Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Общая структура команды SELECTСодержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
Практически весь SQL базируется на единственном операторе, а именно операторе SELECT. Сам оператор SELECT есть не что иное, как выражение для получения результирующего набора из таблиц БД. Мы формируем запрос при помощи оператора SELECT, а он, в свою очередь, выполнив свою работу, возвращает результирующий набор данных. Возвращаются эти данные в виде таблицы, которая в свою очередь, может быть обработана следующим оператором SELECT и т.д. Рассмотрим сам оператор и его синтаксис. Этот оператор позволяет осуществлять следующее: - Проекция (projection): Вы можете выбрать лишь те столбцы из таблицы, которые нужны. Можно выбрать любое количество столбцов, имеющееся в таблице. - Селекция (selection): Вы можете извлечь часть строк из таблицы, которые отвечают заданным условиям. - Объединение (joining): Вы можете извлекать данные одновременно из нескольких таблиц, создавая связи между ними. Наиболее простая синтаксическая конструкция оператора SELECT: SELECT * | { [DISTINCT] столбец | выражение [синоним],... } FROM таблица; Где: SELECT - открытие списка одного или более столбцов; * - выбор всех столбцов; DISTINCT - устранение повторяющихся строк; столбец | выражение - выборка указанного столбца или выражения; синоним – заголовок столбца в результате выборки; FROM таблица - указывается таблица, из которой выбираются столбцы.
На практике SQL-выражения для выборки данных могут быть намного сложнее (а иногда – проще). SELECT ALL схема, столбец DISTINCT * FROM схема, таблица.. WHERE условие поискаGROUP BY схема, столбецHAVING условие поискаORDER BY спецификатор сортировки
Первое правило: само выражение SELECT обязательно включает выражение FROM. Предложение FROM содержит "список спецификаторов таблиц", а именно имена таблиц, из которых производится запрос. Такие таблицы называются "исходными таблицами запроса". Так как результаты запроса берутся именно из них. Остальные выражения используются по мере необходимости. Выражение SELECT включает в себя список столбцов возвращаемых запросом. Выражение FROM включает в себя список таблиц для выполнения запроса. Выражение WHERE устанавливает условие поиска, если необходимо вернуть не все строки, а только ту часть, которая описана условием, поиска. Выражение GROUP BY позволяет создать итоговой запрос, разбитый на группы. Выражение HAVING определяет условие возврата групп и используется только совместно с GROUP BY. Выражение ORDER BY определяет порядок сортировки результирующего набора данных. В случае если необходимо просто вывести информацию из всех столбцов, имеющихся в таблицах (указанных в предложении FROM), используйте звездочку (*). (Пример1-выборка всех столбцов из таблицы Regions). В этом случае поля на экран будут выводиться в том порядке, как они создавались с помощью команды CREATE TABLE. Пример 1: select * from regions
Рисунок №20 – Результат выборки
Вы можете сделать выборку не всех столбцов таблицы, а только тех, которые представляют интерес. Для этого после ключевого слова SELECT перечислите через запятую все необходимые столбцы.
Пример 2: select country_name from countries
Рисунок №21- Результат выборки из примера №2
Сделаем теперь выборку нескольких столбцов из таблицы. Пример 3: select country_name,region_id from countries
Рисунок №22- Результат выборки из примера №3
Формирование условий отбора При использовании технологии «клиент-сервер» количество передаваемых по сети данных очень сильно влияет на производительность. Идеальный способ обработки данных – использование хранимых процедур, когда ваше приложение обменивается с сервером только параметрами и результатами. Но это не всегда возможно, а часто и не нужно, потому что просмотр пользователем информации тоже имеет значение. Основная забота программиста – построение предложения WHERE. Оно может включать в себя операторы, перечисленные в таблице 1. При построении условий поиска необходимо помнить, что оптимизатор запросов не может работать с отрицанием, например NOT BETWEEN. Поэтому хорошим стилем является стремление избежать операторов отрицания. Таблица 2 – Операторы, используемые в предложении WHERE
При использовании операторов сравнения необходимо придерживаться двух простых правил: - Выражения могут содержать константы, имена столбцов, функции, вложенные запросы и арифметические операторы. - Использовать одинарные кавычки с данными типа char, varchar, text, datetime и smalldatetime. Хотя двойные кавычки не запрещены, одинарные кавычки предпочтительней для совместимости со стандартом ANSI. Часто требуется просмотреть данные в их отношении друг к другу. Oracle предоставляет для этой цели операторы сравнения. В большинстве диалектов операторы сравнения ограничиваются набором, представленным в таблице 3. Таблица 3 – Операторы сравнения
Обычно операторы сравнения используются для работы с числами. Но в SQL вы можете их использовать и с типами char и varchar: тогда знак “<” значит раньше по алфавиту, а “>” – позже. Кроме того, операторы сравнения можно использовать для дат. Как уже отмечалось, при работе с этими типами данных главное – не забыть поставить вокруг выражений одинарные кавычки. Обычно в предложении WHERE приходится использовать несколько условий поиска, которые объединяются логическими операторами AND, OR, NOT (их еще называют булевыми операторами). Смысл этих операторов такой же, как и во всех языках программирования: AND – это логическое И, a OR – ИЛИ. Вы можете составлять запросы, используя арифметические выражения. В арифметических выражениях могут принимать участие наименования столбцов, константы, переменные и операторы. Используйте следующие операторы: + (сложение), - (вычитание), * (умножение), / (деление). Арифметические выражения можно применять в любой части SQL -запросов, кроме предложения FROM. Рассмотрим Пример 4: select country_name,region_id from countries where region_id=3
Рисунок №23 – Пример выборки с использованием предложения where
В данном примере, из таблицы Countries мы выбрали вначале два столбца, а затем вывели лишь те полям, region_id которых равен 3. Пример 5: select country_name,country_id from countries where region_id=6
Рисунок №24 – Выборки примера № 5
Как мы видим по нашему запросу ничего не найдено.
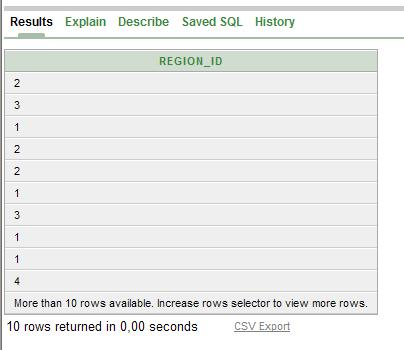
Пример 6: Вывести список идентификаторов менеджеров офисов. SELECT region_id FROM countries
Рисунок №25 – Выборки примера №6
Запись с номерами 2,3,1повторилась не один раз, т.к такие номера есть у многих полей таблицы. Чтобы этого не происходило, нужно использовать оператор DISTINCT. Например, вот так:
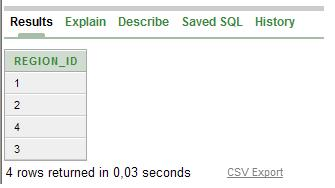
Пример 7: SELECT DISTINCT region_id FROM countries
Рисунок №26 – Выборки примера №7
Рассмотрим выражение BETWEEN, по своей сути это выражение проверки на принадлежность к диапазону значений. Синтаксис выражения строится примерно так: поверяемое выражение BETWEEN нижнее выражение AND верхнее выражениеNOTВыражение NOT обуславливает обратное инвертирование условия, то есть "не принадлежит". Давайте попробуем применить, на практике. Рассмотрим пример 8 работы с датами. Выражение TO_DATE и есть преобразование строк. select employee_id, first_name, last_name, hire_date, salary from employees where hire_date between TO_DATE('01.11.1996','DD/MM/YYYY') AND TO_DATE('31.12.1998','DD/MM/YYYY')
Рисунок №27 – Результат выборки between
Функции работы с датами -add_months(d,n) — добавляет n месяцев к дате d с учетом количества дней в месяце: add_months('31-Oct-2001',4) = '28-Feb-2002' -last_day(d) — последний день месяца, которому принадлежит дата d: last_day('3-Oct-2001') = '31-Oct-2001' -months_between(d1,d2) — количество месяцев (необязательно целое) между датами d2 и d1 (если d2>d1, то результат отрицательный): months_between('3-Oct-2001', '2-Nov-2001') = -0.967741935 -next_day(d,c) — ближайший следующий за датой d день недели c: next_day('3-Oct-2001','wed') = '10-Oct-2001' -round(d [,fmt]) — округляет дату d[1] до единиц, указанных fmt — форматной строкой для даты. По умолчанию округляет до дня: round(to_date('3-Oct-2001', 'dd-mon-yyyy'),'YEAR') = '1-Jan-2002' -sysdate — текущая дата и время; обратите внимание, что если функция не принимает аргументов, пустые скобки после ее имени не пишутся. -trunc(d [,fmt]) — обрезает дату d до единиц, указанных fmt — форматной строкой для даты. По умолчанию обрезает до дня: trunc(to_date('3-Oct-2001', 'dd-mon-yyyy'),'mm') = '1-Oct-2001'
Символьные функции -ascii(s) — ASCII-код первого символа строки s: ascii('Abc') = 65 -chr(n) — ASCII-символ с кодом n: chr(65) = 'A' -concat(s1,s2) — конкатенация строк s1 и s1; то же, что s1 || s2: concat('A', 'B') = 'AB' -initcap(s) — делает первые буквы всех слов строки s заглавными: initcap('иванов и.и.') = 'Иванов И.И.' -instr(s,sub [,n [,m]]) — возвращает позицию m-го вхождения строки sub в строку s, начиная с позиции n; если n отрицательна, то позиция считается от конца строки s. -По умолчанию m=1 и n=1:instr(' Иванов И.И.',' И') = 1 instr(' Иванов И.И.',' И',2,2) = 10 -length(s) — длина s в символах: length(' длина строки') = 12 -lower(s) — преобразование строки s в нижний регистр: lower('НиЖний') = 'нижний' -lpad(s1,n [,s2]) — дополняет s1 слева до длины n символами из s2 (если s2 не указана, то пробелами). Если длина s1 больше n, обрезает s1 справа: lpad('семь',7,'.') = семь' -ltrim(s1 [,s2]) — убирает из строки s1 слева все символы, входящие в s2. Если s2 не указана, убирает пробелы: ltrim(' семь ') = ' семь ' -replace(s1,s2 [,s3]) — заменяет в строке s1 все вхождения s2 на s3. Если s3 не указана, что все вхождения s2 удаляются: replace('Иванов И.ИИван','Петр') = 'Петров И.И.' -rpad(s1,n [,s2]) — дополняет строку s1 справа до длины n символами из s2 (если s2 не указана, то пробелами). Если длина s1 больше n, обрезает s1 справа: rpad(' семь',7,'.') = ' семь... ' -rtrim(s1 [,s2]) — убирает из строки s1 слева все символы, входящие в s2. Если s2 не указана, убирает пробелы: rtrim(' семь ') = ' семь' -soundex(s) — возвращает звуковое представление слова s:soundex('MicroSoft') = 'M262' soundex('miKrosOVte') = 'M262' -substr(s,m [,n]) — возвращает подстроку s начиная с позиции m длиной n символов. Если m=0, считается m=1; если m отрицательно, то считается позиция от конца строки. Если n не указано, то возвращается подстрока от m до конца строки: substr(' Иванов И.И.',1,6) = ' Иванов' substr(' Иванов И.И.',-4) = ' И.И.' -translate(s1,s2,s3) — возвращает s1, в которой все символы из s2 заменены соответствующими символами из s3; символы, не входящие в s2, не заменяются; символы, которые есть в s2, но не имеют соответствия в s3, удаляются: translate^Иванов И.ИИва','!') = '!нов -trim([leading | trailing] c from s) — удаляет символы c из начала (leading), конца (trailing) или с обоих концов строки s; c представляет собой строку длиной в 1 символ: trim(leading ' ' from ' строка') = ' строка' -upper(s) — преобразование строки s в верхний регистр: upper('вЕрХний') = 'ВЕРХНИЙ'
Математические функции - abs(x) — абсолютное значение x: abs(-15) = 15 - acos(x) — арккосинус x: acos(-1) = 3.14159265 - asin(x) — арксинус x: asin(-1) = -1.57079633 - atan(x) — арктангенс x; результат от -я/2 до я/2: - atan(1) = 0.78539816 - atan2(x,y) — то же, что atan(x/y); результат от -я до я, в зависимости от знака x и y: atan2(5774,10000) = 3.1415914 - ceil(x) — наименьшее целое, большее или равное x: ceil(15.7) = 16, ceil(-15.7) = -15 - cos(x) — косинус x: cos(0) = 1 - cosh(x) — гиперболический косинус x: cosh(2.71828) = 7.6101113 - exp(x) — экспонента x: exp(1) = 2.718281828 - floor(x) — наибольшее целое, меньшее или равное x: floor(15.7) = 15, floor (-15.7) = -16 - ln(x) — натуральный логарифм x: ln(2.71828) = 0.99999933 - log(a,x) — логарифм x по основанию a: log(2,1024) = 10 - mod(a,b) — остаток от деления a на b: mod(7,3) = 1 - power(x,y) — x в степени y: power(2,3) = 8 - round(x[,n]) — округление x до n десятичных разрядов: round(128.51) = 129 round(128.51,1) = 128.5, round(128.51,-1) = 130 - sign(x) — знак x: sign(-9) = -1 - sin(x) — синус x: sin(1.57) = 0.99999968 - sinh(x) — гиперболический синус x: sinh(2.71828) = 7.54412319 - sqrt(x) — квадратный корень x: sqrt(9) = 3 - tan(x) — тангенс x: tan(3.14159/4) = 0.99999867 - tanh(x) — гиперболический тангенс x: tanh(1) = 0.761594156 - trunc(x,[n]) — отбрасывание дробной части x, точность n десятичных знаков: trunc(128.51) = 128 trunc (128.51,1) = 128.5 trunc (128.51,-1) = 120 Далее приведем еще один пример на выборку значений из промежутка.
Пример 9: select first_name, last_name, salary from employees where salary between 4000 AND 7000
Рисунок №28 – Результаты выборки примера 9
Пример 10: не в диапазоне с использованием NOT select first_name, last_name, salary from employees where salary not between 4000 AND 7000
Рисунок №29 – Результаты выборки примера 10
Рассмотрим теперь предикат LIKE ИМЯ СТОЛБЦА LIKE (шаблон)NOT ESCAPE (имя пропуска)Вначале произведем выборку для дальнейшего использования like. select first_name, last_name, salary from employees where last_name = 'Ernst'
Рисунок №30 – Результаты выборки
А теперь используем Like (рис 21) делаем поиск по букве s. select first_name, last_name, salary from employees where last_name like '%s'
Рисунок №31 – Результат использования LIKE
Для вывода данных, отсортированных по какому-либо столбцу, используется ключевое слово ORDER BY. Результат выборки можно отсортировать одновременно по 16 столбцам. В Transact-SQL в предложение ORDER BY можно включать столбцы или выражения, отсутствующие в списке выборки. Сортировать можно по именам столбцов, по заголовкам столбцов, по выражению или по номеру, указывающему позицию столбца в списке выборки. При сортировке по номеру столбца необходимо указывать тот номер, который реально присутствует в списке выборки. То есть если в списке выборки два столбца, а вы пытаетесь отсортировать по третьему, то произойдет ошибка. При использовании в запросе ключевого слова COMPUTE BY обязательно необходимо проводить сортировку с помощью предложения ORDER BY. Не забудьте, что значение NULL при сортировке выводится раньше всех других. Столбцы типа text и image использовать в предложении ORDER BY нельзя. Подзапросы и представления не могут включать предложения ORDER BY, COMPUTE BY или ключевое слово INTO.Самое главное, для чего предназначено предложение ORDER BY, – сделать результаты вашей выборки более удобными для восприятия. Порядок сортировки зависит от используемого набора символов и кодовой страницы. Синтаксис Order by выглядит следующим образом: Приведем пример13: использование Order by. select COUNTRY_ID, REGION_ID, COUNTRY_NAME from countries ORDER BY REGION_ID, COUNTRY_NAME
Рисунок №32 – Результаты выборки примера 13
Группировка данных Во всех приведенных выше примерах из базы извлекались данные в том виде, в котором они лежат в таблицах. Однако язык SQL позволяет извлекать данные по группам строк. Для этого служит фраза group by предложения select. Поля, по которым группируются строки, должны быть перечислены во фразе group by. Если строки группируются по всем полям, то такой запрос эквивалентен указанию ключевого слова distinct в операторе select. Все поля, не входящие в список группировки, должны вычисляться с помощью агрегатных функций, т. е. функций, аргументами которых являются целые столбцы. Агрегатные функции будут рассмотрены ниже, а сейчас приведем пример на работу оператора GROUP BY.Сколько рабочих работает в офисах? Select job_id, count(*) from employees group by job_id
Рисунок №33 – Результаты группировки данных
|
||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-02-09; просмотров: 649; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.142.197.111 (0.009 с.) |