Треугольник Серпинского» задается тремя, а «папоротник Барнсли» четырьмя аффинными преобразованиями (или, в нашей терминологии, «линзами»). Каждое преобразование кодируется буквально считанными байтами, в то время как изображение, построенное с их помощью, может занимать и несколько мегабайт.
Фактически, фрактальная компрессия — это поиск самоподобных областей в изображении и определение для них параметров аффинных преобразований.
Подавляющее большинство исследований в области фрактальной компрессии сейчас направлены на уменьшение времени архивации, необходимого для получения качественного изображения.
Требования к методам цифрового кодирования
При использовании прямоугольных импульсов для передачи дискретной информации необходимо выбрать такой способ кодирования, который одновременно достигал бы нескольких целей:
· имел при одной и той же битовой скорости наименьшую ширину спектра результирующего сигнала;
· обеспечивал синхронизацию между передатчиком и приемником;
· обладал способностью распознавать ошибки;
· обладал низкой стоимостью реализации.
Более узкий спектр сигналов позволяет на одной и той же линии (с одной и той же полосой пропускания) добиваться более высокой скорости передачи данных. Кроме того, часто к спектру сигнала предъявляется требование отсутствия постоянной составляющей, то есть наличия постоянного тока между передатчиком и приемником. В частности, применение различных трансформаторных схем гальванической развязки препятствует прохождению постоянного тока.



