Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Эффективное кодирование. Словарное сжатие. Сжатие с потерями.
Сжатие - это процесс представления информации, содержащейся в сообщении, меньшим числом символов (меньшим объемом). Характеризуя процесс сжатия (компрессии), можно сказать, что он осуществляет обработку символов сообщения и перевод этих символов в некоторые коды. Если этот процесс организован эффективно, то его результатом будет закодированное сообщение меньшего объема. Таким образом, в широком смысле сжатие - это форма кодирования, при которой объем данных уменьшается. Сжатие может быть использовано как с целью сокращения объема памяти при хранении (запоминании) информации, так и с целью сокращения временных затрат на передачу по каналам связи. И в том и в другом случаях получение исходной информации предполагает осуществление обратной операции - декомпрессии (разжимания). Эффективные алгоритмы сжатия были известны с начала 50-х годов. Традиционно существовал компромисс между преимуществами использования сжатия и вычислительными затратами на реализацию процедур компрессии и декомпрессии. С появлением дешевых микропроцессоров и специализированных микросхем сжатие быстро становится стандартной составляющей передачи и хранения данных самого различного вида. Различают сжатие без потерь и сжатие с потерями. В первом случае информация, восстановленная из сжатого состояния (после декомпрессии), в точности соответствует исходной до начала сжатия. Во втором случае информация, восстановленная после сжатия, только частично соответствует исходной. Потери при восстановлении, очевидно, могут быть допущены для сигналов речи, аудио- и видеоинформации при соответствующем снижении требований к качеству воспроизведения. Сжатие без потерь применяется для текстуальных, цифровых данных, где потеря даже одного бита информации является неприемлемой. Каждый метод сжатия имеет свои достоинства и недостатки. Естественно, что большую сжимаемость данных обеспечивает сжатие с потерями. Современные процедуры сжатия позволяют уменьшить объем передаваемых данных в 2...5 раз при использовании процедур сжатия без потерь и в десятки раз - при сжатии с потерями. Однако алгоритмы сжатия без потерь отличаются универсальностью, в то время как технологии сжатия с потерями жестко ориентированы на определенный вид сжимаемых сообщений (речь, музыка, изображение и т. д.).
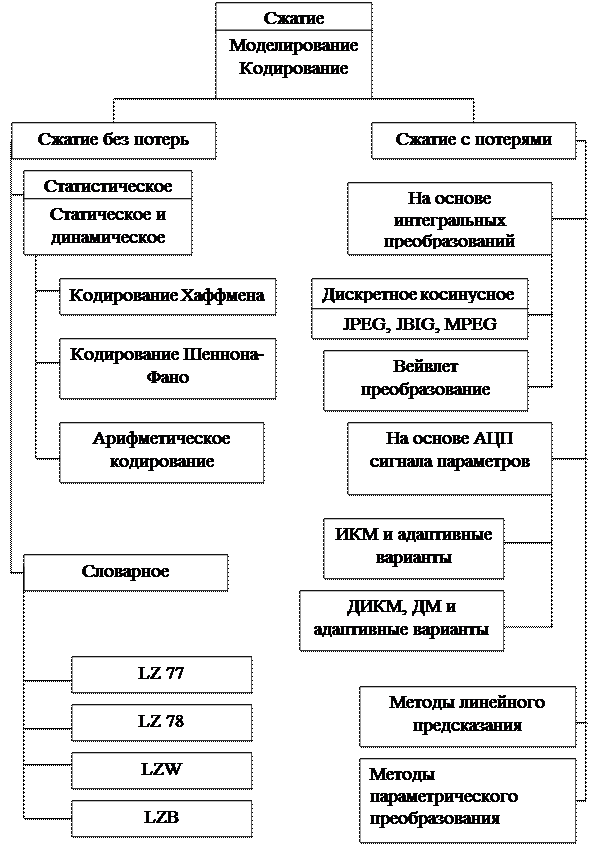
Существует два основных класса алгоритмов сжатия: статистический и словарный. В алгоритмах статистического сжатия сжимаемые данные представляются в виде последовательности отдельных символов, каждому из которых присваивается кодовая комбинация в соответствии с вероятностью выдачи его источником сообщения. В словарных алгоритмах сжатия кодируются группы символов (строк, фраз, слов). Причем каждое кодированное слово может быть найдено в некотором словаре, что позволяет при сжатии заменить его ссылкой на образец из словаря. На рис.2.1. представлена обобщенная классификация методов сжатия, которая отражает современное состояние вопроса.
Рис.2.1. Обобщенная классификация методов сжатия.
Вероятности можно оценивать синхронно с появлением символов (адаптивно) с помощью символьных счетчиков. Вначале все они устанавливаются в 1 (для избегания нулевой вероятности), а затем после кодирования символа значение соответствующего счетчика увеличивается на единицу. Аналогично, при декодировании этого символа раскодировщик увеличивает показание счетчика. Эта простая адаптивная модель также применяется с кодом Хаффмена, но адаптивного вида, о котором будет сказано ниже. Более сложный путь вычисления вероятностей символов предполагает учет предыдущих символов (контекста). Количество k учитываемых предшествующих символов для вычисления вероятности текущего символа определяет контекстно-ограниченную модель степени k. Контекстно-свободная модель имеет степень 0. Модель, где всем символам присваивается одно значение вероятности, обозначают степенью -1, как более примитивную, чем модель степени 0. На практике широко используется модель степени 4. Контекстно-ограниченные модели применяются адаптивно, что обеспечивает хорошую приспосабливаемость к конкретному виду сжимаемых данных. Оценки вероятностей в этом случае просто заменяются показаниями счетчиков, фиксирующих частоту появления символов на основе уже просмотренного сообщения. Любая сбалансированная система представляет собой сложный компромисс между временем, пространством и эффективностью сжатия. Из всех известных технологий контекстно-ограниченное моделирование обычно дает лучшее сжатие, но может быть очень медленным. Эффективное сжатие достигается на основе очень больших моделей, которые всегда забирают память больше, чем сами сжимаемые данные. Основной фактор улучшения сжатия, как показывает практика, связан с возможностью доступа к большим объемам памяти. При адаптации эта память относительно дешева для моделей, не нуждающихся в поддержке или обслуживании, так как они существуют только во время собственно сжатия, и их не надо передавать.
|
||||||
|
|
Последнее изменение этой страницы: 2020-11-11; просмотров: 118; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.117.72.224 (0.005 с.) |