Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Синтез микропрограммного автомата Мура по граф-схеме алгоритма.Содержание книги
Поиск на нашем сайте
Назначение ОЗУ · Хранение данных и команд для дальнейшей их передачи процессору для обработки. Информация может поступать из оперативной памяти не сразу на обработку процессору, а в более быструю, чем ОЗУ, кэш-память процессора. · Хранение результатов вычислений, произведенных процессором. · Считывание (или запись) содержимого ячеек. Особенности работы ОЗУ Оперативная память может сохранять данные лишь при включенном компьютере. Поэтому при его выключении обрабатываемые данные следует сохранять на жестком диске или другом носителе информации. При запуске программ информация поступает в ОЗУ, например, с жесткого диска компьютера. Пока идет работа с программой она присутствуют в оперативной памяти (обычно). Как только работа с ней закончена, данные перезаписываются на жесткий диск. Другими словами, потоки информации в оперативной памяти очень динамичны. ОЗУ представляет собой запоминающее устройство с произвольным доступом. Это означает, что прочитать/записать данные можно из любой ячейки ОЗУ в любой момент времени. Для сравнения, например, магнитная лента является запоминающим устройством с последовательным доступом.
Логическое устройство оперативной памяти Оперативная память состоит их ячеек, каждая из которых имеет свой собственный адрес. Все ячейки содержат одинаковое число бит. Соседние ячейки имеют последовательные адреса. Адреса памяти также как и данные выражаются в двоичных числах. Обычно одна ячейка содержит 1 байт информации (8 бит, то же самое, что 8 разрядов) и является минимальной единицей информации, к которой возможно обращение. Однако многие команды работают с так называемыми словами. Слово представляет собой область памяти, состоящую из 4 или 8 байт (возможны другие варианты). Типы оперативной памяти Принято выделять два вида оперативной памяти: статическую (SRAM) и динамическую (DRAM). SRAM используется в качестве кэш-памяти процессора, а DRAM - непосредственно в роли оперативной памяти компьютера. SRAM состоит из триггеров. Триггеры могут находиться лишь в двух состояниях: «включен» или «выключен» (хранение бита). Триггер не хранит заряд, поэтому переключение между состояниями происходит очень быстро. Однако триггеры требуют более сложную технологию производства. Это неминуемо отражается на цене устройства. Во-вторых, триггер, состоящий из группы транзисторов и связей между ними, занимает много места (на микроуровне), в результате SRAM получается достаточно большим устройством. В DRAM нет триггеров, а бит сохраняется за счет использования одного транзистора и одного конденсатора. Получается дешевле и компактней. Однако конденсаторы хранят заряд, а процесс зарядки-разрядки более длительный, чем переключение триггера. Как следствие, DRAM работает медленнее. Второй минус – это самопроизвольная разрядка конденсаторов. Для поддержания заряда его регенерируют через определенные промежутки времени, на что тратится дополнительное время. Основными характеристиками ОЗУ являются информационная емкость и быстродействие. Емкость оперативной памяти на сегодняшний день выражается в гигабайтах.
7. Оперативная память ЭВМ. Структура запоминающего устройства с двухкоординатной выборкой Запоминающее устройство с произвольным доступом (сокращённо ЗУПД; также Запоминающее устройство с произвольной выборкой, сокращённо ЗУПВ; англ. RandomAccessMemory) — один из видов памяти компьютера, позволяющий единовременно получить доступ к любой ячейке (всегда за одно и то же время, вне зависимости от расположения) по её адресу на чтение или запись. Назначение ОЗУ · Хранение данных и команд для дальнейшей их передачи процессору для обработки. Информация может поступать из оперативной памяти не сразу на обработку процессору, а в более быструю, чем ОЗУ, кэш-память процессора. · Хранение результатов вычислений, произведенных процессором. · Считывание (или запись) содержимого ячеек. Особенности работы ОЗУ Оперативная память может сохранять данные лишь при включенном компьютере. Поэтому при его выключении обрабатываемые данные следует сохранять на жестком диске или другом носителе информации. При запуске программ информация поступает в ОЗУ, например, с жесткого диска компьютера. Пока идет работа с программой она присутствуют в оперативной памяти (обычно). Как только работа с ней закончена, данные перезаписываются на жесткий диск. Другими словами, потоки информации в оперативной памяти очень динамичны. ОЗУ представляет собой запоминающее устройство с произвольным доступом. Это означает, что прочитать/записать данные можно из любой ячейки ОЗУ в любой момент времени. Для сравнения, например, магнитная лента является запоминающим устройством с последовательным доступом. Типы оперативной памяти Принято выделять два вида оперативной памяти: статическую (SRAM) и динамическую (DRAM). SRAM используется в качестве кэш-памяти процессора, а DRAM - непосредственно в роли оперативной памяти компьютера. SRAM состоит из триггеров. Триггеры могут находиться лишь в двух состояниях: «включен» или «выключен» (хранение бита). Триггер не хранит заряд, поэтому переключение между состояниями происходит очень быстро. Однако триггеры требуют более сложную технологию производства. Это неминуемо отражается на цене устройства. Во-вторых, триггер, состоящий из группы транзисторов и связей между ними, занимает много места (на микроуровне), в результате SRAM получается достаточно большим устройством. В DRAM нет триггеров, а бит сохраняется за счет использования одного транзистора и одного конденсатора. Получается дешевле и компактней. Однако конденсаторы хранят заряд, а процесс зарядки-разрядки более длительный, чем переключение триггера. Как следствие, DRAM работает медленнее. Второй минус – это самопроизвольная разрядка конденсаторов. Для поддержания заряда его регенерируют через определенные промежутки времени, на что тратится дополнительное время. Основными характеристиками ОЗУ являются информационная емкость и быстродействие. Емкость оперативной памяти на сегодняшний день выражается в гигабайтах.
Структура запоминающего устройства с двухкоординатной выборкой:
Код адреса разделяется на 2 части, каждая из которых подается на дешифраторы X и Y. При обращении информация замыкается или считывается из одного из 2m запоминающих элементов. Записывается и считывается один разряд 2m/2 2m/2=2m
Достоинство используются два простых дешифратора вместо одного сложного 210 =1024 25 25 =32 32 =1024
числа выходов дешифраторов
Недостатки 1)сложные элементы памяти, допускающие двухкоординатную выборку. · 2) необходимо использовать несколько корпусов ОЗУ для запоминания многоразрядного слова.
8. Оперативная память ЭВМ. Структура запоминающего устройства со стековой организацией Запоминающее устройство с произвольным доступом (сокращённо ЗУПД; также Запоминающее устройство с произвольной выборкой, сокращённо ЗУПВ; англ. RandomAccessMemory) — один из видов памяти компьютера, позволяющий единовременно получить доступ к любой ячейке (всегда за одно и то же время, вне зависимости от расположения) по её адресу на чтение или запись. Назначение ОЗУ · Хранение данных и команд для дальнейшей их передачи процессору для обработки. Информация может поступать из оперативной памяти не сразу на обработку процессору, а в более быструю, чем ОЗУ, кэш-память процессора. · Хранение результатов вычислений, произведенных процессором. · Считывание (или запись) содержимого ячеек. Особенности работы ОЗУ Оперативная память может сохранять данные лишь при включенном компьютере. Поэтому при его выключении обрабатываемые данные следует сохранять на жестком диске или другом носителе информации. При запуске программ информация поступает в ОЗУ, например, с жесткого диска компьютера. Пока идет работа с программой она присутствуют в оперативной памяти (обычно). Как только работа с ней закончена, данные перезаписываются на жесткий диск. Другими словами, потоки информации в оперативной памяти очень динамичны. ОЗУ представляет собой запоминающее устройство с произвольным доступом. Это означает, что прочитать/записать данные можно из любой ячейки ОЗУ в любой момент времени. Для сравнения, например, магнитная лента является запоминающим устройством с последовательным доступом. Типы оперативной памяти Принято выделять два вида оперативной памяти: статическую (SRAM) и динамическую (DRAM). SRAM используется в качестве кэш-памяти процессора, а DRAM - непосредственно в роли оперативной памяти компьютера. SRAM состоит из триггеров. Триггеры могут находиться лишь в двух состояниях: «включен» или «выключен» (хранение бита). Триггер не хранит заряд, поэтому переключение между состояниями происходит очень быстро. Однако триггеры требуют более сложную технологию производства. Это неминуемо отражается на цене устройства. Во-вторых, триггер, состоящий из группы транзисторов и связей между ними, занимает много места (на микроуровне), в результате SRAM получается достаточно большим устройством. В DRAM нет триггеров, а бит сохраняется за счет использования одного транзистора и одного конденсатора. Получается дешевле и компактней. Однако конденсаторы хранят заряд, а процесс зарядки-разрядки более длительный, чем переключение триггера. Как следствие, DRAM работает медленнее. Второй минус – это самопроизвольная разрядка конденсаторов. Для поддержания заряда его регенерируют через определенные промежутки времени, на что тратится дополнительное время. Основными характеристиками ОЗУ являются информационная емкость и быстродействие. Емкость оперативной памяти на сегодняшний день выражается в гигабайтах. ЗУ со стековой организацией широко используется при построении системы прерываний ЭВМ, а также при программировании алгоритмов, связанных с обработкой данных типа вектор, массив (переменных с индексами). Стековые ЗУ обеспечивают запись, чтение информации в соответствии с правилом: последним пришёл, первым вышел (LIFO). В них при обращении доступна только одна ячейка – т.н. вершина стека. При записи в стек слово сначала записывается в вершину стека, а затем проталкивается внутрь ЗУ и т.д. при записи очередных слов. При выполнении операции чтения слово сначала выталкивается в вершину стека, а затем подаётся на выходную шину ЗУ. Технически такая память может быть реализована на основе сдвиговых регистров в количестве n – штук: количество сдвиговых регистров определяется разрядностью ячеек – n. Разрядность регистров сдвига определяется ёмкостью стека. Такая организация стека называется магазинной (стековой) памятью (рисунок 1). Одна из основных проблем магазинных ЗУ – переполнение стека, которое ведёт к потере информации, поэтому не допустимо. Следить за возможным переполнением должен сам программист. Недостаток ЗУ магазинного типа – большие затраты оборудования и, следовательно, высокая удельная стоимость: сдвиговые регистры сложнее обычных.
Структура магазинных ЗУ Стековые ЗУ по этой причине (с целью экономии оборудования) обычно организуются другим способом: вместо сдвига информации в них используется подвижный указатель вершины стека (УС). Структура стекового ЗУ представлена на рисунке 2. Операция записи осуществляется по сигналу ЗП: 1) ЗП: [УС]:=ВХ; 2) УС:=УС+1, т.е. сначала производится запись слова в вершину стека (в ячейку, на которую указывает УС), а затем УС инкрементируется. Операция чтения реализуется по сигналу чтения ЧТ: 1) УС:=УС-1; 2) ВЫХ:= [УС]. Технически УС реализуется на основе реверсивного счетчика. Следует отметить, что запоминающая часть стековых ЗУ обычно располагается в адресном пространстве ОП: часть ячеек ОП отводится под стек.
ЗИ при страничной адресации Может быть обеспечена любым вариантом страничной организации памяти без каких либо дополнений. Перед тем как передать управление программой пользователю операционная система расставляет в дискретных регистрах физический номера страниц. Это физические номера тех страниц, к которым программа пользователя разрешено обращаться. ОС расставляет их в дискретные регистры, соответственно тем материальным адресам, по которым программа пользователя будет к ним обращаться. Если по сведениям ОС некоторым материальным номера не должен использоваться в данной программе пользователя и ОС не выделило под него никакой физический страницы, то в соответственный дискртеторных регистр ОС занесет пустой номер физической страницы. Единственное дополнение, которое было бы желательно сделать в дешифратор, присоединенный к разрядом физические номера страницы в используемом адресе, который обнаруживая бы появления в этих разрядах пустого номера и.те. формировался бы сигнал прерывания или вызова супервайзера в случае попытки программы пользователя обращаться к закрытой странице памяти.
15. Организация виртуальной памяти Виртуальная память – технология управления памятью ЭВМ, разработанная для многозадачных операционных систем. При использовании данной технологии для каждой программы используются независимые схемы адресации памяти, отображающиеся тем или иным способом на физические адреса в памяти ЭВМ. Позволяет увеличить эффективность использования памяти несколькими одновременно работающими программами, организовав множество независимых адресных пространств, и обеспечить защиту памяти между различными приложениями. Также позволяет программисту использовать больше памяти, чем установлено в компьютере, за счет откачки неиспользуемых страниц на вторичное хранилище. При использовании виртуальной памяти упрощается программирование, так как программисту больше не нужно учитывать ограниченность памяти, или согласовывать использование памяти с другими приложениями. Для программы выглядит доступным и непрерывным все допустимое адресное пространство, вне зависимости от наличия в ЭВМ соответствующего объема ОЗУ. Применение механизма виртуальной памяти позволяет: · упростить адресацию памяти клиентским программным обеспечением; · рационально управлять оперативной памятью компьютера (хранить в ней только активно используемые области памяти); · изолировать процессы друг от друга (процесс полагает, что монопольно владеет всей памятью). В настоящее время эта технология имеет аппаратную поддержку на всех современных бытовых процессорах. В то же время во встраиваемых системах и в системах специального назначения, где требуется либо очень быстрая работа, либо есть ограничения на длительность отклика (системы реального времени) виртуальная память используется относительно редко. ВП разделена на аппаратно-независимую и аппаратно-зависимую части. Коротко рассмотрим, что и каким образом входит в аппаратно-зависимую часть подсистемы управления виртуальной памятью. При работе машины с ВП, используются методы страничной, сегментной и сегментно-страничной организации памяти. Рассмотрим первую форму организации ВП – страничную организацию (СО). При СО, все ресурсы памяти, как оперативной, так и внешней представляются для пользователя единым целым. Пользователь работает с общим адресным пространством. Виртуальная память разбивается на равные страницы, которые содержат определённое фиксированное количество ячеек памяти. Передача информации между памятью и диском всегда осуществляется целыми страницами. Страницы имеют фиксированную длину, обычно являющуюся степенью числа 2, и не могут перекрываться. На рисунке 1 изображена схема Страничной организации виртуальной памяти.
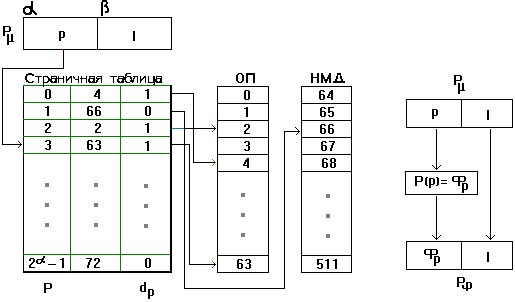
Рис.1 Страничная организация Виртуальной Памяти. Виртуальные адреса делятся на страницы (page), соответствующие единицы в физической памяти образуют страничные кадры (pageframes), а в целом система поддержки страничной виртуальной памяти называется пейджингом (paging). Виртуальный адрес в страничной системе упорядоченная пара (p,d), где p - номер страницы в виртуальной памяти, а d - смещение в рамках страницы p, где размещается адресуемый элемент. Система отображения виртуальных адресов в физические сводится к системе отображения виртуальных страниц в физические и представляет собой таблицу страниц, которая адресуется при помощи специального регистра процессора и позволяет определить номер кадра по виртуальному адресу. В большинстве современных компьютеров со страничной организацией виртуальной памяти все таблицы страниц хранятся в основной памяти, а быстрота доступа к элементам таблицы текущей виртуальной памяти достигается за счет наличия сверхбыстродействующей буферной памяти (кэша). Сегментно-страничная организация памяти требует более сложной аппаратурно-программной организации. На рисунке 2 подробно показан способ организации ВП с ССО. Адрес ячейки в данном случае складывается из 3х частей: первая содержит номер самого сегмента (S egment), по этому номеру машина обращается к сегментной таблице. Вторая часть адреса содержит номер искомой страницы (p age), которая находится внутри выбранного сегмента и третья смещение (l ength), по которому находится требуемый адрес. Pµ, обведенное в двойную рамку показывает математический адрес, а P ф физический. Как и при СО, смещение l переписывается в ячейку физического адреса без изменений. Вверху рисунка, аббревиатурой N обозначен номер какой-нибудь программы пользователя. А0с индексом 1 обозначает конкретный начальный адрес сегментной таблицы для данной программы. Сначала берется этот адрес и номер сегмента S из регистра математического адреса. Оба этих адреса складываются в сумматоре, который изображен в виде обведенного плюса. Получившийся адрес А1 + S является входом в сегментную таблицу (изображен в первой колонке сегментной таблицы). Далее, благодаря этому адресу, отыскивается соответствующий адрес страничной таблицы (А0 с индексом 2), который в свою очередь суммируется с номером искомой страницы p в сумматоре. Результирующая сумма есть вход в страничную таблицу. Структура страничной таблицы нам уже знакома.
Моделирование данных XML Техника моделирования данных является таким же необходимым инструментом управления XML-данными, как данными и в традиционных базах данных. Поэтому понятие модели данных по необходимости фигурирует в документации стандартов XML. Нужно, однако, заметить, что авторы стандартов XML употребляют "старомодную" трактовку понятия модели данных как структуры конкретного XML-документа, а не как инструмента моделирования таких информационных ресурсов. Одно из следствий такого подхода состоит в том, что остается в стороне вопрос о стандартизации операционных возможностей средств управления XML-данными. Хотя понятие модели данных упоминалось в прошлые годы в спецификациях ряда стандартов платформы XML, проблемы моделирования данных не были здесь основательно проработаны. Единой функционально полной, охватывающей как структурные, так и операционные возможности, специфицированной в явном виде модели данных, на которой бы базировались все стандарты платформы, не существует до сих пор и похоже, что в близкое время она вряд ли сможет появиться. Никакой деятельности в этом направлении в консорциуме пока не ведется. Вопросы моделирования данных обсуждаются лишь автономно в рамках спецификаций некоторых стандартов. При этом авторы имеют в виду только структурные аспекты моделирования данных. Исключение составляет стандарт DOM, определяющий API для репозиториев XML- и HTML-документов. Заметим, что хотя DOM может применяться к XML-данным, он не является стандартом платформы XML (приложением XML), а относится к ее окружению. В рамках проекта языка запросов XQuery опубликовано несколько документов. Среди них документы посвящены спецификации модели данных. Судя по наименованиям этих документов, авторы полагают, вероятно, что к модели данных имеет отношение лишь первый из этих документов, с чем нельзя согласиться.
17. Правильно построенный документ XML: общие правила синтаксиса XML XML (Extensible Markup Language – расширяемый язык разметки) – рекомендован W3C как язык разметки, представляющий свод общих синтаксических правил. XML предназначен для обмена структурированной информацией с внешними системами. Формат для хранения должен быть эффективным, оптимальным с точки зрения потребляемых ресурсов (памяти, и др.). Такой формат должен позволять быстро извлекать полностью или частично хранимые в этом формате данные и быстро производить базовые операции над этими данными. Каждый документ начинается декларацией – строкой, указывающей как минимум версию стандарта XML. В качестве других атрибутов могут быть указаны кодировка символов и внешние связи. <?xmlversion="1.0" encoding="UTF-8"?> Важнейшее обязательное синтаксическое требование заключается в том, что документ имеет только один корневой элемент. Это означает, что текст или другие данные всего документа должны быть расположены между единственным начальным корневым тегом и соответствующим ему конечным тегом. После декларации в XML-документе могут располагаться ссылки на документы, определяющие структуру текущего документа и собственно XML элементы (теги), которые могут иметь атрибуты и содержимое. Открывающий тег состоит из имени элемента, например <city>.Закрывающий тег, состоит из того же имени, но перед именем добавляется символ ‘/’, например </city>. Содержимым элемента (content) называется всё, что расположено между открывающим и закрывающим тегами, включая текст и другие (вложенные) элементы. В любом месте дерева может быть размещен элемент-комментарий. XML-комментарии размещаются внутри специального тега, начинающегося с символов <!-- и заканчивающегося символами -->. Два знака дефис (--) внутри комментария присутствовать не могут. <!-- Это комментарий. --> Остальная часть этого XML-документа состоит из вложенных элементов, некоторые из которых имеют атрибуты и содержимое. Элемент обычно состоит из открывающего и закрывающего тегов, обрамляющих текст и другие элементы. Текстовые блоки XML-документа не могут содержать символов, которые служат в написании самого XML: <, >, &. <description>в текстовых блоках нельзя использовать символы <,>,&</description> В таких случаях используются ссылки (указатели) на символы, которые должны быть заключены между символами & и;. Особо распространенными указателями являются: < – символ <; > – символ >; & – символ &; ' – символ апострофа ‘; " – символ двойной кавычки “. Таким образом, пример правильно будет выглядеть так: <description>в текстовых блоках нельзя использовать символы <, >, &</description> Если необходимо включить в XML-документ данные (в качестве содержимого элемента), которые содержат символы '<', '>', '&', '‘' и '“', чтобы не заменять их на соответствующие определения, можно все эти данные включить в раздел CDATA. Раздел CDATA начинается со строки "<[CDATA[", а заканчивается "]]>", при этом между ними эти строки не должны употребляться. Объявить раздел CDATA можно, например, так: <data><[CDATA[ 5 < 7 ]]></data> Корректность XML-документа определяют следующие два компонента: синтаксическая корректность (well-formed): то есть соблюдение всех синтаксических правил XML; действительность (valid): то есть данные соответствуют некоторому набору правил, определённых пользователем; правила определяют структуру и формат данных в XML.ВалидностьXML документа определяется наличием DTD или XML-схемы XSD и соблюдением правил, которые там приведены. Пример: <?xml version="1.0" encoding="UTF-8"?> <menu:nodesxmlns:xsi=”http://www.w3.org/2001/XMLSchema-instance” xmlns:menu="http://bvf.by/main-menu" xsi:schemaLocation="http://bvf.by/main-menu xsd/main-menu.xsd"> <node> <title>menu_main</title> <url>/BVFApp/</url> </node> <node> <title>menu_federation</title> <nodes> <node> <title>menu_federation_direction</title> <!--<url>/BVFApp/faces</url>--> </node> </nodes> </node> </menu:nodes>
18. Интерфейсы анализаторов XML: доступ и манипулирование содержанием и структурой XML XML как набор байт в памяти, запись в базе или текстовый файл представляет собой данные, которые еще предстоит обработать. То есть из набора строк необходимо получить данные, пригодные для использования в программе. Поскольку ХML представляет собой универсальный формат для передачи данных, существуют универсальные средства его обработки – XML-анализаторы (парсеры). Парсер – это библиотека, которая читает XML-документ, а затем предоставляет набор методов для обработки информации этого документа. Существует три подхода (API) к обработке XML-документов: DOM (DocumentObjectModel – объектная модель документов) – платформенно-независимый программный интерфейс, позволяющий программам и скриптам управлять содержимым документов HTML и XML, а также изменять их структуру и оформление. Модель DOM не накладывает ограничений на структуру документа. Любой документ известной структуры с помощью DOM может быть представлен в виде дерева узлов, каждый узел которого содержит элемент, атрибут, текстовый, графический или любой другой объект. Узлы связаны между собой отношениями родитель-потомок. SAX (Simple API for XML) базируется на модели последовательной одноразовой обработки и не создает внутренних деревьев. При прохождении по XML вызывает соответствующие методы у классов, реализующих интерфейсы, предоставляемые SAX-парсером. StAX (Streaming API for XML) не создает дерево объектов в памяти, но,в отличие от SAX-парсера, за переход от одной вершины XML к другой отвечает приложение, которое запускает разбор документа. Анализаторы, которые строят древовидную модель, – это DOM-анализаторы. Анализаторы, которые генерируют события, – это SAX-анализаторы. Анализаторы, которые ждут команды от приложения для перехода к следующему элементу XML – StAX-анализаторы. В первом случае анализатор строит в памяти дерево объектов, соответствующее XML-документу. Далее вся работа ведется именно с этим деревом. Во втором случае анализатор работает следующим образом: когда происходит анализ документа, анализатор вызывает методы, связанные с различными участками XML-файла, а программа, использующая анализатор, решает, как реагировать на тот или иной элемент XML-документа. Так, анализатор будет генерировать событие о том, что он встретил начало документа либо его конец, начало элемента либо его конец, символьную информацию внутри элемента и т.д. StAX работает как Iterator, который указывает на наличие элемента с помощью метода hasNext() и для перехода к следующей вершине использует метод next(). Когда следует использовать DOM-, а когда – SAX, StAX -анализаторы? DOM-анализаторы следует использовать тогда, когда нужно знать структуру документа и может понадобиться изменять эту структуру либо использовать информацию из XML-файла несколько раз. SAX/StAX-анализаторы используются тогда, когда нужно извлечь информацию о нескольких элементах из XML-файла либо когда информация из документа нужна только один раз. DOM – это специальная, языково-независимая интерфейсная модель разбора XML и HTML документов. Существует три уровня моделей DOM: DOM Level 1 – описывает основные интерфейсы, DOM Level 2 – вводит дополнение XML Namespaces, DOM Level 3 – определяет методы Load и Save. Модель DOM Level 1 – описана выше. Модель DOM Level 2 вводит использование стилевых таблиц, определяет модель сообщений и XML Namespaces. В сущности namespaces (пространства имен) используются для того чтобы разрешить многократный доступ к словарям XML при этом используясь в одном XML документе. Для того чтобы присвоить какому либо элементу универсальный идентификатор нужно к тегу стоящему выше его по иерархии DOM добавить параметр вида "xmlns:indentefier="URI", где indentefier это имя идентификатора, а URI – сам идентификатор. Для его использования надо к используемому элементу добавить спереди имя идентификатора indentefier и двоеточие. <?xml version="1.0"?> <html xmlns:xhtml="www.w3c.org/tr/xhtml" xmlns:books="www.piter-press.ru"> <xhtml:title>Это заголовок документа XHTML</xhtml:title> <book> <books:title>А здесь должен быть заголовок книжки</books:title> </book> </html> В даном случае в корневом теге <html> описано два пространства имен – xhtml и books. Теперь в этом документе можно использовать одни и те же элементы, но с разным значением, ставя перед ними имя пространства имен и двоеточие. DOM Level 3 На данный момент это последняя версия DOM. Спецификация этой модели состоит из трех частей: DOM3-ASLS, DOM3-Core, DOM3-Events, DOM3-XPath. DOM ASLS (Abstract Schemas and Load and Save specification) – эта спецификация определяет схемы DTD и XML Schemas, а также методы Load and Save. Методы LoadandSave, как можно догадаться из названия должны загружать и сохранять содержимое DOM-модели. Спецификация DOM3 Events – описывает модель сообщений и в основном базируется на DOM2 Events. Особенного внимания заслуживает спецификация DOM3-XPath. Эта спецификация определяет простой набор интерфейсов для доступа к дереву DOM через XPath 1.0. Модель данных Используемая в XSLT модель данных аналогична используемой в XPath с определенными дополнениями, описанными в этом разделе. XSLT оперирует с исходными, конечными документами и документами стилей, используя одну и ту же модель данных. Любые два XML документа, имеющие одно и то же дерево, будут обрабатываться XSLT одинаковым образом. Инструкции обработки и комментарии в стиле игнорируются: стиль обрабатывается так, как если бы в представляющем его дереве не было представлено ни узлов инструкций обработки, ни узлов комментариев. Непосредственный потомок корневого узла Обычные ограничения для непосредственного потомка корневого узла на конечное дерево не распространяется. Конечное дерево может иметь в качестве непосредственных потомкоы любую последовательность узлов, которые можно использовать как узел элемента. В частности, оно может иметь непосредственным потомком текстовый узел и любое количество узлов элементов. Если вывод осуществляется с помощью метода output из XML (см. главу [16 Вывод]), то может оказаться, что конечное дерево не является корректным XML документом. Однако оно корректной внешней общей разобранной сущностью будет всегда. Если исходное дерево создано разбором корректного XML документа, корневой узел в исходном дереве автоматически удовлетворяет обычным ограничениям: непосредственным потомком не может быть текстовый узел, а может быть только один элемент. Когда исходное дерево создано как-нибудь иначе, например, с помощью DOM, то обычные ограничения ни на исходное дерево, ни на конечное не действуют. Базовый URI С каждым узлом связан URI, называемый его базовым URI, который используется для преобразования значений атрибутов, являющихся относительными URI, в абсолютные URI. Если элемент или инструкция обработки найдены во внешней сущности, то базовым URI для такого элемента или инструкции обработки будет URI этой внешней сущности. В противном случае базовым является URI самого документа. Базовым URI для узла документа является URI сущности документа. Базовым URI для текстового узла, узла комментария, узла атрибута и узла пространства имен является базовый URI родителя этого узла. Неразобранные сущности Корневой узел имеет схему отображения, которая определяет URI для каждой неразобранной сущности, декларированной в DTD данного документа. Этот URI создается из системного идентификатора и публичного идентификатора, указанного в декларации сущности. Чтобы для сущности найти URI, XSLT процессор может воспользоваться публичным идентификатором, вместо того чтобы обращаться к URI, указанному в системном идентификаторе. Если XSLT процессор для построения данного URI не пользуется публичным идентификатором, то он обязан воспользоваться системным идентификатором. Если системный идентификатор является относительным URI, он должен быть преобразован в абсолютный URI, используя в качестве базового URI того ресурса, который содержит декларацию данной сущности [RFC2396]. Удаление пробельных символов После построения дерева исходного документа или документа стиля, но перед какой-либо его обработкой XSLT процессором, выполняется очистка (stripping) некоторых текстовых узлов. Текстовый узел вычищается только тогда, когда он содержит одни пробельные символы. При очистке текстовый узел удаляется из дерева документа. На вход процедура очистки получает перечень названий элементов, для которых следует сохранить пробельные символы. Процедура очистки применяется как для стилей, так и для исходных документов, однако перечень названий элементов, сохраняющих пробельные символы, для стилей и исходных документов определяется отдельно. Трансформации дерева Трансформация дерева конструирует результирующее дерево/resulttree. В XSL это дерево называется дерево элементов и атрибутов с объектами, изначально находящимися в пространстве имён "объекта форматирования". В этом дереве объект форматирования представлен как элемент XML со свойствами, представленными набором пар атрибут-значение XML. Содержимое объекта форматирования это содержимое элемента XML. Трансформация дерева определена в Рекомендациях XSLT [XSLT]. Таблица стилей XSL используется в дереве трансформации. Таблица стилей содержит набор правил конструирования дерева. Правила конструирования дерева состоят из двух частей: патэрна, который подставляется в элементы дерева-источника, и шаблона, который конструирует части результирующего дерева. Это позволяет применять таблицу стилей к широкому классу документов, имеющих похожие структуры деревьев-источников. В некоторых реализациях XSL/XSLT результат конструирования дерева может быть выведен как документ XML. Это позволяет выводить XML-документ, который содержит объекты форматирования и свойства форматирования. Такая возможность ни обязательна для процессора XSL, ни навязывается ему. Бывают, однако, случаи, когда это имеет важное значение, как при подготовке сервером ввода для известного клиента; например, способ, которым сервер WAP (http://www.wapforum.org/faqs/index.htm) подготавливает специальный вывод для ручных WAP- устройств. Для сохранения доступности дизайнеры Web-систем не должны создавать архитектуры, требующие наличия (или использующие) передачу документов, содержащих объе
|
||||
|
|
Последнее изменение этой страницы: 2016-08-06; просмотров: 443; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.118.1.63 (0.011 с.) |