
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Методичні вказівки до Розв'язання задачСодержание книги
Поиск на нашем сайте
Приклад 1 Таблиця розподілу робітників за виконанням норм виробітку
Так як дані згруповані, середнє розраховується за формулою середньої арифметичної зваженої:
Для розрахунку показників варіації побудуємо таблицю розрахунку показників варіації та форми розподілу
У таблиці в графах 1-2 наведені проміжні дані, які розраховані для зручності користування формулами. Використаємо їх для розрахунку середнього лінійного відхилення та дисперсії для згрупованих даних:
Середнє квадратичне відхилення:
Відносні характеристики варіації: а) лінійний коефіцієнт варіації
або
Відносно низькі коефіцієнти варіації свідчать про однорідність сукупності робітників за виконанням норм виробітку. Для характеристики форми розподілу використаємо коефіцієнт асиметрії та ексцесу через моменти третього та четвертого порядку
Тоді
Розраховані значення свідчать про те, що розподіл робітників за виконанням норм виробітку лівосторонній з невеликою плосковерхістю. Побудуємо графік розподілу:
Приклад 2 Маємо такі дані про годинний виробіток деталей робітниками двох груп, які пройшли перепідготовку (N1) і не пройшли (N2), чисельністю 5 чол. кожна. Таблиця — Годинний виробіток робітників, які пройшли і не пройшли перепідготовку
Дисперсійний аналіз дає можливість визначити роль систематичної та випадкової варіації у загальній варіації і тим самим визначити роль фактора, покладеного в основу групування, в зміні результативної ознаки. Для цього використовують правило складання дисперсії, згідно з яким загальна дисперсія дорівнює сумі двох дисперсій: середньої із групових і міжгрупової:
Тісноту зв'язку характеризує співставлення міжгрупової дисперсії із загальною. Це відношення називається кореляційним відношенням :
Обчислимо ці параметри для наведеного прикладу. Спочатку обчислимо групові та загальні середні. Графи 2 таблиці є розрахунковими. Загальна дисперсія, яка характеризує загальну варіацію під впливом усіх факторів, дорівнює
Загальна середня дорівнює
Міжгрупова дисперсія, яка характеризує факторну варіацію, тобто відмінності у виробітку, обумовлені тим, що частина робітників пройшла перепідготовку, становить:
де
Це треба розуміти так, що 93,1 % всієї варіації обумовлено фактором, який покладено в основу групування, і тільки 6,9 % варіації є результатом дії інших. Такими, наприклад, можуть бути вік робітника, його стать та ін. Кореляційне відношення змінюється від 0 до 1. Коли міжгрупова дисперсія дорівнює нулю, що можливо лише тоді, коли всі групові середні однакові, тобто коли кореляційний зв'язок між середніми відсутній. Причому міжгрупова дисперсія дорівнює загальній, а середня з групових – нулю. Це означає, що кожному значенню факторної ознаки відповідає єдине значення результативної ознаки, тобто зв'язок між ознаками функціональний. Припустимо, що ми поділили робітників на дві групи за ознакою числа літер у прізвищі (парне чи непарне) і обчислені групові середні відрізняються. Але в цьому випадку різниця є випадковістю. Перевірку істотності (невипадковості) відхилень групових середніх здійснюють за допомогою статистичних критеріїв. У даному випадку можна використати критерій Фішера, або порівняти фактичне значення У таблиці розподіл залежить від числа ступенів вільності факторної К1 та випадкової К2 дисперсій.
де т — число груп; п — загальний обсяг сукупності. «Входами» в таблицю критичних значень є числа ступенів вільності К1, Кг та рівень значимості a, який задається дослідником і характеризує, в якій мірі він ризикує помилитися в своєму припущенні (про «невипадковість»).
Для нашого прикладу
а aоберемо на рівні 5 %. За таблицею критичних значень для рівня істотності a = 0,05 знаходимо Це означає, що тільки в 5 випадках із 100 може випадково виникнути кореляційне відношення, яке перевищує значення 0,399. Тепер треба порівняти фактичне значення з критичним. Якщо воно більше критичного, то зв'язок між факторною і результативною ознакою вважається істотним:
Тобто, зв'язок між фактом проходження робітником перепідготовки та зростанням продуктивності праці слід вважати істотним. Приклад 3 З отари овець загальною чисельністю 1000 голів (N) вибірковій контрольній стрижці було піддано 100 голів (n), середній настриг вовни при цьому становив 4,2 кг на одну вівцю при середньому квадратичному відхиленні 1,5 кг. Визначити межі, в яких знаходиться середній настриг вовни для усіх 1000 голів з імовірністю 0,954 (t = 2). У даному разі маємо простий випадковий відбір, до того ж, зрозуміло, безповторний. Підставимо дані у відповідні формули:
Тоді одне із можливих значень, в межах яких може знаходитись середній настриг вовни, розраховуєтся за формулою
У загальному вигляді це записується таким чином:
що дорівнює:
Таким чином, на підставі проведеної вибірки гарантуємо, що у 954 випадках із 1000 середній настриг вовни буде знаходитися в межах: від 3,9 до 4,4 кг на одну вівцю. Приклад 4 Маємо такі дані:
Обчислити індекс рівня споживання продуктів харчування на душу населення, якщо відомо, що чисельність населення зросла на 4%. Зрозуміло, що рівень споживання продуктів на душу населення ми обчислимо, якщо розділимо загальний обсяг споживання на чисельність населення:
таким чином
Згідно з умовою задачі ІT = 1,04. Залишається обчислити Іq. У звичайному вигляді він має форму (3). Для зручності ми рекомендуємо приводити в графах таблиць умовні позначення. Ми бачимо, що в умові задачі наведені агрегати, тобто знаменник, ми вже маємо. Необхідний чисельник ми обчислимо, використавши індивідуальні індекси.
Звідки
Отже, рівень споживання на душу населення збільшився на 3,8%.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-08-26; просмотров: 244; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.147.6.122 (0.008 с.) |

 .
.



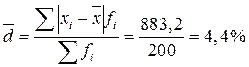 .
.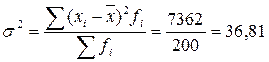

 .
. ,
, ,
, ,
, .
. ,
,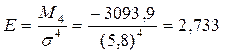 .
.

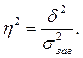





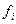 – число одиниць у групі, i — число груп. Таким чином, кореляційне відношення становить
– число одиниць у групі, i — число груп. Таким чином, кореляційне відношення становить (тобто 93,1%).
(тобто 93,1%).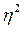 з критичним (табличним).
з критичним (табличним).
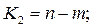


 .
.
 ,
, .
. .
. ,
, .
.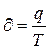 ;
;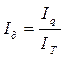 .
. (тобто 108,0%).
(тобто 108,0%). (тобто 103,8%).
(тобто 103,8%).


