
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Методы анализа больших систем, факторный анализСодержание книги
Поиск на нашем сайте
Данный параграф является заключительным и более не будет возможности осветить еще одну особенность методов системного анализа, показать вам еще один путь к достижению профессионального уровня в области управления экономическими системами. Уже ясно, что ТССА большей частью основывает свои практические методы на платформе математической статистики. Несколько упреждая ваш рабочий учебный план (курс математической статистики — предмет нашего сотрудничества в следующем семестре), обратимся к современным постулатам этой науки. Общепризнанно, что в наши дни можно выделить три подхода к решению задач, в которых используются статистические данные. · Алгоритмический подход, при котором мы имеем статистические данные о некотором процессе и по причине слабой изученности процесса его основная характеристика (например, эффективность экономической системы) мы вынуждены сами строить “разумные” правила обработки данных, базируясь на своих собственных представлениях об интересующем нас показателе. · Аппроксимационный подход, когда у нас есть полное представление о связи данного показателя с имеющимися у нас данными, но неясна природа возникающих ошибок — отклонений от этих представлений. · Теоретико-вероятностный подход, когда требуется глубокое проникновение в суть процесса для выяснения связи показателя со статистическими данными. В настоящее время все эти подходы достаточно строго обоснованы научно и “снабжены” апробированными методами практических действий. Но существуют ситуации, когда нас интересует не один, а несколько показателей процесса и, кроме того, мы подозреваем наличие нескольких, влияющих на процесс, воздействий — факторов, которыеявляются не наблюдаемыми, скрытыми или латентными. Наиболее интересным и полезным в плане понимания сущности факторного анализа — метода решения задач в этих ситуациях, является пример использования наблюдений при эксперименте, который ведет природа, Ни о каком планировании здесь не может идти речи — нам приходится довольствоваться пассивным экспериментом. Удивительно, но и в этих “тяжелых” условиях ТССА предлагает методы выявления таких факторов, отсеивания слабо проявляющих себя, оценки значимости полученных зависимостей показателей работы системы от этих факторов.
Пусть мы провели по n наблюдений за каждым из k измеряемых показателей эффективности некоторой экономической системы и данные этих наблюдений представили в виде матрицы (таблицы).
Матрица исходных данных E [n·k]{3-26}
Пусть мы предполагаем, что на эффективность системы влияют и другие — ненаблюдаемые, но легко интерпретируемые (объяснимые по смыслу, причине и механизму влияния) величины — факторы. Сразу же сообразим, что чем больше n и чем меньше таких число факторов m (а может их и нет вообще!), тем больше надежда оценить их влияние на интересующий нас показатель E. Столь же легко понять необходимость условия m < k, объяснимогона простом примере аналогии — если мы исследуем некоторые предметы с использованием всех 5 человеческих чувств, то наивно надеяться на обнаружение более пяти “новых”, легко объяснимых, но неизмеряемых признаков у таких предметов, даже если мы “испытаем” очень большое их количество. Вернемся к исходной матрице наблюдений E[n · k] и отметим, что перед нами, по сути дела, совокупности по n наблюдений над каждой из k случайными величинами E1, E2, … E k. Именно эти величины “подозреваются” в связях друг с другом — или во взаимной коррелированности. Из рассмотренного ранее метода оценок таких связей следует, что мерой разброса случайной величины E iслужит ее дисперсия, определяемая суммой квадратов всех зарегистрированных значений этой величины S( Eij )2 и ее средним значением (суммирование ведется по столбцу). Если мы применим замену переменных в исходной матрице наблюдений, т.е. вместо Ei j будем использовать случайные величины
Xij =
то мы преобразуем исходную матрицу в новую
X[n·k] {3-28}
Отметим, что все элементы новой матрицы X[n·k] окажутся безразмерными, нормированными величинами и, если некоторое значение Xij составит, к примеру, +2, то это будет означать только одно - в строке j наблюдается отклонение от среднего по столбцу i на два среднеквадратичных отклонения (в большую сторону).
Выполнимтеперь следующие операции. · Просуммируем квадраты всех значений столбца 1 и разделим результат на (n - 1) — мы получим дисперсию (меру разброса) случайной величины X1, т.е. D1. Повторяя эту операцию, мы найдем таким же образом дисперсии всех наблюдаемых (но уже нормированных) величин. · Просуммируем произведения соответствующих строк (от j =1 до j = n) для столбцов 1,2 и также разделим на (n -1). То, что мы теперь получим, называется ковариацией C12 случайных величин X1 , X2 и служит мерой их статистической связи. · Если мы повторим предыдущую процедуру для всех пар столбцов, то в результате получим еще одну, квадратную матрицу C[k · k], которую принято называть ковариационной. Этаматрица имеет на главной диагонали дисперсии случайных величин X i, а в качестве остальных элементов — ковариации этих величин (i =1…k). Ковариационная матрица C [k·k] {3-29}
Если вспомнить, что связи случайных величин можно описывать не только ковариациями, но и коэффициентами корреляции, то в соответствие матрице {3-29} можно поставить матрицу парных коэффициентов корреляции или корреляционную матрицу
R [k·k] {3-30}
в которой на диагонали находятся 1, а внедиагональные элементы являются обычными коэффициентами парной корреляции. Так вот, пусть мы полагали наблюдаемые переменные E iнезависящими друг от друга, т.е. ожидалиувидеть матрицу R [k·k]диагональной, с единицамив главной диагонали и нулями в остальных местах. Если теперь это не так, то наши догадки о наличии латентных факторов в какой-то мере получили подтверждение. Но как убедиться в своей правоте, оценить достоверность нашей гипотезы — о наличии хотя бы одного латентного фактора, как оценить степень его влияния на основные (наблюдаемые) переменные? А если, тем более, таких факторов несколько — то как их проранжировать по степени влияния? Ответы на такие практические вопросы призван давать факторный анализ. В его основе лежит все тот же “вездесущий” метод статистического моделирования (по образному выражению В.В.Налимова — модель вместо теории). Дальнейший ход анализа при выяснению таких вопросов зависит от того, какой из матриц мы будем пользоваться. Если матрицей ковариаций C [k·k], то мы имеем дело с методом главных компонент, если же мы пользуемся только матрицей R [k·k], то мы используем метод факторного анализа в его “чистом” виде. Остается разобраться в главном — что позволяют оба эти метода, в чем их различие и как ими пользоваться. Назначение обоих методов одно и то же — установить сам факт наличия латентных переменных (факторов), и если они обнаружены, то получить количественное описание их влияния на основные переменные Ei. Ход рассуждений при выполнении поиска главных компонент заключается в следующем. Мы предполагаем наличие некоррели-рованных переменных Zj (j=1…k), каждая из которых представляется нам комбинацией основных переменных (суммирование по i =1…k): Z j = S A j i · X i{3-31} и, кроме того, обладает дисперсией, такой что
D(Z 1 ) ³ D(Z 2 ) ³ … ³ D(Z k ). Поиск коэффициентов A j i(их называют весом j -й компонеты в содержании i -й переменной ) сводится к решению матричных уравнений и не представляет особой сложности при использовании компьютерных программ. Но суть метода весьма интересна и на ней стоит задержаться. Как известно из векторной алгебры, диагональная матрица [2·2] может рассматриваться как описание 2-х точек (точнее — вектора) в двумерном пространстве, а такая же матрица размером [k·k] — как описание k точек k -мерного пространства. Так вот, замена реальных, хотя и нормированных переменных X iна точно такое же количество переменных Z jозначает не что иное, как поворот k осей многомерного пространства. “Перебирая” поочередно оси, мы находим вначале ту из них, где дисперсия вдоль оси наибольшая. Затемделаем пересчет дисперсий для оставшихся k-1 осей и снова находим “ось-чемпион” по дисперсии и т.д. Образно говоря, мы заглядываем в куб (3-х мерное пространство) по очереди по трем осям и вначале ищем то направление, где видим наибольший “туман” (наибольшая дисперсия говорит о наибольшем влиянии чего-то постороннего); затем “усредняем” картинку по оставшимся двум осям и сравниваем разброс данных по каждой из них — находим “середнячка” и “аутсайдера”. Теперь остается решить систему уравнений — в нашем примере для 9 переменных, чтобы отыскать матрицу коэффициентов (весов) A [k·k]. Если коэффициенты A j i найдены, то можно вернуться к основным переменным, поскольку доказано, что они однозначно выражаются в виде (суммирование по j=1…k) X i = S A ji· Z j. {3-32} Отыскание матрицы весов A[k·k] требует использования ковариационной матрицы и корреляционной матрицы. Таким образом, метод главных компонент отличается прежде все тем, что дает всегда единственное решение задачи. Правда, трактовка этого решения своеобразна. · Мы решаем задачу о наличии ровно стольких факторов, сколько у нас наблюдаемых переменных, т.е. вопрос о нашем согласии на меньшее число латентных факторов невозможно поставить; · В результате решения, теоретически всегда единственного, а практически связанного с громадными вычислительными трудностями при разных физических размерностях основных величин, мы получим ответ примерно такого вида — фактор такой-то (например, привлекательность продавцов при анализе дневной выручки магазинов) занимает третье место по степени влияния на основные переменные. Этот ответ обоснован — дисперсия этого фактора оказалась третьей по крупности среди всех прочих. Всё… Больше ничего получить в этом случае нельзя. Другое дело, что этот вывод оказался нам полезным или мы его игнорируем — это наше право решать, как использовать системный подход!
Несколько иначе осуществляется исследование латентных переменных в случае применения собственно факторного анализа. Здесь каждая реальная переменная рассматривается также как линейная комбинация ряда факторов F j, но в несколько необычной форме X i = S B ji · Fj + D i. {3-33} причем суммирование ведется по j=1…m, т.е. по каждому фактору. Здесь коэффициент B jiпринято называть нагрузкой на j -й фактор со стороны i -й переменной, а последнее слагаемое в {3-33} рассматривать как помеху, случайное отклонение для Xi. Число факторов m вполне может быть меньше числа реальных переменных n и ситуации, когда мы хотим оценить влияние всего одного фактора (ту же вежливость продавцов), здесь вполне допустимы. Обратим внимание на само понятие “латентный”, скрытый, непосредственно не измеримый фактор. Конечно же, нет прибора и нет эталона вежливости, образованности, выносливости и т.п. Но это не мешает нам самим “измерить” их — применив соответствующую шкалу для таких признаков, разработав тесты для оценки таких свойств по этой шкале и применив эти тесты к тем же продавцам. Так в чем же тогда “ненаблюдаемость”? А в том, что в процессе эксперимента (обязательно) массового мы не можем непрерывно сравнивать все эти признаки с эталонами и нам приходится брать предварительные, усредненные, полученные совсем не в “рабочих” условиях данные. Можно отойти от экономики и обратиться к спорту. Кто будет спорить, что результат спортсмена при прыжках в высоту зависит от фактора — “сила толчковой ноги”. Да, это фактор можно измерить и в обычных физических единицах (ньютонах или бытовых килограммах), но когда?! Не во время же прыжка на соревнованиях! А ведь именно в это, рабочее время фиксируются статистические данные, накапливается материал для исходной матрицы. Несколько более сложно объяснить сущность самих процедур факторного анализа простыми, элементарными понятиями (по мнению некоторых специалистов в области факторного анализа — вообще невозможно). Поэтому постараемся разобраться в этом, используя достаточно сложный, но, к счастью, доведенный в практическом смысле до полного совершенства, аппарат векторной или матричной алгебры. До того как станет понятной необходимость в таком аппарате, рассмотрим так называемую основную теорему факторного анализа. Суть ее основана на представлении модели факторного анализа {3-33} в матричном виде X [k·1] = B [k·m] · F [m·1] + D [k·1] {3-34} и на последующем доказательстве истинности выражения R [k·k] = B [k·m] · B* [m·k], {3-35} для “идеального” случая, когда невязки D пренебрежимо малы. Здесь B*[m · k] это та же матрица B [k · m], но преобразованная особым образом (транспонированная). Трудность задачи отыскания матрицы нагрузок на факторы очевидна — еще в школьной алгебре указывается на бесчисленное множество решений системы уравнений, если число уравнений больше числа неизвестных. Грубый подсчет говорит нам, что нам понадобится найти k · m неизвестных элементов матрицы нагрузок, в то время как только около k2 / 2 известных коэффициентов корреляции. Некоторую “помощь” оказывает доказанное в теории факторного анализа соотношение между данным коэффициентом парной корреляции (например R 12) и набором соответствующих нагрузок факторов:
R 12 = B 11 · B 21 + B 12 · B 22 + … + B 1m · B 2m . {3-36} Таким образом, нет ничего удивительного в том утверждении, что факторный анализ (а, значит, и системный анализ в современных условиях) — больше искусство, чем наука. Здесь менее важно владеть “навыками” и крайне важно понимать как мощность, так и ограниченные возможности этого метода. Есть и еще одно обстоятельство, затрудняющее профессиональную подготовку в области факторного анализа — необходимость быть профессионалом в “технологическом” плане, в нашем случае это, конечно же, экономика. Но, с другой стороны, стать экономистом высокого уровня вряд ли возможно, не имея хотя бы представлений о возможностях анализировать и эффективно управлять экономическими системами на базе решений, найденных с помощью факторного анализа. Не следует обольщаться вульгарными обещаниями популяризаторов факторного анализа, не следует верить мифам о его всемогущности и универсальности. Этот метод “на вершине” только по одному показателю — своей сложности, как по сущности, так и по сложности практической реализации даже при “повальном” использовании компьютерных программ. К примеру, есть утверждения о преимуществах метода главных компонент — дескать, этот метод точнее расчета нагрузок на факторы. По этому поводу имеется одна острота известного итальянского статистика Карло Джинни, она в вольном пересказе звучит примерно так: “ Мне надо ехать в Милан, и я куплю билет на миланский поезд, хотя поезда на Неаполь ходят точнее и это подтверждено надежными статистическими данными. Почему? Да потому, что мне надо в Милан…”.
От автора Выражая благодарность каждому, кто дочитал до этого места или прослушал все лекции и посетил все семинары, автор считает своим долгом сделать ряд пояснений, раскрыть свою позицию и свои взгляды на курс “Основы теории систем и системного анализа”. · Место курса ТССА в ряду учебных дисциплин специальности “Учет и аудит” обусловлено прежде всего общим учебным планом, в первую очередь — разумной дисцпозицией всех дисциплин, с учетом их содержания и отводимого числа часов. Анализ (разумеется — системный!) общего рабочего плана специальности показывает, что курс ТССА должен излагаться после курса “Высшая математика” или, по крайней мере, в том семестре, в котором излагаются вопросы матричной алгебры. Кроме того, слушатели должны иметь представления о сути методов математической статистики, элементарных положениях теории вероятностей и иметь хотя бы начальные навыки обработки статистических данных. Отсюда второй вывод — данному курсу должно предшествовать изучение хотя бы введения в математическую статистику (в объеме не менее 2 час. лекций и 1 часа семинаров в неделю). · Курс ТССА является теоретической и, главное, методолгической основой большинства специальных, экономических дисциплин (если, конечно, они излагаются на уровне современных информационных технологий). Поэтому данный курс должен читаться до таких дисциплин как “Экономическая статистика”, “Экономическо-математические методы и модели”, “Эконометрия”, “Экономический риск” и т.д. · Несомненна целесообразность связей курса ТССА с такими дисциплинами как “Компъютерная техника и программирование”, а также “Информационные системы учета”. Первая из них может считаться необходимой базой для знакомства слушателей с практикой решения задач системного анализа на ЭВМ, вторая — может служить естественным продолжением ТССА в такой специфической области как информатика. · И, наконец, — о данном материале. Решение о необходимости его создания было принято кафедрой не только в связи с известными, временными трудностями только что созданного ВУЗа в вопросах обеспечения учебными и методическими пособиями. Сыграли роль и предвидимые кафедрой трудности восприятия курса слушателями, не имеющими “платформы знаний” в области статистики и необходимых вопросов математики. Всё это и обусловило столь нестандартный, причудливый подход к изложению данного курса (1 час лекций в неделю и 1 час семинаров): основные узловые точки, фундаментальные понятия излагались на лекциях и, затем, движение по таким же вопросам продолжалось на семинарах, с акцентом на практических примерах. · В заключение несколько слов о роли “практических” занятий по данному курсу. По мнению автора эти занятия могут быть полезны только в чистом виде “семинара” (группового занятия с коллективным обсуждением проблем системного анализа), но при этом не занимать половину аудиторного времени.
Профессор кафедры информационных систем и высшей математики ИДА Г.И.Корнилов
12.12.96
Литература
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-07-14; просмотров: 233; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.139.58.206 (0.014 с.) |

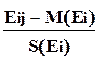 , {3-27}
, {3-27}


