
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Модели данных и этапы проектирования баз данных.Содержание книги
Поиск на нашем сайте
Учебник По базам данным
· 2. язык SQL 1. История развития и стандарты. 2. Наборы команд SQL. 3. Оператор SELECT. 4. Операторы определения данных (основные сведения). 5. Операторы манипулирования данными. · 3. СУБД MS SQL Server и язык Transact -SQL 1. Введение в SQL Server. 2. Типы данных, управляющие конструкции языка и функции Transact-SQL. 3. Объекты баз данных и работа с ними. 4. Физическая модель данных MS SQL Server. 5. Система безопасности и администрирование SQL Server. 6. Перспективы MS SQL Server. · 4. Коллекция СУБД. 1. СУБД dBase. Хранение данных в формате DBF. · 5. Введение в FoxPro 6. 1. История Visual FoxPro и основные особенности шестой версии. 2. Язык программирования FoxBASE. 3. Основные команды FoxBASE. 4. Разработка форм в FoxPro 6. 5. Разработка отчётов в FoxPro 6. 6. Создание исполняемых модулей в FoxPro 6. · 6. Microsoft Access 2002. Общие сведения. 1. Общие сведения. 2. Объекты Microsoft Access. 3. Средства программирования. 4. Спецификации Microsoft Access. 5. Типы данных, которые могут иметь поля в Microsoft Access 6. Импорт и экспорт данных. · 7. Программирование в VBA (Visual Basic for Application) 1. Общие сведения. 2. Типы переменных 3. Доступность 4. Обработка ошибок 5. Ветвления и циклы 6. Параметры процедур и функций. 7. Работа со строками 8. Простейшие программы на VBA 9. Задание свойств форм, отчетов и элементов управления 10. DAO и ADO. 11. Общение с JET через объекты данных Access. 12. Использование объекта TableDef 13. Использование объекта Recordset 14. Примеры использования методов DAO 15. Программирование в формах. · 8. Методы организации удалённого доступа к данным. 1. Интернет-доступ к базам данных. 2. Доступ к базам данных с помощью языка ASP. 3. Доступ к базам данных с помощью языка РНР. 4. Иные технологии. · 9. СУБД MySQL. · 10. Перспективы развития СУБД. 1. Недостатки реляционной модели. 2. Интеллектуальный анализ данных (data mining) 3. Постреляционные базы данных. 4. Отказ от нормализации отношений. 5. Объектно-реляционные базы данных. 6. Язык SQL-3 и СУБД Oracle 8. 7. Объектно-ориентированные базы данных. Информационные системы. Можно выделить две основные области использования вычислительной техники. Первая область – выполнение численных расчетов, которые слишком долго или вообще невозможно производить вручную. Вторая область – это так называемые информационные системы, предназначенные для обработки информации. ”Практически все окружающие человека системы в той или иной степени связаны с функциями долговременного хранения и обработки информации. Фактически информация становится фактором, определяющим эффективность любой сферы деятельности.” Информационная система (ИС) – взаимосвязанная совокупность средств, методов и персонала, используемая для хранения, обработки и представления информации. К функциям информационных систем относятся:
контроль правильности информации Различают два основных класса ИС: информационно-поисковые (развитой поиск данных по определённому критерию), системы обработки данных (пользователя интересует результат обработки, а не сами исходные данные). Виды информационных систем: фактографические (регистрируются конкретные значения данных об объектах реального мира с точной структуризацией) и документальные (содержат совокупность текстовых документов и графических объектов с приблизительным поиском).
Структурирование информации – введение каких-либо соглашений о способах представления данных. Первоначально проблема структурирования информации решалась путём построения файловой системы, каждый элемент которой являлся ответственным за хранение определённого вида информации. Однако файловые системы обеспечивают хранение слабо структурированной информации, оставляя дальнейшую структуризацию прикладным программам. Конечному пользователю не нужно знать:
о механизмах поддержания баз данных в актуальном состоянии
Терминология СУБД. Система управления базами данных (СУБД) – это комплекс программных и языковых средств, необходимых для создания баз данных, поддержания их в актуальном состоянии и организации поиска в них необходимой информации. Основная особенность СУБД – наличие процедур для ввода и хранения не только данных, но и описаний их структуры. В широком смысле база данных:
Файлы, снабжённые описанием хранимых в них данных и находящиеся под управлением СУБД.
Понятие согласованности данных является ключевым понятием баз данных. Если некая информационная система поддерживает согласованное хранение информации в нескольких файлах, можно говорить о том, что она поддерживает базу данных. Если же при этом допускается модификация данных в этих файлах – то это СУБД. “При рассмотрении приложений, работающих с одной базой данных, предполагается, что они могут работать параллельно и независимо друг от друга, и именно СУБД призвана обеспечить работу множества приложений с единой базой данных таким образом, чтобы каждое из них выполнялось корректно, но учитывало все изменения в базе данных, вносимые другими приложениями.” Назначение СУБД:
желательно, чтобы в СУБД были реализованы механизмы оптимизации выполнения перечисленных выше операций. То есть должен быть в наличии компонент, отвечающий за максимальную эффективность выполнения СУБД своих функций. Централизованная БД хранится в памяти одной вычислительной системы. При этом база данных располагается на одном компьютере. Если для этого компьютера установлена поддержка сети, то множество пользователей с клиентских компьютеров могут одновременно обращаться к информации, хранящейся в центральной базе данных. В локальных сетях чаще всего используется именно такой способ обработки данных. Распределённая БДсостоит из нескольких серверов, хранимых в различных ЭВМ, связанных сетями между собой. В таких БД может храниться пересекающаяся или дублирующаяся информация. Для работы с такой базой данных используется система управления распределёнными базами данных (СУРБД). Файловый сервер – на одном из компьютеров располагается банк данных – файлы, которые могут совместно обрабатывать несколько различных СУБД пользователей. После обработки на компьютерах клиентов, файлы копируются обратно на сервер. Технология «клиент-сервер» подразумевает, что помимо хранения базы данных центральный компьютер (сервер базы данных) должен ещё и обеспечивать выполнение основного объёма обработки этих данных. Запрос клиента (программы-клиента) на выполнение какой-либо операции с данными провоцирует на сервере поиск и извлечение данных. Клиентская часть (Front - End) обеспечивает графический интерфейс и находится на компьютере пользователя; серверная часть (Back - End) обеспечивает управление данными, разделение информации, администрирование и безопасность. Примерами СУБД, работающих по технологии клиент-сервер, являются MS SQL Server, Oracle, IBM DB 2, SyBase. Функции СУБД:
Поддержка языков баз данных Транзакция – последовательность операций над БД, рассматриваемых СУБД как единое целое. Реализация аппарата транзакций необходимо для поддержания логической целостности БД. Сериализация транзакций – такой порядок их выполнения, при котором суммарный эффект смеси транзакций эквивалентен эффекту их некоторого последовательного выполнения.
Модели доступа к данным. Помимо разделения баз данных по методам обработки, можно классифицировать их по используемой модели (или структуре) данных. С помощью модели данных можно наглядно представить структуру объектов и установленные между ними связи. Модель данных непосредственно определяет наименование СУБД.
Иерархическая модель появилась первой среди всех даталогических моделей: именно эту модель поддерживала первая из зарегистрированных промышленных СУБД IMS (Information Management System) IBM (1968 год). Каждая физическая база описывается набором операторов, определяющих как её логическую структуру, так и структуру хранения баз данных.
элемент (потомок) может иметь более одного порождающего элемента (предка). Сетевая БД может представлять непосредственно все виды связей, присущих данным. По этим данным можно перемещаться, исследовать и запрашивать их всевозможными способами. Однако любой запрос к сетевой БД предполагает выработку собственного механизма навигации по этой базе. При этом автоматически целостность данных СУБД не поддерживается. Базовыми понятиями модели являются: Элемент данных – минимальная информационная единица, доступная пользователю с использованием СУБД. Агрегат – поименованный набор данных. Агрегат данных типа «вектор» - линейный набор элементов данных (например агрегат «Адрес: город, улица, дом, квартира»). Агрегат данных типа «повторяющаяся группа» соответствует совокупности векторов данных. Например, агрегат «Зарплата: месяц, сумма (х 12)». Записью называется совокупность агрегатов или элементов данных, моделирующая некоторый класс объектов реального мира. Для записи вводятся понятия типа записи и экземпляра записи. Связь или набор – двухуровневый граф, связывающий отношением «один-ко-многим» два типа записи. Связи именуются. Для любых двух типов записей может быть задано любое количество связей. Некоторые правила и термины построения сетевой модели: Тип связи L определяется для типа записи предка P и потомка C. Экземпляр типа связи состоит из одного экземпляра типа записи предка и упорядоченного набора экземпляров типа записи потомка. При этом (1) каждый экземпляр типа P является предком только в одном экземпляре L; (2) Каждый экземпляр C является потомком не более чем в одном экземпляре L. Следствия таких правил таковы:
Одни и те же типы записей могут быть предком и потомком в связи L 1 и потомком и предком в связи L 2. Стандарт сетевой модели впервые был определен в 1975 году организацией CODASYL (Conference of Data System Language), которая определила базовые понятия модели и формальный язык описания. Типичным представителем является Integrated Database Management System (IDMS) компании Cullinet Software, Inc. Реляционная модель. Основная идея реляционной модели данных заключается в том, чтобы представить любой набор данных в виде двумерной таблицы. В простейшем случае реляционная модель описывает единственную двумерную таблицу, но чаще всего эта модель описывает структуру и взаимоотношения между несколькими таблицами. Реляционная модель не позволяет корректно представить данные, имеющие собственную сложную структуру. Создание реляционных отношений для таких данных может привести к потере значимых связей между данными. Примеры широко известных реляционных БД: MS FoxPro, MS Access. Объектно-ориентированная модель. Её структура описывается с помощью трёх ключевых понятий:
Особенностью ООБД является невозможность применения к хранимым объектам понятий и алгоритмов реляционной модели. В этой связи необходим некоторый процедурный язык для оформления запросов и обработки данных. Обеспечение целостности данных заключается в (1) автоматической поддержке отношений наследования; (2) возможности объявлять поля и методы объекта как «скрытые» (т.е. невидимые для других объектов); (3) реализовывать процедуры контроля целостности данных внутри объектов. Примеры ООБД: Cach e, FastObjects, GemStone / S, Jasmine, к ним примыкает объектно-реляционная СУБД PostgeSQL.
Отношение находится во второй нормальной форме тогда и только тогда, когда оно находится в первой нормальной форме и не содержит неполных функциональных зависимостей непервичных атрибутов от атрибутов первичного ключа. Функциональная зависимость R. A ® R. B называется полной, если набор атрибутов В функционально зависит от А, но не зависит функционально от любого подмножества А, то есть если " А 1 I А? R. A –/ ® R. B. В противном случае функциональная зависимость называется неполной. Пример отношения, которое НЕ находится во 2 NF: результаты сессии. Рассмотрим отношение R (ФИО, номер зачетки, группа, дисциплина, оценка). Первичный ключ подчеркнут. Однако при этом атрибуты (ФИО, группа) зависят только от части первичного ключа – от атрибута (номер зачетки). При этом возможны следующие аномалии: - в результате ошибки оператора студенту по результатам одного или нескольких экзаменов приписали не ту группу. - если студент не сдал ни одного экзамена, то он не существует. Для приведения отношения во 2 NF следует провести декомпозицию (разбить на проекции), например так: 1. R 1 (ФИО, номер зачетки, группа). 2. R 2 (номер зачетки, дисциплина, оценка). Приведение таблицы ко второй нормальной форме позволяет избежать повторения (избыточности) данных.
Отношение R находится в пятой нормальной форме (нормальной форме проекции-соединения) в том и только в том случае, когда любая зависимость соединения в R следует из существования некоторого возможного ключа в R. Определение: Отношение R (A, B, … Z) удовлетворяет зависимости соединения (А, B, … Z) в том и только в том случае, когда R восстанавливается без потерь путём соединения своих проекций на A, B, … Z (наборы атрибутов отношения R). Полной декомпозицией отношения называют такую совокупность произвольного числа его проекций, соединение которых полностью совпадает с содержимым исходного отношения. Иными словами, отношение находится в пятой нормальной форме тогда и только тогда, когда в каждой его полной декомпозиции все проекции содержат возможный ключ. Пример отношения, которое находится в 4 NF, но НЕ находится в 5 NF: почасовики. Дано отношение: R (преподаватель, кафедра, дисциплина). Считается, что приглашённый преподаватель может работать на нескольких кафедрах и вести различные дисциплины. В этом случае ключом отношения является полный набор из трёх атрибутов. В отношении отсутствуют многозначные зависимости, и поэтому оно находится в 4 NF. Однако в нём нет наборов атрибутов, которые составляют возможные ключи отношения, и потому это отношение не в PJ / NF. При этом провести полную декомпозицию на два отношения нельзя. Возможна декомпозиция следующего вида: 1. R 1 (преподаватель, кафедра). 2. R 2 (преподаватель, дисциплина). 3. R3 (кафедра, дисциплина). Отношение, не имеющее ни одной полной декомпозиции, также находится в пятой нормальной форме. Задание: провести нормализацию отношения «продажи магазина»: R (дата продажи, фамилия и имя продавца, фамилия и имя покупателя, город, улица, наименование товара, сумма). Наборы команд SQL. Подмножества команд SQL (перечислены не все): 1) DDL – Data Definition Language – язык определения данных.
2) DMP – Data Manipulation Language – язык манипулирования данными.
3) DQL – Data Query Language – язык запросов.
4) TCS – Transactional Control Statement – c редства управления транзакциями.
5) Средства администрирования данных.
Оператор SELECT. Весь запрос SELECT разбивается на отдельные разделы, каждый из которых имеет своё назначение. Большая часть этих разделов может быть опущена. Упрощённый вариант синтаксиса оператора SELECT: 1 SELECT [ALL | DISTINCT] < список вывода > 2 [ INTO <имя новой таблицы> ] 3 FROM <список таблиц и условий соединения> 4 [ WHERE <условие отбора или соединения> ] 5 [ GROUP BY <список полей группировки> ] 6 [ HAVING <условия, накладываемые на группу> ] 7 [ ORDER BY <список полей для сортировки вывода> ] 8 [ UNION <запрос на выборку для объединения>] 9 … <список вывода>::= { * | [<имя таблицы> | <алиас>.] {<имя столбца> | <выражение>} [ AS <алиас>] | <имя столбца> = <выражение> } [… n ] Символ звёздочка означает, что в результирующий набор включаются все столбцы из указанных исходных таблиц: SELECT * FROM publishers Декартово произведение отношений: SELECT * FROM publishers, authors ALL – в результирующий набор включаются все строки, удовлетворяющие условиям запроса, даже если среди них будут одинаковые (?!, то есть полученное отношение не удовлетворяет требованиям реляционной алгебры). SELECT ALL p.country FROM publishers AS p DISTINCT – в результирующий набор включаются только уникальные строки. Если в результат выборки включаются несколько столбцов, то уникальность будет определяться по значениям обоих этих столбцов. SELECT DISTINCT state, contract FROM authors Простейшие вычисления в разделе SELECT: SELECT ' Название книги: ', title, yearpub-1992 FROM titles WHERE yearpub > 1992; Раздел WHERE предназначен для наложения горизонтальных фильтров на данные, обрабатываемые запросом. Для этого указывается логическое условие, от результата вычисления которого зависит, будет ли строка включена в результат выборки или нет. SELECT au_lname, au_fname, state FROM authors WHERE state<>'CA' Предикаты, используемые в условных конструкциях SQL: 1) Предикаты сравнения: =, <>, <, >, >=, <=; SELECT * FROM authors WHERE 1=1 2) AND – соединение нескольких логических выражений; SELECT title FROM titles WHERE yearpub>=1995 AND yearpub<=1997 3) OR – если одно из двух условий истинно, то результат True; SELECT title FROM titles WHERE yearpub<1995 OR yearpub>1997 4) NOT – отрицание, может ставиться непосредственно перед нижеследующими предикатами; 5) Предикат диапазона: Between A and B – принимает значение True, если сравниваемое значение лежит между A и В; SELECT title FROM titles WHERE yearpub NOT BETWEEN 1995 AND 1997 6) Вхождение во множество: IN (<список значений>) – принимает True, если сравниваемое значение входит во множество заданных значений; SELECT title FROM titles WHERE yearpub IN (1995, 1996, 1997) 7) Сравнение с образцом: LIKE. В шаблон могут входить специальные символы «_» – для обозначения любого одиночного символа, и «%» – для обозначения произвольной последовательности символов; SELECT publisher, url FROM publishers WHERE publisher LIKE ‘%Wiley%' 8) Предикат сравнения с неопределённым значением: IS NULL. SELECT publisher, “url not defined!” FROM publishers WHERE url IS NULL Связь между таблицами с использованием раздела WHERE (стандарт SQL 89) Представим ситуацию, когда выборку данных надо производить из отношения, которое является результатом слияния нескольких отношений. При отсутствии соединения в разделе WHERE результат будет эквивалентен расширенному декартовому произведению отношений. Обычно всегда в случае использования нескольких таблиц имени поля предшествует имя таблицы во всех разделах оператора SELECT. SELECT titles.title, titles.yearpub, publishers.publisher FROM titles, publishers WHERE titles.pub_id = publishers.pub_id AND titles.yearpub>1996 В данном запросе в разделе WHERE указаны условия связи и условия фильтрации данных. Связь между таблицами с использованием раздела FROM (стандарт SQL 2, внешние объединения) С помощью раздела FROM определяются источники данных, с которыми будет работать запрос. Связи между отношениями в этом разделе реализуются как одна или несколько вложенных связей между левой и правой таблицами по одному или нескольким полям. 1. [INNER] JOIN. Данный тип связи используется по умолчанию. Строки левой таблицы, для которых не имеется пары в правой таблице, в результат выборки не включаются. Строки правой таблицы, для которых не имеется пары в левой таблице, также в результат не включаются. 2. LEFT [ OUTER ] JOIN. Все строки левой таблицы включаются в результат выборки. При этом, если отсутствуют строки в правой таблице, то в соответствующих столбцах правой таблицы, включенных в результат запроса, будет установлено значение NULL. Строки правой таблицы, для которых не имеется пары в левой таблице, в результат не включаются. 3. RIGHT [ OUTER ] JOIN. Все строки правой таблицы включаются в результат выборки. Для соответствующих столбцов левой таблицы, включенных в запрос, устанавливается значение NULL. Строки левой таблицы, для которых не имеется пары в левой таблице, в результат не включаются. 4. FULL [ OUTER ] JOIN. В результат будут включены все строки как левой, так и правой таблицы. 5. CROSS JOIN – выражение эквивалентно просто запятой между таблицами. Пример связи двух таблиц: SELECT authors.au_lname, authors.au_fname, titleauthor.royalty FROM authors INNER JOIN titleauthor ON authors.au_id = titleauthor.au_id WHERE authors.state='CA' Если бы мы хотели узреть и тех авторов из штата Калифорния, которые не получили гонорар, то надо было бы использовать конструкцию LEFT JOIN Пример связи нескольких таблиц: SELECT countries.name_rus AS страна, subjects.name_rus AS регион, msu.name_rus AS район, data.year AS год FROM data INNER JOIN subjects ON data.subject = subjects.subject INNER JOIN msu ON data.msu = msu.id_msu INNER JOIN countries ON subjects.country = countries.country Раздел GROUP BY позволяет выполнять группировку строк таблиц по определённым критериям. Типичным примером использования GROUP BY является суммирование однотипных значений. GROUP BY почти всегда используется вместе с функциями агрегирования. GROUP BY разделяет таблицу на группы, а функция агрегирования вычисляет для каждой из них итоговое значение. Основные функции агрегирования:
Следующий запрос определяет количество книг каждого издательства, зарегистрированных в базе данных: SELECT publishers.publisher, COUNT(titles.title) FROM titles, publishers WHERE titles.pub_id = publishers.pub_id GROUP BY publisher Правила использования группировок в запросах: 1) Функции агрегирования не работают со значениями NULL. 2) В разделе SELECT (т.е. для вывода) можно указывать только те поля, по которым осуществляется группировка. Чтобы вывести значения столбцов, не указанных в критериях группировки, необходимо применять к ним функции агрегирования. 3) Раздел WHERE не допускает использования функций агрегирования. Ещё один пример: подсчитать, сколько записей ввёл каждый из операторов по каждому региону за 2003 год. SELECT max(subjects.name_rus) as [ субъект ], COUNT(*) AS [ количество записей ], max(users.u_name) as [ оператор ] FROM subjects, data, users WHERE data.subject = subjects.subject and data.id_user = users.id_user and data.year=2003 GROUP BY data.subject, data.id_user ORDER BY [ субъект ] Если при выполнении группировки используется раздел WHERE, то возможно появление групп, не содержащих ни одной строки. По умолчанию эти группы не включаются в результат выборки. Однако если необходимо вывести все без исключения группы, то используется вариант GROUP BY ALL. При этом для групп, не содержащих ни одной строки, не выполняются функции агрегирования, вместо которых выводится значение NULL. Простой запрос, использующий функцию агрегирования без группировки: SELECT Count(*) FROM data Раздел HAVING. Этот раздел практически аналогичен по назначению с разделом WHERE (горизонтальная фильтрация), однако используется для задания условий групповой фильтрации. В этом разделе допускается использование функций агрегирования. Определим количество книг каждого издательства, исключая случаи единственного экземпляра. SELECT publishers.publisher, COUNT(titles.title) FROM titles, publishers WHERE titles.pub_id = publishers.pub_id GROUP BY publisher HAVING COUNT (*)>1; Другой пример: получить номера деталей, суммарное количество которых на складе превышает 400 шт. SELECT number, SUM(volume) FROM warehouse GROUP BY number HAVING SUM(volume)>400 Раздел ORDER BY предназначен для упорядочения набора данных, возвращаемых после выполнения запроса. Используются ключевые слова ASC (по возрастанию, используется по умолчанию) и DESC (по убыванию). При этом в сортировке могут участвовать столбцы, не входящие в раздел SELECT. Приоритет в сортировке по столбцам, указанным первыми. SELECT data.* FROM data ORDER BY subject, msu, year Раздел UNION служит для объединения результатов выборки, возвращаемых двумя и более запросами. Это может быть выборка из одной таблицы или слияние данных из множества таблиц. Иными словами, раздел UNION вставляется между двумя запросами, возвращающими одинаковый набор столбцов. В результат будут включены строки как первого, так и второго запроса. По умолчанию дублирующие строки в результат не включаются. SELECT publisher, url FROM publishers UNION SELECT site, url FROM wwwsites Использование вложенных запросов. Команда SELECT позволяет использовать подзапросы в предикатах главного (т.е. в разделах WHERE и HAVING). Совместно с подзапросом можно использовать предикат EXIST, который возвращает истину, если вывод подзапроса не пуст. Задача: найти названия всех изданий, выпущенные издательством «Wiley» SELECT title FROM titles WHERE pub_id IN (SELECT pub_id FROM publishers WHERE publisher='Wiley'); Более сложные задачи: даны отношения Supplier s (id _ supplier, name) – поставщики (код поставщика, ФИО поставщика) Supply (id _ supplier, number) – поставки (код поставщика, номер детали) Components (number, title) – детали (номер детали, наименование детали). 1. Найти имена поставщиков, которые поставляют все детали из занесённых в базу. SELECT MAX(suppliers.name) FROM suppliers, supply WHERE suppliers.id_supplier=supply.id_supplier GROUP BY supply.id_supplier HAVING COUNT(DISTINCT supply.number) = ( SELECT COUNT(number) FROM components) 2. Получить список поставщиков, поставляющих деталь с номером 222. SELECT * FROM suppliers WHERE EXIST (SELECT * FROM supply WHERE suppliers.id_supplier = supply.id_supplier AND supply.number = 222); Такие подзапросы называются коррелируемыми (correlated). Внешняя ссылка может принимать различные значения для каждой строки-кандидата, оцениваемого с помощью подзапроса, поэтому подзапрос должен выполняться заново для каждой строки, отбираемой в основном запросе. Простой пример: контроль ссылочной целостности вручную: SELECT * FROM data WHERE item NOT IN (SELECT item FROM items) Реализация реляционной алгебры средствами оператора SELECT (Реляционная полнота SQL) Для того, чтобы показать, что язык SQL является реляционно полным, нужно показать, что любой реляционный оператор может быть выражен средствами SQL.
2,4 Операторы определения данных (основные сведения). Введение в SQL Server. Microsoft SQL Server 2000, на базе которого будет строиться дальнейшее изложение, является реляционной СУБД, поддерживающей технологию клиент-сервер вплоть до создания распределённых баз данных в масштабе локальной или глобальной компьютерной сети. SQL Server позволяет создавать базы данных различного масштаба: от уровня домашней сети до корпоративного. По уровню значимости основным конкурентом SQL Server, которому обычно отдаётся первое место по многим показателям, является Oracle Corporation. Краткая история: 1. В 1988 году Microsoft и Ashton-Tate анонсировали первую версию Microsoft SQL Server — реляционную СУБД для локальных вычислительных сетей. Новый продукт носил название Ashton-Tate/Microsoft SQL Server и представлял собой версию Sybase DataServer для OS/2. Роль Ashton-Tate заключалась в том, что эта фирма предоставила dBASE IV, используемую для разработки приложений. 2. В 1992 выпущен SQL Server 4.2 — 16-разрядная СУБД, результат совместной работы Microsoft и Sybase. В этой СУБД были реализованы клиентские библиотеки для MS-DOS, Windows и OS/2, помимо этого в нее впервые были включены средства администрирования с графическим интерфейсом под управлением Windows. 3. В 1996 году выпущен SQL Server версии 6.5, обладавший встроенной поддержкой Web-приложений, средствами распределенного администрирования, наличием динамических блокировок. 4. 1998 — выпущен Microsoft SQL Server 7.0 с радикально измененной архитектурой. Это была первая версия SQL Server, не содержавшая унаследованного кода, оставшегося со времен сотрудничества с Sybase. Особо стоит отметить появление в этой версии OLAP-служб (служб анализа данных) в составе продукта (до этого серверные OLAP-средства, производимые поставщиками серверных СУБД, включая и Oracle, продавались исключительно как отдельные продукты и относились к категории весьма дорогостоящего программного обеспечения). 5. В 2000 – выпущен Microsoft SQL Server 2000, поддерживающий XML (eXtensible Markup Language, расширяемый язык разметки), а также содержащий множество нововведений в административных утилитах. Версия Microsoft SQL Server 2000 построена на основе ядра Microsoft SQL Server 7.0. Ее отличительными особенностями являются повышенная масштабируемость, производительность и интеграция с Internet. Одним из главных событий, определивших дальнейшую судьбу Microsoft SQL Server, стало решение Microsoft сосредоточить усилия исключительно на поддержке только платформы Windows NT. Эта СУБД настолько связана с операционной системой, что ее надежность, масштабируемость и производительность определяются надежностью, масштабируемостью и производительностью самой платформы, и положение SQL Server на рынке будет зависеть от выпуска новых версий Windows. Рекомендуемая платформа: Windows 2000 Server. Одним из преимуществ SQL Server является простота его применения, в частности администрирования. SQL Server Enterprise Manager, входящий в состав всех редакций Microsoft SQL Server, представляет собой полнофункциональное и достаточно простое
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-02-08; просмотров: 429; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.137 (0.017 с.) |


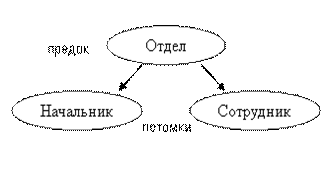 Иерархическая модель. БД состоит из упорядоченного набора древовидных структур данных. Организационные структуры, списки материалов, оглавления в книгах, планы проектов и многие другие совокупности данных могут быть представлены в иерархическом виде. При этом автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя, причём потомок имеет единственного родителя. Недостатком модели является сложность реорганизации данных и невозможность выполнения «горизонтальных» запросов к данным, не связанных с иерархической структурой.
Иерархическая модель. БД состоит из упорядоченного набора древовидных структур данных. Организационные структуры, списки материалов, оглавления в книгах, планы проектов и многие другие совокупности данных могут быть представлены в иерархическом виде. При этом автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя, причём потомок имеет единственного родителя. Недостатком модели является сложность реорганизации данных и невозможность выполнения «горизонтальных» запросов к данным, не связанных с иерархической структурой. Сетевая модель. Является расширением иерархической модели. Здесь каждый порождённый
Сетевая модель. Является расширением иерархической модели. Здесь каждый порождённый


