|
Последнее изменение этой страницы: 2016-12-16; просмотров: 281; Нарушение авторского права страницы; Мы поможем в написании вашей работы!
infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.222.180.149 (0.009 с.)
|






 s), где общий вид функции Fmod (т.е. тип модели) считается известным, а параметры, от которых она зависит, могут быть как известными, так и неизвестными.
s), где общий вид функции Fmod (т.е. тип модели) считается известным, а параметры, от которых она зависит, могут быть как известными, так и неизвестными.


 (2)
(2)
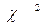 определяемой по выборке X1, X2, … X n и гипотетической модельной Fmod(X,
определяемой по выборке X1, X2, … X n и гипотетической модельной Fmod(X, 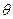 1, …
1, …  Пирсона.
Пирсона.
 ,где
,где - частота, R – общее число возможных значений или интервалов группирования, S – количество параметров распределения.
- частота, R – общее число возможных значений или интервалов группирования, S – количество параметров распределения. разбивается на ряд интервалов группирования
разбивается на ряд интервалов группирования  ,
, 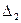 , …
, …  не обязательно одинаковой длины. Это разбиение на интервалы необходимо получить следующим условием:
не обязательно одинаковой длины. Это разбиение на интервалы необходимо получить следующим условием: 3). Если же отказаться от этого предположения, то требование а) следовало бы заменить более жестким R
3). Если же отказаться от этого предположения, то требование а) следовало бы заменить более жестким R 

 неизвестных параметров
неизвестных параметров  , от которых зависит данный закон распределения F (гл.8). Более корректным способом действия считается тот, при котором оценки
, от которых зависит данный закон распределения F (гл.8). Более корректным способом действия считается тот, при котором оценки  и вычисляются вероятности событий
и вычисляются вероятности событий 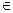

 % - ная точка
% - ная точка 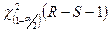 и 100
и 100  % точка
% точка 
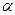 - уровень значимости)
- уровень значимости) , то
, то принимается.
принимается.



