
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Анализ аналогичных разработокСтр 1 из 9Следующая ⇒
Аннотация
Данный дипломный проект содержит в себе описание процесса портирования ядра операционной системы Linux, приводится аналитический обзор существующих разработок. Характеристики дипломного проекта: · Объем составляет 70 страниц. · Количество графических материалов составляет 9 листов · Количество литературных источников составляет 10 позиций. Введение
В программировании под портированием понимают адаптацию некоторой программы или её части, с тем чтобы она работала в другой среде, отличающейся от той среды, под которую она была изначально написана. Процесс портирования также называют портингом (от англ. porting), а результат - портом. Портируемость (переносимость, англ. portability) обычно относится к одной из двух вещей: 1. Портируемость - как возможность единожды откомпилировав код (обычно в некоторый промежуточный код, который затем компилируется во время исполнения, «на лету», англ. Just-In-Time), затем запускать его на множестве платформ без каких-либо изменений. 2. Портируемость - как свойство программного обеспечения, описывающее, насколько легко это ПО может быть портировано. По мере развития операционных систем, языков и техники программирования, становится всё проще портировать программы между различными платформами. Одной из изначальных целей создания языка С и стандартной библиотеки этого языка - была возможность простого портирования программ между несовместимыми аппаратными платформами. Дополнительные преимущества в плане портируемости могут иметь программы, удовлетворяющие специальным стандартам и правилам написания. Международные стандарты (в частности, продвигаемые международной организацией по стандартизации ISO) значительно упрощают портирование, благодаря тому что они описывают среду исполнения программ таким образом, что различия между платформами становятся минимальными. Часто портирование программ между платформами, реализующими один и тот же стандарт (такой как POSIX.1) сводятся к перекомпиляции программы на новой платформе. Существует также всё расширяющийся набор инструментов, облегчающих портирование, например, таких как компилятор GCC, предоставляющий неизменный язык программирования на различных платформах.
Некоторые языки программирования высокого уровня (Eiffel, Esterel) достигают портируемости путем трансляции исходного кода в промежуточный язык, имеющий компиляторы для многих процессоров и операционных систем. Специальная часть Постановка задачи
Необходимость в выполнении портирования операционной системы возникает в силу различий в наборе операций процессора, различий между интерфейсами операционной системы, различий в оборудовании, либо по причине несовместимости или даже полного отсутствия используемого языка программирования в целевом окружении. На базе ядра Linux может быть создана необходимая конфигурация операционной системы и, поэтому данная операционная система может быть использована в качестве средства для управления процессорами MIPS-архитектуры. В рамках проекта необходимо произвести портирование ядра Linux в микропроцессорную систему MIPS-архитектуры и провести тестирование полученного порта. Целью дипломного проекта является разработка порта Linux и проведение тестирования полученного порта операционной системы для конкретного микропроцессора MIPS-архитектуры, аналога MIPS64.
Обзор предметной области
Термин "архитектура системы" часто употребляется как в узком, так и в широком смысле этого слова. В узком смысле под архитектурой понимается архитектура набора команд. Архитектура набора команд служит границей между аппаратурой и программным обеспечением и представляет ту часть системы, которая видна программисту или разработчику компиляторов. Следует отметить, что это наиболее частое употребление этого термина. В широком смысле архитектура охватывает понятие организации системы, включающее такие высокоуровневые аспекты разработки компьютера как систему памяти, структуру системной шины, организацию ввода/вывода и т.п. Двумя основными архитектурами набора команд, используемыми компьютерной промышленностью на современном этапе развития вычислительной техники являются архитектуры CISC и RISC. (англ. Reduced Instruction Set Computing) - вычисления с сокращённым набором команд. Это концепция проектирования процессоров, которая во главу ставит следующий принцип: более компактные и простые инструкции выполняются быстрее. Простая архитектура позволяет удешевить процессор, поднять тактовую частоту, а также распараллелить исполнение команд между несколькими блоками исполнения (т.н. суперскалярные архитектуры процессоров). Многие ранние RISC-процессоры даже не имеют команд умножения и деления. Идея создания RISC процессоров пришла после того, как в 1970-х годах ученые из IBM обнаружили, что многие из функциональных особенностей традиционных ЦПУ игнорировались программистами. Отчасти это был побочный эффект сложности компиляторов. В то время компиляторы могли использовать лишь часть из набора команд процессора. Следующее открытие заключалось в том, что, поскольку некоторые сложные операции использовались редко, они как правило были медленнее, чем те же действия, выполняемые набором простых команд. Это происходило из-за того, что создатели процессоров тратили гораздо меньше времени на улучшение сложных команд, чем на улучшение простых.
Первые RISC-процессоры выполняли небольшой (50−100) набор команд, тогда как обычные CISC (Complex Instruction Set computer) выполняли 100-200. Характерные особенности RISC-процессоров: · Фиксированная длина машинных инструкций (например, 32 бита) и простой формат команды. · Специализированные команды для операций с памятью - чтения или записи. Операции вида «прочитать-изменить-записать» отсутствуют. Любые операции "изменить" выполняются только над содержимым регистров (т.н. load-and-store архитектура). · Большое количество регистров общего назначения (32 и более). · Отсутствие поддержки операций вида "изменить" над укороченными типами данных - байт, 16-битное слово. Так, например, система команд DEC Alpha содержала только операции над 64-битными словами, и требовала разработки и последующего вызова процедур для выполнения операций над байтами, 16- и 32-битными словами. · Отсутствие микропрограмм внутри самого процессора. То, что в CISC процессоре исполняется микропрограммами, в RISC процессоре исполняется как обыкновенный (хотя и помещенный в специальное хранилище) машинный код, не отличающийся принципиально от кода ядра ОС и приложений. Так, например, обработка отказов страниц в DEC Alpha и интерпретация таблиц страниц содержалась в так называемом PALCode (Privileged Architecture Library), помещенном в ПЗУ. Заменой PALCode можно было превратить процессор Alpha из 64битного в 32битный, а также изменить порядок байт в слове и формат входов таблиц страниц виртуальной памяти. Основой архитектуры современных рабочих станций и серверов является архитектура компьютера с сокращенным набором команд. Зачатки RISC-архитектуры уходят своими корнями к компьютерам CDC6600, разработчики которых (Торнтон, Крэй и др.) осознали важность упрощения набора команд для построения быстрых вычислительных машин. Эту традицию упрощения архитектуры С. Крэй с успехом применил при создании широко известной серии суперкомпьютеров компании Cray Research. Однако окончательно понятие RISC в современном его понимании сформировалось на базе трех исследовательских проектов компьютеров: процессора 801 компании IBM, процессора RISC университета Беркли и процессора MIPS Стенфордского университета.
Разработка экспериментального проекта компании IBM началась еще в конце 70-х годов, но его результаты никогда не публиковались и компьютер на его основе в промышленных масштабах не изготавливался. В 1980 году Д.Паттерсон со своими коллегами из Беркли начали свой проект и изготовили две машины, которые получили названия RISC-I и RISC-II. Главными идеями этих машин было отделение медленной памяти от высокоскоростных регистров и использование регистровых окон. В 1981 году Дж. Хеннесси со своими коллегами опубликовал описание стенфордской машины MIPS, основным аспектом разработки которой была эффективная реализация конвейерной обработки посредством тщательного планирования компилятором его загрузки. Эти три машины имели много общего. Все они придерживались архитектуры, отделяющей команды обработки от команд работы с памятью, и делали упор на эффективную конвейерную обработку. Система команд разрабатывалась таким образом, чтобы выполнение любой команды занимало небольшое количество машинных тактов (предпочтительно один машинный такт). Сама логика выполнения команд с целью повышения производительности ориентировалась на аппаратную, а не на микропрограммную реализацию. Чтобы упростить логику декодирования команд использовались команды фиксированной длины и фиксированного формата. Развитие архитектуры RISC в значительной степени определялось прогрессом в области создания оптимизирующих компиляторов. Именно современная техника компиляции позволяет эффективно использовать преимущества большего регистрового файла, конвейерной организации и большей скорости выполнения команд. Современные компиляторы используют также преимущества другой оптимизационной техники для повышения производительности, обычно применяемой в процессорах RISC: реализацию задержанных переходов и суперскалярной обработки, позволяющей в один и тот же момент времени выдавать на выполнение несколько команд. Первое время RISC-архитектуры с трудом принимались рынком из-за отсутствие программного обеспечения для них. Эта проблема была быстро решена переносом UNIX-подобных операционных систем на RISC архитектуры.
Иерархия памяти При разработке процессора R10000 большое внимание было уделено эффективной реализации иерархии памяти. В нем обеспечиваются раннее обнаружение промахов кэш-памяти и параллельная перезагрузка строк с выполнением другой полезной работой. Реализованные на кристалле кэши поддерживают одновременную выборку команд, выполнение команд загрузки и записи данных в память, а также операций перезагрузки строк кэш-памяти. Заполнение строк кэш-памяти выполняется по принципу "запрошенное слово первым", что позволяет существенно сократить простои процессора из-за ожидания требуемой информации. Все кэши имеют двухканальную множественно-ассоциативную организацию с алгоритмом замещения LRU.
Кэш память команд Объем внутренней двухканальной множественно-ассоциативной кэш-памяти команд составляет 32 Кбайт. В процессе ее загрузки команды частично декодируются. При этом к каждой команде добавляются 4 дополнительных бит, которые указывают исполнительное устройство, в котором она будет выполняться. Таким образом, в кэш-памяти команды хранятся в 36-битовом формате. Размер строки кэш-памяти команд составляет 64 байта. Обработка команд перехода При реализации конвейерной обработки возникают ситуации, которые препятствуют выполнению очередной команды из потока команд в предназначенном для нее такте. Такие ситуации называются конфликтами. Конфликты снижают реальную производительность конвейера, которая могла бы быть достигнута в идеальном случае. Одним из типов конфликтов, с которыми приходится иметь дело разработчикам высокопроизводительных процессоров, являются конфликты по управлению, которые возникают при конвейеризации команд перехода и других команд, изменяющих значение счетчика команд. Конфликты по управлению могут вызывать даже большие потери производительности суперскалярного процессора, чем конфликты по данным. По статистике среди команд управления, меняющих значение счетчика команд, преобладают команды условного перехода. Таким образом, снижение потерь от условных переходов становится критически важным вопросом. Имеется несколько методов сокращения приостановок конвейера, возникающих из-за задержек выполнения условных переходов. В процессоре R10000 используются два наиболее мощных метода динамической оптимизации выполнения условных переходов: аппаратное прогнозирование направления условных переходов и "выполнение по предположению" (speculation). Устройство переходов процессора R10000 может декодировать и выполнять только по одной команде перехода в каждом такте. Поскольку за каждой командой перехода следует слот задержки, максимально могут быть одновременно выбраны две команды перехода, но только одна более ранняя команда перехода может декодироваться в данный момент времени. Во время декодирования команд к каждой команде добавляется бит признака перехода. Эти биты используются для пометки команд перехода в конвейере выборки команд. Направление условного перехода прогнозируется с помощью специальной памяти (branch history table) емкостью 512 строк, которая хранит историю выполнения переходов в прошлом. Обращение к этой таблице осуществляется с помощью адреса команды во время ее выборки. Двухбитовый код прогноза в этой памяти обновляется каждый раз, когда принято окончательное решение о направлении перехода. Моделирование показало, что точность двухбитовой схемы прогнозирования для тестового пакета программ SPEC составляет 87%.
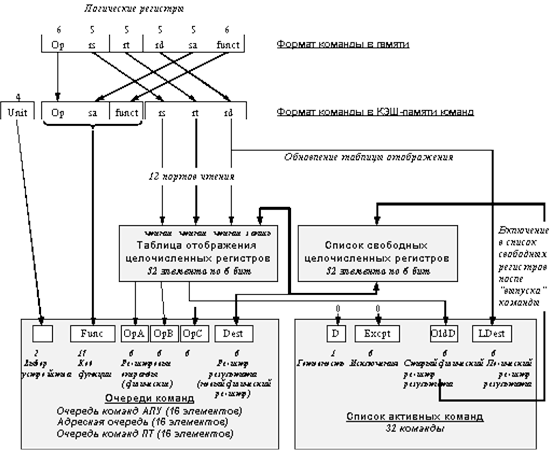
Все команды, выбранные вслед за командой условного перехода, считаются выполняемыми по предположению (условно). Это означает, что в момент их выборки заранее не известно, будет ли завершено их выполнение. Процессор допускает предварительную обработку и прогнозирование направления четырех команд условного перехода, которые могут разрешаться в произвольном порядке. При этом для каждой выполняемой по предположению команды условного перехода в специальный стек переходов записывается информация, необходимая для восстановления состояния процессора в случае, если направление перехода было предсказано неверно. Стек переходов имеет глубину в 4 элемента и позволяет в случае необходимости быстро и эффективно (за один такт) восстановить конвейер. Структура очередей команд Процессор R10000 содержит три очереди (буфера) команд (очередь целочисленных команд, очередь команд плавающей точки и адресную очередь). Эти три очереди осуществляют динамическую выдачу команд в соответствующие исполнительные устройства. С каждой командой в очереди хранится тег команды, который перемещается вместе с командой по ступеням конвейера. Каждая очередь осуществляет динамическое планирование потока команд и может определить моменты времени, когда становятся доступными операнды, необходимые для выполнения каждой команды. Кроме того, очередь определяет порядок выполнения команд на основе анализа состояния соответствующих исполнительных устройств. Как только ресурс оказывается свободным очередь выдает команду в соответствующее исполнительное устройство. Адресная очередь Очередь адресных команд выдает команды в устройство загрузки/записи и содержит 16 строк. Очередь организована в виде циклического буфера FIFO (first-in first-out). Команды могут выдаваться в произвольном порядке, но должны записываться в очередь и изыматься из нее строго последовательно. В каждом такте в очередь могут поступать до 4 команд. Буфер FIFO поддерживает первоначальную последовательность команд, что упрощает обнаружение зависимостей по адресам. Выполнение выданной команды может не закончиться при обнаружении зависимости по адресам, кэш-промаха или конфликта по ресурсам. В этих случаях адресная очередь должна заново повторять выдачу команды до тех пор, пока ее выполнение не завершится. Переименование регистров Одним из аппаратных методов минимизации конфликтов по данным является метод переименования регистров (register renaming). Он получил свое название от широко применяющегося в компиляторах метода переименования - метода размещения данных, способствующего сокращению числа зависимостей и тем самым увеличению производительности при отображении необходимых исходной программе объектов (например, переменных) на аппаратные ресурсы (например, ячейки памяти и регистры). При аппаратной реализации метода переименования регистров выделяются логические регистры, обращение к которым выполняется с помощью соответствующих полей команды, и физические регистры, которые размещаются в аппаратном регистровом файле процессора. Номера логических регистров динамически отображаются на номера физических регистров посредством таблиц отображения, которые обновляются после декодирования каждой команды. Каждый новый результат записывается в новый физический регистр. Однако предыдущее значение каждого логического регистра сохраняется и может быть восстановлено в случае, если выполнение команды должно быть прервано из-за возникновения исключительной ситуации или неправильного предсказания направления условного перехода. В процессе выполнения программы генерируется множество временных регистровых результатов. Эти временные значения записываются в регистровые файлы вместе с постоянными значениями. Временное значение становится новым постоянным значением, когда завершается выполнение команды (фиксируется ее результат). В свою очередь, завершение выполнения команды происходит когда все предыдущие команды успешно завершились в заданном программой порядке. Программист (или компилятор) имеет дело только с логическими регистрами. Реализация физических регистров от него скрыта. Таким образом, аппаратный метод переименования регистров, используемый в процессоре R10000, имеет три основных достоинства. Во-первых, результаты "выполняемых по предположению" команд могут прямо записываться в регистровый файл. Во-вторых, этот метод устраняет все конфликты типа "запись после чтения" и "запись после записи", которые часто возникают при неупорядоченном выполнении команд. И, наконец, метод переименования регистров упрощает контроль зависимостей по данным. Поскольку процессор обеспечивает выдачу для выполнения до четырех команд в каждом такте, в процессе переименования регистров их логические номера сравниваются для определения зависимостей между четырьмя командами, декодированными в одном и том же такте. Реализованная в микропроцессоре R10000 схема отображения команд состоит из двух таблиц отображения, списка активных команд и двух списков свободных регистров (для целочисленных команд и команд плавающей точки имеются отдельные таблицы отображения и списки свободных регистров). Чтобы поддерживать последовательный порядок завершения выполнения команд, существует только один список активных команд, который содержит как целочисленные команды, так и команды плавающей точки. Микропроцессор R10000 содержит по 64 физических регистра (целочисленных и плавающей точки). В любой момент времени значение физического регистра содержится в одном из указанных выше списков. На Рис. 3 показана упрощенная блок-схема отображения целочисленных команд. Команды выбираются из кэша команд и помещаются в таблицу отображения. В любой момент времени каждый из 64 номеров физических регистров находится в одном из трех указанных на рисунке блоков. Список активных команд длиною 32 элемента может хранить упорядоченную в соответствии с программой последовательность команд, которые могут находиться в обработке в любой данный момент времени. Команды из очереди целочисленных команд могут выполняться неупорядочено и записывать результаты в физические регистры, но порядок их окончательного завершения определяется списком активных команд.
Рис. 3. Упрощенная блок-схема отображения целочисленных команд
Каждая команда может уникально идентифицироваться своим положением в списке активных команд. Поэтому каждую команду в очереди и в соответствующем исполнительном устройстве сопровождает 5-битовая метка, называемая тегом команды. Этот тег и определяет положение команды в списке активных команд. Когда в исполнительном устройстве заканчивается выполнение команды, тег позволяет очень просто ее отыскать в списке активных команд и пометить как выполненную. Когда результат операции из исполнительного устройства записывается в физический регистр, номер этого физического регистра становится больше не нужным и может быть затем возвращен в список свободных регистров, а соответствующая команда перестает быть активной. Когда в процессе переименования из списка свободных регистров выбирается очередной номер физического регистра, он передается в таблицу отображения, которая обновляется. При этом старый номер регистра, соответствующий определенному в команде логическому регистру результата, помещается из таблицы отображения в список активных команд. Этот номер остается в списке активных команд до тех пор, пока соответствующая команда не "выпустится" (graduate), т.е. завершится в заданном программой порядке. Команда может "выпуститься" только после того, как успешно завершится выполнение всех предыдущих команд. Микропроцессор R10000 содержит 64 физических и 32 логических целочисленных регистра. Список активных команд может содержать максимально 32 элемента. Список свободных регистров также может максимально содержать 32 значения. Если список активных команд полон, то могут быть 32 "зафиксированных" и 32 временных значения. Отсюда потребность в 64 регистрах. Исполнительные устройства В процессоре R10000 имеются пять полностью независимых исполнительных устройств: два целочисленных АЛУ, два основных устройства плавающей точки с двумя вторичными устройствами плавающей точки, которые работают с длинными операциями деления и вычисления квадратного корня, а также устройство загрузки/записи. Целочисленный АЛУ В микропроцессоре R10000 имеются два целочисленных АЛУ: АЛУ1 и АЛУ2. Время выполнения всех целочисленных операций АЛУ (за исключением операций умножения и деления) и частота повторений составляют один такт. Оба АЛУ выполняют стандартные операции сложения, вычитания и логические операции. Эти операции завершаются за один такт. АЛУ1 обрабатывает все команды перехода, а также операции сдвига, а АЛУ2 - все операции умножения и деления с использованием итерационных алгоритмов. Целочисленные операции умножения и деления помещают свои результаты в регистры EntryHi и EntryLo. Во время выполнения операций умножения в АЛУ2 могут выполняться другие однотактные команды, но сам умножитель оказывается занятым. Однако когда умножитель заканчивает свою работу, АЛУ2 оказывается занятым на два такта, чтобы обеспечить запись результата в два регистра. Во время выполнения операций деления, которые имеют очень большую задержку, АЛУ2 занято на все время выполнения операции. Целочисленные операции умножения вырабатывают произведение с двойной точностью. Для операций с одинарной точностью происходит распространение знака результата до 64 бит прежде, чем он будет помещен в регистры EntryHi и EntryLo. Время выполнения операций с двойной точностью примерно в два раза превосходит время выполнения операций с одинарной точностью. Устройства плавающей точки В микропроцессоре R10000 реализованы два основных устройства плавающей точки. Устройство сложения обрабатывает операции сложения, а устройство умножения - операции умножения. Кроме того, существуют два вторичных устройства плавающей точки, которые обрабатывают длинные операции деления и вычисления квадратного корня. Время выполнения команд сложения, вычитания и преобразования типов равно двум тактам, а скорость их поступления в устройство составляет 1 команда/такт. Эти команды обрабатываются в устройстве сложения. Команды преобразования целочисленных значений в значения с плавающей точкой с однократной точностью имеют задержку в 4 такта, поскольку они должны пройти через устройство сложения дважды. В устройстве умножения обрабатываются все операции умножения с плавающей точкой. Время их выполнения составляет два такта, а скорость поступления - 1 команда/такт. Устройства деления и вычисления квадратного корня выполняют операции с использованием итерационных алгоритмов. Эти устройства не конвейеризованы и не могут начать выполнение следующей операции до тех пор, пока не завершилось выполнение текущей команды. Таким образом, скорость повторения этих операций примерно равна задержке их выполнения. Порты умножителя являются общими и для устройств деления и вычисления квадратного корня. В начале и в конце операции теряется по одному такту (для выборки операндов и для записи результата). Операция с плавающей точкой "умножить-сложить", которая в вычислительных программах возникает достаточно часто, выполняется с использованием двух отдельных операций: операции умножения и операции сложения. Команда "умножить-сложить" (MADD) имеет задержку 4 такта и скорость повторения 1 команда/ такт. Эта составная команда увеличивает производительность за счет устранения выборки и декодирования дополнительной команды. Устройства деления и вычисления квадратного корня используют раздельные цепи и могут работать одновременно. Однако очередь команд плавающей точки не может выдать для выполнения обе команды в одном и том же такте. Системный интерфейс Системный интерфейс процессора R10000 работает в качестве шлюза между самим процессором, связанным с ним кэшем второго уровня и остальной системой. Системный интерфейс работает с тактовой частотой внешней синхронизации (SysClk). Возможно программирование работы системного интерфейса на тактовой частоте 200, 133, 100, 80, 67, 57 и 50 МГц. Все выходы и входы системного интерфейса синхронизируются нарастающим фронтом сигнала SysClk, позволяя ему работать на максимально возможной тактовой частоте. В большинстве микропроцессорных систем в каждый момент времени может происходить только одна системная транзакция. Процессор R10000 поддерживает протокол расщепления транзакций, позволяющий осуществлять выдачу очередных запросов процессором или внешним абонентом шины, не дожидаясь ответа на предыдущий запрос. Максимально в любой момент времени поддерживается до четырех одновременных транзакций на шине. Разработка
Ядро операционной системы имеет некоторые специфические особенности в сравнении с программами, которые выполняются в пространстве пользователя. Вот некоторые из них: · Ядро не имеет доступа к стандартным библиотекам языка C. Причина этого - скорость выполнения и объем кода. Даже самая необходимая часть библиотеки - очень большая и неэффективная для ядра. Часть функций, однако, реализованы в ядре. Например, обычные функции работы со строками описаны в файле lib/string.c. · Отсутствие защиты памяти. Если обычная программа предпринимает попытку некорректного обращения к памяти, ядро может аварийно завершить процесс. Если ядро предпримет попытку некорректного обращения к памяти, результаты могут быть менее контролируемыми. К тому же ядро не использует замещение страниц: каждый байт, используемый в ядре - это один байт физической памяти. · В ядре нельзя использовать вычисления с плавающей точкой. Активизация режима вычислений с плавающей точкой требует сохранения и проставления регистров устройства поддержки вычислений с плавающей точкой, помимо других рутинных операций. · Фиксированный стек. Стеком называют область адресного пространства, в которой выделяются локальные переменные. Локальные переменные - это все переменные, объявленные внутри левой открывающей фигурной скобки тела функции (или любой другой левой фигурной скобки) и не имеющие ключевого слова static. Стек в режиме ядра ни большой, ни изменяющийся. Поэтому в коде ядра не рекомендуется использоватьрекурсию. Обычно стек равен двум страницам памяти, что соответствует 8 Кбайт для 32-разрядных систем и 16 Кбайт для 64 -разрядных. · Переносимость. Платформо-независимый код, написанный на языке C, должен компилироваться без ошибок на максимально возможном количестве систем. Perl -эмулятор Отличительными особенностями MIPS 64 реализации фирмы KEDAH являются:
· Отсутствие операций с плавающей точкой (программная эмуляция FPU математического сопроцессора). · TLB - 32 входное · Раздельный кэш данных и кэш команд - по 32 КБайт · Шина адреса - 32-разрядная Руководствуясь задачами применения разработанного процессора, в эмуляторе были реализованы только следующие основные регистры: В силу особенностей реализации процессора фирмой KEDAH, в качестве средства кросс-отладки операционной системы использовался собственный эмулятор kem-2.0.2, написанный на языке Perl. Использование эмулятора позволяет провести отладку выполнения программ до физической реализации микропроцессорной системы, что является менее трудоемким и сокращает финансовые затраты на предварительную аппаратную реализаци. В эмулятор заложены возможности: · просмотра памяти · установки точек остановок в ходе отладки · пошагового выполнения команд · просмотра содержимого регистров процессора в интерактивном режиме.
Вывод в порт Следующим шагом отладки был запуск программы «Hello, world!». Для получения сообщений в ходе отладки ядра в драйвер консоли был включен модуль printf для вывода сообщений в последовательный порт. Результатом послужил успешный запуск на эмуляторе kem-2.0.2 программы «Hello, World!» Сборка ядра Процесс сборки ядра состоял из следующих этапов: 1) Приобретение исходников ядра. Исходный код ядра версии 2.6.28 с http://www.kernel.org/pub. Данная версия ядра поддерживает интересующую нас архитектуру MIPS64. После получения исходных кодов ядра в архиве linux-2.6.28.tar.bz2, его нужно распаковать (обычно распаковывают в каталог /usr/src/) с помощью утилиты tar от имени суперпользователя. 2) Подготовка каталогов с исходниками ядра. Дерево исходных кодов ядра содержит подкаталоги, описание которых приведено в Табл. 1. В корне дерева также содержится ряд файлов: COPYING - лицензия, CREDITS - список основных разработчиков, MAINTAINERS - список разработчиков, занимающихся поддержкой подсистем и драйверов ядра, Makefile - основной сборочный файл ядра. Таблица 1
3) Конфигурирование ядра (config.mips64r2): 4) Сборка ядра осуществляется командой make. Ускорить процесс можно, запустив команду make -j2. Параметр -j2 означает запуск двух потоков выполнения (обычно используют два потока на процессор): # make -j 2 ARCH=mips CROSS_COMPILE=mipsel-linux- menuconfig Сборка ядра: # make -j 2 ARCH=mips CROSS_COMPILE=mipsel-linux- vmlinux.bin 5) Компиляция ядра и установка модулей: Также загружен патч с кросс-компилятором MIPS (http://linux-mips.org, mipsel-sdelinux-v6.05.00-4.i386.rpm) Получение патча. Все изменения исходного кода ядра распространяются в виде заплат (patch). Заплаты - это результат вывода утилиты diff в формате, который подается на вход утилиты patch. # diff -uprN -X linux-2.6.28.orig/Documentation/dontdiff linux-2.6.28.orig linux-2.6.28.dev > linux-2.6.28-kem-mips64r2.le.001.patch 6) Перемещение ядра Перенос ядра в рабочую директорию: # mv ~/vmlinux.bin./vmlinux.kem.mips64.r2.le.001.bin Доступ к серверу: # ssh alexey@verilog.ru (xxxxxx) # ssh server (xxxxxx) # cd project ng 7) Копирование ядра на удаленный сервер с эмулятором kem: # scp arch/mips/boot/vmlinux.bin renatn@verilog.ru: 8) Запуск эмулятора # perl../kem-2.0.2.pl -i vmlinux.kem.mips64.r2.le.001.bin -l 0xffffffff80100000 В ходе отладки анализировались возникшие ошибки. Устранение ошибок производилось редактированием конфигурационных файлов, либо внесением правок в исходный код файлов ядра. В частности были изменены участки кода, в которых присутствовали обращения к нереализованным в эмуляторе регистрам памяти. Также бы отключен режим предварительного выбора команд (Prefetch). Анализ результатов
) Поставлена задача портирования операционной системы Linux на процессор MIPS64 Release 2 реализации фирмы KEDAH. 2) Рассмотрены различные походы к решению данной задачи. ) Изучены особенности загрузки операционной системы Linux, эмулятор kem-2.0.2 фирмы KEDAH. ) Проведена настройка конфигурации операционной системы Linux для работы с эмулятором kem-2.0.2 фирмы KEDAH. ) Проведены отладка конфигурации операционной системы. ) Проведены тестовые запуски операционной системы и анализ возникших ошибок. ) Проведена успешная загрузка операционной системы Linux на эмуляторе kem-2.0.2 фирмы KEDAH. В ходе дипломного проектирования были изучены спецификация архитектуры процессора MIPS64, технологии сборки, компиляции и портирования ядра операционной системы ОС Linux. В процессе конфигурирования и компиляции дистрибутива ОС Linux на Perl-эмуляторе kem-2.0.2 процессора, аналогичного MIPS64 Release 2, был получен устойчивый порт ОС Linux на данную платформу. Полученные результаты свидетельствуют о том, что разработанный процессор соответствует архитектуре MIPS64 и совместим с большинством современных систем. Экологическая часть Электрическая безопасность А) Анализ электрической опасности Анализ электрической опасности целесообразно проводить на примере наиболее опасного двухфазного (двухполюсного) прикосновения. При этом сопротивление тела человека Rч для напряжения 5 В и выше переменного тока 50 Гц можно рассчитать по формуле:
где Uпр - напряжение прикосновения. В нашей стране в качестве расчётных значений приняты Rч = 1000 Ом при Uпр= 50 В и выше, при этом продолжительность воздействия тока на человека считается менее 1 с, и Rч =6000 Ом при Uпр= 36 В и менее при длительности воздействия тока более 1с. Следует учитывать что при Uпр около 200 В всегда происходит пробой рогового слоя кожи и Rч становится равным примерно 300 Ом. В моём рабочем помещении используются питающие напряжения 220 В, 50 Гц. Для данных условий стандарт предусматривает следующие нормы для электроустановок. Наибольшие допустимые значения: · Нормальный режим работы. Uпр= 2 В, Iч = 0,3 мА. · Аварийный режим работы производственных электроустановок. Таблица аварийного режима работы производственных электроустановок.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2020-03-27; просмотров: 124; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.218.55.14 (0.152 с.) |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 кОм
кОм


