Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Файли метаданих файлової системиСодержание книги
Поиск на нашем сайте
Оскільки кожен байт тому виділяється деякому файлу, адміністративні дані файлової системи також повинні зберігатися у файлах. Microsoft називає такі файли файлами метаданих, але це може викликати плутанину, оскільки в тексті також часто згадуються метадані файлів. Я називатиму ці спеціальні файли файлами метаданих файлової системи.
Таблиця 17.1 – Стандартні файли метаданих файлової системи NTFS
Microsoft резервує для файлів метаданих файлової системи перші 16" записів MFT[1]. Невживані зарезервовані записи знаходяться у виділеному стані і містять лише базову і загальну інформацію. Всі файли метаданих файлової системи відображуються в кореневому каталозі, хоча зазвичай вони ховаються від більшості користувачів. Імена файлів метаданих файлової системи починаються з символу «$», а перша буква є прописною (табл. 17.1). Атрибути записів MFT Записи MFT володіють мінімальною структурою, а велика їх частина використовується для зберігання атрибутів — об'єктів, що містять дані певного типу. Кількість різних атрибутів велика, і кожен з них володіє власною внутрішньою структурою. Наприклад, існують атрибути для імені файлу, дати і часу, і навіть вмісту файлу. У цьому виявляється одна з відмінностей NTFS від інших файлових систем. Як правило, файлові системи читають і записують вміст файлів, а NTFS читає і записує атрибути, одна із різновидностей яких інкапсулює вміст файлів. Повернемося до приведеної раніше аналогії, в якій запис MFT порівнювався із скринею, а атрибути — з коробками меншого розміру, які кладуть в скриню. Коробки можуть мати будь-яку форму, яка краще всього личить для зберігання об'єкту. Наприклад, капелюхи зручніше зберігати в круглих коробках, а плакати — в довгих тубусах. Хоча різнотипні атрибути розраховані на різні типи даних, всі атрибути містять дві загальні частини: заголовок і вміст. На рис. 17.4 показаний запис MFT з чотирма парами «заголовок/вміст». Заголовок універсальний і стандартний для всіх атрибутів. Вміст залежить від типу атрибуту і може мати довільний розмір.
Заголовки атрибутів Заголовок визначає тип атрибуту, його розмір і ім'я. Він також містить прапори, які вказують на стискування або шифрування значення. Тип атрибуту є числовим кодом, що асоціюється з типом даних, що зберігаються. Запис MFT може містити декілька однотипних атрибутів. Деяким атрибутам призначається ім'я, що зберігається в кодуванні Unicode UTF-16 в заголовку атрибуту. Атрибуту також призначається ідентифікатор, який забезпечує його унікальність в рамках запису MFT. Якщо запис містить декілька однотипних атрибутів, вони розрізняються за значенням ідентифікатора.
Вміст атрибутів Вміст атрибуту має довільний формат і довільний розмір. Наприклад, один з атрибутів використовується для зберігання вмісту файлу, розміри якого можуть складати декілька мегабайт або навіть гігабайт. Було б незручно зберігати таку кількість даних в 1024-байтових записах MFT. Для вирішення цієї проблеми в NTFS передбачена можливість зберігання вмісту атрибутів в двох місцях. Вміст резидентних атрибутів зберігається в записах MFT із заголовками. Такий спосіб личить лише для невеликих атрибутів. Вміст нерезидентних атрибутів зберігається у зовнішньому кластері файлової системи. У заголовку атрибуту вказано, є атрибут резидентним або нерезидентним. В резидентних атрибутів вміст слідує безпосередньо за заголовком. Для нерезидентних атрибутів в заголовку міститься адреса кластера. На рис. 17.5 показаний запис MFT, який вже наводився раніше, але цього разу її третій атрибут дуже великий для зберігання в MFT, тому для його зберігання виділяється кластер 829.
Нерезидентні атрибути зберігаються в серіях кластерів, тобто групах суміжних кластерів. Серія визначається адресою початкового кластера і довжиною. Наприклад, якщо атрибуту були виділені кластери 48, 49, 50, 51 і 52, то серія починається з кластера 48 і має довжину 5. Якщо атрибуту також виділені кластери 80 і 81, друга серія починається з кластера 80 і має довжину 2. Третя серія може починатися з кластера 56 і мати довжину 4 (рис. 17.6). Ми визначили логічну адресу файлової системи як адресу, назначену блокам даних файлової системи, а логічна адреса файлу — як адреса, що задається по відношенню до початку файлу. У NTFS ці адреси позначаються іншимитермінами. Логічний номер кластера (LCN, Logical Cluster Number) ідентичний логічній адресі файлової системи, а віртуальний помер кластера (VCN, Virtual Cluster Number) ідентичний логічній адресі файлової системи.
У NTFS для опису серій нерезидентних атрибутів використовуються відображення VCN/LCN. Якщо повернутися до попереднього прикладу, адреси VCN з адресами 0-4 відображуються на адреси LCN 48-52, адреси VCN 5-6 — на адреси LCN 80-41, і адреси VCN 7-10 — на адреси LCN 56-59. Стандартні типи атрибутів До доданого моменту ми говорили про атрибути виключно на загальному рівні. В цьому розділі наводимо інформацію про стандартні атрибути. Як згадувалося раніше, кожен тип атрибуту представляється деяким числом, причому Microsoft сортує атрибути в записі по цьому числу. Стандартним атрибутам привласнюється значення за умовчанням, але, як буде показано пізніше, це значення можна перевизначити за допомогою файлу метаданих файлової системи $AttrDef. Окрім числового ідентифікатора кожен тип атрибуту володіє ім'ям, яке складається лише з прописних букв і починається із знаку «$». У таблиці 17.2 перераховані деякі стандартні типи атрибутів і відповідні ним ідентифікатори. Врахуємо, що не всі типи атрибутів та ідентифікатори існують для кожного файлу.
Таблиця 17.2 – Стандартні типи атрибутів в записах MFT
Майже всі виділені записи MFT містять атрибути типів $FILE_NAME і $STANDARD_IN FORMATION. Єдиний виняток становлять не-базові записи MFT, про які мова піде далі. Атрибут $FILE_NAME містить ім'я файлу, розмір і тимчасові штампи. Атрибут $STANDARD_INFORMATION містить часові штампи, інформацію про власників і безпеку. Останній існує у всіх файлах і каталогах, тому що містяться в ньому дані необхідні для забезпечення безпеки даних і дискових квот. В абстрактному розумінні цей атрибут не містить необхідних даних, але його присутність необхідно для роботи механізмів файлової системи прикладного рівня. Обидва атрибути завжди є резидентними. Кожен файл володіє атрибутом $DATA, в якому зберігається вміст файлу. Якщо розмір вмісту досягає приблизно 700 байт, він стає нерезидентним і зберігається в зовнішніх кластерах. Якщо файл містить більше одного атрибуту $DATA, додаткові атрибути інколи називаються альтернативними потоками даних, або ADS (alternate data streams). Основний атрибут $DATA, створений при створенні файлу, не має власного імені, але додатковим атрибутам $DATA повинні призначатися імена. Звернемо увагу: ім'я атрибуту відрізняється від імені типу. $DATA — це ім'я типу атрибуту, тоді як самому атрибуту може бути привласнене інше ім'я (скажімо, «fred»). Деякі програми, у тому числі, що входять в пакет TSK (The Sleuth Kit), привласнюють стандартним атрибуту $DATA ім'я «$Data». Кожен каталог володіє атрибутом $INDEX_RООT з інформацією про існуючих в ньому файлах і підкаталогах. При великому розмірі каталогу інформація також зберігається в атрибутах $INDEX_ALLOCATION і $ВІТМАР. Ситуація додатково ускладнюється тим, що каталоги можуть володіти атрибутом $DATA помимо атрибута $INDEX_RООT. Іншими словами, в каталозі можуть зберігатися як вміст файлів, так і списки його файлів і підкаталогів. В атрибуті $DATA можуть знаходитися будь-які дані, які застосування або користувач побажає в ньому зберегти. Атрибутам $INDEX_RООT і $INDEX_ALLOCATION для каталогів зазвичай присвоюються імена «$130».
На рис. 17.7 показаний приклад запису MFT з іменами і типами атрибутів. Запис містить три стандартні атрибути. В даному прикладі всі три атрибути є резидентними. Інші концепції атрибутів В попередньому розділі розглядалися базові концепції, що відносяться до всіх атрибутів NTFS. Ця частина присвячена концепціям більш високого рівня. Зокрема, ми поглянемо, що відбувається, коли файл містить надто багато атрибутів, а також познайомимося із способами стискування і шифрування вмісту атрибутів. Базові записи MFT Теоретично файл може містити до 65536 атрибутів (із-за 16-розрядних ідентифікаторів), тому для зберігання всіх заголовків атрибутів одного запису MFT може виявитися недостатньо — адже навіть в нерезидентних атрибутів заголовок повинен зберігатися в записі MFT. Коли з файлом асоціюються додаткові записи MFT, вихідний запис MFT називається базовим записом MFT. В не базових записів адреса базового запису зберігається в одному з полів запису MFT. Базовий запис MFT містить атрибут типа $ATTRIBUTE_LIST, в якому зберігається список всіх атрибутів файлу і адрес MFT, по яких їх можна знайти. Небазові записи MFT не містять атрибути $FILE_NAME і $STANDARD_INFORMATION. Розріджені атрибути Аби зменшити об'єм місця, займаного файлом, NTFS може зберігати значення деяких нерезидентних атрибутів $DATA у розрідженому форматі. Розрідженим називається атрибут, в якого кластери, заповнені одними нулями, не записуються на диск. Замість цього для нульових кластерів створюється спеціальна серія. Звичайні серії містять позицію початкового кластера і розмір, тоді як розріджені серії містять лише розмір без початкової адреси. Також присутній прапор, який вказує, що атрибут є розрідженим.
Припустимо, файл займає 12 кластерів. Перші п'ять кластерів містять ненульові дані, наступні три кластери заповнено одними нулями, а останні чотири кластери відмінні від нуля. При зберіганні у вигляді нормального атрибуту для файлу створюється одна серія довжини 12 (рис. 17.8(A)). При зберіганні у вигляді розрідженого атрибуту створюються три серії, а виділяються лише дев’ять кластерів (рис. 17.8 (В)). Стислі атрибути NTFS дозволяє зберігати атрибути в стислому вигляді, хоча опис алгоритму стиснення не опублікований. Звернемо увагу: йдеться про стискуванні на рівні файлової системи, а не про використання зовнішніх застосувань типу WinZip абоgzip. Microsoft стверджує, що стискуватися можуть лише атрибути $DATA і лише при зберіганні в нерезидентному форматі. Як розріджені серії, так і стискування даних використовуються в NTFS для скорочення об'єму витрачуваного дискового простору. Прапор в заголовку атрибуту вказує, що атрибут зберігається в стислому вигляді, а прапори в атрибутах $STANDARD_INFORMATION і $FILE_NAME також повідомляють, що файл містить стислі атрибути. Перед стискуванням вмісту атрибуту дані діляться на фрагменти однакового розміру, названі блоками стискування. Розмір блоку стискування вказується в заголовку атрибуту. В кожному блоці стискування можлива одна з трьох ситуацій: 1. Всі кластери заповнені нулями. В цьому випадку створюється серія розріджених даних, розмір якої збігається з розміром блоку, а дисковий простір не виділяється. 2. Кількість кластерів після стискування не змінилася (тобто стискування виявилося малоефективним). В цьому випадку блок не стискується, а серія створюється для вихідних даних. 3. Дані після стискування займають меншу кількість кластерів. В цьому випадку дані стискуються і зберігаються в серії на диску. Після стислої серії створюється розріджена серія, аби загальна довжина серії збігалася з кількістю кластерів в блоці стискування. В наступному простому прикладі продемонстрований кожен з цих сценаріїв. Передбачимо, розмір блоку стискування дорівнює 16 кластерам, а довжина атрибуту $DATA складає 64 сектори (рис. 17.9). Вміст ділиться на чотири блоки, а кожен блок аналізується файловою системою. Перший блок стискується до 16 кластерів, тому він зберігається без стискування. Другий блок заповнений одними нулями; для нього створюється розріджена серія з 16 кластерів, але кластери на диску не виділяються. Третій блок стискується до 10 кластерів; стислі дані записуються на диск у вигляді серії з 10 кластерів, до якої додається розріджена серія з 6 кластерів для даних, скорочених в результаті стискування. Останній блок стискується до 16 кластерів, тому він зберігається без стискування у вигляді серії з 16 кластерів.
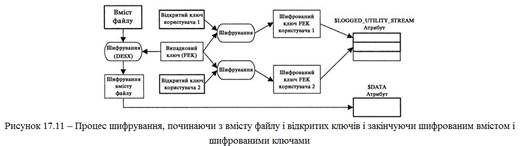
Коли ОС або програма аналізу читає цей атрибут, вона виявляє встановлений прапор стискування і перетворює серії у фрагменти, розмір яких відповідає розміру блоку стискування. Перша серія по довжині збігається з блоком стиснення; отже, вона зберігається без стискування. Друга серія по довжині збігається з блоком стискування і є розрідженою; це означає, що вона складається із 16 кластерів, заповнених нулями. Третя серія утворює розмір блоку лише в поєднані з четвертою; третя серія займає лише 10 кластерів і потребує розпакування. Остання серія по довжині теж співпадає з блоком, а отже, зберігається без стискування. Останній приклад був дуже простим, тому я представлю більш складний, показаний на рис. 17.10. Складнощі пояснюються тим, що вихідна структура серій не ділиться на блоки стискування безпосередньо. Аби обробити цей файл, необхідно спочатку відновити дані з шести серій, а потім розбити їх на блоки стискування з 16 кластерів. Після об'єднання фрагментованих серій ми отримаємо одну серію вмісту, одну розріджену серію, потім знову вміст і ще одну розріджену серію. Об'єднані дані діляться на блоки стискування; ми бачимо, що перші два блоки не містять розріджених серій і не стискуються. Третій і п'ятий блоки містять розріджені серії і стискуються. Четвертий блок зберігається в розрідженому вигляді, а відповідні дані заповнені лише нулями. Шифрування атрибутів У NTFS також передбачена можливість шифрування вмісту атрибутів. В цьому розділі наведемо огляд того, як це робиться і які дані існують на диску. Теоретично шифруватися можуть будь-які атрибути, але Windows підтримує шифрування лише для атрибутів $DATA. Шифрується лише вміст, але не заголовок атрибуту. Для файлу створюється атрибут $LOGGED_UTILITY_STREAM з ключами, необхідними для розшифровки даних. У Windows шифруватися можуть як окремі файли, так і цілі каталоги. Зашифрований каталог не містить зашифрованих даних, але будь-який файл або каталог, створений в цьому каталозі, буде зашифрований. В зашифрованих файлів або каталогів в атрибуті $STANDARD_INFORMATION встановлюється спеціальний прапор, і в кожного зашифрованого атрибуту в заголовку теж встановлюється прапор. Основи криптографії Перш ніж пояснювати, як криптографічні функції реалізовані в NTFS, я приведу короткий огляд основних концепцій криптографії. Шифруванням називається процес, що використовує криптографічний алгоритм і ключ для перетворення простого тексту в зашифровані дані. Дешифровкою називається зворотний процес, що використовує криптографічний алгоритм і ключ для перетворення зашифрованих даних в простий текст. Навіть маючи в своєму розпорядженні зашифрованими дані, сторонній не зможе відновити вихідний текст без ключа. Криптографічні алгоритми діляться на дві категорії: симетричні і асиметричні. Симетричні алгоритми використовують один і той же ключ як для шифрування, так і для розшифровки даних. Симетричне шифрування працює дуже швидко, але воно створює проблеми з передачею зашифрованих даних. Якщо файл зашифрований симетричним алгоритмом і ми хочемо надати доступ до нього багатьом користувачам, доведеться або зашифрувати файл з використанням спільного ключа, або створити окрему копію файлу для кожного користувача і зашифрувати її з ключем, унікальним для даного користувача. Якщо використовувати один ключ для всіх, буде важко позбавити користувача доступу до зашифрованих даних без зміни ключа. Якщо шифрувати файл заново для кожного користувача, це приведе до великих витрат часу і дискового простору. Асиметричні алгоритми використовують один ключ для шифрування, а інший — для дешифровки. Наприклад, ключ «spot» може використовуватися для перетворення простого тексту в зашифрований, а ключ «felix» — для розшифрування зашифрованого тексту. В найпоширенішому варіанті асиметричного шифрування один з ключів робиться відкритим, тобто загальнодоступним, а інший зберігається в секреті. Будь-який бажаючий може зашифрувати дані із загальним ключем, але їх розшифровка можлива лише із закритим (приватним) ключом. Зрозуміло, ключі, вживані на практиці, набагато довші за слова «spot» і «felix». Як правило, довжина ключів перевищує 1024 біт. Реалізація в NTFS При шифруванні атрибуту $DATA у NTFS застосовується симетричний алгоритм DESX. Для кожного запису MFT, що містить шифровані дані, генерується один випадковий ключ, який називається ключем шифрування файлу (FEK, File Encryption Кеу). Якщо запис містить декілька атрибутів $DATA, всі вони шифруються одним ключем FEK. Ключ FEK зберігається в зашифрованому вигляді в атрибуті $LOGGED_UTILITY_STREAM. Атрибут містить список полів розшифровки даних (DDF, Data Decryption Fields) і полів відновлення даних (Data Recovery Fields). DDFстворюється для кожного користувача, що має доступ до файлу, і містить код SID (Security ID) користувача, дані шифрування і ключ FEK, зашифрований відкритим ключем користувача. Поле відновлення даних створюється для кожного методу відновлення даних і містить ключ FEK, зашифрований з відкритим ключем відновлення даних; він використовується в тих випадках, коли адміністратору або іншому привілейованому користувачеві потрібно буде звернутися до даних (рис. 17.11). При розшифровці атрибуту $DATA система обробляє атрибут $LОGGED_UTILITY_STREAM і знаходить записDDF користувача. Закритий ключ користувача використовується для дешифровки ключа FEK, а ключ FEK — для дешифровки атрибуту $DATA. Коли користувач втрачає право доступу, його ключ видаляється із списку. Закритий ключ користувача зберігається в реєстрі Windows і шифрується симетричним алгоритмом, при цьому його пароль входу в систему використовується як ключ. Таким чином, для дешифровки всіх зашифрованих файлів, виявлених в процесі розслідування, необхідно знати пароль користувача і мати доступ до реєстру. Процес показаний на рис. 17.12.
Деякі програми здатні виконати атаку шляхом підбору пароля користувача, що може використовуватися для дешифровки даних. Незашифровані копії вмісту файлу також можуть знаходитися у вільному просторі, якщо шифруються лише деякі файли і каталоги. У архітектурі NTFS присутній невеликий дефект: система створює тимчасовий файл з ім'ямEFS0.TMP, що містить текстову версію шифрованого файлу. Завершивши шифрування вихідного файлу, ОС видаляє тимчасовий файл, але його вміст не стирається. Таким чином, текстова версія файлу продовжує існувати, і його можна відновити, поки запис MFT не буде виділений іншому файлу. Копії незашифрованих даних також можуть знайтися в просторі підкачки. Також повідомлялося, що в разі порушення прав адміністратора, контролера домена або іншого облікового запису, налагодженого як агент відновлення, з'являється можливість дешифровки будь-яких файлів, оскільки такі облікові записи володіють доступом до всіх файлів. Індекси В цьому розділі описані індексні структури даних, використовувані NTFS в багатьох ситуаціях. Індекс в NTFS є колекцією атрибутів, що зберігаються у відсортованому порядку. Найпоширенішим прикладом вживання індексів можна назвати каталоги, тому що вони містять атрибути $FILE_NAME. До виходу NTFS версії 3.0 (що входить в постачання Windows 2000) індексним був лише атрибут $FILE_NAME, але тепер в індексів є і інші застосування, що містять інші атрибути. Наприклад, в індексах зберігаються дані безпеки і визначення квот. Давайте поглянемо, що є індексом і як він реалізований. B-дерева В індексах NTFS атрибути сортуються у вигляді особливого різновиду дерев, а саме В-дерев. Деревом називається сукупність структур даних, які називаються вузлами; вузли зв'язуються між собою, починаючи з кореневого вузла. На рис. 17.13 (А) зверху знаходиться вузол А, пов'язаний з вузлами В і С. У свою чергу, вузол В зв'язується з вузлами D і Е. Батьківським вузлом називається вузол, від якого йдуть зв'язки до інших вузлів, а дочірним — той вузол, до якого веде зв'язок. Наприклад, вузол А є батьківським по відношенню до вузлів В і С, а останні є дочірніми по відношенню до А. Аркушем (або листовим вузлом) називається вузол, що не має дочірніх вузлів. Так, вузли С, D і Е є листовими. Дерево, показане на рисунку, називається бінарним, тому що кожен вузол має не більше двох дочірніх вузлів. Деревовидні структури спрощують пошук і сортування даних. На рис. 17.13 (В) показано те ж дерево, що і на рис. 17.13 (А), але в ньому кожному вузлу привласнено деяке значення. Якщо потрібно було знайти значення в дереві, спочатку ми порівнюємо його з кореневим вузлом. Якщо кореневе значення більше, ми переходимо до лівого дочірнього вузла, а якщо менше — до правого. Припустимо, було потрібно знайти значення 6; ми порівнюємо його з кореневим значенням 7. Кореневий вузол більший, тому ми переходимо до лівого вузла і порівнюємо шукане значення із значенням цього вузла (5). Значення вузла менше, ми переходимо до правого дочірнього вузла; його значення дорівнює 6. Таким чином, значення було знайдене всього за три порівняння. Наприклад, значення 9 знаходиться всього за 2 порівняння замість 5, необхідних при зберіганні значень в списку.
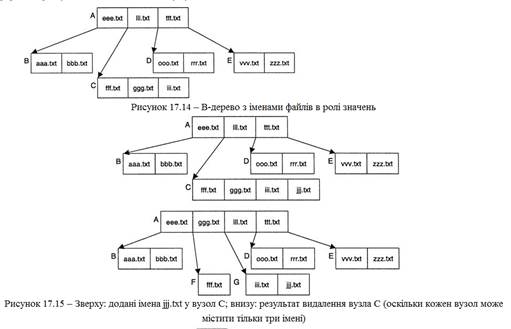
У NTFS використовуються В-дерева, які нагадують бінарне дерево з рис. 17.13, але в них кожен вузол може мати більше двох дочірніх вузлів. Як правило, кількість дочірніх вузлів залежить від того, скільки значень може зберігатися в кожному вузлі. Наприклад, в бінарному дереві в кожному вузлі зберігалося одне значення, тому кількість допустимих нащадків була рівна двом. Якби в кожному вузлі зберігалося п'ять значень, нащадків було б шість. Існує багато різновидів В-дерев і всіляких правил, які ми розглядати не будемо. На рис. 17.14 показано В-дерево, що містить імена замість чисел. Вузол А містить три значення і має чотири дочірні вузли. Скажімо, при пошуку файлу ggg.txt ми звернулися б до кореневого вузла і визначили, що шукане ім'я за абеткою розташоване між eee.txt і LU.txt. Звертаючись до вузла С, ми знаходимо в ньому шукане ім'я файлу. З додаванням і видаленням вузлів справа йде складніше. Проте це досить важливий момент — він пояснює, чому в NTFS важко знайти імена видалених файлів. Передбачимо, що кожен вузол вміщає лише три імена файлів і у вузол додається файл jjj.txt. На перший погляд все просто, але насправді ця операція наводить до видалення двох і створенню п'яти нових вузлів. Визначивши, де повинен знаходиться вузол jjj.txt, ми побачимо, що він повинен слідувати в кінці вузла С, за ім'ям iii.txt (рис. 1.15, вгорі). На жаль, це ім'я стане четвертим, тоді як вузол вміщає лише три імені. Отже, вузол С розбивається надвоє, ім'я ggg.txt зміщується на один рівень вгору, і в дереві створюються вузли F і G з іменами з вузла С (рис. 17.15, внизу). На жаль, тепер з'ясовується, що вузол А містить чотири значення. Відповідно, він розбивається надвоє, і значення ggg.txt переміщається на рівень вище (рис. 17.16). Додавання одного файлу привело до видалення вузлів А і С і додаванню вузлів F, G, Н, J і J. Всі дані, що залишилися у вузлах А і С від раніше видалених файлів, до цього моменту можуть бути втрачені. Тепер видалимо файл zzz.txt. Операція виключає ім'я з вузла Е і не вимагає інших змін. Залежно від реалізації інформація файлу zzz.txt може залишатися у вузлі; можливо, її вдасться відновити.
З видаленням файлу fff.txt справа йде складніше. Вузол F стає порожнім, і його необхідно заповнити. Значення eee.txt переміщається з вузла І у вузол F, а значення bbb.txt — з вузла В у вузол I. Дерево залишається збалансованим, а все листя знаходиться на однаковій відстані від вузла Н (рис. 17.17).
У вільному просторі вузла В знаходиться значення bbb.txt, тому що значення bbb.txt було переміщено у вузол I. Програма аналізу може показати, що файл bbb.txt був видалений, але насправді це не так — він просто перемістився із-за видалення fff.txt. Я продемонстрував процес додавання і видалення значень з дерева з єдиною метою: показати, наскільки складною може виявитися ця процедура. У файлових системах, що використовують прості списки імен в каталогах (наприклад, FAT), легко дізнатись, чому видалене ім'я існує (або не існує) в системі. При використанні деревовидних структур передбачити кінцевий результат операції буває дуже важко. Атрибути індексів NTFS Отже, ми розглянули загальну концепцію В-дерев; тепер потрібно розібратися, як вони реалізуються в NTFS при побудові індексів. Для кожного елементу даних в дереві створюється структура даних, названа індексним елементом і призначена для зберігання значень кожного вузла. Існує багато типів індексних елементів, але вони завжди містять однаковий набір полів заголовка. Наприклад, індексний елемент каталогу містить декілька заголовних полів і атрибут $FILE_NAME. Індексні елементи об'єднуються в деревовидну структуру і зберігаються у вигляді списку. Порожній елемент позначає кінець списку. На рис. 17.18 показаний приклад вузла в індексі каталога, який містить чотири індексні елементи $FILE_NAME. Для зберігання індексних вузлів можуть використовуватися два типи атрибутів записів MFT. Атрибут $INDEX_RООT завжди є резидентним і містить тільки один вузол з невеликим числом індексних елементів. Атрибут $INDEX_RООT завжди відповідає кореневому вузлу індексного дерева.
У великих індексах створюються нерезидентні атрибути $INDEX_ALLOCATION, які не обмежуються по кількості вузлів. Вміст цього атрибуту є великим буфером з одним або декількома індексними записами. Індексний запис має статичний розмір (зазвичай 4096 байт) і містить список індексних елементів. Кожному індексному запису привласнюється адреса, починаючи з 0. На рис. 17.19 показаний атрибут $INDEX_RООT з трьома індексними елементами і нерезидентним атрибутом $INDEX_ALLОCATIОN; останньому був виділений кластер 713, і він використовує три індексні записи.
Атрибуту $INDEX_ALLОCATIОN може виділятися простір, не використовуваний для зберігання індексних записів. Атрибут $BITMAP управляє станом виділення індексних записів. Якщо в дереві потрібно буде створити новий вузол $BITMAP використовується для пошуку вільних індексних записів; якщо знайти запис не вдалося, додається новий простір. Кожному індексу присвоюється ім'я; це ж ім'я має бути присутнім в заголовку атрибутів $INDEX_RООT, $INDEX_ALLОCATIОN і $В1ТМАР. Кожен індексний елемент володіє прапором, який показує, чи має він дочірні вузли. Якщо такі вузли є, адреси їх індексних записів вказуються в індексному елементі. Індексні елементи вузла зберігаються у відсортованому порядку, і якщо шукане значення менше значення індексного елементу, а в останнього є дочірній вузол, ми звертаємося до дочірнього вузла. Діставшись до порожнього елементу в кінці списку, ми звертаємося до його дочірнього вузла.
Розглянемо декілька прикладів. Спершу візьмемо індекс з трьома елементами, що поміщаються в $INDEX_RООT. В цьому випадку пам'ять виділяється лише для атрибуту $INDEX_RООT, який містить три структури даних індексних елементів і порожній елемент в кінці списку (рис. 17.20 (А). Наступний індекс містить 15 елементів, які не поміщаються в $INDEX_RООT, але поміщаються в атрибут $INDEX_ALLОCATIОN з одним індексним записом (рис. 17.20 (В)). Після заповнення всіх індексних елементів в індексному записі додається новий рівень, в результаті створюється дерево з трьох вузлів (рис. 17.20 (С)). Воно містить одне значення в кореневому вузлі і має два дочірні вузли. Кожен дочірній вузол знаходиться в окремому індексному записі одного атрибуту $INDEX_ALLОCATIОN, а посилання на нього містяться в елементах вузла $INDEX_RООT. Програми аналізу Для перегляду різних атрибутів в системі Windows можна скористатися програмою nfi.exe від компанії Microsoft. Програма виводить вміст MFT в робочій системі, включаючи імена атрибутів і адреси кластерів. При проведенні досліджень вона не принесе особливої користі, тому що система має бути «живою», проте програма допоможе у вивченні NTFS. Утиліта Марка Руссиновіча (Mark Russinovich) NTFSInfo виводить аналогічну інформацію. Пакет TSK дозволяє проглянути вміст будь-якого атрибуту. Опишемо синтаксис перегляду різних атрибутів. Пригадаємо, що кожен атрибут володіє типом і кожному атрибуту в записі MFT привласнюється унікальний ідентифікатор. За допомогою цих двох значень можна відображувати будь-який атрибут. Замість однієї адреси метаданих програмі icat передається адреса і тип атрибуту. За наявності декількох атрибутів такого типа до них додається унікальний ідентифікатор. Наприклад, аби проглянути атрибут $FILE_NAME (тип 48) запису MFT 34, слід використовувати запит «34-48». Для перегляду атрибуту $DATA (тип 128) запит набирає вигляду «34-128». Якщо існують інші атрибути $DATA, у запит також включається унікальний ідентифікатор атрибуту. Скажімо, для атрибуту з ідентифікатором 3 використовуватиметься рядок «34-128-3». Програма istat з пакету TSK виводить всі атрибути файлу. Приклад виводу для атрибутів запису MFT: [...] Type: $STANDARD_INFORMATION (16-0) Name: N/A Resident size: 72 Type: $FILE_NAME (48-2) Name: N/A Resident size: 84 Type: $ОBJECT_ID (64-8) Name: N/A Resident size: 16 Name: $DATA (128-3) Name: $Data Non-Resident, Encrypted size: 4294 94843 94844 94845 94846 94847 94848 102873 102874 Name: $DATA (128-5) Name: ADS Non-Resident. Encrypted size: 4294 102879 102880 102881 102882 102883 102884 102885 102886 Type: $LOGGED_UTILITY_STREAM (256-7) Name: $EFS Non-Resident size: 552 102892 102893
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-09-19; просмотров: 597; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.138.113.44 (0.013 с.) |