
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Characteristic features of the Grammatical CategoryСодержание книги
Похожие статьи вашей тематики
Поиск на нашем сайте
1) GC is based on the opposition of 2 or more form classes (are members of opposition). The opposite members are opposed to each other in form and in meaning. But these 2 things always should be present. When we look at the difference in form we point out the marked or the strong member of the opposition and unmarked or the weak member of the opposition. The marked member has the certain marker, which is a form-building signal. The unmarked member has no marker or zero morpheme. When we point out the marked member of the opposition we point out the difference in form. The next thing to do is to point out the difference in meaning: Grammatical meaning of the marked member is described first, because it's easier to define. Unmarked is difficult, in this case it's defined negatively. We say that the unmarked member doesn't express the meaning of the marked member. 2) Within one and the same GC the members of the opposition are mutually excluding. It means that a form of one form-class can't express the meaning of the opposite form-class = 2 opposite grammatical meanings of the same category can't be expressed, can't coexist in one form. Ex: sheep (Sg) - sheep (PI) => 2 different forms (homonyms), we understand meaning from the context, according to verb. Бархударов used this feature to prove that the Future Tense doesn’t exist. He analyzed the form of the Future-in-the Past, which expresses both a future and a past action. If these actions are expressed in one form that proves that Future-in-the Past don't belong to the category of tense. Смирницкий used it to prove that the Perfect belongs neither to the category of tense nor aspect. For that purpose he analyzed the form of the Perfect Continuous. 3) Within different GCs a word form can be opposed to a number of word-forms within diff grammatical categories.
Chapter 3. Morphemic structure of the word. In accord with the allo-emic theory lingual units may be described by means of 2 types of term allo-terms and eme-terms. Eme-terms denotes the generalized invariant: phonemes, morphemes. Allo-terms are concrete manifestations of variants: allo-forms, allomorphes. A set of allo-units is one eme-unit. The allo-emic identification of lingual elements is achieved by means of distributional analysis. The aim of this analysis is to fix and study the language unit in relation to the textual environment. The environment of the unit may be right or left. E.x. un-pardon-able (left environment of the root) The left environment of the root is the negative prefix –un, the right environment of the root is the qualitative suffix –able. Respectively, the root –pardon- is the right environment for the prefix, and the left environment for the suffix. The analysis is conducted in 2 stages: 1. The analyzed text is divided into segments consisting of phonemes. They are called morphs 2. We establish the environment of the morphs and define the type distribution.
· contrastive (the environment of the morphs are the same, but meaning are different) · non-contrastive (if their meaning is the same suffix; ex.ed-t: learned-learnt) · complementary (concerns different environments of different morphs, but their meaning ex: dogs-oxen) Notion of the morpheme. Morpheme – is one of the central notions of grammatical theory, without which no serious attempt at grammatical study can be made. Morpheme is the smallest meaningful unit of the language. There may be zero morphemes that is the absence of morpheme. It indicates certain meanings (book-books). Zero morphemes indicate singular form, s-morpheme - plurality. In traditional grammar the study of the morpheme was conducted in the light of 2 criteria (positional and semantic). The combination of these criteria gives us a classification of morphemes. According to their position morphemes can be prepositional (prefix), central (root)and postpositional (suffixes and inflexions).
Traditionally the following types of morphemes are distinguished:
Root morphemes Affixal morphemes (affixes) - prefixes - suffixes - inflections (grammatical suffixes)
Prefixes, root-morphemes, lexical suffixes are lexical morphemes in English. Only grammatical suffixes (inflections) are form-building means in English. (Russian suffixes and prefixes are form-building) It's necessary to distinguish between form-building and word-building means. Word-building means express notions. e.g. work – worker –> -er – lexical suffix workable –> -able – lex. suffix
They build new words, they're treated in Lexicology. Form-building means are means of building up new forms of words. They are treated in grammar (morphology). Both form-building and word-building affixes can be:
productive non-productive -er; -or; -ent; -ness -dom; -hood (lex. suffixes) -(e)s; -(e)d; -ing; -er, -est -en; -em (grammatical suffixes)
Both word-building and form-building suffixes can be polysemantic: e.g. -ly (lex. suff) can build adj, adv. => loudly – adv.; friendly – adj. -s (es) (grammatical suff.) forms plural/singular of nouns + possessive case. According to semantic criteria roots are the bearers of meaning. Prefix and suffixes-have lexico-semantic function. Inflexions have no lexical meaning or function, however an inflexion morpheme can get a lexical meaning in some special cases (colour-colours // custom-customs)-lexicalization. There are some cases when one and the same morpheme may function as an inflexion and suffix (morpheme-ing-as a suffix deriving verbal nouns has inflexion forming gerund/non-finite verbal forms. Suffix is a morpheme coming after the root, it may be applied to derivation post root morpheme. Inflexion is any morpheme deriving a form of a word and having no lexical meaning. Inflexion is a morpheme expressing case and number in nouns and person and number in verbs. Morphemes can be: -free and bound. Bound morphemes cannot form words by themselves, they are identified only as component segmental parts of words. On the contrary, free morphemes can build up words by themselves, i.e. can be used “freely”. e.g. handful – the root hand is a free morpheme, the suffix –ful is a bound morpheme. -overt and covert. Overt morphemes are genuine, explicit morphemes building up words; the covert morpheme is identified as a contrastive absence of morpheme expressing a certain function. The notion of covert morpheme coincides with the notion of zero morpheme in the oppositional description of grammatical categories. e.g. clock-s- 2 morphemes (a lexical morpheme and a grammatical one) clock-Ø – 2 morphemes (the overt root and the covert (implicit) zero morpheme Ø) -segmental and suprasegmental. Supra-segmental morphemes are intonation contours, accents, pauses. -additive. Additive morphemes are outer grammatical suffixes, as they are opposed to the absence of morphemes in grammatical alternation: e.g. look-ed; small-er. On the basis of linear characteristics, “continuous (linear)” morphemes and “discontinuous” morphemes are distinguished. The discontinuous morpheme is a 2-element grammatical unit, which is the analytical from comprising an auxiliary word and a grammatical suffix: · e.g. be … ing – is going (continuous) · have … en – has gone (perfect) · be … en – is taken (passive) Continuous morpheme is uninterruptedly expressed.
|
|||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-02-17; просмотров: 632; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.145.75.69 (0.01 с.) |

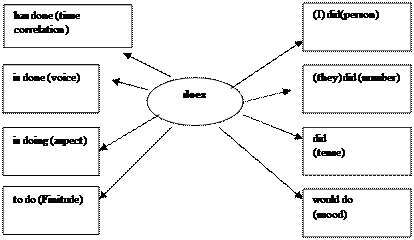



 Morphemes
Morphemes





