Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Лекция 32. Индексы, фильтрация, отчетность
В этой лекции мы закончим работу над проектом "Библиотечный каталог". Научимся создавать индексы, производить по ним фильтрацию (поиск) данных, выводить данные в отчет. Научимся создавать подстановочные поля – вводить в таблицу новое поле, из другой таблицы. Индексы Первичный (основной) ключ программы служит для того, чтобы записи в таблице сортировались по возрастанию этого ключа. Если мы не указали первичного ключа, то данные будут выводиться в том порядке, в каком их ввел пользователь. Однако бывает, когда необходимо отсортировать данные по одному или по другому полю, для этого используют вторичные ключи – индексы. Индексов может быть много, они могут содержать одно поле таблицы или несколько. Если вы указываете в индексе только одно поле, то при применении индекса таблица будет отсортирована по этому полю. Если вы указываете два индексных поля, то вначале сортировка будет произведена по первому, затем по второму полю. Впрочем, индексацию таблицы лучше изучать на примере. Если в данный момент у вас открыта Delphi с нашей программой – закройте ее. Нам нужно будет изменить структуру таблицы, и просто закрытие приложения не поможет, до закрытия Delphi таблица будет в использовании, и изменить ее структуру не получится. Теперь откройте утилиту Database Desktop, и загрузите в нее нашу таблицу d:\data\books.db Далее выбираем команду Table – Restructure. Откроется то самое окно, в котором мы вводили названия и типы полей таблицы. Перед тем, как мы установим индексы для полей, давайте изменим языковой драйвер таблицы. Если этого не сделать, то при использовании индексирования по текстовому полю, где содержится текст на русском языке, могут возникнуть проблемы. Для изменения языкового драйвера в поле Table Properties выберите Table Language, а в открывшемся окне – Pdox ANSI Cyrillic. Теперь вот что еще важно – чтобы индексы работали, необходимо иметь главный ключ, так что если у вас поле Key1 не установлено, как ключевое, сделайте это. Кстати, поле Key2 во второй таблице тоже должно быть ключевым. Далее приступим к созданию индексов. Поскольку сортировку мы будем делать по полю "Автор" и по полю "Название", то и индексов у нас должно быть два. В поле Table Properties выберите Secondary Indexes, и нажмите кнопку Define. Откроется окно, в левой части которого будут находиться все поля нашей таблицы, а в правой – индексные поля. Правая часть пока что пуста. Установите галочку "Maintained", без этого вы сможете пользоваться индексом только в режиме чтения, при добавлении новой записи будет выходить ошибка. Установка этой галочки говорит о том, что в дальнейшем индексация данных будет автоматической.
Выделите поле Avtor, и кнопкой со стрелкой вправо скопируйте его в правую часть. Таким образом, мы указали это поле как вторичный индекс. Далее нажимаем кнопку OK. Выйдет окошко с запросом имени индекса, укажем там "Sort_Avtor". Называть индексы теми же именами, что и таблица, не рекомендуется – индексов может быть много, да и вам легче будет запутаться в одинаковых названиях. После этого, индекс Sort_Avtor должен появиться в окне ниже кнопки Define. При выделении этого индекса станут доступными еще две кнопки – Modify и Erase. Первой кнопкой вы сможете изменить этот индекс, второй – удалить его. Но нам это не нужно. Далее точно также делаем другой индекс – нажимаем кнопку Define, копируем направо поле Nazvanie, и сохраняем индекс по имени "Sort_Nazvanie". Теперь в окошке вы должны видеть два индекса. Сохраните таблицу и выйдите из утилиты. Посмотрите на каталог с базой данных – он увеличился на 4 файла, по 2 файла на каждый индекс. Именно поэтому базы данных в серьезных приложениях бывают довольно большими и содержат сотни взаимосвязанных файлов. С модификацией таблицы закончили, открываем наш проект. По команде меню "Сортировка – По автору" напишем такой код: fDM.TBooks.IndexName:= 'Sort_Avtor'; "Сортировка – По названию книги" будет содержать fDM.TBooks.IndexName:= 'Sort_Nazvanie'; Сохраните проект, скомпилируйте его и посмотрите, как он работает. Подсчет данных Улучшим пример, подсчитав общее количество книг и их сумму. Для этого в модуле DM создайте переменную – закладку. Она нам необходима для того, чтобы после подсчета возвращаться к записи, откуда вызвана процедура пересчета. И переменная должна находится там же, где определены компоненты Table, потому что закладки описываются в этих модулях. Переменная должна быть глобальной:
bm: TBookmarkStr; //закладка Далее, в главном модуле в разделе Private опишем нашу процедуру: procedure Itog; Напишем эту процедуру в самом низу: procedure TfMain.Itog; var all: Integer; //для общ. кол-ва книг summ: Real; //для общ. суммы begin //ставим закладку: DM.bm:= fDM.TBooks.Bookmark; //обнуляем переменные all:= 0; summ:= 0; //перемещаемся от начала до конца и сохраняем результат: fDM.TBooks.First; while not fDM.TBooks.Eof do begin all:= all + fDM.TBooks['Exemp']; summ:= summ + fDM.TBooks['Exemp'] * fDM.TBooks['Cena']; fDM.TBooks.Next; end; //while //снова переходим на закладку и убираем ее: fDM.TBooks.Bookmark:= DM.bm; DM.bm:= ''; //записываем данные: Label1.Caption:= 'Всего книг: ' + IntToStr(all); Label2.Caption:= 'На общую сумму: ' + FormatFloat('0,000.00', summ) + ' с.'; //14 лекция end; Сгенерируйте событие onShow для главной формы и там вызовите нашу процедуру: Itog; Также добавьте ее вызов из команды меню "Редактирование – Добавить книгу". Теперь мы можем быть уверены, что при добавлении книги пересчет будет правильный. Подстановочные поля Иной раз приходится добавлять поле, которого изначально в данной таблице не было. Возьмите главную форму – там у нас выходит поле с номером автора, но не с его фамилией, а пользователю номер вряд ли поможет. Значит, для его удобства нам нужно будет вставить поле, где бы вместо номера выходили фамилия, имя и отчество автора. Это поле мы будем брать из таблицы авторов, подставлять нужные значения и выводить их так, будто изначально они были в первой таблице. Создание нового поля возможно только при неактивной таблице, поэтому закройте таблицу TBooks (свойство Active переведите в False). Щелкните дважды по компоненту TBooks, который находится в модуле DM, чтобы открыть редактор полей. Далее щелкните по свободному месту редактора правой кнопкой и выберите команду "New Field" (новое поле). Появится окно, где мы должны указать все необходимые атрибуты поля.
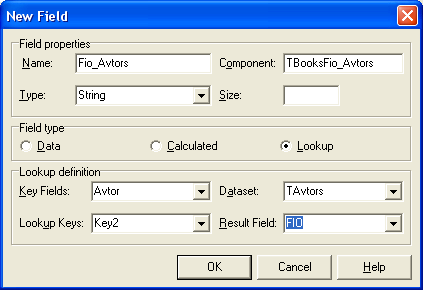
Рис. 32.1. Создание нового поля В поле Name раздела Field properties нужно указать имя нового поля. Назовем его Fio_Avtors. Далее, в поле Type нужно указать тип нового поля, у нас это String, строковое поле для вывода фамилий авторов. В разделе Fieldtype нужно выбрать тип поля, выберемLookup, это значит, что мы будем брать данные из другой таблицы. Остался раздел Lookup definition. Здесь в поле Key Fields мы должны указать поле нашей таблицы, откуда мы будем брать значения. У нас это Avtor, здесь хранятся числа – номера авторов. В поле Dataset мы укажем таблицу, откуда будем брать значения, это таблица TAvtors. В поле Lookup Keys укажем начальное поле, которое хранит цифры – номера авторов, поле Key2. А в поле Result Field – результативное поле, значения которого будем подставлять. Это поле FIO. Далее нажмите кнопку ОК. В редакторе полей перетащите новое поле поближе к полю Avtor, в начало таблицы. Переведите таблицу в активное состояние. Уже в проекте видны недостатки – заголовок подстановочного поля выходит латинскими буквами, и полеAvtor, содержащее цифры, уже не нужно. Снова вызовите редактор полей. Поле Avtor сделайте невидимым (visible в false). У поля Fio_Avtors в свойстве DisplayLabel укажите "Авторы". Теперь данные в сетке выходят в удобочитаемом виде. Новое поле никак не влияет на таблицы. Оно необходимо только для вывода данных в нормальном виде. Далее займемся поиском нужной записи с помощью фильтров. Фильтрация данных Фильтрация данных предназначена для облегчения и ускорения поиска необходимой записи. Если у нас в базе всего около 100-200 записей, то найти нужную запись несложно путем обычного перебора записей, с первой по последнюю, либо пока не будет найдена нужная запись. А вот если записей миллион? Или сто миллионов? Тогда время поиска заметно увеличится, и тут придет на помощь фильтрация.
Когда вы применяете фильтр, то на экран выходят только те данные, которые удовлетворяют условиям фильтра. В нашем примере удобней всего делать фильтр по названию книги, так как подстановочное поле использовать в фильтре нельзя, а авторы у нас числятся как целые числа. На экран выйдут только те книги, название которых удовлетворяет условиям поиска, а уж среди них найти нужную книгу будет несложно. Приступим к программированию. На панель главной формы, которая находится под меню, установите один компонент Label, на котором напишите "Найти книгу:", и один Edit, у которого удалите текст и сделайте его немного длинней. Когда мы будем вводить название книги в поле ввода Edit, на сетке будут отображаться только отфильтрованные данные. Для компонента Edit создайте событие onChange, где напишите такой код: //если пусто - не фильтруем. if Length(Edit1.Text) = 0 then begin fDM.TBooks.Filtered:= False; Exit; end //if else fDM.TBooks.Filtered:= True; //индексируем по названию, чтобы они были по алфавиту fDM.TBooks.IndexName:= 'Sort_Nazvanie'; //устанавливаем фильтр: fDM.TBooks.Filter:= 'Nazvanie>='+QuotedStr(Edit1.Text); Здесь мы вначале проверяем – есть ли текст? Если нет, то убираем фильтр (Filtered:= False) и выходим из процедуры. Если же текст есть, то указываем, что таблица должна фильтроваться: Filtered:= True. Далее, чтобы быстрей найти нужную книгу из списка отфильтрованных записей, делаем сортировку по названию книги. И наконец, устанавливаем сам фильтр. Функция QuotedStr() возвращает текст, заключенный в кавычки. Можно было бы кавычки установить самостоятельно, однако здесь есть некоторые сложности – приходится считать, сколько же кавычек нужно ставить. Дело в том, что условие фильтрации требует такой записи: Table1.Filter:= 'значение'; А само значение может быть в таком виде: Nazvanie >= 'Значение' То есть, внутри строки будет еще одна строка, которую необходимо поставить в одинарные кавычки. Чтобы внутри текста указать одинарную кавычку, ее нужно написать дважды, так что строка превратиться в такой вид: fDM.TBooks.Filter:= 'Nazvanie>='''+ Edit1.Text+''''; Чтобы избежать таких сложностей подсчитывания кавычек, и существует функция QuotedStr(). Отчетность
Для создания отчетности существует очень много способов. Наиболее "продвинутый", но и наиболее сложный – вывод отчета с помощью компонентов отчетности, таких как Quick Report. Другой профессиональный способ – вывод отчета в файл MS Excel или MS Word. Мы разберем самый простой способ отчетности – будем выводить отчет в компонент Memo, а при желании – сохранять его в файл. Создайте новую форму. В свойстве Name укажите fOtchet, в свойстве Caption – "Отчет", а саму форму сохраните в модуле Otchet. Далее, в верхнюю часть формы установим Memo, и растянем его по всему верху (свойство Align = alTop). В нижней части поместим кнопку и компонент SaveDialog. На кнопке напишем "Сохранить в файл". У Memo уберем весь текст, и установим вертикальную прокрутку. Не забудем добавить к этой форме модуль DM с помощью команды Uses Unit, а в главной форме той же командой добавим новое окно Otchet. По нажатию кнопки напишем такой код: if SaveDialog1.Execute then Memo1.Lines.SaveToFile(SaveDialog1.FileName); Теперь нам необходимо написать код, по которому Memo будет заполняться данными. Это лучше всего сделать по событию главной формы onShow: var s: String; begin //очищаем Memo: Memo1.Lines.Clear; //устанавливаем закладку: bm:= fDM.TBooks.Bookmark; //готовим таблицу: fDM.TBooks.First; fDM.TBooks.Filtered:= False; //делаем отпервой до последней записи: while not fDM.TBooks.Eof do begin //собираем данные в переменную s: s:= 'Автор: '+ GetFIO(fDM.TBooks['Avtor'])+#13+#10; s:= s + 'Название: '+ fDM.TBooks['Nazvanie']+#13+#10; s:= s + 'Экземпляров: '+ IntToStr(fDM.TBooks['Exemp'])+#13+#10; s:= s + 'Стоимость: '+ FloatToStr(fDM.TBooks['Cena'])+#13+#10; s:= s + 'Дата поставки: '+DateToStr(fDM.TBooks['Date'])+#13+#10; s:= s + '--------------------------------------------' +#13+#10; fDM.TBooks.Next; Memo1.Lines.Add(s); end; //while //переходим на закладку: fDM.TBooks.Bookmark:= bm; bm:= ''; Мы указали функцию GetFIO(), которой пока нет. Эта функция будет принимать номер автора, и возвращать его фамилию, имя и отчество. Создайте эту функцию выше процедуры onShow: function GetFIO(i: Integer):String; begin Result:= ''; fDM.TAvtors.First;
while not fDM.TAvtors.Eof do begin if fDM.TAvtors['Key2'] = i then begin Result:= fDM.TAvtors['FIO']; Break; end; //if fDM.TAvtors.Next; end; //while if Length(Result)= 0 then Result:= 'Автор не найден'; end; Вот теперь все! Сохраните проект, скомпилируйте его и посмотрите, как он работает. Мы в этом проекте использовали почти все приемы работы с таблицами, хотя приложение, конечно, получилось не совсем профессиональным. Например, если удалить автора из таблицы авторов, то разрушится целостность таблиц – книга будет указывать автора, которого нет. В профессиональных проектах все это учитывается, однако на это уходит гораздо больше времени, и пишется гораздо больше кода. Когда вы освоите работу с таблицами самостоятельно, для вас все это не будет представлять никаких проблем. Подытоживая сказанное о базах данных, заметим еще раз, что приложения бывают локальными – когда приложение и сама база данных располагаются на машине клиента. Такой подход следует использовать в приложениях, в которых сотрудники предприятия не должны обращаться к одним и тем же данным, например, в собственном телефонном справочнике, в приложении с кулинарными рецептами, в каталоге домашней библиотеки и тому подобными программами.
Сетевая база данных работает примерно так же, как локальная, только сама база данных находится на сетевом ресурсе, и с ее данными работают несколько клиентских приложений. Такой подход следует использовать для небольших сетевых приложений, когда сотрудников, работающих с данными тоже немного. Если записей в таблице перевалит за десяток тысяч, то обработка такой базы данных очень сильно загрузит сеть. Клиент – серверная база данных работает иначе. Данные хранятся на сервере. Там же хранится СУБД (Система Управления Базами Данных). Пользователь работает не напрямую с данными, а получает к ним доступ из СУБД с помощью SQL – запросов. Сервер эти данные обрабатывает, и пользователю возвращается результат – только те данные, которые необходимы. А в предыдущем случае каждый клиент получал свою копию полной БД. Нетрудно сообразить, что клиент – серверный подход значительно ускоряет работу с БД и снижает нагрузку на сеть. Однако начинать программирование БД следует все же с локальных приложений. По мере накопления опыта вы будете двигаться дальше, к сетевым и клиент – серверным БД.
|
|||||||||
|
|
Последнее изменение этой страницы: 2017-02-07; просмотров: 249; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.118.226.105 (0.05 с.) |