Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
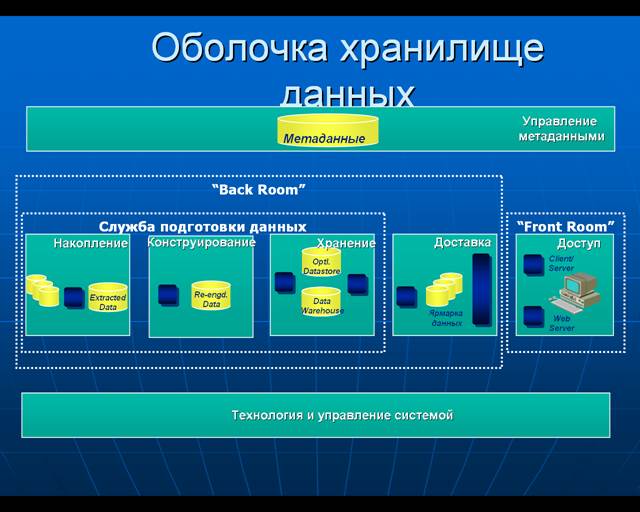
Иерархия обработки корпоративных данныхСодержание книги
Поиск на нашем сайте
Сравнительные характеристики OLTP и OLAP технологий Сравнение OLTP и OLAP
Концепция «от данных к знаниям» От данных к знаниям
33. Сравнительные характеристики экспертных систем и Data Manıng
Концепция доступа к данным в хранилище данных обрав в одном месте всю информацию об истории развития организации, ее успехах и неудачах, о взаимоотношениях с поставщиками и заказчиками, об истории развития и состоянии рынка, менеджеры получают уникальную возможность для анализа прошлой деятельности, сегодняшнего дня и построения обоснованных прогнозов на будущее. Однако не следует забывать и о том, что если не обеспечены надлежащие средства защиты и ограничения прав доступа, вы можете снабдить этой информацией и ваших конкурентов. Одним из первых же вопросов, встающих при обсуждении проекта Хранилища Данных, является вопрос защиты данных. Чисто психологически, многих пугают не столько затраты на реализацию системы Хранилищ Данных (чаще всего есть понимание, что эффект от ее использования будет больше), а то, что доступ к критически значимой информации может получить кто либо, не имеющий на это права. В таких системах, часто оказывается недостаточно защиты обеспечиваемой в стандартных конфигурациях коммерческих СУБД (обычно уровень защиты по классу “C2 OrangeBook”.) Региональный менеджер должен видеть только те данные, которые относятся к его региону, а менеджер подразделения не должен видеть данные, относящиеся ко всей фирме. Но, для повышения эффективности доступа к данным, в целевой БД Хранилища Данных, все эти данные, как правило, хранятся в виде единой фактологической таблицы. Следствием этого, является то, что средства реализации должны поддерживать ограничения доступа не только на уровне отдельных таблиц и их колонок, но и отдельных строк в таблице (класс “B1 OrangeBook”).
Многомерная модель данных Реляционные СУБД предназначались для информационных систем оперативной обработки информации и в этой области весьма эффективны. В системах аналитической обработки они показали себя несколько неповоротливыми и недостаточно гибкими. Более эффективными здесь оказываются многомерные СУБД. Многомерные СУБД являются узкоспециализированными СУБД, предназначенными для интерактивной аналитической обработки информации. Основные понятия, используемые в этих СУБД: агрегируемость, историчность и прогнозируемость. Агрегируемость данных означает рассмотрение информации на различных уровнях ее обобщения. В информационных системах степень детальности представления информации для пользователя зависит от его уровня: аналитик, пользователь, управляющий, руководитель. Историчность данных предполагает обеспечение высокого уровня статичности собственно данных и их взаимосвязей, а также обязательность привязки данных ко времени. Прогнозируемость данных подразумевает задание функций прогнозирования и применение их к различным временным интервалам.Многомерность модели данных означает не многомерность визуализации цифровых данных, а многомерное логическое представление структуры информации при описании и в операциях манипулирования данными. По сравнению с реляционной моделью многомерная организация данных обладает более высокой наглядностью и информативностью. Измерение – это множество однотипных данных, образующих одну из граней гиперкуба. В многомерной модели измерения играют роль индексов, служащих для идентификации конкретных значений в ячейках гиперкуба. Ячейка – это поле, значение которого однозначно определяется фиксированным набором измерений. Тип поля чаще всего определен как цифровой. В зависимости от того, как формируются значения некоторой ячейки, она может быть переменной (значения изменяются и могут быть загружены из внешнего источника данных или сформированы программно) либо формулой (значения, подобно формульным ячейкам электронных таблиц, вычисляются по заранее заданным формулам). Основным достоинством многомерной модели данных является удобство и эффективность аналитической обработки больших объемов данных, связанных со временем. Недостатком многомерной модели данных является ее громоздкость для простейших задач обычной оперативной обработки информации. Примерами систем, поддерживающими многомерные модели данных, является Essbase, MediaMulti — matrix, OracleExpressServer, Cache. Существуют программные продукты, например Media / MR, позволяющие одновременно работать с многомерными и с реляционными БД.
|
||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-02-10; просмотров: 214; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 52.15.111.109 (0.006 с.) |