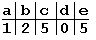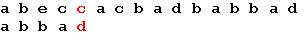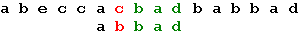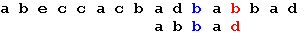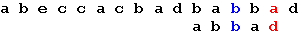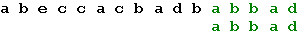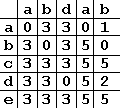Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Поиск подстроки в строке. Постановка задачи, решение методом «грубой силы». Возможность оптимизации. Алгоритм Боэра-Мура.Содержание книги
Поиск на нашем сайте Задача поиска подстроки в строке заключается в нахождении в оригинальной строке, точного вхождения (соответствие всех символов) подстроки. В результате программа должна выдать номера символов всех вхождений подстроки… Метод Грубой силы. Этот алгоритм заключается в проверке всех позиций текста с 0 по n – m (n-длина строки, m-длина подстроки) на предмет совпадения с началом образца. Если совпадает - смотрим следующую букву и т.д. Алгоритм грубой силы не нуждается в предварительной обработке и дополнительном пространстве. Оптимизацией метода грубой силы является алгоритм Боэра-Мура… Алгоритм Боэра-Мура Алгоритм Боэра-Мура, разработанный двумя учеными – Боэром (Robert S. Boyer) и Муром (J. Strother Moore), считается наиболее быстрым среди алгоритмов общего назначения, предназначенных для поиска подстроки в строке. Прежде чем рассмотреть работу этого алгоритма, уточним некоторые термины. Под строкой мы будем понимать всю последовательность символов текста. Собственно говоря, речь не обязательно должна идти именно о тексте. В общем случае строка – это любая последовательность байтов. Поиск подстроки в строке осуществляется по заданному образцу, т. е. некоторой последовательности байтов, длина которой не превышает длину строки. Наша задача заключается в том, чтобы определить, содержит ли строка заданный образец. Простейший вариант алгоритма Боэра-Мура состоит из следующих шагов. На первом шаге мы строим таблицу смещений для искомого образца. Процесс построения таблицы будет описан ниже. Далее мы совмещаем начало строки и образца и начинаем проверку с последнего символа образца. Если последний символ образца и соответствующий ему при наложении символ строки не совпадают, образец сдвигается относительно строки на величину, полученную из таблицы смещений, и снова проводится сравнение, начиная с последнего символа образца. Если же символы совпадают, производится сравнение предпоследнего символа образца и т. д. Если все символы образца совпали с наложенными символами строки, значит мы нашли подстроку и поиск окончен. Если же какой-то (не последний) символ образца не совпадает с соответствующим символом строки, мы сдвигаем образец на один символ вправо и снова начинаем проверку с последнего символа. Весь алгоритм выполняется до тех пор, пока либо не будет найдено вхождение искомого образца, либо не будет достигнут конец строки. Величина сдвига в случае несовпадения последнего символа вычисляется исходя из следующих соображений: сдвиг образца должен быть минимальным, таким, чтобы не пропустить вхождение образца в строке. Если данный символ строки встречается в образце, мы смещаем образец таким образом, чтобы символ строки совпал с самым правым вхождением этого символа в образце. Если же образец вообще не содержит этого символа, мы сдвигаем образец на величину, равную его длине, так что первый символ образца накладывается на следующий за проверявшимся символ строки. Величина смещения для каждого символа образца зависит только от порядка символов в образце, поэтому смещения удобно вычислить заранее и хранить в виде одномерного массива, где каждому символу алфавита соответствует смещение относительно последнего символа образца. Поясним все вышесказанное на простом примере. Пусть у нас есть набор символов из пяти символов: a, b, c, d, e и мы хотим найти вхождение образца “abbad” в строке “abeccacbadbabbad”. Следующие схемы иллюстрируют все этапы выполнения алгоритма:
Таблица смещений для образца “abbad”.
Начало поиска. Последний символ образца не совпадает с наложенным символом строки. Сдвигаем образец вправо на 5 позиций:
Три символа образца совпали, а четвертый – нет. Сдвигаем образец вправо на одну позицию:
Последний символ снова не совпадает с символом строки. В соответствии с таблицей смещений сдвигаем образец на 2 позиции:
Еще раз сдвигаем образец на 2 позиции:
Теперь, в соответствии с таблицей, сдвигаем образец на одну позицию, и получаем искомое вхождение образца:
Хотя рассмотренный упрощенный алгоритм вполне пригоден с практической точки зрения (и часто применяется), нельзя не заметить, что результаты сравнений используются недостаточно эффективно. Действительно, на втором шаге, когда у нас совпали три символа, мы, зная, что последовательность “bad” встречается в образце только один раз, могли бы сразу сместить образец на всю его длину, а не на один символ. Теперь мы рассмотрим другой, немного более сложный вариант алгоритма Боэра-Мура, позволяющий учесть результаты предыдущих сравнений в случае частичного совпадения образца и подстроки. Прежде всего изменим принцип построения таблицы смещений. В этом варианте алгоритма таблица – двумерная, каждому символу образца соответствует один столбец таблицы, а каждой букве алфавита – одна строка. В ячейках таблицы содержатся значения смещений, на которые нужно сдвинуть образец, если при проверке данного символа образца обнаружено несовпадение и вместо искомого символа получен символ алфавита, соответствующий некоторой строке в таблице. Например, таблица последовательности “abdab” для нашего пятибуквенного алфавита будет выглядеть следующим образом:
Заполнение таблицы начинается с последнего столбца. Самый правый столбец таблицы фактически соответствует массиву, который используется в упрощенном варианте алгоритма. Следующие столбцы содержат значения сдвига для образца при условии, что предыдущие (при движении справа налево) символы совпали. Проводя поиск при помощи этой таблицы, мы последовательно просматриваем значения ячеек, лежащих на пересечении столбца, соответствующего символу образца и строки, соответствующей символу текста. Просмотр начинается с последнего столбца. Если в каждом столбце выбранная ячейка содержит 0, значит, подстрока найдена. Если значение ячейки отличается от нуля, мы сдвигаем образец на соответствующее значение. Определенные сложности могут возникнуть при работе с кодировкой Unicode. Очевидно, что таблица, число строк которой равно числу символов двухбайтовой кодировки, будет слишком громоздкой. К счастью, в такой таблице нет необходимости, ведь в случае двухбайтовой кодировки любой образец содержит лишь небольшую часть символов алфавита. Для всех символов, не содержащихся в образце, значения смещения в каждом столбце таблицы будут одинаковыми. Эта особенность позволяет разработать сокращенные варианты таблицы для Unicode. Unicode-строку можно рассматривать как последовательность байтов, где каждый Unicode-символ представлен двумя байтами. Дополнительным преимуществом данного варианта алгоритма является возможность организовать «регистронезависимый» поиск, т. е. поиск слова вне зависимости от регистра букв. Для этого достаточно в таблице смещений сопоставить одинаковые строки одним и тем же буквам разного регистра. Можно даже ввести поиск по шаблону, содержащему подстановочные символы. Превосходство алгоритма Боэра-Мура перед методом грубой силы наиболее ощутимо проявляется с увеличением длины образца. Хотя алгоритм Боэра-Мура производит меньше сравнений, чем примитивный алгоритм при длине образца более двух символов, большая сложность этого алгоритма и необходимость заранее вычислять таблицу смещений может свести на нет его преимущества, если поиск проводится в коротком тексте, и длина образца невелика. Преимущество в быстродействии более сложного варианта алгоритма Боэра-Мура перед более простым вариантом сказывается, только если длина образца велика, и в тексте часто встречаются отдельные последовательности символов, содержащиеся в образце. Главное же достоинство более сложного варианта алгоритма заключается в возможности реализации регистронезависимого поиска и поиска по шаблону. Разбор арифметических выражений. Понятие дерева выражений, понятие префиксной, инфиксной и суффиксной записи. Алгоритм Дэйкстры перевода строки из инфиксной формы в суффиксную форму. Вычисление значения выражения, записанного в суффиксной форме. Понятие выражения Под «выражением» или «математическим выражением» подразумевается строка, в которой есть операнды и действия. Каждый операнд состоит ровно из одного символа, причем этот символ не может быть таким же, как символ одного из действий. В выражении используются четыре типа операции: +, -, *, /. Первыми выполняются операции умножения и деления. Все операции являются бинарными операторами (т.е. они работают с двумя операндами). Типы записи выражений Каждое математическое выражение можно представить в трех специфических видах записи: Префиксная запись — сначала пишется действие, затем левый операнд, затем правый операнд. Для выражения (a+b) префиксная запись будет иметь вид +ab. Выражению (a+b*(c+d)) соответствует запись +a*b+cd (складываем a с произведением b и суммы c и d) Инфиксная запись выражения — пишется левый операнд, затем пишется знак действия и правый операнд. Инфиксная запись отличается от других тем, что в не соблюден порядок действий. Ее очень легко получить из выражения, просто убрав скобки: (a+b*(c+d)) соответствует a+b*c+d Постфиксная запись выражения — пишется левый операнд, затем пишется правый операнд и знак операции. Для выражения (a+b) постфиксная запись имеет вид ab+. Выражению (a+b*(c+d)) соответствует запись abcd+*+. Её можно прочитать с конца, аналогично префиксной записи. Эти типы записи были введены польским логиком Яном Лукасевичем, поэтому их также называют системой польского обозначения. С помощью постфиксной (инфиксной) записи легко вычисляется значение выражения. Определение дерева Некоторая вершина типа T (корень) с конечным числом связанных с ней отдельных деревьев с типом узлов T, называемых поддеревьями. Из определения дерева ясно, что линейный список можно рассматривать как дерево, в котором каждая вершина имеет не более одного поддерева. Поэтому список иногда назы-вают вырожденным деревом. Будем считать, что дерево состоит из узлов, которые имеют указатели на своего предка, и правого и левого потомков. Потомки в свою очередь тоже являются узлами. Узел, не имеющий потомков, назовем листом дерева. Дерево определятся узлом, которое будем называть корневым. Корневой узел может в определенных условиях меняться. В качестве информационной части у узла будет переменная символьного типа. Под деревом выражения будет называть дерево, которое можно построить из математического выражения. Каждый узел (не лист) такого дерева содержит знак действия, а каждый лист один из индетификаторов выражения. Дерево строится так, чтобы по нему можно было восстановить порядок действий. Например, пусть задано простое арифметическое выражение вида: (A+B)*(C+D)-E Представим это выражение в виде дерева, в котором узлам соответствуют операции, а ветвям - операнды. Построение начнем с корня, в качестве которого выбирается операция, выполняющаяся последней. Левой ветви соответствует левый операнд операции, а правой ветви - правый. Дерево выражения показано ниже: - / \ / \ * E / \ / \ / \ / \ + + / \ / \ / \ / \ A B C DСовершим обход дерева, под которым будем понимать формирование строки символов из символов узлов и ветвей дерева. Обход будем совершать от самой левой ветви вправо и узел переписывать в выходную строку только после рассмотрения всех его ветвей. Результат обхода дерева имеет вид: AB+CD+*E- (1) Это постфиксная/суффиксная запись выражения или обратная польская запись. Обратная польская запись обладает рядом замечательных свойств, которые превращают ее в идеальный промежуточный язык при трансляции. Во-первых, вычисление выражения, записанного в обратной польской записи, может проводиться путем однократного просмотра, что является весьма удобным при генерации объектного кода программ. например, вычисление выражения (1) может быть проведено следующим образом: |-----|----------------------|-----------------------|| # | Анализируемая | Действие || п/п | строка | ||-----|----------------------|-----------------------|| 0 | A B + C D + * E - | r1=A+B || 1 | r1 C D + * E - | r2=C+D || 2 | r1 r2 * E - | r1=r1*r2 || 3 | r1 E - | r1=r1-E || 4 | r1 | Вычисление окончено ||-----|----------------------|-----------------------|Здесь r1, r2 - вспомогательные переменные. Для того чтобы, имея дерево выражения, записать его в префиксной форме нужно читать его по следующему правилу: узел, левый операнд, правый.Для инфиксной записи: левый операнд, узел, правый. Получение обратной польской записи из исходного выражения может осуществляться так же весьма просто на основе простого алгоритма, предложенного Дейкстpой. Для этого вводится понятие стекового приоритета операций: |----------|-----------|| Операция | Приоритет ||----------|-----------|| (| 0 ||) | 1 || +|- | 2 || *|/ | 3 || ** | 4 ||----------|-----------|Просматривается исходная строка символов слева направо, операнды переписываются в выходную строку, а знаки операций заносятся в стек на основе следующих соображений: а) если стек пуст, то операция из входной строки переписывается в стек;??? б) операция выталкивает из стека все операции с большим или равным приоритетом в выходную строку; в) если очередной символ из исходной строки есть открывающая скобка, то он проталкивается в стек; г) закрывающая круглая скобка выталкивает все операции из стека до ближайшей открывающей скобки, сами скобки в выходную строку не переписываются, а уничтожают друг друга. Процесс получения обратной польской записи выражения схематично представлен в следующей таблице:
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-07-11; просмотров: 691; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.214 (0.011 с.) |