
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Выбор типа модели на основе регрессионного анализа
Задача регрессионного анализа установить определенную обусловленность между изучаемыми характеристиками, представив выявленную связь в строгой аналитической форме. В этом случае результат исследования – например, влияние режимов на силы резания, может быть описан математически с использованием аппроксимирующего выражения (эмпирической формулы). Однофакторная регрессия Задача – предсказание (прогнозирование) одной переменной на основании другой. Вид функциональной зависимости неизвестен. Используемые варианты: 1. Линейная взаимосвязью между исследуемыми переменными y = b 0 + b 1 x. 2. Криволинейные зависимости вида: применяются математические функции следующего вида: – гиперболическая y = b 0 + b 1 / x; – показательная y = b 0 + b 1 x; – степенная y = b 0 x b 1; – параболическая y = b 0 + b 1 x + b 2 x 2; – логарифмическая y = b 0 + b 1lg x; – экспоненциальная y = b 0 exp (b1x); – многочлен (полином), расположенный по восходящим степеням изучаемого фактора и одновременно линейный ко всем коэффициентам y = f (x) = b 0 + b 1 x + b 2 x 2 +…+ bm xm,
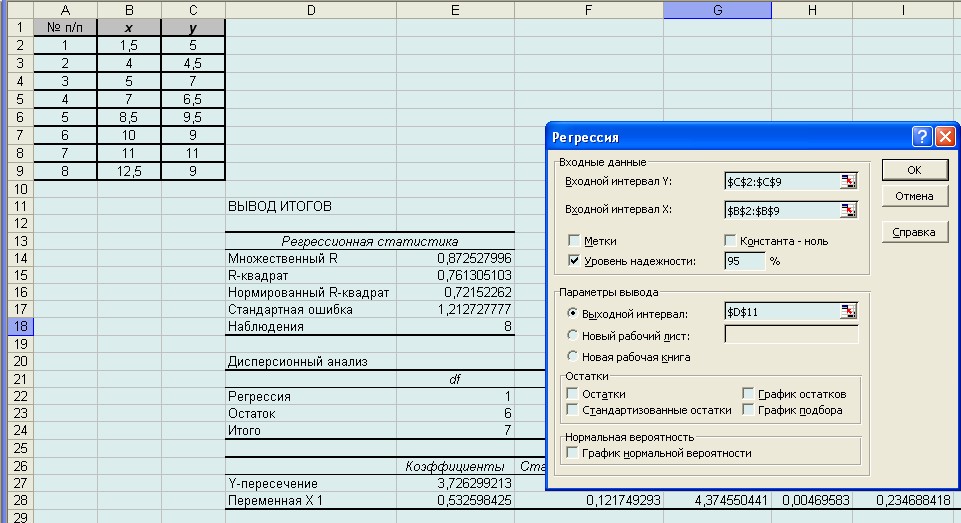
где b 0 , b 1, b 2,…, bm − коэффициенты, подлежащие определению. Расчет с использованием компьютерной программы На рабочем листе Excel предварительно создается таблица с исходными данными, в которой укажем содержимое задания. Причем сама таблица строится по столбцам и помещается в ячейках (на примере A1:C9). Итоговый результат показан на рис. 5.
Рис. 5. Лист Excel с результатами расчета коэффициентов регрессии
Далее: − в главном меню запустить серию команд Сервис/Анализ данных/Регрессия; − в появившемся диалоговом окне заполнить поля ввода данных для обоих параметров у и х;для этого в каждое окно (Входной интервал Y и Входной интервал Х) поместить данные, выделив их предварительно в соответствующих столбцах (в примере для функции у ее данные «сидят» в третьем столбце С2:С9, а для переменной х – во втором, т.е. В2:В9; при этом выделяются только те ячейки, которые содержат исключительно числовые показатели); − отметить Уровень надежности (доверительную вероятность), равный 95 %; − указать в окне вывода Выходной интервал ту ячейку, от которой будет формироваться весь блок получаемых статистических показателей, это D11;
− после чего нажать кнопку ОК. На рис. 5 в собранном виде представлены все упомянутые элементы – исходная таблица (в верхнем левом углу), заполненное диалоговое окно Регрессия и, наконец, рассчитанные статистические показатели под заголовком «Вывод итогов». Excel выдал набор разнообразных статистических материалов. Выберем из них только те, которые нам потребуются для заключительных рассуждений. Интерес представляют показатели, которые именованы как «Коэффициенты». Один из них назван «Y-пересечение», а второй – «Переменная Х1». Это и есть нужные нам коэффициенты регрессии: свободный член b 0 и коэффициент b 1при аргументе х. После вычисления коэффициентов полученное уравнение регрессии надлежит подвергнуть проверке на адекватность. Это делается с помощью набора показателей, представленных под заголовком «Вывод итогов. Множественная регрессия Прогнозирование единственной переменной у на основании нескольких переменных хk называется множественной регрессией. В этом случае математическая модель процесса представляется в виде уравнения регрессии с несколькими переменными величинами, т.е. у = f (b 0, …, xk). Общий вид уравнения множественной регрессии обычно стараются представить в форме линейной зависимости у = b 0 + b 1 x 1 + b 2 x 2 + …+ bkxk,
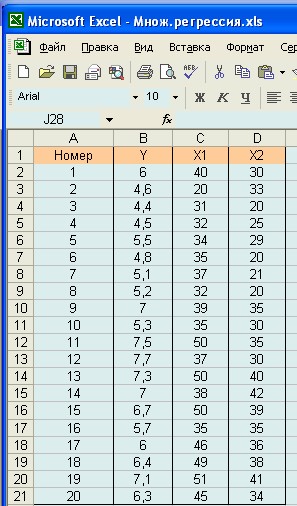
где b 0 – свободный член (или сдвиг); b 1, b 2, …, bk − коэффициенты регрессии, которые подлежат вычислению методом наименьших квадратов. Расчет коэффициентов регрессии и представление уравнения множественной регрессии Рассмотрим решение задачи на следующем примере. Исходная информация представлена в таблице 3
Таблица 3 Исходные данные для расчета множественной регрессии
Запускаем Excel и воспроизводим в табличной форме имеющиеся исходные результаты (табл. 3). В данном случае все экспериментальные данные (по каждой позиции) представляем в виде самостоятельных колонок (рис. 6). Размещаем всю таблицу в ячейках от A1 до D21, при этом сами исходные данные (т.е. для у и x 1, x 2) будут находиться в диапазоне B1: D21.
Рис. 6. Лист Excel с исходными табличными результатами
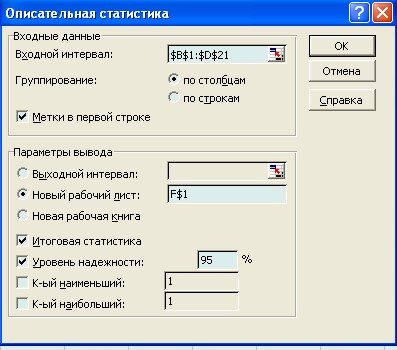
После этого получим сводную таблицу основных статистических характеристик для функции у. Для этого воспользуемся известным методом анализа данных – программой Описательная статистика. Предпримем следующие шаги: - в главном меню выбираем последовательно пункты Сервис/Анализ данных/Описательная статистика, после чего щелкаем по кнопке ОК; - заполняем диалоговое окно для ввода данных и параметров вывода. Чтобы получить их, проделаем следующие манипуляции (рис. 7): - укажем Входной интервал (в виде абсолютных ссылок $B$1: $D$21), т.е. адресуем все ячейки, в которых находятся значения функции у и аргументовx1, x 2; - отметим способ Группирования (в нашем случае по столбцам); - откроем флажок для Метки, показывающий, что первая строка содержит название столбца; - выделим Выходной интервал, для этого достаточно указать левую верхнюю ячейку будущего диапазона ($F$1); - установим флажки, показывающие, что нам нужна информация в виде Итоговой статистики, а также Уровень надежности, равный95 %;после чего нажмем кнопку ОК.
Рис. 7. Диалоговое окно ввода параметров Описательная статистика
Полученные результаты статистического расчета показаны на рис. 8 в виде соответствующего листа Excel. Из представленного комплекта статистических показателей выберем те, которые нам потребуются для последующего анализа − среднее арифметическое и стандартное отклонение (среднеквадратичное отклонение) Sn. В табл. 4 приведены названные статистические показатели для функции у и обеих переменных х 1 и х 2. Отметим, что для функции у ее среднее арифметическое
Таблица 4 Статистические показатели для функции у и переменных х 1 и х 2
Рис. 8. Лист Excel с результатами расчета статистических показателей
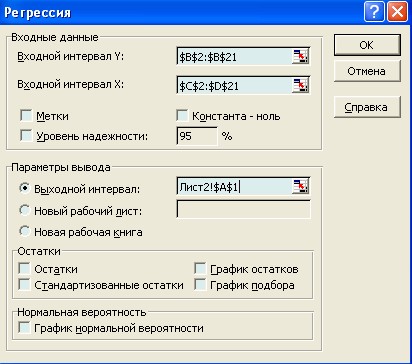
Расчет показателей регрессии также исполняется по компьютерной программе. Для ее запуска исполним следующие команды: − в главном меню выберем пункты Сервис/Анализ данных / Регрессия, после чего щелкнем по кнопке ОК; − заполним диалоговое окно ввода данных для параметра у и обеих характеристик х 1 и х 2;для этого в каждое окно (Интервал Y и Интервал Х) поместим наши данные, выделив их предварительно в соответствующих столбцах (напомним, что для функции у ее данные «сидят» во втором столбце В2:В21, а для переменных х1 и х 2 – в третьем и четвертом, т.е. в диапазоне ячеек C2:D21; заметим, что при этом выделяются только те ячейки, которые содержат исключительно числовые показатели); − выделим в текстовом поле Выходной интервал ту ячейку, от которой будет формироваться весь блок получаемых статистических показателей; при этом укажем другой лист − Лист 2; − после чего − кнопка ОК. Заполненное диалоговое окно для программы Регрессия представлено на рис. 9.
Рис. 9. Диалоговое окно ввода параметров Регрессия
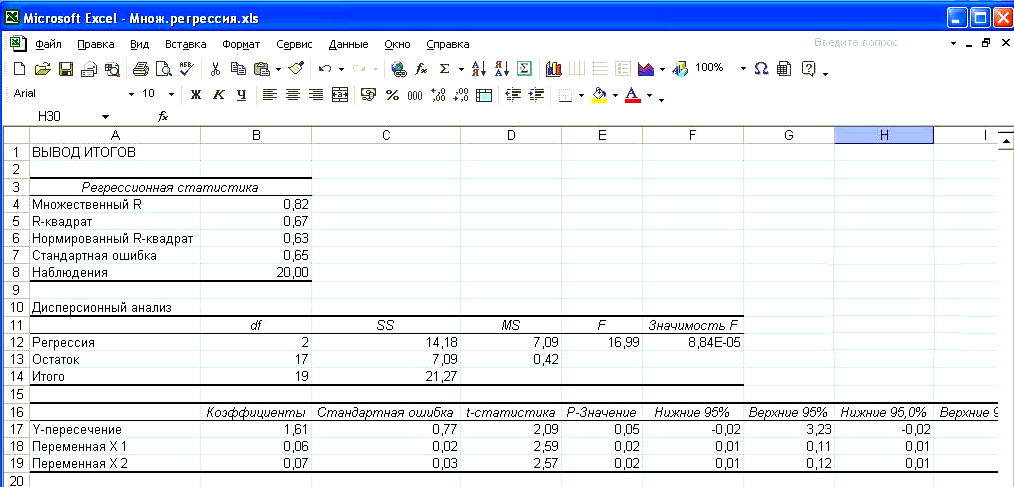
Excel выдает набор разнообразных статистических материалов (рис. 10). Выберем из них такие, которые нам потребуются для последующего анализа: расчетные значения коэффициентов регрессии, стандартную ошибку, величины t -критерия и показатели уровня значимости α (табл. 5). Укажем также (ниже таблицы) рассчитанные показатели для самой функции у.
Рис. 10. Лист Excel с результатами расчета статистических показателей регрессии Таблица 5 Данные регрессионной статистики
Для функции Y:
ŷ = 1,61 + 0,06 x 1 + 0,07 x 2.
|
|||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2020-03-14; просмотров: 180; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.135.217.228 (0.017 с.) |
 составляет 6,01, а стандартное отклонение (среднеквадратичное отклонение) Sn равно 1,06.
составляет 6,01, а стандартное отклонение (среднеквадратичное отклонение) Sn равно 1,06. 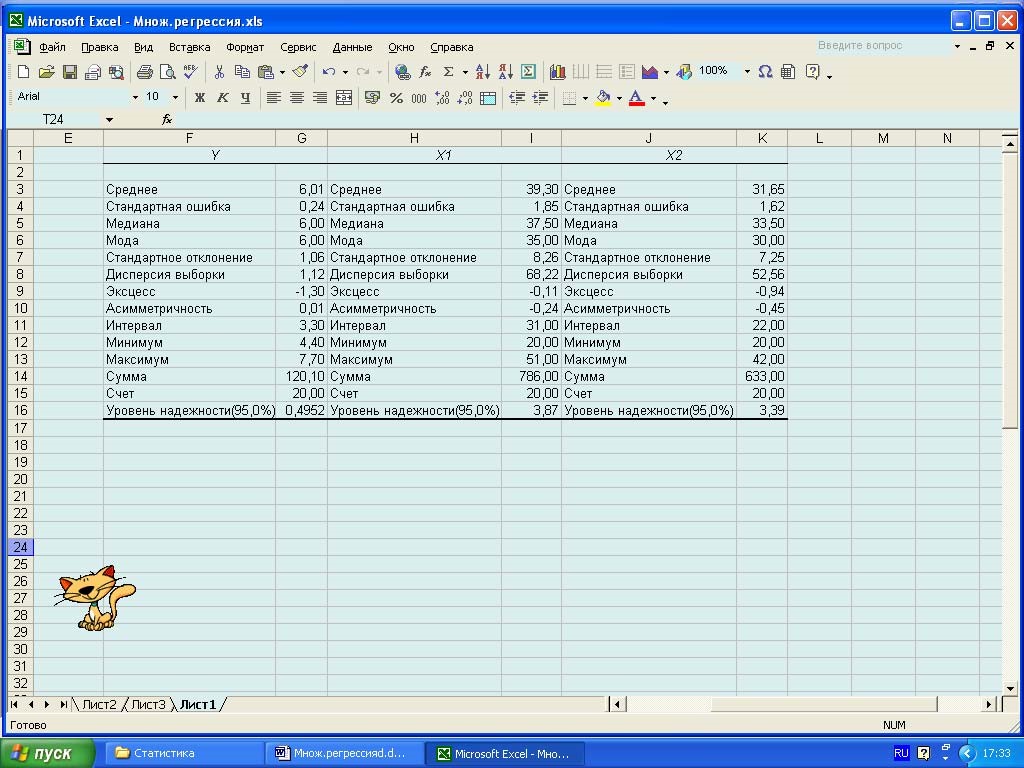
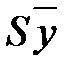 = 0,65; R -квадрат = 0,67; R -квадрат (нормир.) = 0,63. Таким образом, для рассматриваемого примера уравнение регрессии (или уравнение прогнозирования) будет иметь следующий вид
= 0,65; R -квадрат = 0,67; R -квадрат (нормир.) = 0,63. Таким образом, для рассматриваемого примера уравнение регрессии (или уравнение прогнозирования) будет иметь следующий вид


