Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Анализ работ по созданию и редактированию распределенных БДСодержание книги
Поиск на нашем сайте
Проектирование распределенных БД: 1. Утвердить перечень общих слоёв в распределённой сети и перечень баз данных, которые будут в ней участвовать. 2. Определить в какой из баз данных будет создан, тот или иной общий слой. 3. Необходимо уточнить в каких базах данных (БД) будут участвовать общие слои. 4. В каких БД будут изменяться общие слои, например. 5. БД, которые будут работать с системными объектами. 6. БД, которые будут работать с пространственными объектами. 7. БД, которые будут вносить изменения в семантические данные. Создание распределенных БД: 1. Создание общих слоёв согласно структуре распределённой БД. 2. Перенос общих слоёв из исходных БД в принимающие БД, которые используют эти общие слои согласно структуре распределённой БД. Экспорт данных из исходной БД. 1-ый вариант. При каждой БД создаётся обменный файл (IDF файл) со всеми общими слоями созданными в этой БД. 2-ый вариант. Создаётся единый список обменных файлов, где каждый обменный файл содержит отдельный общий слой. Импорт данных в принимающую БД. В каждую принимающую БД из полученных обменных файлов импортируются общие слои согласно структуре распределённой БД. Редактирование распределенных БД: Субъекты распределенной системы вносят изменения в общие слои согласно структуре распределённой базы данных. При синхронизации общих слоёв, из БД, в которой производились изменения общего слоя, делается экспорт этого слоя вместе с пространственными объектами в обменный файл. Полученный обменный файл импортируется во все БД, которые используют этот слой.
Организация распределенной БД Несмотря на то, что распределенная база данных состоит из нескольких локальных баз данных, у пользователя должна сохраняться иллюзия работы с централизованной базой данных, что вызывает потребность в использовании некоторого общего представления о данных - глобальной концептуальной схемы. Определение данных в такой концептуальной схеме должно быть аналогичным определению в централизованной базе данных. Отличия начинаются, когда требуется хранить данные в нескольких узлах. Чтобы произвести разбиение данных, нужно секционировать таблицы глобальной схемы на фрагменты. Существует два типа секционирования: горизонтальное и вертикальное. При секционировании таблицы по строкам выполняется горизонтальное секционирование, при разбиении по столбцам - вертикальное.
Таким образом, архитектура распределенной СУБД должна содержать информацию о секционировании исходных таблиц базы данных, что предполагает создание дополнительного уровня - фрагментного. Самый высший уровень архитектуры распределенной СУБД - это интерфейс прикладной программы и интерфейс процессора запросов. Взгляд на базу данных отдельных пользователей представлен в архитектуре отдельным 1-м уровнем, что аналогично внешнему уровню в классической архитектуре СУБД. Для реализации и объяснения распределенной природы базы данных выделяются два уровня: фрагментный (см. выше) и уровень распределенного представления. Последний показывает географическое распределение данных по рабочим станциям, расположение экземпляра каждого фрагмента. 1-4 уровни архитектуры распределенной СУБД относятся к сетевой СУБД. Однако выделяют еще локальные СУБД, где определяют представление данных на каждой рабочей станции. Каждый уровень поддерживает различные представления базы данных; каждый уровень взаимодействует только со смежными уровнями представления. Для управления распределенной базой данных создается программный комплекс - система управления распределенной базой данных (СУРБД). Изучение структуры файлов распределенной БД Концепция дифференциального файла для различных приложений и различных вариантов появлялась много раз. Применительно к распределенным системам баз данных описаны три способа дифференциального файла. Дифференциальная структура для ленточных систем разработана для того, чтобы исключить запись неизменяемых данных при последовательной пакетной обработке обновлений. Файл данных разбивается на одинаково упорядоченные подфайлы: большая совокупность записей, для которых разрешено только чтение, хранится на одной ленте, в то время как небольшая совокупность модифицируемых записей содержится на отдельной «ленте изменений». Для обновления файла данных обе ленты сливаются, при этом получается новая измененная лента. Неизменяемые записи с ленты, доступной только для чтения, никогда не записываются. Поэтому рекомендуется проводить реорганизацию файла данных после модификации половины всех записей.
В файловой системе с прямым доступом необходимо использовать принцип дифференциального файла для обработки изменений. Система обращается к записям через уникальный идентификатор, и любая ссылка на данные проходит через индекс базы данных, которая адресует все записи. Созданный однажды, главный файл данных никогда не модифицируется. Новые записи базы данных обращаются к индексу, но запоминаются в отдельной области переполнения. Все модификации записей данных трактуются как записи добавления. При этом создается новая копия записи и обновляется индекс для указания на область переполнения. Старая запись не уничтожается, а, наоборот, поддерживается как предшествующий образ, на который указывает новая запись, и свидетельствует о том, что новая запись в результате обновления увеличивается в размерах без нарушения размещения соседних записей. Система с подобной структурой была разработана с целью обеспечения восстановления базы данных при внезапном отключении электрического питания, И в этом случае все обращения осуществляются через системный индекс и все модификации выделяются в файл изменений, называемый MODFILE. Каждая измененная запись указывает на свой предыдущий образ. При отключении электрического питании информация из журнала транзакций совместно с информацией из файла MODFILE используется для удаления незавершенных обновлений. Всякий раз, когда запись обновляется одним из описанных в способов, механизм поиска записи (связанный ранее лишь с главным файлом) модифицируется таким образом, чтобы указывать на новую копию записи, которая запоминается в дифференциальном файле. Доступ к текущему значению идентифицированной записи независимо от того, находится ли она в главном или дифференциальном файле, осуществляется при помощи общего механизма поиска - системного индекса. При наличии у каждой записи базы данных своего идентификатора поиск вначале всегда проводится в дифференциальном файле. Если запись там не найдена, выборка осуществляется из главного файла. Подразумевается, что каждый файл может иметь свой собственный механизм поиска. При этом индекс главного файла является неизменяемым и может быть быстро восстановлен в случае сбоя по копии. Изменяемая часть индекса перенесена в меньший и более легко восстанавливаемый индекс дифференциального файла.
Заключение По итогам прохождения учебной практики, полученные знания были изучены и закреплены путем практических выполнений поставленных задач. В процессе прохождения практики были поставлены следующие задачи:
1. Проектирование базы данных «Спортивный магазин», построение: диаграммы сущность-связь и ER диаграмм, проектирование СУБД; 2. Работа с ЛВС: 1. проектирование ЛВС для размещения распределенной базы данных; 2. монтажные работы с ЛВС; 3. обжим кабеля витой пары и тестирование их работоспособности при помощи соответствующих оборудований; 4. настройка и оптимизация ЛВС; 5. проверка параметров сетевых карт сети; 6. проверка отсутствия конфликтов адресов ЛВС; 7. проверка допустимости ПК к настроенной сети;
3. Создание и настройка сервера на Windows Server для распределенной БД:
установка серверных систем для работы распределенных БД; установка доменных служб Active Directory; подключение пользовательских ПК к домену Active Directory; изучение распределенной БД; Изучение структуры файлов распределенной БД Поставленные задачи учебной практики все были выполнены, а выполнение практической части практики представлены в данном отчете по практике.
Список литературы http://referatz.ru/works/210732/ http://works.doklad.ru/view/tVLrVJBGzVg/all.html http://venec.ulstu.ru/lib/disk/2007/81.pdf http://demo.rosdiplom.ru/readyi2a1a2new.asp?id=107912 http://bibliofond.ru/view.aspx?id=67201 сущность-связь описание способов тестирования анализ действий по оптимизации ЛВС проверка сетевой карты распределенные БД (создание/редактирование)
Приложение 1. Руководство пользователя БД 1. Запуск Microsoft Access осуществляется с помощью файла «Спортивный Магазин.mdb».
2. Откроется окно интерфейса Microsoft Access с главной формой, где будет название базы данных, название магазина и две кнопки: «Поиск товара по коду» и «Открыть форму товаров» (рис. 31).
Рисунок 31. Интерфейс Microsoft Access c главной формой базой данных
3. При нажатии на кнопку «Поиск товара по коду» появиться окно, в котором нужно вести нужный код (рис. 32). Коды товаров: Код 1-Горные велосипеды; Код 2-Подростковые велосипеды; Код 3-Женские велосипеды; Код 4-Беговые дорожки; Код 5-Велотренажеры; Код 6-Гимнастические обручи; Код 7-Мячи; Код 8-Сноуборды.
Рисунок 32. Окно ввода кода товара
4. Введя нужный код, откроется таблица, где будет показано: регистрационный номер, название, цена реализации и наличие на складе. Для примера был введен код 1(рис. 33).
Рисунок 33. Список товара, присвоенный коду 1
5. Для закрытия таблицы нужно нажать правой кнопкой мыши на вкладку «Поиск по коду» и в открывшимся меню нажать на пункт закрыть (рис. 34).
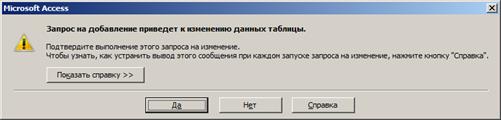
Рисунок 34. Закрытие таблицы и формы 6. Нажав на кнопку «Открыть форму товаров» на главной форме (рис. 31) появится сообщение об изменении данных таблицы, такое сообщение появляется при открытии БД и нажатии на кнопку «Закрыть форму», во всех случаях следует нажать «Да» (рис. 35).
Рисунок 35. Зарос БД на изменение данных таблицы
7. После этой процедуры открывается форма для выбора и добавление товара в корзину, а также просмотра содержимого корзины и печати чека.
Рисунок 36. Форма для добавления товаров в корзину.
8. Для поиска товара нужно ввести его название в поле и нажать на кнопку «Поиск», после чего выведется нужный товар, а для пролистывания нужно нажимать на кнопки «◄» «►» (рис. 36).
Рисунок 37. Поиск товара
9. После того как нашли нужный товар нужно добавить его в корзину для этого нажимаем на кнопку «Добавить в корзину». Так же можно выбрать количество товара, введя в строку «Введите количество товара», также при выборе товара указывается его цена с учетом количества. После того как выбрали нужные товары нужно добавить их в корзину для этого нужно нажать на кнопку «Добавить в корзину» и выбранные товары отправятся в корзину (рис. 40). После нажатия на кнопку «Добавить в корзину» появятся два диалоговых окна (рис. 38 и рис. 39).
Рисунок 38. Предупреждение об изменении данных таблицы при выполнении запроса
Рисунок 39. Предупреждение о количестве добавленных записей
Рисунок 40. Добавление товара в корзину 10. Теперь для просмотра всех добавленных товаров в корзине необходимо нажать на кнопку «Открыть корзину» (рис. 39).
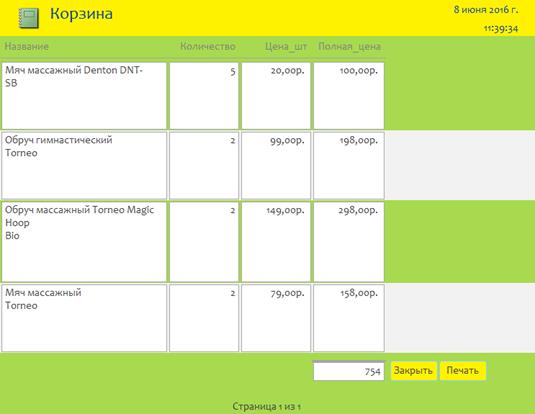
Рисунок 41. Кнопка для открытия корзины После нажатия на кнопку откроется окно со списком товаров и две кнопки «Закрыть» и «Печать». В списке указано: название, количество, цена за штуку и полная цена с учетом количества товара. Под списком показывается итоговая цена за все товары.
Рисунок 42. Корзина со списком выбранных товаров. Приложение 2. Руководство программиста БД
11. При нажатии на кнопку печать появиться окно «Печать».
|
||||||||
|
|
Последнее изменение этой страницы: 2016-07-15; просмотров: 401; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.145.143.57 (0.011 с.) |