Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Основа категорії даних файлової системиСодержание книги
Поиск на нашем сайте
У UFS дані категорії файлової системи зберігаються в трьох видах структур даних: суперблоці, зведеннях груп циліндрів і дескрипторах груп. Суперблок знаходиться на початку файлової системи і містить основну інформацію про розмір і конфігурацію. В суперблоці зберігається посилання на область файлової системи, названу зведенням груп циліндрів; в ній міститься зведена інформація про використання груп циліндрів. Кожна група циліндрів містить структуру даних дескриптора групи з детальнішою інформацією про окрему групу. Далі всі ці структури даних будуть описані детальніше. Суперблок Суперблок UFS містить основні параметри файлової системи — такі, як розмір кожного фрагмента і кількість фрагментів в кожному блоці. Крім того, в ньому зберігається розмір кожної групи циліндрів і місцезнаходження різних структур даних в кожній групі. На підставі цієї інформації можна визначити конфігурацію файлової системи. В суперблоці також може зберігатися мітка тому і час останнього монтування файлової системи. Суперблок UFS грає ту ж роль, що і суперблок ExtX, але інформація про структуру і необов’язкові дані відрізняються. Суперблок UFS зберігається поблизу від початку файлової системи. На змінних носіях він може починатися в першому секторі. Зазвичай суперблок UFS1 знаходиться в 8, а суперблок UFS2 — в 64 кілобайтах від початку файлової системи. Також суперблок UFS2 може розташовуватися в 256 кілобайтах від початку файлової системи, але такий варіант розташування не є стандартним. Резервні копії суперблоку можуть бути присутніми у всіх групах циліндрів. У UFS1 і UFS2 використовуються структури даних, що злегка відрізняються, але в обох версіях їх розмір перевищує 1 Кбайт, а структури містять близько 100 полів. Суперблоки UFS1 і UFS2 відрізняються тим, що версія UFS2 включає 64-розрядні версії полів розміру і дати, які додаються в кінець структури даних. Невикористовувані 32-розрядні поля ігноруються і не використовуються для зберігання інших даних. У суперблоці також зберігається інша службова інформація — наприклад, загальна кількість вільних індексних вузлів, фрагментів і блоків. Із суперблоку можна дізнатись про місцезнаходження області, названим зведенням групи циліндрів. У цій області також зберігається таблиця із записами для всіх груп циліндрів; у записах документується кількість вільних блоків, фрагментів та індексних вузлів. Як буде показано пізніше, ця інформація також присутня в дескрипторе кожної групи. Суперблок містить інформацію про геометрію диска, яка використовується для найбільш ефективної організації і оптимізації файлової системи. Багато похідних значень зберігаються окремо, аби ОС не доводилося кожен раз обчислювати їх заново. Наприклад, розмір блоку зберігається як в байтах, так і у фрагментах. Крім того, є порозрядна маска і величини зрушень для перетворення адреси байта на адресу блоку і навпаки. Теоретично досить зберігати лише одне з цих значень, а останні обчислювати при необхідності. Не дивлячись на те що багато полів обов'язковими не є, в цьому розділі основна увага буде приділена як обов'язковим, так і необов'язковим даним, які можуть містити інформацію. Детальні описи структур даних приведені нами в розділ 2. Суперблоки як UFS1, так і UFS2 розглядатимуться на прикладі тестових образів файлових систем. Дескриптор групи циліндрів Як згадувалося раніше, файлова система ділиться на групи циліндрів. Всі групи (можливо, окрім останньої) володіють однаковим розміром; кожна група містить дескриптор з описом даної групи. Перша група починається на початку файлової системи, а кількість фрагментів в кожній групі задається в суперблоці. Окрім дескриптора, кожна група містить таблицю індексних вузлів і резервну копію суперблоку. Дескриптор групи UFS значно більший свого аналога в ExtX, хоча дані, що містяться в ньому, в основному не обов'язкові. Для зберігання дескриптора групи виділяється повний блок; дескриптор складається з набору стандартних полів і відкритої області, призначеної для зберігання різних таблиць. Стандартні поля містять службову інформацію і описують будову, яка завершує частини блоку. Такі службові дані, як місцезнаходження останнього виділеного блоку, фрагменту та індексного вузла, використовуються для підвищення ефективності створення файлів. Також присутня зведена інформація про кількість вільних блоків, фрагментів і індексних вузлів; ці параметри повинні збігатися із значеннями в зведенні груп циліндрів. Дескриптор групи також містить час останнього запису в групу (рис. 22.2).
Завершуюча частина дескриптора групи містить бітові карти індексних вузлів, блоків і фрагментів групи. У ній також зберігаються таблиці, що спрощують пошук суміжних фрагментів і блоків заданого розміру. Початкове місцерозташування кожного з цих структур даних задається у вигляді зсуву в байтах відносно початку дескриптора групи, а розмір структури даних зазвичай доводиться обчислювати. Як і в ExtX, в другому блоці кожної групи завжди зберігається таблиця дескрипторів груп. У UFSмісцезнаходження дескриптора групи, таблиці індексних вузлів і резервної копії суперблоку задається окремо для кожної файлової системи, а зсуви задаються в суперблоці. Наприклад, таблиця індексних вузлів може починатися в 32, а дескриптор групи — в 16 фрагментах від початку. У UFS1 ситуація додатково ускладнюється тим, що зсуви доповнюються базовим зрушенням, яке залежить від групи циліндрів. Наприклад, якщо для таблиці індексних вузлів заданий зсув в 32 фрагменти, вона може бути видалена на 32 фрагменти від початку групи 0, на 64 фрагменти від початку групи 1 і на 96 фрагментів від початку групи 2. Такий розкид вноситься для того, щоб скоротити наслідки від фізичних пошкоджень пластин на старих дисках. Групи циліндрів називаються так тому, що вони вирівнюються по границях циліндрів. На старих жорстких дисках кількість секторів в доріжці була постійною; це означало, що перші сектори всіх груп знаходилися на одній пластині. Коли б не розкид адміністративних даних, всі копії суперблоку знаходилися б на одній пластині. На нових жорстких дисках кількість секторів в циліндрах відрізняється, тому такої проблеми не існує, і в UFS2 розкид адміністративних даних вже не використовується. «Базове» зрушення кожної групи обчислюється на підставі двох параметрів із суперблоку — циклу (с) і дельти (d). Базове зрушення збільшується на d для кожної групи і повертається до початку через с груп. Наприклад, для кожної групи може вноситися зсув в 32 фрагменти, який потім буде повертатися до 0 після 16 груп. На рис. 22.3 показаний приклад будови систем UFS1 і UFS2. У файловій системі UFS1 адміністративні дані зберігаються з циклом 3, а в UFS2 використовується постійний зсув всередині кожної групи. Фрагменти до і після адміністративних даних можуть використовуватися для зберігання вмісту файлів.
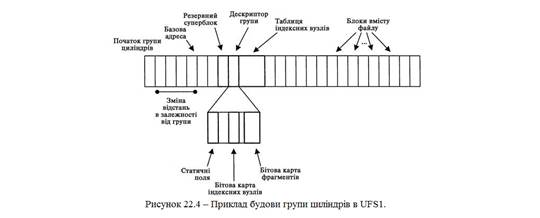
На рис. 22.4 показаний приклад групи. Базова адреса видалена на декілька блоків від початку групи, а резервний суперблок, дескриптор групи і таблиця індексних вузлів зберігаються в послідовному порядку. Всередині дескриптора групи зберігаються бітові карти і стандартні поля структур даних. Останні фрагменти призначені для вмісту файлів і каталогів.
Базова адреса задається змінною кількістю блоків від початку групи, а бітові карти зберігаються на статичній відстані від базової адреси. Завантажувальний код Якщо файлова система UFS містить ядро ОС, в ній також повинен бути присутнім завантажувальний код. Він зберігається в першому секторі файлової системи і слідує аж до суперблоку або структури даних розмітки диска. У BSD і Solaris використовуються власні схеми створення розділів. В системах IA32 (наприклад, x86/i386) створюється один розділ, всередині якого знаходиться один або декілька розділів BSD. Місцезнаходження розділів BSD визначається структурою розмітки диска в секторі 1 розділу DOS. Завантажувальний код знаходиться в секторі 0, а потім в секторах 2 і 5. У файловій системі UFS1 суперблок знаходиться в секторі 16, а в UFS2 — в секторі 128. У UFS2 завантажувальний код також займає додаткові сектори. У системі І386 Solaris також створюються два розділи DOS. Один має невеликі розміри і містить лише завантажувальний код. Другий містить файлову систему, а в його секторі 0 зберігається структура даних змісту тому VTOC (Volume Table of Contents). В дисків системи Sparc Solaris VTOC зберігається в секторі 0 диска, а завантажувальний код — в секторах 1-15. В нових системах Sparc Solaris замість VTOC може використовуватися таблиця розділів EFI. У файлових системах, що не містять завантажувального коду, сектори перед суперблоком не використовуються. На рис. 22.5 (А) показаний приклад диска FREEBSD для платформи IA32, а на рис. 22.5 (В) — приклад диску Sparc Solaris.
Приклад образу Приведемо результати виконання програми fsstat з пакету TSK (The Sleuth Kit) для образу UFS1. Цей образ використовуватиметься і надалі, так і при ручному аналізі дискових структур. Насправді вихідні дані fsstat займають значно більше місця, тому що в них включається детальна інформація по кожній групі циліндрів; я приведу лише найістотніші дані (лістинг 22.1):
Лістинг 22.1 – Результати виконання програми fsstat # fsstat -f openbsd openbsd.dd FILE SYSTEM INFORMATION - - - - - - - - - - - - - - - - File System Type: UFS 1 Last Written: Tue Aug 3 09:14:52 2004 Last Mount Point: /mnt
METADATA INFORMATION - - - - - - - - - - - - - - - - Inode Range: 0 – 3839 Root Directory: 2 Num of Avail Inodes: 3813 Num of Directories: 4
CONTENT INFORMATION - - - - - - - - - - - - - - - - Fragment Range: 0 – 9999 Block Size: 8192 Fragment Size: 1024 Num of Avail Full Blocks: 1022 Num of Avail Fragments: 16
CYLINDER GROUP INFORMATION - - - - - - - - - - - - - - - - Number of Cylinder Groups: 2 Inodes per group: 1920 Fragments per group: 8064
Group 0: Last Written: Tue Aug 3 09:14:33 2004 Inode Range: 0 – 1919 Fragment Range: 0 - 8063 Boot Block: 0 - 7 Super Block: 8 - 15 Super Block: 16 - 23 Group Desc: 24 - 31 Inode Table: 32 - 271 Data Fragments: 272 – 8063 Global Summary (from the superblock summary area): Num of Dirs: 2 Num of Avail Blocks: 815 Num of Avail Inodes: 1912 Num of Avail Frags: 11 Local Summary (from the group descriptor): Num of Dirs: 2 Num of Avail Blocks: 815 Num of Avail Inodes: 1912 Num of Avail Frags: 11 Last Block Allocated: 392 Last Fragment Allocated: 272 Last Inode Allocated: 7 […]
У вихідних даних fsstat наводиться загальна інформація — розміри блоку і фрагмента, кількість індексних вузлів.Також в них присутня інформація по окремих групах циліндрів, про те, які фрагменти входять до кожної групи і які ресурси були виділені останніми. У вихідних даних об’єднуються дані з суперблоку, із зведення груп циліндрів і з дескрипторів груп. Наприклад, за адресою блоку можна взнати, до якої групи він належить, а також визначити місцезнаходження таблиці індексних вузлів і дескриптора для кожної групи. Це особливо важливо для UFS1, оскільки ці адміністративні дані зберігаються з різними зсувами в групах. Звернемо увагу на присутність двох суперблоків в першій групі. Перша копія присутня тому, що в секторі 16 (тобто в блоці 8 даної файлової системи) завжди присутній суперблок. Наявність другої копії пояснюється тим, що в кожній групі циліндрів зберігається резервна копія із зсувом в 16 фрагментів.
Методи аналізу Аналіз даних категорії файлової системи направлений на пошук і обробку загальних відомостей про файлову систему з метою вживання додаткових методів аналізу. У файловій системі UFS аналіз починається з пошуку суперблоку в одному із стандартних місць. На підставі даних суперблоку визначаються місцерозташування кожної групи циліндрів і блоку даних. Резервні копії суперблоку присутні в кожній групі циліндрів. Аби знайти дескриптор конкретної групи, необхідно взяти зсув, вказаний в суперблоці, і додати його до базової адреси групи. У UFS2 базова адреса збігається з початком групи, але в групах циліндрів UFS1 вноситься розкид даних. Початкова адреса дескриптора обчислюється на підставі параметров (дельти і циклу), що зберігаються в суперблоці. Дескриптор групи використовується при визначенні стану виділення ресурсів групи. Остання важлива структура даних зберігається в області зведення груп цилиндрів. Її адреса задається в суперблоці, і вона містить таблицю з даними про використання кожної групи циліндрів. Зведення призначене для здобуття базової інформації про групи. Фактори аналізу В категорії даних файлової системи рідко зустрічаються яка-небудь інформація. В UFS ця категорія містить безліч необов'язкових даних, і виявлення прихованої інформації ускладнюється тісним переплетенням обов'язкових і необов’язкових даних. В кінці блоку, виділеного для зберігання суперблоку, зведення груп циліндрів або дескрипторів груп, можуть знаходитися невживані області. Аби виявити резервний простір тому, порівняємо розмір файлової системи з розміром тому. У суперблоці, дескрипторах груп і області присутня всіляка службова інформація. Якщо інцидент стався зовсім недавно, можливо, нам вдасться прийти до яких-небудь висновків відносно того, де знаходилися видалені файли або який файл був створений останнім. Зберігання декількох копій службових даних також дозволяє порівняти їх, якщо ви запідозрите стороннє втручання. Резервні копії суперблоку зберігаються в кожній групі циліндрів, а для їх пошуку можна скористатися сигнатурою цієї структури даних. Категорія вмісту До категорії вмісту відносяться дані про вміст файлів і каталогів. Основи категорії вмісту У UFS вміст файлів і каталогів зберігається у фрагментах і блоках. Фрагментом називається група суміжних секторів, а блоком — група суміжних фрагментів. Кожному фрагменту призначається адреса; нумерація адрес починається з 0. Адресація блоків здійснюється по першому фрагменту блоку. Перший блок і фрагмент розташовуються в першому секторі файлової системи. Мінімальний розмір блоку UFS складає 4096 байт, а максимальна кількість фрагментів у блоці рівне 8. Приклад зв'язку між блоками і фрагментами показаний на рис. 22.6: блок 64, що містить фрагменти 64-71, повністю виділяється файлу, а з блоку 72 виділяються фрагменти 74 і 75. Останні фрагменти блоку 72 можуть виділятися іншим файлам.
Один блок виділений повністю, в іншому блоці файлу виділено лише два фрагменти. Дворівневе виділення дискового простору (блоки і фрагменти) дозволяє виділяти великі об'єми суміжних блоків без втрати простору в останньому блоці. UFS намагається звести до мінімуму втрати простору в останньому блоці. Якщо файл може заповнити цілий блок, йому виділяється повний блок. При записі останньої порції даних виділяються фрагменти, необхідні для зберігання даних. Якщо файл збільшиться в розмірах і зможе заповнити цілий блок, дані будуть переміщені. Розглянемо приклад файлової системи з 8192 блоками і 1024 фрагментами. Для зберігання файлу, розмір якого дорівнює 20 000 байт, буде потрібно 2 блоки і 4 фрагменти. Ситуація показана на рис. 22.7: два блоки починаються у фрагментах 584 і 592. У двох блоках розміщуються 16 384 байти файлу, а що залишилися 3616 байт зберігаються у фрагментах 610-613. Перші два фрагменти блоку використовуються іншим файлом.
Стан виділення блоку або фрагмента визначається по одній з двох бітових карт. У одній карті біти відповідають фрагментам, а в іншій — блокам; взагалі кажучи, обидві карти повинні містити практично однакову інформацію, але бітова карта блоків дозволяє швидше знаходити великі суміжні блоки при створенні великих файлів. Бітові карти UFS відрізняються від «звичайних»: фактично в них зберігається інформація не про зайняті, а про вільні кластери. Таким чином, якщо біт дорівнює 1, відповідний блок доступний, а якщо біт дорівнює 0 — блок використовується. Бітові карти зберігаються в згадуваній раніше структурі даних дескриптора групи циліндрів. Отже, перед перевіркою стану виділення блоку необхідно визначити, в якій групі він знаходиться. Втім, це завдання вирішується легко, тому що для цього досить розділити адресу фрагмента на кількість фрагментів в групі циліндрів. Аби визначити положення потрібного біта в бітовій карті конкретного блока, слід обчислити початковий блок групи і відняти це значення з адреси блоку. Програма dstat з пакету TSK повідомляє стан виділення фрагмента UFS і вказує, до якої групи циліндрів він належить. Приклад виводу для тестового образу UFS1: # dstat -f openbsd openbsd.dd 288 Fragment: 288 Allocated Group: 0
Алгоритми виділення Проектувальники UFS доклали чималі зусилля до вироблення стратегій виділення, що забезпечують ефективне виділення блоків. Ймовірно, аналогічні роботи проводилися і для комерційних файлових систем, але їх результати не були опубліковані, і базове тестування навряд чи могло б дати повне представлення про використовувані алгоритми. Не дивлячись на наявність документованої стратегії виділення, реалізації ОС не зобов'язані їй слідувати — реалізація може вибрати іншу стратегію на свій розсуд. Перше, що враховується при виділенні блоків і фрагментів, — приналежність до групи циліндрів. Якщо ОС виділяє блоки для нового файлу і в групі циліндрів індексного вузла є доступні блоки, то система використовує блоки з цієї групи. Якщо при виділенні блоків для існуючого файлу кількість блоків, що належать одному файлу в рамках однієї групи, може обмежуватися; можливо, доведеться вибрати іншу групу циліндрів. Наприклад, багато ОС обмежують кількість блоків, що виділяються, для файлів і каталогів в одній групі на рівні 25-33 % від загальної кількості блоків. Досягши порогового значення вибирається нова група. Solaris використовує аналогічну стратегію: перші 12 блоків (прямі покажчики) файлів виділяються в межах однієї групи циліндрів, а останні блоки виділяються в інших групах. Після вибору групи циліндрів ОС виділяє блоки, керуючись об’ємом записуваних даних. Якщо розмір файлу невідомий або файл поступово збільшується, блоки виділяються послідовно з використанням стратегії пошуку наступного доступного блоку. Раніше для визначення оптимального місцезнаходження блоків враховувалася ротаційна затримка, але зараз просто використовується наступний суміжний блок. Якщо розмір відомий заздалегідь, дані діляться на ділянки; розмір однієї ділянки зазвичай дорівнює 16 блокам. Для виділення блоків в межах ділянки використовується стратегія пошуку першого доступного блоку. Таким чином, для 8192-байтових блоків розмір кожної ділянки буде рівний 128 Кбайт. Це значення налаштовується на рівні файлової системи і задається в суперблоці. Для завершуючої порції даних у файлі замість повного блоку виділяються фрагменти. ОС шукає серію послідовних фрагментів, розмір якої достатній для зберігання даних. Суміжні фрагменти не можуть пересікати кордон блоку, а інформацію про наявність фрагментів потрібної довжини можна отримати із службових даних файлової системи. При виділенні фрагментів для останніх даних файлу використовується стратегія пошуку першого вільного фрагмента. Якщо новими даними доповнюється файл, якому вже були виділені фрагменти, ОС намагається розширити виділену серію фрагментів. Якщо розширення неможливе, виділяється новий набір фрагментів або повний блок, а дані переміщаються. Якщо файл займає 12 повних блоків, фрагменти зазвичай не використовуються, а при розширенні файлу виділяються повні блоки. У суперблоці вказано, скільки вільних блоків повинно залишатися в системі на будь-який момент часу. Вільні блоки резервуються для того, щоб адміністратор міг увійти до системи і повернути її в нормальний стан, проте ОС не зобов'язана дотримувати встановлене обмеження. Всі протестовані мною системи BSD і Solaris стирали вміст невикористовуваних секторів у фрагментах. Отже, в резервному просторі виділених фрагментів марно шукати дані від видалених файлів. Методи аналізу Аналіз даних в категорії вмісту заснований на пошуку блоку або фрагменту, перегляді його вмісту і перевірці стану виділення. Для пошуку даних необхідно знати адресу фрагмента або блоку. Обива розміри зберігаються в суперблоці; пошук виконується простим зсувом від початку файлової системи до досягнення потрібної адреси. Адреса блоку відповідає адресі першого фрагменту в блоці. Аби перевірити стан виділення будь-якого фрагмента, необхідно спочатку визначити групу циліндрів, до якої він належить. Для цього адреса блоку ділиться на кількість фрагментів в групі. Місцезнаходження дескриптора групи визначається збільшенням зсуву, що зберігається в суперблоці, до базової адреси групи. Дескриптор групи містить бітову карту фрагментів. Аби отримати вміст всіх вільних фрагментів файлової системи, досить перебрати всі групи і проаналізувати всі бітові карти фрагментів. Фрагменти і блоки, використовувані для зберігання суперблоків, індексних таблиць, дескрипторів груп і зведення груп циліндрів, вважаються виділеними, хоча вони і не зв'язуються ні з яким конкретним файлом. Фактори аналізу Архітектура і стратегії виділення UFS надають ряд переваг експертам, але при цьому створюють і цілий ряд проблем. З одного боку, прив'язка блоків до індексних вузлів спрощує відновлення даних, а якщо видалені дані зберігаються в рідко використовуваних групах, вони існують довше, ніж видалені дані в інших групах. До переваг також можна віднести і те, що виділення серій суміжних блоків знижує фрагментацію, а ця обстовина спрощує роботу програм витягування даних. До проблем UFS можна віднести наявність завершуючого фрагмента. «Хвіст» файлу зазвичай опиняється в іншій групі циліндрів, оскільки для його зберігання необхідний лише один фрагмент. Розкид даних ускладнює їх витягання. З іншого боку, фрагменти часто дозволяють відновити більше даних, ніж ExtX із стиранням всіх байтів блоку. У UFS стирається лише вміст виділених фрагментів, так що окремі частини блоку продовжують існувати і після його повторного виділення. Відновлення дуже великих файлів (скажімо, вкладень в повідомленнях електронної пошти) ускладнюється тим, що такий файл може займати більше 25 % об’єму групи циліндрів; в цьому випадку залишок переміщається в іншу групу. Крім того, Solaris після виділення перших 12 блоків файлу переходить до нової групи циліндрів, що заважає роботі службових програм витягування даних. Звичайно, ОС, що створює файлову систему, не зобов'язана дотримувати всі правила UFS і слідувати всім стратегіям виділення. Категорія метаданих До категорії метаданих відносяться дані, що містять інформацію про файли і каталоги. У цьому розділі наведемо, де UFS зберігає дані і як організується їх аналіз. Основи категорії метаданих У UFS, як і в ExtX, метадані файлів і каталогів зберігаються в індексних вузлах. UFS2 також дає можливість зберегти додаткову інформацію про файл в розширених атрибутах. Ми розглянемо ці структури даних окремо. Індексні вузли Індексні вузли в UFS мало чим відрізняються від своїх аналогів в ExtX. Кожна група циліндрів містить таблицю індексних вузлів; місцезнаходження таблиці задається в суперблоці. У UFS1 всі індексні вузли ініціалізувалися при створенні файлової системи. У UFS2 використовуються динамічні індексні вузли: вони ініціалізувалися в міру потреби, а простір таблиці індексних вузлів може використовуватися для зберігання вмісту файлів, якщо всі інші блоки файлової системи виявляться заповненими. Для кожного файлу і каталогу виділяється один індексний вузол, в якому зберігається адреса блоків, виділених файлу, розмір файлу і тимчасові штампи. В індексних вузлах UFS зберігаються 12 прямих покажчиків на блоки і поодинці непрямому покажчику першого, другого і третього рівня. Адреса в кожному покажчику відноситься до повного блоку; виключення складає останній покажчик, який може посилатися на один або декілька фрагментів. Кількість фрагментів визначається розміром файлу. У UFS1 використовуються 32-розрядні покажчики, а в UFS2 — 64-розрядні. UFS підтримує розріджені файли. Якщо частина вмісту файлу не визначена або весь блок заповнений нулями, ОС зазвичай не виділяє блок з дискового простору. Замість цього в покажчик заноситься значення 0, а при читанні з файлу передається блок, заповнений нулями. Типи і дозволи доступу до файлів в UFS не відрізняються від використовуваних в ExtX. В індексних вузлах зберігаються час останньої модифікації, звернення і зміни, але час видалення не підтримується. З іншого боку, в UFS2 в індексні вузли доданий час створення. Значення тимчасових штампів зберігаються у вигляді кількості секунд, прошедших з 12:00 1 січня 1970 року у форматі UTC, а для підвищення точності також зберігається кількість наносекунд. У UFS1 використовуються 32-розрядні тимчасові штампи, а в UFS2 — 64-розрядні. Кожному індексному вузлу привласнюється адреса, нумерація адрес починається з 0. Звернемо увагу: в цьому відношенні UFS відрізняється від системи ExtX, в якій нумерація починається з 1. Індексні вузли 0 і 1 зарезервовані, але не задіяні ні для яких цілей. Індексний вузол 1 раніше містив інформацію про пошкоджені блоки. Вузол 2 зарезервований для кореневого каталогу. Стан виділення індексного вузла визначається по бітовій карті індексних вузлів, групи, що зберігається в дескрипторі. Аби визначити, до якої групи належить індексний вузол, слід розділити його адресу на кількість індексних вузлів в групі, взяту з суперблоку. Розширені атрибути Підтримка розширених атрибутів була реалізована в UFS2. В розширених атрибутах зберігаються додаткові дані про файл або каталог. Розширений атрибут є парою «ім'я-значення»; в даний час розширені атрибути діляться на два «типи»: призначений для користувача і системний простори імен. Атрибути призначеного для користувача простору імен можуть бути прочитані всіма користувачами, яким дозволено читання вмісту файлу. З іншого боку, атрибути системного простору імен можуть читатися лише привілейованими користувачами. В індексних вузлах UFS2 розширені атрибути представлені трьома полями. В одному полі зберігається розмір, а в двох інших — адреси блоків, в яких зберігаються атрибути. Блоки заповнюються структурами даних змінного розміру, що складаються із заголовка і значення атрибуту. Користувач призначає атрибути командою setextattr, а застосування читають їх викликами спеціальних системних функцій. Тестовий образ Далі наводяться вихідні дані, отримані в результаті виконання istat для тестового образу файлової системи. Приведемо виведення istat лише для того, щоб дати уявлення про доступну інформацію: # istat -f openbsd -z UTC openbsd.dd 3 і node: 3 Allocated Group: 0 uid / gid: 0 / 0 mode: -rw-r-r- size: 1274880 num of links: 1 Inode Times: Accessed: Tue Aug 3 14:12:56 2004 File Modified: Tue Aug 3 14:13:14 2004 Inode Modified: Tue Aug 3 14:13:14 2004
Direct Blocks: 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 [...] 1568 1569 1570 1571 1572 1573 1574 1575 1576 1577 1578 1579 1580 Indirect Blocks: 384 385 386 387 388 389 390 391 Ми бачимо, що файл займає 1247880 байт і для його зберігання потрібно більше 28-кілобайтних блоків. У нижній частині лістингу перераховані всі фрагменти, виділені для зберігання файлу. Раніше вже говорилося про те, що в індексному вузлі наводиться лише адреса блоку, але istat наводить адреси всіх фрагментів блоку. Останній рядок секції Direct Blocks показує, що використовуються лише п'ять з восьми фрагментів блоку 1576, а фрагменти 1581-1583 можуть використовуватися іншими файлами. Також звернемо увагу, що блок 384 використовується для непрямої адресації, тобто містить покажчики на інші блоки. Алгоритми виділення Документований метод виділення індексних вузлів в UFS збігається з ExtX. ОС може вибрати будь-який алгоритм, але на практиці індексний вузол для каталога зазвичай виділяється в новій групі циліндрів, число каталогів в якій менше середнього, а кількість вільних блоків — більше середнього. Індексний вузол файлу за наявності вільного місця виділяється в тій же групі циліндрів, в якій знаходиться батьківський каталог. При пошуку вільних індексних вузлів в групах циліндрів застосовується стратегія пошуку першого доступного вузла. При виділенні вміст індексного вузла стирається, а його М-, А- і С-час (а також час створення в UFS2) задаються рівними поточному часу. Лічильник посилань задається рівним 1 для файлів і 2 для каталогів (з врахуванням запису «.» в каталозі). При видаленні файлу системи BSD і Solaris стирають покажчики на блоки в індексних вузлах, очищають поля розміру і режиму. Отже, розмір файлу, його типу і місцезнаходження вмісту відновити не вдасться. Проте вміст блоків непрямих покажчиків не стирається, тому пошук таких блоків може надати допомогу при відновленні. Ймовірно, для пошуку блоків, заповнених 32- або 64-розрядними адресами, буде потрібно спеціальна програма. Звернемо увагу на відмінності між процедурою видалення в UFS і тій, що ми бачили в Linux/ExtX: в Linux поле режиму не стиралося, та зате в ExtX втрачався вміст непрямих покажчиків. Оновлення тимчасових штампів в OPENBSD 3, FREEBSD 5 і Sun Solaris 9 відбувається по тих же правилах, що і дляFedora Core 2. А саме, при створенні файлу всі тимчасові штампи синхронізуються з поточним часом, а в батьківського каталога оновлюється М- і С-час. При переміщенні в нового файлу оновлюється С-час, але М- і А-час залишається тим самим. При копіюванні файлу оновлюється А-час вихідного файлу, а в приймального файлу оновлюється М-, А- і С-час. При видаленні файлу обновляється М- і С-час. Методи аналізу Аналіз в категорії метаданих направлений на пошук інформації про файли для подальшого сортування і здобуття додаткової інформації. Для цього необхідно мати можливість знайти індексні вузли, перевірити їх стан виділення і обробити розширені атрибути (якщо вони існують). Пошук індексного вузла починається з ідентифікації його групи; для цього потрібно розділити адресу індексного вузла на кількість вузлів в групі. Потім індексна таблиця групи шукається по початковому фрагменту групи і зсуву індексної таблиці, вказаному в суперблоці. У UFS1 також необхідно обчислити додатковий зсув розкиду для групи. Нарешті, індексний вузол знаходиться в таблиці відніманням адреси індексного вузла з адреси першого індексного вузла в групі. Обробка індексних вузлів вельми прямолінійна. Перш ніж скористатися даними режиму і часу, необхідно спочатку декодувати і обробити ці дані. Вміст файлу шукається по адресах, що зберігаються в 12 покажчиках на блоки. Якщо файл має більший розмір, слід прочитати окремі блоки і обробити їх вміст як список адрес блоків. Покажчики із значенням 0 позначають розріджені блоки і відповідають блокам, заповненим нулями. При обробці останнього покажчика слід врахувати розмір файлу. Останній блок може бути фрагментом, і наступний фрагмент може використовуватися іншим файлом. Стан виділення індексного вузла перевіряється по бітовій карті індексних вузлів групи, що зберігається в дескрипторі групи. Дескриптор знаходиться за початковою адресою групи і зсувами в суперблоках. Якщо біт індексного вузла дорівнює 1, значить, індексний вузол виділений. Інколи буває корисно проаналізувати всі вільні індексні вузли, тому що в них можуть бути присутніми тимчасові штампи або інша інформація з видалених файлів. Для цього в бітових картах шукаються індексні вузли, біти яких дорівнюють 0, після чого обробляються вузли, відмінні від нуля. Індексні вузли, заповнені нулями, зазвичай раніше не використовувалися і знаходяться в ініціалізованому стані. Розширені атрибути також можуть містити докази і приховані дані, тому їх необхідно проаналізувати. Для цього слід прочитати блоки, перераховані в індексному вузлі, і обробити всі записи в них.
Фактори аналізу Велика частина чинників аналізу метаданих ExtX повною мірою застосовна до UFS. В індексних вузлах видалених файлів стираються покажчики на блоки, розмір і режим, але UFS зберігає стан непрямих покажчиків. А це означає, що програма відновлення може спробувати знайти непрямий покажчик і реконструювати файл. По М- і С-часу вільних індексних вузлів інколи вдається отримати інформацію про час видалення відповідних файлів. При витягуванні даних можна скористатися інформацією про стратегію виділення і зосередити увагу на окремій групі вузлів (замість всієї файлової системи). Як було показано для ExtX, команда touch дозволяє змінити М- і А-час будь-якого файлу. Отже, бажано мати у розпорядженні інше джерело інформації з тимчасовими даними для перевірки надійності тимчасових штампів. С-час файлу оновлюється при використанні команди touch. Часові штампи зберігаються у форматі UTC, тому для правильного виводу значень програмі аналізу має бути відомий часовий пояс, в якому знаходиться комп'ютер. Всі протестовані мною системи BSD записували нулі на місце невикористовуваних байтів в останньому фрагменті файлу, також званому резервним простором. Отже, дані з видалених файлів можна знайти тільки в одному місці — у вільних фрагментах. На щастя, виділяється і стирається лише відносно невелика кількість фрагментів. А це означає, що блок може містити видалені дані у фрагментах, які ще не були виділені повторно. Втім, резервний простір може містити приховані дані. Розширені атрибути у файловій системі UFS2 можуть використовуватися для зберігання невеликих об'ємів прихованих даних. Їх розмір обмежується двома блоками, але ми повинні перевірити, чи відображує програма аналізу їх вміст, і чи включається воно в пошук за ключовими словами. Приховані дані також можуть зберігатися в динамічних таблицях індексних вузлів UFS2. ОС не ініціалізувала блоки записів індексних вузлів в таблицях до моменту їх безпосереднього використання. Таким чином, дані можуть непомітно зберігатися в невживаних областях до того моменту, коли ОС їх зажадає і зітре вміст цих областей. Категорія даних імен файлів До категорії імен файлів відносяться дані, що зв'язують індексні вузли і інші метадані з іменами, зрозумілими для користувача. В цьому розділі розкажемо про те, де в UFS зберігаються дані і як організовується їх аналіз.
|
||||
|
|
Последнее изменение этой страницы: 2016-09-19; просмотров: 353; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.148.108.174 (0.012 с.) |