Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Основи категорії даних імен файлівСодержание книги
Поиск на нашем сайте
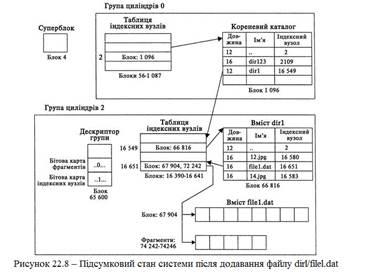
У UFS1 і UFS2 використовуються ті ж структури даних імен файлів, що і в ExtX. В структурі даних запису каталогу зберігається ім'я файлу, адреса індексного вузла і значення типу. Довжина структури визначається довжиною імені, максимальна довжина якої дорівнює 255 символам. Ім'я зберігається в кодуванні ASCII і завершується нуль-символом, хоча імена ExtX не завершуються нулями. Структури записів каталогів знаходяться в блоках, виділених каталогам. Каталог відрізняється від звичайного файлу лише тим, що в полі режиму для них вказується тип каталога. Перші два записи будь-якого каталога завжди відповідають записам «.» і «..». В кожному записі каталога зберігається довжина, по якій визначається початок наступного запису, а довжина останнього запису посилається на кінець блоку. При видаленні файлу довжина попереднього запису збільшується таким чином, аби вона посилалася на запис після приховуваної. Кореневий каталог завжди знаходиться в індексному вузлі 2. В наступному розділі приведений детальний опис структури даних каталога і приклад з образу файлової системи. В лістингу 22.2 наведено результат виконання програми fls для тестового образу файлової системи, описаного нижче.
Лістинг 22.2 – Результат виконання програми fls для тестового образу файлової системи # fls -f openbsd -a openbsd.dd 1921 d/d 1921: d/d 2: r/r 1932: filel.txt r/r 1933: file8.txt r/r 1934: file7.txt r/- * 1935: file6.txt [...] Рядок з позначкою «*» відповідає видаленому файлу. В першому стовпці вказана інформація про тип файлу, взятого із запису каталога та з індексного вузла. Ми бачимо, що UFS стирає тип файлу з індексного вузла, тому що у видаленого файлу дані про тип в індексному вузлі відсутні. У UFS підтримуються як жорсткі, так і м'які посилання, які дозволяють визначати додаткові імена для файлів і каталогів. Жорстке посилання представляє собою альтернативне ім'я для файлу або каталогу, що знаходиться в тій же файловій системі. При створенні жорсткого посилання створюється новий запис каталогу, яка посилається на індексний вузол вихідного файлу. Лічильник посилань в індексному вузлі збільшується, що відображає появу нового імені. М'які посилання створюються у вигляді символічних посилань, які містять дорогу до цільового файла або у фрагменті, або в 60 байтах, зазвичай використовуваних для покажчиків на блоки. У UFS використовуються 64-розрядні покажчики замість 32-розрядних, тому простір для зберігання шляху збільшується до 120 байт. Каталоги в UNIX використовуються і для зберігання імен файлів, і як точки монтування інших файлових систем.Багато систем сімейства BSD підтримують режим об'єднуючого монтування (хоча він і не активізується по замовчуванню), при якому вміст каталога, використовуваного як точка монтування, залишається видимим. ОС об'єднує файли з каталога монтування і кореневого каталога вмонтовуваного тому так, що вони виглядають як єдине ціле. Алгоритми виділення У BSD і Solaris для каталогів застосовується стратегія виділення першому доступному запису. ОС перебирає записи каталогів і порівнює вказану довжину запису з фактичною, тобто реально необхідною для зберігання імені файлу відповідної довжини. Якщо вказана довжина більше і інформація про новий файл поміщається в невживаному «хвості», запис каталогів створюється в цьому місці. При виділенні запису каталогів заповнюються нулями. Структури записів каталогів не пересікають кордону блоків. При видаленні файлу вказана довжина попереднього запису збільшується так, щоб вона посилалася на початок наступного запису за видаленим файлом. На відміну від Solaris, системи BSD не стирають тип файлу або поля індексного вузла. Це означає, що в BSD можна отримати інформацію про тимчасові штампи для видаленого файлу, але прямі покажчики на блоки, швидше за все, виявляться стертими. Інші операційні системи можуть використовувати інші методи із стиранням імені. Методи аналізу Аналіз даних в категорії імен файлів направлений на отримання списку файлів і підкаталогів в заданому файлі, з пошуком закономірностей і конкретних імен. Для цієї мети зазвичай потрібно спочатку знайти кореневий каталог. Він завжди знаходиться в індексному вузлі 2, і ця обставина дозволяє використовувати при пошуку його вмісту прийоми, описані вище. Після того, як вміст каталога буде знайдений, він обробляється як список записів каталогів. При обробці вмісту каталога наступний запис знаходиться по покажчику, що зберігається в поточному записі. Пошук видалених записів заснований на перевірці простору від кінця імені файлу у виділеному записі і до початку наступного запису. Якщо в цьому просторі вдається виявити дані у форматі записи каталога, ймовірно, вони залишилися від видалених файлів. Після виявлення видаленого файлу або каталога, що представляє інтерес, можна отримати про нього додаткову інформацію — для цього слід визначити адресу відповідного індексного вузла і обробити її. Багато програм вирішують цю задачу автоматично і виводять тимчасові штампи разом з інформацією про ім'я. При видаленні каталогів зв'язок між індексним вузлом і блоками зазвичай розривається. Якщо потрібно буде знайти вміст видаленого каталога, спробуємо знайти записи «.» і «..». Записи каталогів не можуть пересікати кордону блоків, тому кожен блок повинен починатися з нового запису. Фактори аналізу Архітектура записів каталогів і її реалізація в більшості систем дозволяє легко знаходити імена видалених файлів, а той факт, що поле індексного вузла не стирається в системах BSD, дозволяє також знайти метадані файлів. Solaris стирає вміст цього поля, тому знайти додаткові дані не вдасться. Втім, навіть якщо ми виявимо видалений запис каталога із збереженим значенням індексного вузла, буде непросто визначити, чи не відповідає вміст індексного вузла колишньому файлу, або індексний вузол був виділений заново, і його вміст тепер відповідає іншому файлу. Можна провести просту перевірку і визначити, чи вільний індексний вузол в даний момент. Якщо він використовується, значить, індексний вузол був виділений заново, або ж файл був переміщений в межах файлової системи, і ми аналізуємо його вихідний індексний вузол. Більшість ОС стирають поле режиму в індексних вузлах UFS, що не дозволяє порівняти тип файлу з типом, вказаним в записі каталога. Структури записів каталогів можуть містити приховані дані — простір між останнім записом каталога і кінцем блоку не використовується системою. Проте ця методика приховування даних вельми рискованна, тому що ОС може стерти дані при створенні нового імені файлу. Загальна картина Наведемо приклади створення і видалення файлу /dirl/filel.dat, що займає 25000 байт, у файловій системі UFS2. Створення файлу На високому рівні процес створення файлу /dir 1/filel.dat зводиться до пошуку каталога dirl, створення запису каталога, виділення індексного вузла і наступного виділення блоків для вмісту файлу. Точний порядок виділення структур даних залежить від ОС; описана далі процедура може відрізнятися від тієї, що використовується у нашій конкретній системі. Для простоти в даному випадку ігноруються структури даних із списками розмірів фрагментів і кластерів. 1. Створення файлу починається з читання суперблоку, який займає 2 Кбайт і знаходиться у файловій системі із зсувом 64 Кбайт. З суперблоку ми дізнаємось, що розмір блоку рівний 16 Кбайт, а розмір фрагменту — 2 Кбайт. Кожна група циліндрів містить 32776 фрагментів і 8256 індексних вузлів. Ми також дізнаємось, що дескриптор групи зберігається із зсувом 40 фрагментів, а таблиця індексних вузлів — із зсувом 56 фрагментів в кожній групі циліндрів. 2. Далі необхідно обробити індексний вузол 2, аби знайти каталог dirl в кореневому каталозі. Використовуючи інформацію про кількість індексних вузлів в групі, ми визначаємо, що індексний вузол 2 знаходиться в групі циліндрів 0. Звідси, таблиця індексних вузлів з інформацією про вузол 2 починається в блоці 56. 3. З блоку 56 читається таблиця індексних вузлів, в якій обробляється третій запис (перший запис відповідає індексному вузлу 0). Вміст індексного вузла 2 показує, що структури записів каталогів для кореневого каталога знаходяться в блоці 1096. 4. Ми читаємо вміст кореневого каталога з блоку 1096 і обробляємо його як список записів каталогів. Послідовно переміщаючись вперед по вказаним довжинах записів (видалені файли нас не цікавлять), ми в кінцевому рахунку приходимо до запису з ім'ям dirl. В записі вказаний номер індексного вузла 16 549. В кореневому каталозі оновлюється А-час. 5. Місцезнаходження індексного вузла 16549 визначається діленням числа на кількість індексних вузлів в групі. Так ми визначаємо, що вузол знаходиться в групі циліндрів 2. Група 2 починається в блоці 65 552, тому її таблиця індексних вузлів починається в блоці 65608 (якби використовувалася файлова система UFS1, нам також довелося б обчислити базову адресу для групи). 6. З блоку 65608 читається таблиця індексних вузлів, в якій обробляється запис 37, — відносним номером індексного вузла 16549. Вміст індексного вузла показує, що вміст dirl знаходиться в блоці 66816. 7. Ми читаємо вміст dirl з блоку 66 816 і обробляємо його як список записів каталогів. Нас цікавить невживаний простір в каталозі. Ім'я filel.dat складається з 8 символів, тому для зберігання запису каталога буде потрібно 16 байт. Ім'я нового файлу включається між двома відповідними іменами, для каталога оновлюється М- і С-час. Місце, відведене під новий запис, раніше використовувалося видаленим файлом. 8. Для створюваного файлу необхідно виділити індексний вузол, причому цей вузол повинен входити до групи свого батьківського каталогу, тобто в групу 2. Аби знайти бітову карту індексних вузлів, необхідно спочатку знайти дескриптор групи, видалений на 48 фрагментів від початку групи. Виясняється, що дескриптор знаходиться в блоці 65600; з нього ми дізнаємось, що бітова карта індексних вузлів зберігається в дескрипторі із зсувом 168 байт. Крім того, дескриптор повідомляє, що останнім був виділений запис індексного вузла 16650. Перевірка стану індексного вузла 16651 показує, що вузол вільний. Відповідний біт в бітовій карті встановлюється, номер останнього виділеного індексного вузла в дескрипторі оновлюється, а лічильник вільних індексних вузлів в дескрипторі групи і в зведенні груп циліндрів зменшується. Адреса індексного вузла заноситься в запис каталога filel.dat.
9. На наступному етапі ми знаходимо в таблиці індексних вузлів вузол 139 (відносна адреса вузла 16651) і ініціалізуємо його параметри. Тимчасові штампи ініціалізувалися поточним часом, а лічильник посилань задається рівним 1. Також заповнюються поля UID, GID і режиму. 10.Розмір файлу дорівнює 25000 байт, для зберігання його вмісту потрібно виділити один блок і п'ять фрагментів. Перш за все з дескриптора групи визначається зсув бітової карти фрагментів, яка зберігається із зміщенням 1200. В дескрипторі групи вказаний номер останнього виділеного блоку 67896. Ми перевіряємо блок 67904 по бітовій карті вільних фрагментів і визначаємо, що він вільний. Біт цього блоку в карті обнулюється, а лічильник вільних блоків зменшується. Також оновлюється поле покажчика на останній виділений блок. П'ять вільних фрагментів знаходяться по бітовій карті (або одному із службових списків); у нашому випадку це фрагменти 74242-74246. Біти фрагментів обнуляються, оновлюються відповідні службові дані. Адреса блоку і початковий фрагмент включаються в індексний вузол. 11.Вміст файлу filel.dat записується у виділений блок і фрагменти. Підсумковий стан системи показаний на рис. 22.8.
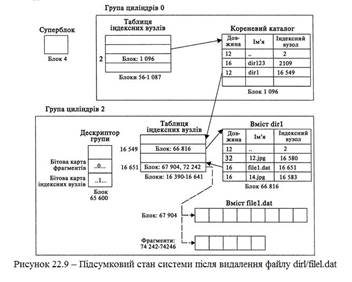
Приклад видалення файлу Перейдемо до процедури видалення файлу /dirl/filel.dat з використанням методів, характерних для BSD. Як згадувалося в попередньому розділі, порядок вивільнення структур даних залежить від ОС, і описана далі процедура може відрізнятися від тієї, що використовується у певній конкретній системі. 1. Видалення файлу починається з читання з суперблоку структури даних об’ємом 2 Кбайт, яка знаходиться у файловій системі із зсувом 64 Кбайт. З суперблоку ми дізнаємось, що розмір блоку рівний 16 Кбайт, а розмір фрагменту — 2 Кбайт. Кожна група циліндрів складається із 32776 фрагментів і 8256 індексних вузлів. Ми також дізнаємось, що дескриптор групи зберігається із зсувом 40 фрагментів, а таблиця індексних вузлів — із зсувом 56 фрагментів в кожній групі циліндрів. 2. Далі необхідно обробити індексний вузол 2, аби знайти каталог dirl в кореневому каталозі. Використовуючи інформацію про кількість індексних вузлів в групі, ми визначаємо, що індексний вузол 2 знаходиться в групі циліндрів 0. Отже, таблиця індексних вузлів з інформацією про вузол 2 починається в блоці 56. 3. З блоку 56 читається таблиця індексних вузлів, в якій обробляється третій запис (перший запис відповідає індексному вузлу 0). Вміст індексного вузла 2 показує, що структури записів каталогів для кореневого каталога знаходяться в блоці 1096. 4. Ми читаємо вміст кореневого каталога з блоку 1096 і обробляємо його як список записів каталогів. Послідовно переміщаючись вперед по вказаним довжинах записів (видалені файли нас не цікавлять), ми в кінцевому рахунку приходимо до запису з ім'ям dirl. В записі вказаний номер індексного вузла 16549. В кореневого каталога оновлюється А-час. 5. Місцезнаходження індексного вузла 16549 визначається діленням числа на кількість індексних вузлів в групі. Так ми визначаємо, що вузол знаходиться в групі циліндрів 2. Група 2 починається в блоці 65552, тому її таблиця індексних вузлів починається в блоці 65608. 6. З блоку 65608 читається таблиця індексних вузлів, в якій обробляється запис 37, — відносним номером індексного вузла 16549, Вміст індексного вузла показує, що вміст dirl знаходиться в блоці 66816. 7. Ми читаємо вміст dirl з блоку 66816 і обробляємо його як список записів каталогів. Нас цікавить запис файлуfilel.dat. Ми знаходимо цей запис і дізнаємось, що їй виділений індексний вузол 16651. Аби звільнити запис каталога, її довжина додається до довжини попереднього запису каталога, що відноситься до файлу 12.jpg. У системі Solaris також довелося б стерти вміст покажчика на індексний вузол. Для каталога dirl оновлюється М-, А- і С-час. 8. В результаті видалення імені файлу лічильник посилань в індексному вузлі 16651 таблиці індексних вузлів групи 2 зменшується на 1. Значення лічильника стає рівним 0; це означає, що індексний вузол необхідно звільнити. Для цього відповідний розряд бітової карти індексних вузлів обнуляется, а в дескрипторі групи і зведенні груп циліндрів оновлюються счетчики вільних індексних вузлів. У індексному вузлі стирається поле режиму. 9. Також необхідно звільнити один блок і п'ять фрагментів, виділених для зберігання вмісту файлу. Для кожного блоку або фрагменту встановлюється відповідний розряд бітової карти блоків/фрагментів і стирається покажчик на блок в індексному вузлі. Розмір файлу зменшується при кожному звільненні блоку, і кінець кінцем він стає рівним 0. М- і С-час індексного вузла оновлюється відповідно до внесених змін. В дескрипторі групи і зведенні груп циліндрів оновлюються лічильники вільних блоків і фрагментів.
Підсумковий стан системи показаний на рис. 22.9. Жирні лінії і значення представляють зміни файлової системи в результаті видалення.
|
||||
|
|
Последнее изменение этой страницы: 2016-09-19; просмотров: 298; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.139.86.58 (0.009 с.) |