
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Упорядоченная выборка информации из ассоциативной памяти.Содержание книги
Поиск на нашем сайте
1. Метод циклического обзора. Заключается в переборе всех возможных аргументов поиска в порядке возрастания (убывания) и опросе в соответствии с каждым аргументом. Имеется двоичный счетчик, который будет служить аргументом поиска для схемы. (Я рисунок не рисовал). В результате мы определяем совпавшее слово, оно затем считывается, и исключается из поиска. Очевидным достоинством этого метода является его простота. К основным блокам АЗУ добавляется лишь один счетчик. Кроме того не требуется маскировать разряды аргумента поиска. Однако существенным недостатком метода является то, что в случае достаточно большой разрядности и небольшого количества слов, хранящихся в АЗУ, эффективность выборки будет незначительной. Необходимое для выборки m n -разрядных слов число опросов накопителя равно 2 n / m, и при увеличении разрядности растет экспоненциально. 2. Метод поразрядного сравнения. Метод поразрядного сравнения основан на свойствах позиционной системы счисления. Для поиска минимума на каждом этапе отбираются те слова, которые имеют «0» в старших разрядах. В конце поиска остается только одно минимальное слово. Затем данное слово исключается из рассмотрения, и среди оставшихся снова отыскивается минимум и т. д. Другой вариант упорядоченной выборки методом поразрядного сравнения состоит в использовании поиска минимума и циклического повторения алгоритма поиска ближайшего большего с исключением найденных слов из дальнейшего рассмотрения. Эффективность упорядоченной выборки по этому методу зависит от особенностей программы поиска информации. Если реализуется описанная выше процедура, то максимальное число опросов при выборке m n -разрядных слов равно mn. 3. Основная идея этого метода состоит в том, что слова, подлежащие упорядоченной выборке, считываются по порядку (например, в порядке увеличения адреса слова в АЗУ), а их величина фиксируется в логической шкале. В качестве логической шкалы может быть использовано ОЗУ, в котором можно проводить выборку не только отдельных слов, но и их разрядов. В логическую шкалу по адресам, соответствующим словам, подлежащим упорядоченной выборке из АЗУ, записываются единицы; по остальным адресам логической шкалы записываются нули. Максимальное число ячеек логической шкалы равно 2 n, где n – число разрядов слов накопителя АЗУ. После окончания просмотра всех слов в накопителе АЗУ, подлежащих упорядоченной выборке, и записи единиц по соответствующим адресам логической шкалы производится собственно упорядоченная выборка. Для считывания минимального слова аргумент поиска устанавливается равным наименьшему адресу логической шкалы, по которому хранится единица. Следующий поисковый аргумент устанавливается равным следующему большему адресу ячейки логической шкалы, в которой хранится единица и т. д. Схема АЗУ для реализации описанного метода упорядоченной выборки приведена на рис. Общее число всех обращений к накопителю АЗУ и к логической шкале для выборки m слов равно 2 m + 2 n, где на опрос накопителя АЗУ приходится только m + 1 обращений, остальные обращения производятся к логической шкале. Недостатком описанного метода является увеличение требуемой емкости логической шкалы при возрастании числа разрядов в аргументе поиска.
Алгоритмические методы упорядоченной выборки информации. В настоящее время распространение получили следующие методы упорядоченной выборки из АЗУ: Фрея и Гольдберга, Сибера и Линдквиста, Левина, Аронза. Рассмотрим эти методы на примере упорядоченной выборки по возрастанию из однокоординатного АЗУ, базовая структура которого представлена на рис.
Метод Фрея и Гольдберга Первоначально этот метод был предложен для записи информации в двоичной системе счисления. Однако он, как и другие рассмотренные ниже, допускает обобщение для случая записи данных в произвольной системе счисления. Достоинством метода является его простота. Для формирования следующего аргумента поиска в процессе поиска наименьшего (наибольшего) или следующего большего (меньшего) слова необходимо знать, имеется ли в АЗУ хотя бы одно слово с заданным признаком. Недостатком метода является более низкая эффективность по сравнению с другими алгоритмическими методами и зависимость общего числа опросов от количества разрядов (особенно при небольшом их количестве слов). Перед началом упорядоченной выборки все разряды регистра аргумента поиска маскируются. Для наглядности и компактности записи зададим общий вид аргумента поиска: ММ … ММ, dM … MM, dd … dM, dd … dd, где d – цифра в заданной системе счисления, а M – маскирующий символ. Рассмотрим алгоритм для случая, когда информация записана в АЗУ в двоичной системе счисления. Для поиска минимума необходимо крайний слева разряд регистра маски привести в состояние «0» и опросить АЗУ. Таким образом, исходный аргумент поиска примет вид 0 М … ММ. Если при этом индикатор совпадения показывает «1», т. е. имеются слова с признаком, содержащим в старшем разряде «0», то следующий ассоциативный поиск производится по поисковому аргументу 00 М … ММ. В противном случае следующий аргумент поиска имеет вид 1 М … ММ. При этом следующий поисковый аргумент имеет вид 10 М … ММ и т. д. Слово подлежит считыванию, когда в аргументе поиска отсутствуют разряды в состоянии М, а индикатор совпадения в результате ассоциативного сравнения установлен в «1». После нахождения минимального слова ищется ближайшее большее прибавлением к аргументу поиска единиц с учетом переносов. При этом может возникнуть ситуация, когда выявляется группа ближайших больших, среди которых нужно найти наименьший, который и будет ближайшим большим к минимуму. Схема алгоритма работы данного метода представлена на рис. 6.
Ожидаемое число опросов накопителя для выборки одного слова по методу Фрея и Гольдберга (для пуассоновского распределения вероятности наступления события при большом числе испытаний) вычисляется по формуле:
где r – основание системы счисления, m – число слов, среди которых производится выборка, n – число разрядов слов, по которым производится выборка. В двоичной системе счисления для считывания одного слова при упорядоченной выборке по этому методу требуется в среднем 5 обращений к ассоциативному накопителю.
Метод Сибера и Линдквиста Более эффективный метод упорядоченной выборки, при котором требуется меньшее число опросов ассоциативного накопителя, рассмотрен Сибером и Линдквистом и обобщен Джонсоном и Мак-Андрью для случая записи информации в любой системе счисления. При этом используются два индикатора совпадений: однократного (D) и многократного (Q). Схема алгоритма работы этого метода приведена на рис. 7. В начале процесса упорядоченной выборки опрос накопителя АЗУ производится по аргументу поиска, крайний слева разряд которого размаскрован и установлен в состояние «0». В отличие от предыдущего метода выборка может быть произведена и при не полностью размаскированном аргументе поиска dd … MM при наличии однократного совпадения (D = 1). В результате чего можно считывать найденное слово. При многократном совпадении (Q = 1) крайний левый замаскированный разряд аргумента поиска устанавливается в «0» (при выборке в порядке уменьшения – в «1»). После каждого опроса, не дающего совпадений или дающего одно совпадение, к самому крайнему справа размаскированному разряду аргумента поиска добавляется «1» с учетом переносов. Все «0», образованные операциями переносов, замещаются на M. При этом, если в результате опроса выявлено только одно слово, размаскированные разряды которого совпадают с размаскированными разрядами аргумента поиска, то оно выбирается. При упорядоченной выборке в порядке уменьшения прибавление «1» при задании следующего аргумента поиска заменяется вычитанием. По этому методу требуется в среднем 2,8 опросов для выборки слова.
Метод Левина Один из наиболее эффективных методов упорядоченной выборки из АЗУ с наименьшим необходимым числом опросов предложил Левин. Метод упорядоченной выборки Левина использует механизм индикации битовых срезов и требует наличия двух элементов памяти для хранения одного бита информации в ассоциативном накопителе. Это позволяет после одного опроса сразу установить, какого вида информация хранится в одноименном разряде (битовом срезе) всех слов, участвующих в упорядоченной выборке: только «0»; только «1»; как «0», так и «1» (обозначим через «Х»). При упорядоченной выборке по методу Левина каждый опрос накопителя производится в два этапа. Сначала выполняется обычный ассоциативный опрос по аргументу поиска, и выделяются слова, которые с ним совпадают. На втором этапе производится опрос только для этих слов. Содержание битовых срезов этих слов («0», «1» или «Х») считывается в выходной регистр. Это также позволяет выделить из всего массива слов в АЗУ те слова, которые участвуют в каждом шаге упорядоченной выборки. С каждым шагом число таких слов уменьшается – до тех пор, пока в результате первого этапа опроса не выявится всего одно слово, отвечающее аргументу поиска. При этом в результате опроса этого слова по словарной шине не может быть выявлена комбинация «Х». Это свойство опроса используется в методе Левина для того, чтобы установить факт нахождения слова, подлежащего считыванию. Схема алгоритма метода Левина показана на рис. 8.
Достоинством метода Левина является независимость количества опросов от числа разрядов в словах. Число опросов накопителя для выборки m слов по этому методу равно 2 m –1. Недостаток – необходимость наличия двух элементов памяти для хранения одного бита информации и усложнение логики управления в ассоциативном накопителе.
Метод Аронза Данный метод отличается от метода Левина тем, что опрос выделенных слов, участвующих в выборке, для определения содержания их разрядных срезов, производится дважды: первый раз для сравнения с «1», второй – с «0». На основании этих опросов можно судить о том, содержатся ли в данном разряде выделенных слов единицы и нули. Таким образом, один опрос по методу Левина заменяется двумя в методе Аронза. По методу Аронза для упорядоченной выборки m слов требуется 2(2 m –1) опросов накопителя.
Лекция 10.11.2010
Режим столбцовой маскируемой записи. Из-за несимметричности рассмотренной ячейки, запись проводится в 2 цикла, в первом цикле идет запись только 1 в выделенный столбец, во втором идет запись нулей. В первом такте в строке маскируются все другие столбцы, в данный столбец устанавливается 1. В столбце маскируются все разряды которые не соответствуют 1. Аналогично записываются 0. Таким образом за 2 цикла реализуется запись.
Здесь так же возможны режимы мультизаписи.
Режимы считывания. Режим строчного считывания. В этом режиме до сигнала опроса в регистр опроса ПА2 должен быть занесен позиционный адрес считываемого слова (униполярный). Остальные разряды маскируются. На входы подается комбинация:
Т.е. подается сравнение с 1. В выходном регистре получим Результат требуемой строки. Благодаря этому режиму мы можем получить значение результата в инверсной форме, нужно запросить сравнение с 0.
Режим строчного конъюнктивного считывания.
Для реализации режима построчного конъюнктивного чтения в регистр ПА2 должен быть записан аргумент, в котором 1 соответствуют адресуемым строкам считываемым в прямом коде, а 0 соответствуют строкам считываемом в инверсном коде, остальные разряды маскируются. И при подаче сигала опроса, в регистре РФ2 фиксируется слово, значение каждого разряда которого, является конъюнкцией соответствующих разрядов считываемых строк (в прямом или инверсном коде).
Аналогично строчному считыванию и строчному конъюнктивного считывания реализуются режимы соответствующего столбцового варианта.
Рассмотрим режимы ассоциативного поиска.
Режим ассоциативного поиска в ортокординатном АЗУ подобен режиму в традиционной однокоординатной памяти.
Режим столбцового ассоциативного поиска выполняется аналогично режиму строчного поиска.
Режимы строчного и столбцового ассоциативного поиска могут выполняться одновременно. На основе одномерных поисковых аргументов, может быть сформирован 2 мерный поисковый объект, на основе которого может быть осуществлена обработка «двумерно связной информации».
Так же возможен режим строчного или столбцового сравнения поисковых признаков, записанных в накопителе с данными поступающими в данное устройство «на лету», т.е. в ритме их подачи. Информация подается на данное устройство непосредственно с внешней шины.
|
|||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-08-16; просмотров: 345; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.117.166.193 (0.009 с.) |



 Рис. 7. Схема алгоритма метода упорядоченной выборки Сибера и Линдквиста
Рис. 7. Схема алгоритма метода упорядоченной выборки Сибера и Линдквиста
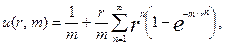
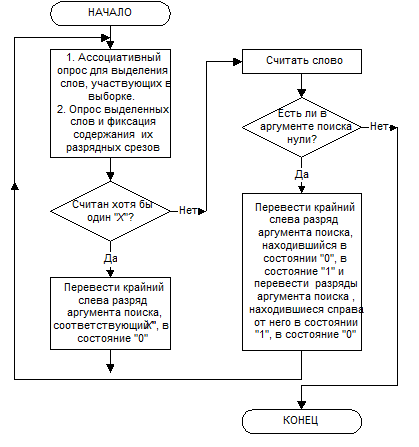 Рис. 8. Схема алгоритма метода упорядоченной выборки Левина
Рис. 8. Схема алгоритма метода упорядоченной выборки Левина



