Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
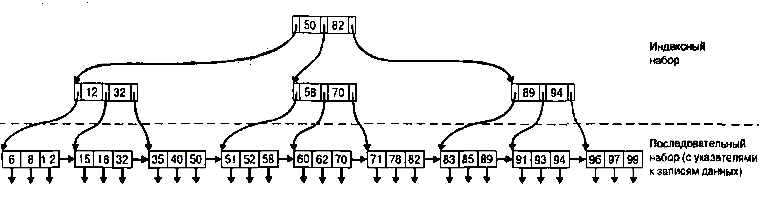
Усовершенствованные сбалансированные древовидные индексы
Сбалансированное дерево Дерево - это структура данных, используемая во многих СУБД для хранения данных или индексов. Дерево состоит из иерархии узлов (node), в которой каждый узел, за исключением корня (root), имеет родительский (parent) узел, а также один, несколько или ни одного дочернего (child) узла. Корень не имеет родительского узла. Узел, который не имеет дочерних узлов, называется листом (leaf). Глубина дерева - это максимальное количество уровней между корнем и листом. Глубина дерева может быть различной для разных путей доступа к листам. Сбалансированное дерево, В-дерево, В-Тгее - это дерево, у которого глубина дерева одинакова для всех листов. Степень (degree), порядок (order) дерева - это максимально допустимое количество дочерних узлов для каждого родительского узла. Большие степени обычно используются для создания более широких и менее глубоких деревьев. Поскольку время доступа в древовидной структуре зависит от глубины, а не от ширины, обычно принято использовать более "разветвленные" и менее глубокие деревья. Бинарное дерево, binary tree - это дерево порядка 2, в котором каждый узел имеет не больше двух дочерних узлов. Усовершенствованные сбалансированные древовидные индексы определяются по следующим правилам.
Методы доступа к файлам Организация файла - физическое распределение данных файла по записям и страницам на вторичном устройстве хранения. Существуют следующие основные типы организации файлов.
Для каждого типа организации файлов используется соответствующий набор методов доступа.
Метод доступа - действия, выполняемые при сохранении или извлечении записей из файла. Поскольку некоторые методы доступа могут применяться только к файлам с определенным типом организации (например, нельзя применять индексный метод доступа к файлу, не имеющему индекса), термины "организация файла" и "метод доступа" часто рассматриваются как эквивалентные. Дальше в этом приложении описаны основные типы структуры файлов и соответствующие им методы доступа. В главе 16 представлена методология физического проектирования базы данных для реляционных систем вместе с рекомендациями по выбору наиболее подходящей структуры файлов и индексов. Неупорядоченные файлы Неупорядоченный файл (который иногда называют кучей) имеет простейшую структуру. Записи размещаются в файле в том порядке, в котором они в него вставляются. Каждая новая запись помещается на последнюю страницу файла, а если на последней странице для нее не хватает места, то в файл добавляется новая страница. Это позволяет очень эффективно выполнять операции вставки. Но поскольку файл подобного типа не обладает никаким упорядочением по отношению к значениям полей, для доступа к его записям требуется выполнять линейный поиск. При линейном поиске все страницы файла последовательно считываются до тех пор, пока не будет найдена нужная запись. Поэтому операции извлечения данных из неупорядоченных файлов, имеющих несколько страниц, выполняются относительно медленно, за исключением тех случаев, когда извлекаемые записи составляют значительную часть всех записей файла. Для удаления записи сначала требуется извлечь нужную страницу, потом удалить нужную запись, а после этого снова сохранить страницу на диске. Поскольку пространство удаленных записей повторно не используется, производительность работы по мере удаления записей уменьшается. Это означает, что неупорядоченные файлы требуют периодической реорганизации, которая должна выполняться администратором базы данных (АБД) с целью освобождения неиспользуемого пространства, образовавшегося на месте удаленных записей.
Неупорядоченные файлы лучше всех остальных типов файлов подходят для выполнения массовой загрузки данных в таблицы, поскольку записи всегда вставляются в конец файла, что исключает какие-либо дополнительные действия по вычислению адреса страницы, в которую следует поместить ту или иную запись. Упорядоченные файлы Записи в файле можно отсортировать по значениям одного или нескольких полей и таким образом образовать набор данных, упорядоченный по некоторому ключу. Поле (или набор полей), по которому сортируется файл, называется полем упорядочения. Если поле упорядочения является также ключом доступа к файлу и поэтому гарантируется наличие в каждой записи уникального значения этого поля, оно называется ключом упорядочения для данного файла. В общем случае бинарный поиск эффективнее линейного, однако этот метод чаще применяется для поиска данных в первичной (оперативной), а не во вторичной памяти (внешней). Операции вставки и удаления записей в отсортированном файле усложняются в связи с необходимостью поддерживать установленный порядок записей. Для вставки новой записи нужно определить ее расположение в указанном порядке, а затем найти свободное место для вставки. Если на нужной странице достаточно места для размещения новой записи, то потребуется переупорядочить записи только на этой странице, после чего вывести ее на диск. Если же свободного места недостаточно, то потребуется переместить одну или несколько записей на следующую страницу. На следующей странице также может не оказаться достаточно свободного места, и из нее потребуется переместить некоторые записи на следующую страницу и т.д. Таким образом, вставка записи в начало большого файла может оказаться очень длительной процедурой. Для решения этой проблемы часто используется временный неотсортированный файл, который называется файлом переполнения (overflow file) или файлом транзакции (transaction file). При этом все операции вставки выполняются в файле переполнения, содержимое которого периодически объединяется с основным отсортированным файлом. Следовательно, операции вставки выполняются более эффективно, но выполнение операций извлечения данных немного замедляется. Если запись не найдена во время бинарного поиска в отсортированном файле, то приходится выполнять линейный поиск в файле переполнения. И наоборот, при удалении записи необходимо реорганизовать файл, чтобы удалить пустующие места. Упорядоченные файлы редко используются для хранения информации баз данных, за исключением тех случаев, когда для файла организуется первичный индекс. Хэширование Статическое хэширование В хэшированием файле записи не обязательно должны вводиться в файл последовательно. Вместо этого для вычисления адреса страницы, на которой должна находиться запись, используется хэш-функция (hash function), параметрами которой являются значения одного или нескольких полей этой записи. Подобное поле называется полем хэширования (hash field), а если поле является также ключевым полем файла, то оно называется хэш-ключом (hash key). Записи в хэшированием файле распределены произвольным образом по всему доступному для файла пространству. По этой причине хэшированные файлы иногда называют файлами с произвольным или прямым доступом (random file или direct file).
хэш-функция выбирается таким образом, чтобы записи внутри файла были распределены наиболее равномерно. Один из методов создания хэш-функции называется сверткой (folding) и основан на выполнении некоторых арифметических действий над различными частями поля хэширования. При этом символьные строки преобразуются в целые числа с использованием некоторой кодировки (на основе расположения букв в алфавите или кодов символов ASCII). Например, можно преобразовать в целое число первые два символа поля табельного номера сотрудника (атрибут staffNo), а затем сложить полученное значение с остальными цифрами этого номера. Вычисленная сумма используется в качестве адреса дисковой страницы, на которой будет храниться данная запись. Более популярный альтернативный метод основан на хэшировании с применением остатка от деления. В этом методе используется функция MOD, которой передается значение поля. Функция делит полученное значение на некоторое заранее заданное целое число, после чего остаток от деления используется в качестве адреса на диске. Недостатком большинства хэш-функций является то, что они не гарантируют получение уникального адреса, поскольку количество возможных значений поля хэширования может быть гораздо больше количества адресов, доступных для записи. Каждый вычисленный хэш-функцией адрес соответствует некоторой странице, или сегменту (bucket), с несколькими ячейками (слотами), предназначенными для нескольких записей. В пределах одного сегмента записи размещаются в слотах в порядке поступления. Тот случай, когда один и тот же адрес генерируется для двух или более записей, называется конфликтом (collision), a подобные записи — синонимами. В этой ситуации новую запись необходимо вставить в другую позицию, поскольку место с вычисленным для нее хэш-адресом уже занято. Разрешение конфликтов усложняет сопровождение хэшированных файлов и снижает общую производительность их работы. Для разрешения конфликтов можно использовать следующие методы:
Открытая адресация При возникновении конфликта система выполняет линейный поиск первого доступного слота для вставки в него новой записи. После неудачного поиска пустого слота в последнем сегменте поиск продолжается с первого сегмента. При выборке записи используется тот же метод, который применялся при сохранении записи, за исключением того, что запись в данном случае рассматривается как не существующая, если до обнаружения искомой записи будет обнаружен пустой слот. На первый взгляд может показаться, что этот подход не дает большого выигрыша в производительности. Однако при более внимательном анализе обнаруживается, что при использовании открытой адресации конфликты, устраненные с помощью первого свободного слота, могут вызвать дополнительные конфликты с записями, которые будут иметь хэш-значение, равное адресу этого прежде свободного слота. Таким образом, количество конфликтов будет возрастать, а производительность — падать. С другой стороны, если количество конфликтов удастся свести к минимуму, то линейный поиск в малой области переполнения будет выполняться достаточно быстро.
|
||||||||
|
|
Последнее изменение этой страницы: 2017-01-25; просмотров: 131; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.141.8.247 (0.011 с.) |