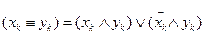Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Многоядерная архитектура и системы поточной обработки в ПКСодержание книги
Поиск на нашем сайте
Логические основы памяти с адресацией по содержанию. Основной операцией выполняемой на уровне ячейки является сравнение по критерию =.
АЯij , i=1..m,j=1..n АЯj=(АЯi1, АЯi1, … АЯin) ПАj=(ПА1, ПА1, … ПАn) M=(M1,M2…Mn) Mj=1,Пj –
P=(P1,P2…Pm)
Параллельно по словам и последовательно по разрядам:
Или
Лекция Полячков 13.10.2010
Пусть
Организация памяти с адресацией по содержанию.
АЗУ с поиском параллельно по словам и разрядам. Рисунок… Лекция 20.10.2010
Рассмотрим работу ассоциативной ячейки. Для записи в нее информации на входы Dj (1) и Dj (0) необходимо подать одну из комбинаций сигналов: «10» – запись единицы; «01» – запись нуля; «00» – маскирование записи. И при установке сигнала высокого уровня на вход Ai в запоминающий элемент ячейки будет записана соответствующая информация. Этим же сигналом активизируется считывание хранимого бита в инверсном виде с выхода Для сравнения бита поискового аргумента с содержимым ассоциативной ячейки на ее входы ACj (1) и ACj (0) нужно подать сочетание сигналов: «10» – при сравнении с единицей; «01» – при сравнении с нулем; «00» – при маскировании сравнения. В случае совпадения на выходе Pi сохранится уровень логической «1», в противном случае на нем установится уровень логического «0». Кроме того, комбинация сигналов «10» на входах ACj (1) и ACj (0) позволяет считать хранимый в АЯ бит с выхода Pi. Регистры аргумента поиска и маски служат для задания, хранения и сдвига маскированных поисковых аргументов. На их разрядных выходах формируются сигналы записи { Dj (1), Dj (0)} и сравнения { ACj (1), ACj (0)}. Целью анализатора многократного совпадение является выявление факта многократного совпадения (хотя бы 2 совпадения), и выделение одной приоритетной линии, поступающей из памяти фиксации реакций. Существуют алгоритмические и аппаратные методы извлечения многозначного ответа. Логика аппаратного метода извлечения многозначного ответа заключается в том что считываются активные линии в порядке возрастания или убывания адресов соответствующих активных линий.
Ассоциативное запоминающее устройство с поиском параллельным по словам и последовательным по разрядам.
Построение такого АЗУ на обычной памяти с произвольным доступом
Недостатки: · Для фиксации ассоциативных признаков необходимо зафиксировать блок информации. · Если нам необходимо модифицировать, хотя бы одно слово, необходимо осуществить перезапись всего слова (своими словами все проблемы из за того, что запись по строкам, а из строки нам нужен тока один разряд, т.е. они ортогональны.)
Для таких устройств могут быть использованы следующие разновидности сложного ассоциативного поиска: 1. Поиски в заданных пределов, и вне заданных пределов. В этом случае поиск проводится в 2 этапа. Сначала определяются слова удовлетворяющие одному пределу, а на втором этапе среди найденных на первом этапе слов ищем те, которые удовлетворяют второму пределу. 2. Поиск экстремальных значений, минимума или максимума. 3. Поиск ближайшего большего или ближайшего меньшего значения. Этот поиск проводится в 2 этапа. Сначала определяются слова в накопителе, меньшие указанного значения, записанного в аргументе поиска. Затем среди этих слов, находится максимальное. 4. Упорядоченная выборка. Данная процедура заключается в поиске, максимального или минимального числа, с последующем исключением найденных слов. 5. Поиск по соответствию – это поиск слов, содержащих максимального числа разрядов, совпадающих с разрядами поискового аргумента, т.е. слова с максимальным количеством совпавших аргументов. 6. Поиск на основе булевых функций. Здесь в различные булевы функции подставляются биты аргумента поиска, а результатом выполнения будет соответствующее значение.
АЗУ с поиском последовательно по словам, параллельно по разрядам. Используются в основном в устройствах фильтрации данных в каналах передачи информации, например в каналах передачи информации в темпе ее подачи (на лету).
Метод Фрея и Гольдберга Первоначально этот метод был предложен для записи информации в двоичной системе счисления. Однако он, как и другие рассмотренные ниже, допускает обобщение для случая записи данных в произвольной системе счисления. Достоинством метода является его простота. Для формирования следующего аргумента поиска в процессе поиска наименьшего (наибольшего) или следующего большего (меньшего) слова необходимо знать, имеется ли в АЗУ хотя бы одно слово с заданным признаком. Недостатком метода является более низкая эффективность по сравнению с другими алгоритмическими методами и зависимость общего числа опросов от количества разрядов (особенно при небольшом их количестве слов). Перед началом упорядоченной выборки все разряды регистра аргумента поиска маскируются. Для наглядности и компактности записи зададим общий вид аргумента поиска: ММ … ММ, dM … MM, dd … dM, dd … dd, где d – цифра в заданной системе счисления, а M – маскирующий символ. Рассмотрим алгоритм для случая, когда информация записана в АЗУ в двоичной системе счисления. Для поиска минимума необходимо крайний слева разряд регистра маски привести в состояние «0» и опросить АЗУ. Таким образом, исходный аргумент поиска примет вид 0 М … ММ. Если при этом индикатор совпадения показывает «1», т. е. имеются слова с признаком, содержащим в старшем разряде «0», то следующий ассоциативный поиск производится по поисковому аргументу 00 М … ММ. В противном случае следующий аргумент поиска имеет вид 1 М … ММ. При этом следующий поисковый аргумент имеет вид 10 М … ММ и т. д. Слово подлежит считыванию, когда в аргументе поиска отсутствуют разряды в состоянии М, а индикатор совпадения в результате ассоциативного сравнения установлен в «1». После нахождения минимального слова ищется ближайшее большее прибавлением к аргументу поиска единиц с учетом переносов. При этом может возникнуть ситуация, когда выявляется группа ближайших больших, среди которых нужно найти наименьший, который и будет ближайшим большим к минимуму. Схема алгоритма работы данного метода представлена на рис. 6.
Ожидаемое число опросов накопителя для выборки одного слова по методу Фрея и Гольдберга (для пуассоновского распределения вероятности наступления события при большом числе испытаний) вычисляется по формуле:
где r – основание системы счисления, m – число слов, среди которых производится выборка, n – число разрядов слов, по которым производится выборка. В двоичной системе счисления для считывания одного слова при упорядоченной выборке по этому методу требуется в среднем 5 обращений к ассоциативному накопителю.
Метод Сибера и Линдквиста Более эффективный метод упорядоченной выборки, при котором требуется меньшее число опросов ассоциативного накопителя, рассмотрен Сибером и Линдквистом и обобщен Джонсоном и Мак-Андрью для случая записи информации в любой системе счисления. При этом используются два индикатора совпадений: однократного (D) и многократного (Q). Схема алгоритма работы этого метода приведена на рис. 7. В начале процесса упорядоченной выборки опрос накопителя АЗУ производится по аргументу поиска, крайний слева разряд которого размаскрован и установлен в состояние «0». В отличие от предыдущего метода выборка может быть произведена и при не полностью размаскированном аргументе поиска dd … MM при наличии однократного совпадения (D = 1). В результате чего можно считывать найденное слово. При многократном совпадении (Q = 1) крайний левый замаскированный разряд аргумента поиска устанавливается в «0» (при выборке в порядке уменьшения – в «1»). После каждого опроса, не дающего совпадений или дающего одно совпадение, к самому крайнему справа размаскированному разряду аргумента поиска добавляется «1» с учетом переносов. Все «0», образованные операциями переносов, замещаются на M. При этом, если в результате опроса выявлено только одно слово, размаскированные разряды которого совпадают с размаскированными разрядами аргумента поиска, то оно выбирается. При упорядоченной выборке в порядке уменьшения прибавление «1» при задании следующего аргумента поиска заменяется вычитанием. По этому методу требуется в среднем 2,8 опросов для выборки слова.
Метод Левина Один из наиболее эффективных методов упорядоченной выборки из АЗУ с наименьшим необходимым числом опросов предложил Левин. Метод упорядоченной выборки Левина использует механизм индикации битовых срезов и требует наличия двух элементов памяти для хранения одного бита информации в ассоциативном накопителе. Это позволяет после одного опроса сразу установить, какого вида информация хранится в одноименном разряде (битовом срезе) всех слов, участвующих в упорядоченной выборке: только «0»; только «1»; как «0», так и «1» (обозначим через «Х»). При упорядоченной выборке по методу Левина каждый опрос накопителя производится в два этапа. Сначала выполняется обычный ассоциативный опрос по аргументу поиска, и выделяются слова, которые с ним совпадают. На втором этапе производится опрос только для этих слов. Содержание битовых срезов этих слов («0», «1» или «Х») считывается в выходной регистр. Это также позволяет выделить из всего массива слов в АЗУ те слова, которые участвуют в каждом шаге упорядоченной выборки. С каждым шагом число таких слов уменьшается – до тех пор, пока в результате первого этапа опроса не выявится всего одно слово, отвечающее аргументу поиска. При этом в результате опроса этого слова по словарной шине не может быть выявлена комбинация «Х». Это свойство опроса используется в методе Левина для того, чтобы установить факт нахождения слова, подлежащего считыванию. Схема алгоритма метода Левина показана на рис. 8.
Достоинством метода Левина является независимость количества опросов от числа разрядов в словах. Число опросов накопителя для выборки m слов по этому методу равно 2 m –1. Недостаток – необходимость наличия двух элементов памяти для хранения одного бита информации и усложнение логики управления в ассоциативном накопителе.
Метод Аронза Данный метод отличается от метода Левина тем, что опрос выделенных слов, участвующих в выборке, для определения содержания их разрядных срезов, производится дважды: первый раз для сравнения с «1», второй – с «0». На основании этих опросов можно судить о том, содержатся ли в данном разряде выделенных слов единицы и нули. Таким образом, один опрос по методу Левина заменяется двумя в методе Аронза. По методу Аронза для упорядоченной выборки m слов требуется 2(2 m –1) опросов накопителя.
Лекция 10.11.2010
Режим столбцовой маскируемой записи. Из-за несимметричности рассмотренной ячейки, запись проводится в 2 цикла, в первом цикле идет запись только 1 в выделенный столбец, во втором идет запись нулей. В первом такте в строке маскируются все другие столбцы, в данный столбец устанавливается 1. В столбце маскируются все разряды которые не соответствуют 1. Аналогично записываются 0. Таким образом за 2 цикла реализуется запись.
Здесь так же возможны режимы мультизаписи.
Режимы считывания. Режим строчного считывания. В этом режиме до сигнала опроса в регистр опроса ПА2 должен быть занесен позиционный адрес считываемого слова (униполярный). Остальные разряды маскируются. На входы подается комбинация:
Т.е. подается сравнение с 1. В выходном регистре получим Результат требуемой строки. Благодаря этому режиму мы можем получить значение результата в инверсной форме, нужно запросить сравнение с 0.
Режим строчного конъюнктивного считывания.
Для реализации режима построчного конъюнктивного чтения в регистр ПА2 должен быть записан аргумент, в котором 1 соответствуют адресуемым строкам считываемым в прямом коде, а 0 соответствуют строкам считываемом в инверсном коде, остальные разряды маскируются. И при подаче сигала опроса, в регистре РФ2 фиксируется слово, значение каждого разряда которого, является конъюнкцией соответствующих разрядов считываемых строк (в прямом или инверсном коде).
Аналогично строчному считыванию и строчному конъюнктивного считывания реализуются режимы соответствующего столбцового варианта.
Рассмотрим режимы ассоциативного поиска.
Режим ассоциативного поиска в ортокординатном АЗУ подобен режиму в традиционной однокоординатной памяти.
Режим столбцового ассоциативного поиска выполняется аналогично режиму строчного поиска.
Режимы строчного и столбцового ассоциативного поиска могут выполняться одновременно. На основе одномерных поисковых аргументов, может быть сформирован 2 мерный поисковый объект, на основе которого может быть осуществлена обработка «двумерно связной информации».
Так же возможен режим строчного или столбцового сравнения поисковых признаков, записанных в накопителе с данными поступающими в данное устройство «на лету», т.е. в ритме их подачи. Информация подается на данное устройство непосредственно с внешней шины.
Ассоциативное запоминающее устройство с матричным расположением поисковых аргументов (АЗУсМРПА).
Виды связности:
В таком устройстве можно использовать отдельно строку или столбец если понадобится. В общем, отдельный регистр АргП заменяется на матрицу. Маскирование может производится с помощью матрицы масок, либо с помощью нескольких регистров масок, если не требуется большая глубина маскирования, вплоть до отдельных регистров. Так же может быть реализовано несколько слоев АН (АН1, АН2, … АНN). Так же реализуется 3-я координата, означающая номер АН. Т.е. будет происходить покомпонентное сравнение с данными соответствующих слоев.
Многоядерная архитектура и системы поточной обработки в ПК За последние 4 года количество ядер возросло с 2 до 4 и более. Параллельность в программах – это способ управлять распределением общих ресурсов, используемых одновременно. Параллельность важна из-за:
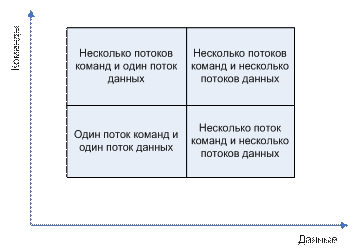
Токсономия Флина.
Параллелизм на уровне команд, известный как внеочередное выполнение команд, так называемый конвеер. Главная задача ликвидировать простаивание процессора. Параллелизм на уровне ОС. Исходит из использования многозадачных ОС. Позволяет скрывать время ожидания путем выполнения других программных потоков. Увеличение количества физических процессоров. Одновременная многопоточность – данная технология подразумевает дублирование в процессоре наиболее используемых блоков, что позволяет реализовать несколько логических процессоров на одном физическом, что позволяет увеличить производительность, но не так как дублирование всего процессора. Процессор сам решает как разделять и выполнять команда которые поступили от ОС’и на якобы разные процессоры. Многоядерные процессоры здесь дублируются исполнительные ядра. Что практически эквивалентно несколькими процессорами, здесь может присутствовать несколько технологий взаимодействия с КЭШ-памятью.
Многоядерность в отличие от гиперпоточности дает выигрыш в производительности при обращении к одинаковым ресурсам.
Оптимальная производительность на многоядерных архитектурах достигается за счет эффективного использования потоков для распределения создаваемых программным обеспечением рабочих нагрузок. Многопоточные приложения работающие на многоядерных платформах разрабатываются исходя из совсем других соображений нежли при использовании одноядерных процессоров. Основные области это кэширование и приоритеты процессов. При оценки эффективности параллельных программ.
Ускорение = Время лучшей посл. орг./ Время парал. орг.
Закон Амдала.
Амдал полагал что выигрыш ограничен последовательностью частью кода. Отсюда следует что распараллеливание программы важнее чем добавление новых ядер.
Программный поток – это отдельная последовательность связанных между собой команд, которая не зависит от других последовательностей команд. Каждая программа имеет хотя бы поток. Слишком большой объем поточной обработки может снизить производительность.
Существует 3 уровня потоков: 1. Пользовательского уровня 2. Потоки уровня ядра 3. Аппаратный уровень.
Лекция
Коэффициент Дайса:
Коэффициент Жаккара:
Коэффициент перекрытия:
11) Мера сходства Танимона: Данная мера может быть использована для сравнения векторов различной длины.
A,B – неупорядоченные набоы
12) Взвешенные меры сходства. Обычно наборы считаются независимыми и если компоненты являются зависимыми, то для оптимального разделения этих векторов, вместо скалярного произведения следует использовать внутреннее произведение. Недостаток – большое количество вычислений для нахождения ковариационной матрицы.
13)
[формула пропущена] Если используется не бинарная логика, то производятся замены операций:
Компромиссным вариантом агрегирования является использование линейной суммы:
Функция симметричная относительно своих аргументов:
14) Нечеткие меры: (смотри в лекциях по нечетких моделях и сетях)
15) Вариационные меры сходства. Используются, как правило, в задачах распознавания образов, в тех случаях если изображения подвержены искажениям или изменениям масштаба. Образы делятся а фрагменты и осуществляется изменение их положения или масштаба для достижения максимального сходства.
16)Сравнение по неизменным признакам:
Модели ассоциативной памяти.
Основными задачами ассоциативной памяти является следующее:
Общая модель ассоциативной памяти базируется на следующих положениях:
Классификация моделей ассоциативной памяти:
Модели памяти с адресацией по содержанию.
На этапе ассоциативной выборки при появлении некоторого ключа на выходе появляется некая реакция. Анализируя контекст можно анализировать информацию подлежащую выборке.
На этапе записи при формировании выходного образа записывается следующая информация с учетом влияния прошлой реакции. При снятии ключа будет выдаваться последовательность реакций с учетом ОС.
Классификация ассоциативных средств хранения и обработки информации.
Структурные признаки:
Функциональные признаки:
i. Максимального или минимального значения, хранимого в накопителе; ii. больших или меньших заданного; iii. внутри или вне заданных пределов; iv. ближайшей большей или ближайшей меньшей, заданного слова.
По способам выборки результатов ассоциативного поиска:
Области применения АЗУ. 1. Выполнение высокопроизводительных параллельных вычислений 2. Обработка изображений 3. Распознавание и анализ образов, сцен и ситуаций 4. Системы машинного перевода и логического вывода 5. Системы обработки нечеткой информации 6. В реализации функций операционной системы (КЭШ).
|
|||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-08-16; просмотров: 292; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.139.69.138 (0.017 с.) |





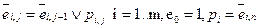
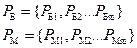



 .
.


 Рис. 7. Схема алгоритма метода упорядоченной выборки Сибера и Линдквиста
Рис. 7. Схема алгоритма метода упорядоченной выборки Сибера и Линдквиста
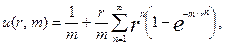
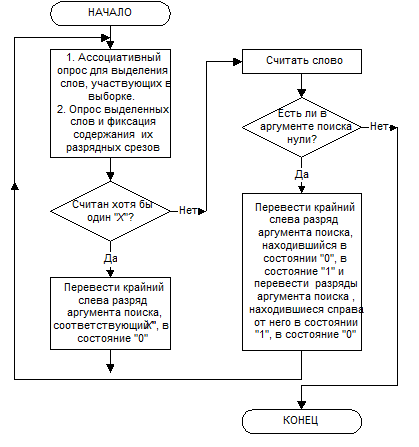 Рис. 8. Схема алгоритма метода упорядоченной выборки Левина
Рис. 8. Схема алгоритма метода упорядоченной выборки Левина
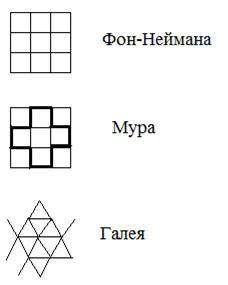


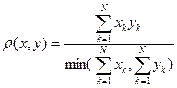


 Меры сходства на основе бинарной, многозначной и непрерывнозначной логики.
Меры сходства на основе бинарной, многозначной и непрерывнозначной логики.