
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Построение интервального ряда распределения единиц выборки по выручке на 1 га С. -х. Угодий и его характеристика системой показателей
Интервальный ряд распределениястроится в следующей последовательности: а) определение группировочного признака, т. е. признака, по которому следует формировать группы; В нашем примере группировочным признаком является выручка на 1 га с.х.угодий. б) построение ранжированного ряда по группировочному признаку; в) анализ характера изменения признака в ранжированном ряду ( по огиве Гальтона); г) определение числа групп При неравномерном распределении признака следует формировать группы с неравными интервалами. Число групп определяется по количеству «скачков», т.е. резких переходов от одних значений признака к другим. При равномерном изменении признака формируются группы с равными интервалами, и их число определяется по формуле m = m =1+3.322 lg N, где N – число единиц в совокупности д) определение шага интервала (h) При равномерном изменении признака шаг рассчитывается по формуле h= е) определение границ интервалов В каждом интервале две границы: нижняя и верхняя. Разность между верхней и нижней границей интервала равна шагу интервала h. Для первой группы нижняя граница интервала равна первому значению признака в ранжированном ряду. Прибавляя к этому значению шаг интервала h, получаем верхнюю границу первой группы. Верхняя граница первого интервала при непрерывном характере признака является одновременно нижней границей второго интервала. Прибавляя к ней шаг интервала, определяем верхнюю границу второго интервала и т.д. ж) подсчет числа единиц (частот встречаемости) в каждом интервале Подсчет проводится по ранжированному ряду. Если значение признака попадает на границу групп (например, первой и второй групп), то, как правило, единицу учитывают по верхней границе (в первой группе) по принципу «включительно». Результаты подсчета записываются в таблицу (таблица 5). Таблица 5- Интервальный ряд распределения хозяйств по выручке на 1 га с.-х. угодий
З) графическое изображение интервального ряда распределения и выводы о распределении плотности единиц по группам.
К статистическим показателям, характеризующим ряд распределения, относятся 1) средние величины (их называют также показателями центральной тенденции), характеризующие типические черты совокупности, 2)показатели вариации, характеризующие изменчивость признака в совокупности, и 3) показатели формы распределений, характеризующие асимметричность (скошенность) и островершинность (плосковершинность) изучаемого распределения относительно нормального распределения. Средние величины могут быть получены на основе всех индивидуальных значений признака («степенные средние» - Средняя в интервальному ряду определяется по средней арифметической За индивидуальные значения признака ( Модальное значение признака вычисляется по формуле
x0 -- начальное значение модального интервала f mo -частота модального интервала f mo-1 - частота интервала, предшествующая модальному интервалу. f mo+1 - частота интервала, следующего за модальным интервалом. h -шаг интервала
Определение медианы в интервальном ряду по алгоритму схоже с определением модального значения: сначала определяется медианный интервал, а затем в нем по формуле рассчитывается конкретное значение медианы. Для определения медианного интервала для каждого интервала определяют накопленную частоту. Далее устанавливается адрес медианы по формуле n мe = медианное значение признака рассчитывается по формуле
где x0 - начальное значение модального интервала h -шаг интервала N - общее число единиц совокупности (+1) – используется в рядах с нечетным числом единиц совокупности Sme – накопленная частота до медианного интервала fme - частота медианного интервала
Показатели вариации могут характеризовать максимальную колеблемость признака (размах вариации) и среднюю колеблемость признака в совокупности (среднее линейное отклонение, среднее квадратичное отклонение, дисперсия признака). Именованные показатели (кроме дисперсии), деленные на среднюю величину Для расчета показателей вариации необходимо составить вспомогательную таблицу (таблица 6) Таблица 6- Исходные и расчетные данные для определения показателей вариации в интервальном ряду распределения
Размах вариациирассчитывается по ранжированному ряду R=Xmax - Xmin Среднее линейное отклонение вычисляется по формуле L= где xi - значение признака, fi - частота встречаемости признака в совокупности. Дисперсия может быть рассчитана по основной и рабочей формуле. Для гарантированной точности расчетов следует рассчитать и сопоставить результаты расчетов по двум формулам. Дисперсия по основной формуле: Дисперсия по рабочей формуле:
Среднее квадратическое отклонение определяется как корень квадратный из дисперсии
Далее определяются относительные показатели вариации. Коэффициент осцилляции Относительное линейное отклонение (линейный коэффициент вариации) Коэффициент вариации ( квадратический коэффициент вариации):
Показатели формы распределений включают, прежде всего характеристику симметричности распределения признака – коэффициент скошенности (асимметрии) и характеристику островершинности распределения – коэффициент эксцесса. Для оценки асимметрии применяются 2 показателя. Первый коэффициент скошенности определяется как отношение центрального момента 3-го порядка (
где Второй коэффициент (предложил К.Пирсон) рассчитывается как отношение разности средней арифметической и моды распределения к среднему квадратичному отклонению Аs = Если коэффициенты положительны, то можно сделать вывод о положительной, правосторонней скошенности. Коэффициент асимметрии Пирсона характеризует, прежде всего, асимметрию середины распределения, а показатель, рассчитанный по центральному моменту – асимметрию крайних значений распределения. Если коэффициент Пирсона больше по значению, можно заключить, что в центре распределения асимметрия выражена сильнее. При несильных отличиях коэффициентов от 0 сделают вывод о невысокой, умеренной асимметрии. Коэффициент островершинности (коэффициент эксцесса) рассчитываются как отношение центрального момента 4 порядка к квадрату дисперсии признака. При нормально распределенной совокупности отношение равно 3. Чтобы сравнение было с нулевым значением, в формуле, из отношения вычитается 3: Если коэффициент островершинности положительный, распределение характеризуется как островершинное. При наличии отрицательного коэффициента распределение плосковершинное.
5. Анализ причинно-следственных связей признаков выборочной совокупности. А) Анализ связи начинается с построения результативной аналитической группировки, целью которой является анализ связи выручки с факторами производства. Группы интервального ряда по выручке на 1 га с.-х. угодий характеризуются системой абсолютных показателей, на основе которых рассчитываются относительные показатели. Расчеты целесообразно вести в таблицах, примерные макеты которых приведены ниже. Таблица 7- Сводные данные по результативной аналитической группировке
Таблица 8- Анализ связи выручки с факторами и результатами экономической деятельности предприятий (результативная аналитическая группировка)
По данным таблицы 8 делается вывод о статистической закономерности изменений значений показателей от первой группы к последней группе. Закономерное изменение показателя (рост или снижение) свидетельствует о связи с группировочным признаком. Между показателями в группах также существует корреляционная связь. Например, производственные затраты на единицу площади и обеспеченность рабочей силой влияют на выручку от реализации продукции. В свою очередь, выручка от реализации продукции влияет на уровень рентабельности. Если группировка показывает отсутствие закономерного роста (или снижения) значения показателя по группе, то делается вывод о том, что связь отсутствует или слабо выражена. Например, группировка показала закономерный рост производственных затрат и нечеткую картину роста обеспеченности рабочей силой. Можно сделать вывод о том, что для роста выручки сельского хозяйства наиболее значимым фактором является интенсификация производства, так как производственные затраты на единицу площади возрастают.
Б) Для исследования более детальной связи выручки и основного факторного признака далее проводится работа по выделению групп по факторному существенному признаку (в нашем примере, по производственным затратам на 1 га с.-х. угодий). С этой целью, строится интервальный ряд по производственным затратам на 1 га с.-х. угодий и каждая группа характеризуется результативными показателями: выручкой на 1 га с.-х. угодий, прибылью и уровнем рентабельности. Результаты группировки целесообразно оформить в таблицах, макеты которых представлены ниже. Таблица 9- Сводные данные по факторной группировке, результаты реализации продукции сельского хозяйства с собственной переработкой, тыс.руб.
По таблице 10 делаются выводы о связях признаков. Таблица 10- Анализ влияния уровня вложений (производственных затрат) на результаты экономической деятельности предприятий (факторная аналитическая группировка)
В) Для статистической оценки существенности различий выручки на 1 га с.-х. угодий в группах факторной группировки (по усмотрению студента и согласованию с преподавателем может быть также взят показатель прибыли или рентабельности) далее необходимо провести дисперсионный анализ. Дисперсионный анализ применяется для проверки статистических гипотез относительно средних величин в нескольких генеральных совокупностях. При проверке гипотез методом дисперсионного анализа используется критерий F-распределения, который представляет собой отношение дисперсий двух выборок, сделанных из одной нормально распределенной генеральной совокупности: Если нулевая гипотеза основана на предположении, что все выборки взяты из нормально распределенных генеральных совокупностей с равными средними величинами (H0 :
Дисперсионный анализ следует проводить по этапам: 1) Сформулировать статистические гипотезы (нулевую и альтернативную) H 0 : Hа : 2) Рассчитать фактическое значение критерия Fфакт, для чего а) определить общий объем вариации изучаемого признака (W общ) и разложить его на составляющие части – вариацию между выборками (Wмежгрупп) и вариацию внутри выборок (остаточную -W остаточн.), иными словами построить модель дисперсионного анализа. В нашем примере, при наличии одного фактора – уровня вложений в производство, случайном формировании единиц в группах модель будет следующей: W общ = W фактора + W остаточная, где общий объем вариации равен W фактора равен W остаточная = W общ - W фактора
б) определить число степеней свободы для всех объемов вариации (V i), в) рассчитать дисперсии (S i 2) по каждому источнику вариации, как отношение объемов вариации (W) к соответствующему числу степеней свободы (V), г) рассчитать фактическое значение критерия Фишера по формуле
3) Определить по таблицам теоретическое значение критерия F 4) Сопоставить фактическое значение критерия (Fфакт) с теоретическим (Fтеорет) и сделать вывод о принятии или отвержении от нулевой гипотезы. Результаты дисперсионного анализа целесообразно оформить в виде таблицы 11. Таблица 11- Расчет и анализ дисперсий
Математический вывод о принятии или отвержении нулевой гипотезы следует дополнить практически значимым выводом о достоверности связи выручки и уровнем интенсивности производства (производственными затратами).
Г) статистическая оценка достоверной связи выручки с обеспеченностью работниками проводится на основе критерия Для проведения анализа необходимо построить двумерный ряд распределения одновременно по двум признакам: по выручке на 1 га с.х. угодий (выделить 2 группы) и численности работников на 100 га с.х. угодий (выделить 2 подгруппы). Ряд целесообразно оформить в таблицу 12. Таблица 12- Распределение хозяйств по выручке и обеспеченности работниками
При распределении важно учесть, чтобы численность единиц в ячейках таблицы была не менее 5 единиц. Проверка статистической гипотезы о независимости эмпирических распределений в генеральной совокупности в соответствии с общей схемой начинается с формулировки гипотез. Но: эмпирические распределения независимы; На: эмпирические распределения зависимы (обеспеченность работниками оказывает положительное влияние на экономический результат). Фактическое значение критерия рассчитывается по формуле
где
Для расчета ожидаемых численностей необходимы суммы частот в каждом интервале и общее число единиц в совокупности: Таблица13- Ожидаемые (гипотетические) распределения хозяйств по обеспеченности работников и размеру выручки (
Суммы гипотетических частот должны быть равны суммам фактических частот (итоги строк и граф таб.12 и 13). Соответственно общее число единиц гипотетических и эмпирических распределений должно быть равным Для расчета фактического значения критерия по формуле далее определяются разности между фактическими и гипотетическими численностями. результаты записываются в таблицу 14. Поскольку суммы фактических и гипотетических частот по интервалам равны, суммы разностей должны равняться нулю. Таблица14- Разности фактических и ожидаемых частот (
По разностям определяют фактическое значение критерия
Табличное значение определяется по уровню значимости (α = 0.05) и по числу степеней свободы После сравнения фактического значения с табличным Д) Следующий этап работы связан с применением корреляционно-регрессионного анализа. Корреляционно-регрессионный анализприменяется для определения количественных характеристик корреляционной связи, проявляющейся в среднем по достаточно большому числу наблюдений. С этой целью связь между переменными выражается посредством математического уравнения соответствующего вида, называемого уравнением корреляционной связи или уравнением регрессии. Например, линейная связь между двумя переменными (парная связь) выражается уравнением: В уравнениях регрессии Следует помнить, что вопрос об установлении вида уравнения является одним из наиболее сложных в корреляционном анализе. При парных связях он может быть решен посредством графиков путем нанесения фактических значений зависимой переменной при соответствующих значениях независимой переменной на корреляционное поле. При достаточно большом числе единиц наблюдения определенное представление о виде уравнения дает построение рядов распределения по двум признакам, или так называемых корреляционных таблиц. Для изучения наличия и направления связи выручки на 1 га с.-х. угодий с несколькими факторами эффективно применение результативной группировки по выручке с рассмотрением средних значений факторных признаков (см.п.А). Для определения формы связи можно сопоставить по каждой группе средние значения результативного и факторных признаков. Постоянство этих соотношений по группам будет свидетельствовать о наличии линейной формы связи. Перед составлением уравнения множественной связи необходимо исключение возможной коллинеарности факторов. С этой целью анализируется матрица парных коэффициентов корреляции, которая может быть получена в результате анализа данных по программе Excel (корреляция). Но коэффициент парной корреляции между факторами в матрице не превышает по своему значению коэффициенты парной корреляции результативного признака (выручки) с каждым из них, то в одну модель можно включать оба фактора. После установления вида уравнения необходимо исчислить показатели регрессионной связи. В частности, следует решить уравнение регрессии, то есть найти значения его параметров. При этом параметры уравнения должны быть определены способом наименьших квадратов, в соответствии с которым сумма квадратов отклонений фактических значений зависимой переменной от значений, определенных по уравнению, должна быть минимальной:
Для двухфакторной множественной модели линейного вида х0 =а0+а1 х1+а2 х2 система уравнений имеет следующий вид:
åх0 = n a0 + a1åх1 + a2åх2; åх0 х1 = a0åх1 + a1å åх0 х2 = a0åх2 + a1å х1х2 + a2åх22
Так как коэффициенты чистой регрессии несопоставимы между собой, во множественной регрессии возникает необходимость применения дополнительных показателей: коэффициентов эластичности, β-коэффициенты и коэффициенты отдельного определения. Коэффициенты эластичности определяются по формуле β-коэффициенты (бета-коэффициенты) определяют по формуле: Коэффициенты отдельного определения Сумма коэффициентов отдельного определения равна множественному коэффициенту детерминации:
После определения параметров уравнения должна быть дана количественная характеристика тесноты связи между переменными, включенными в уравнение. При парной линейной зависимости тесноту связи характеризуют коэффициентом детерминации (r 2) и коэффициентом корреляции (r), при множественной - соответственно, коэффициентом множественной детерминации (R 2) и коэффициентом множественной корреляции (R). Коэффициент детерминации может быть исчислен по следующей основной формуле: r 2 (R 2)= Следует помнить, что коэффициент детерминации показывает, какая доля общей вариации зависимой переменной обусловлена влиянием изучаемых независимых переменных; его величина заключена в пределах от 0 до 1. Соответственно и коэффициент корреляции, представляющий собой корень квадратный из коэффициента детерминации r (R) =
В практических расчетах для определения коэффициентов корреляции и детерминации используют ряд рабочих формул.
Е) Следующий этап работы- проверка статистических гипотез относительно показателей корреляционной связи и статистическая оценка показателей связи в генеральных совокупностях при парной линейной зависимости, т.к. корреляционный анализ проводится по данным выборочного наблюдения. Статистические гипотезы выдвигаются относительно коэффициентов регрессии и коэффициентов корреляции. Проверка осуществляется с помощью критерия t-Стьюдента. Нулевая гипотеза об отсутствии связи выручки с фактором и равенстве коэффициента регрессии в генеральной совокупности нулю имеет вид: Н0: Альтернативная гипотеза противоположна по содержанию На:
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-02-09; просмотров: 794; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.16.147.124 (0.109 с.) |
 или
или
 ) или на основе отдельных значений признака («структурные средние», в частности модальное значение признака (мода -
) или на основе отдельных значений признака («структурные средние», в частности модальное значение признака (мода -  ) – значение признака с наибольшей частотой встречаемости и медианное значение признака (медиана -
) – значение признака с наибольшей частотой встречаемости и медианное значение признака (медиана -  ) – значение признака, делящее ранжированный ряд единиц совокупности пополам).
) – значение признака, делящее ранжированный ряд единиц совокупности пополам).
 ) в интервальном ряду условно принимаются серединные значения интервалов. Срединные значения интервалов определяют как полусумму значений нижней и верхней границ интервалов.
) в интервальном ряду условно принимаются серединные значения интервалов. Срединные значения интервалов определяют как полусумму значений нижней и верхней границ интервалов. , где
, где .
.
 , позволяют получить относительные показатели вариации (коэффициент осцилляции, коэффициенты вариации).
, позволяют получить относительные показатели вариации (коэффициент осцилляции, коэффициенты вариации).



 fi
fi

 - средняя арифметическая,
- средняя арифметическая,
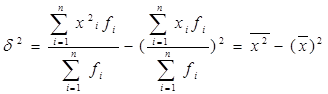




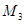 ) к среднему квадратичному отклонению в 3-ей степени (
) к среднему квадратичному отклонению в 3-ей степени ( )
) ,
,

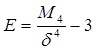 , где
, где 
 )
)
 где S1 2
где S1 2 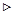 S2 2
S2 2 
 …
…  ), критическая область критерия определяется как Fфакт
), критическая область критерия определяется как Fфакт  Fα. Это означает, что если Fфакт
Fα. Это означает, что если Fфакт  Fα, нулевая гипотеза должна быть принята.
Fα, нулевая гипотеза должна быть принята. , (средние уровни выручки по группам с разными вложениями в генеральной совокупности равны);
, (средние уровни выручки по группам с разными вложениями в генеральной совокупности равны);

 (средние уровни выручки по группам с разными вложениями в генеральной совокупности не равны).
(средние уровни выручки по группам с разными вложениями в генеральной совокупности не равны).
 ,
,
 где S2межг.
где S2межг. 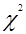 как критерия независимости.
как критерия независимости.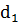
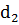
 факт.=
факт.= 
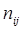 -фактические численности в группах и подгруппах
-фактические численности в группах и подгруппах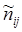 - ожидаемые (гипотетические) численности при верной нулевой гипотезе.
- ожидаемые (гипотетические) численности при верной нулевой гипотезе. ,
,  и
и  . Далее определяется удельный вес каждой группы в общей численности единиц (процентное отношение частот каждого интервала к общему числу единиц в совокупности -последняя графа табл.12). При расчете ожидаемых численностей исходим из нулевой гипотезы о независимости распределений и предполагаем, что распределение хозяйств в подгруппе А и Б одинаково и равно процентному отношению по совокупности в целом. Например, для ячейки I-a ожидаемая частота будет равна
. Далее определяется удельный вес каждой группы в общей численности единиц (процентное отношение частот каждого интервала к общему числу единиц в совокупности -последняя графа табл.12). При расчете ожидаемых численностей исходим из нулевой гипотезы о независимости распределений и предполагаем, что распределение хозяйств в подгруппе А и Б одинаково и равно процентному отношению по совокупности в целом. Например, для ячейки I-a ожидаемая частота будет равна  =
=  , для ячейки II-a ожидаемая частота будет равна
, для ячейки II-a ожидаемая частота будет равна 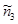 =
=  или разность (N-
или разность (N-  =
= 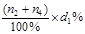 . Для ячейки II -б ожидаемая частота будет равна
. Для ячейки II -б ожидаемая частота будет равна  =
=  . Результаты расчетов ожидаемых численностей с округлением до целых (число предприятий - дискретная величина) целесообразно оформить в таблицу 13.
. Результаты расчетов ожидаемых численностей с округлением до целых (число предприятий - дискретная величина) целесообразно оформить в таблицу 13. )
)
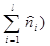
 .
.

 , где l - общее число интервалов в распределениях; k - число независимых ограничивающих линейных связей. l = ав, где а и в - число интервалов по каждому признаку; k = а + в -1. Тогда
, где l - общее число интервалов в распределениях; k - число независимых ограничивающих линейных связей. l = ав, где а и в - число интервалов по каждому признаку; k = а + в -1. Тогда  = ав - (а+ в - 1) = (а - 1)(в - 1). Для рассматриваемого примера
= ав - (а+ в - 1) = (а - 1)(в - 1). Для рассматриваемого примера  , между несколькими переменными (множественная связь) -
, между несколькими переменными (множественная связь) - 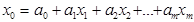 и т.д.
и т.д. - зависимая переменная,
- зависимая переменная,  - независимые переменные,
- независимые переменные,  - параметры уравнения. Параметр
- параметры уравнения. Параметр  - начало отсчета. В уравнении линейной парной связи параметр
- начало отсчета. В уравнении линейной парной связи параметр  называется коэффициентом полной регрессии; он показывает, на сколько единиц в среднем изменится значение зависимой переменной при изменении независимой на единицу. В уравнениях линейной множественной связи параметры
называется коэффициентом полной регрессии; он показывает, на сколько единиц в среднем изменится значение зависимой переменной при изменении независимой на единицу. В уравнениях линейной множественной связи параметры  называются коэффициентами чистой регрессии; каждый из них показывает, на сколько единиц в среднем изменится значение зависимой переменной при изменении соответствующей независимой переменной на единицу при условии, что другие независимые переменные, включенные в уравнение, не изменяются.
называются коэффициентами чистой регрессии; каждый из них показывает, на сколько единиц в среднем изменится значение зависимой переменной при изменении соответствующей независимой переменной на единицу при условии, что другие независимые переменные, включенные в уравнение, не изменяются. . Поэтому для определения параметров решают систему нормальных уравнений. Число нормальных уравнений в системе равно числу параметров уравнения регрессии. Так, для парной линейной связи, выраженной уравнением х0=а0+а1х1, где а0 и а1 - неизвестные параметры уравнения, система нормальных уравнений имеет вид:
. Поэтому для определения параметров решают систему нормальных уравнений. Число нормальных уравнений в системе равно числу параметров уравнения регрессии. Так, для парной линейной связи, выраженной уравнением х0=а0+а1х1, где а0 и а1 - неизвестные параметры уравнения, система нормальных уравнений имеет вид:
 + a2åх1х2;
+ a2åх1х2; и показывают, на сколько процентов изменится зависимая переменная при изменении независимой на 1 %.
и показывают, на сколько процентов изменится зависимая переменная при изменении независимой на 1 %.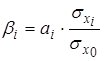 . Они показывают, на сколько среднеквадратических отклонений изменится зависимая переменная при изменении независимой переменной на свое среднеквадратичное отклонение.
. Они показывают, на сколько среднеквадратических отклонений изменится зависимая переменная при изменении независимой переменной на свое среднеквадратичное отклонение. рассчитываются по формуле
рассчитываются по формуле  , где
, где  - парные коэффициенты корреляции зависимой переменной с фактором;
- парные коэффициенты корреляции зависимой переменной с фактором; 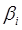 -бета-коэффициенты. Они показывают долю вариации зависимой переменной, обусловленную вариацией факторного признака.
-бета-коэффициенты. Они показывают долю вариации зависимой переменной, обусловленную вариацией факторного признака. +
+  =
= 
 ., где
., где 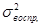 . - дисперсия воспроизведенная, характеризующая колеблемость зависимой переменной под влиянием независимых переменных, включенных в уравнение регрессии;
. - дисперсия воспроизведенная, характеризующая колеблемость зависимой переменной под влиянием независимых переменных, включенных в уравнение регрессии;  о - общая дисперсия зависимой переменной.
о - общая дисперсия зависимой переменной. изменяется от 0 до 1. Знаки "+" и " - " при коэффициенте парной связи означает направление связи; "+" - связь прямая, "-" - связь обратная. Равенство коэффициентов нулю означает, что связь между переменными отсутствует, равенство коэффициентов единице означает, что между переменными существует функциональная зависимость. Анализ градаций коэффициента корреляции по шкале Чеддока позволяет дать характеристику тесноты связи:
изменяется от 0 до 1. Знаки "+" и " - " при коэффициенте парной связи означает направление связи; "+" - связь прямая, "-" - связь обратная. Равенство коэффициентов нулю означает, что связь между переменными отсутствует, равенство коэффициентов единице означает, что между переменными существует функциональная зависимость. Анализ градаций коэффициента корреляции по шкале Чеддока позволяет дать характеристику тесноты связи:
 -Коэффициент корреляции при парной линейной связи
-Коэффициент корреляции при парной линейной связи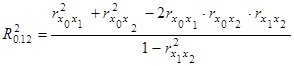 - Коэффициент детерминации при множественной линейной связи зависимой переменной с двумя факторами.
- Коэффициент детерминации при множественной линейной связи зависимой переменной с двумя факторами. = 0;
= 0; .
.


