Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Построение обратной польской записиСодержание книги
Поиск на нашем сайте
Сложные вычислительные задачи обычно требуют больших объемов вычислений, поэтому к разработчикам языков программирования было предъявлено требование: максимально приблизить форму записи математических выражений в коде программы к естественному языку математики. Одну из первых областей системного программирования составили исследования способов трансляции математических выражений. В результате наибольшее распространение получил метод трансляции при помощи обратной польской записи, которую предложил польский математик Я. Лукашевич. Рассмотрим алгоритмы получения обратной польской записи с использованием структур в виде дерева и стека.
Алгоритм, использующий дерево Данный алгоритм основан на представлении математического выражения в виде дерева и использовании третьего способа его обхода (см. п. 15.5.6). Напомним его на примере арифметического выражения (A+B)*(C+D)–E. Представим это выражение в виде дерева, в котором узлам соответствуют операции, а листьям – операнды. Построение начинается с корня, в качестве которого выбирается последняя выполняемая операция. Левой ветви соответствует левый операнд операции, а правой ветви – правый. Дерево выражения имеет вид:
Совершим обход дерева, под которым понимается формирование строки из символов узлов и ветвей дерева. Обход будем совершать от самой левой ветви вправо и узел переписывать в выходную строку только после рассмотрения всех его ветвей. Обход совершаем строго по уровням: 1) уровень 2: АВ+CD+ 2) поднялись на уровень 1: *Е 3) и, наконец, корень: – В результате такого обхода получили обратную польскую запись: AB+CD+*E– (15.1) Алгоритм, использующий стек Получение обратной польской записи с использованием стека может осуществляться весьма просто на основе алгоритма, предложенного Дейкстрой, который ввел понятие стекового приоритета операций:
Суть алгоритма в следующем. Просматривается исходная строка символов S слева направо, операнды переписываются в выходную строку В, а знаки операций заносятся в стек, который первоначально пуст, на основе следующих правил: 1) если в строке S встретился операнд, то помещаем его в строку В; 2) если в S встретилась открывающая скобка, то помещаем ее в стек; 3) если в S встретилась закрывающая скобка, то выталкиваем из стека в строку В все операции до открывающей скобки, саму отрывающую скобку также извлекаем из стека; обе скобки (открывающая и закрывающая) игнорируются; 4) если в S встретилась операция Х, то выталкиваем из стека все операции, приоритет которых не ниже Х, после чего операцию Х записываем в стек; 5) при достижении конца строки S, если стек не пуст, переписываем его элементы в выходную строку В. Обратная польская запись обладает рядом замечательных свойств, которые превращают ее в идеальный промежуточный язык при трансляции. Во-первых, вычисление выражения, записанного в обратной польской записи, может проводиться путем однократного просмотра, что является весьма удобным при генерации объектного кода программ. Например, вычисление полученного выражения (15.1) может быть проведено следующим образом:
Здесь R 1 и R 2 – вспомогательные переменные. Пример реализации Пусть задано выражение a + b * c +(d * e + f)* g. Необходимо записать это выражение в постфиксной форме. Правильным ответом будет выражение abc *+ de * f + g *+. Решаем эту задачу, используя стек. Пусть исходная информация хранится в строке S =” a + b * c +(d * e + f)* g ”. Результат будем получать в строке В. Начинаем последовательно просматривать символы исходной строки, причем стек пуст и В – пустая строка. Букву «a» помещается в строку В, а операцию «+» помещаем в стек. Букву «b» помещаем в строку В. На этот момент стек и строка В выглядят следующим образом:
Операцию «*» помещаем в стек, т.к. элемент в вершине стека имеет более низкий приоритет. Букву «с» помещаем в строку В, после чего имеем
Следующий символ строки S «+». Анализируем стек и видим, что элемент в вершине стека «*» и следующий за ним «+» имеют приоритеты не ниже текущего, следовательно, обе операции извлекаем из стека и помещаем в строку В, а текущий элемент помещаем в стек. В итоге имеем
Далее в строке S следует символ «(», его помещаем в стек, а букву «d» помещаем в строку В, в результате получается
Следующий в строке S символ «*». Так как открывающую скобку нельзя извлечь из стека до тех пор, пока не встретилась закрывающая, то «*» помещаем в стек. Букву «e» помещаем в строку В:
Следующий прочитанный символ «+», и т.к. элемент стека «*» имеет более высокий приоритет, то извлекаем его из стека и помещаем в строку В, а текущий символ «+» помещаем в стек. Символ «f» помещаем в строку В:
Далее в строке S идет закрывающая скобка, все элементы стека до символа «)» помещаем в строку В (это элемент «+»), а сам символ «(» извлекаем из стека. Обе скобки игнорируются:
Операцию «*» помещаем в стек, а букву «g» – в строку В:
Все символы строки S рассмотрены, следовательно, анализируем состояние стека, если он не пуст, то переписываем все его элементы в строку В:
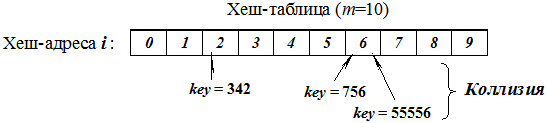
Таким образом, просмотрев исходную информацию только один раз, мы решили поставленную задачу. Текст программы, реализующий рассмотренный алгоритм, может иметь следующий вид: ... struct Stack { char c; // Символ операции Stack *Next; }; int Prior (char); Stack* InS(Stack*,char); Stack* OutS(Stack*,char*); void main () { Stack *t, *Op = NULL; // Стек операций Op – пуст char a, In[50], Out[50]; // Входная In и выходная Out строки int k = 0, l = 0; // Текущие индексы для строк puts(" Input formula: "); gets(In); while (In[k]!= '\0') { // Анализируем символы строки In // Если символ «)», выталкиваем из стека в выходную строку все операции if (In[k] == ')') { while ((Op -> c)!= '(') { // до открывающей скобки Op = OutS(Op,&a); // Считываем элемент из стека if (!Op) a = '\0'; Out[l++] = a; // и записываем в строку Out. } t = Op; // Удаляем из стека открывающую скобку Op = Op -> Next; free(t); } // Если символ строки In – буква, заносим ее в строку Out if (In[k] >= 'a' && In[k] <= 'z') Out[l++] = In[k]; // Если символ – открывающая скобка, записываем ее в стек if (In[k] == '(') Op = InS(Op,In[k]); /* Если символ – знак операции, переписываем из стека в строку Out все операции с большим или равным приоритетом */ if (In[k] == '+' || In[k] == '–' || In[k] == '*' || In[k] == '/') { while (Op!= NULL && Prior (Op -> c) >= Prior (In[k])) { Op = OutS(Op,&a); // Извлекаем из стека символ Out[l++] = a; // и записываем в строку Out } Op = InS(Op,In[k]); // Текущий символ – в стек } k++; } // Конец цикла анализа входной строки // Если стек не пуст, переписываем все операции в выходную строку while (Op!=NULL) { Op = OutS(Op,&a); Out[l++] = a; } Out[l] = '\0’; printf("\n Polish = %s", Out); // Выводим на экран результат } //======= Функция реализации приоритета операций ========= int Prior (char a) { switch (a) { case '*': case '/': return 3; case '–': case '+': return 2; case '(': return 1; } return 0; } // ============== Добавление элемента в стек ============= Stack* InS(Stack *t, char s) { Stack *t1 = (Stack*) malloc(sizeof(Stack)); t1 -> c = s; t1-> Next = t; return t1; } // ============== Извлечение элемента из стека =============== Stack* OutS(Stack *t, char *s) { Stack *t1 = t; *s = t -> c; t = t->Next; free(t1); return t; } Понятие хеширования Для решения задачи поиска необходимого элемента среди данных большого объема был предложен алгоритм хеширования (hashing – перемешивание), при котором создаются ключи, определяющие данные массива и на их основании данные записываются в таблицу, названную хеш-таблицей. Ключи для записи определяются при помощи функции i = h (key), называемой хеш-функцией. Алгоритм хеширования определяет положение искомого элемента в хеш-таблице по значению его ключа, полученного хеш-функцией. Понятие хеширования– это разбиение общего (базового) набора уникальных ключей элементов данных на непересекающиеся наборы с определенным свойством. Возьмем, например, словарь или энциклопедию. В этом случае буквы алфавита могут быть приняты за ключи поиска, т.е. основным элементом алгоритма хеширования является ключ (key). В большинстве приложений ключ обеспечивает косвенную ссылку на данные. Фактически хеширование – это специальный метод адресации данных для быстрого поиска нужной информации по ключам. Если базовый набор содержит N элементов, то его можно разбить на 2 N различных подмножеств. 15.7.1. Хеш-таблица и хеш-функции Функция, отображающая ключи элементов данных во множество целых чисел (индексы в таблице – хеш-таблица), называется функцией хеширования, или хеш-функцией: i = h (key); где key – преобразуемый ключ, i – получаемый индекс таблицы, т.е. ключ отображается во множество целых чисел (хеш-адреса), которые впоследствии используются для доступа к данным. Однако хеш-функция для нескольких значений ключа может давать одинаковое значение позиции i в таблице. Ситуация, при которой два или более ключа получают один и тот же индекс (хеш-адрес), называется коллизией при хешировании. Хорошей хеш-функцией считается такая функция, которая минимизирует коллизии и распределяет данные равномерно по всей таблице, а совершенной хеш-функцией – функция, которая не порождает коллизий:
Разрешить коллизии при хешировании можно двумя методами: – методом открытой адресации с линейным опробыванием; – методом цепочек. Хеш-таблица Хеш-таблица представляет собой обычный массив с необычной адресацией, задаваемой хеш-функцией. Хеш-структуру считают обобщением массива, который обеспечивает быстрый прямой доступ к данным по индексу. Имеется множество схем хеширования, различающихся как выбором удачной функции h (key), так и алгоритма разрешения конфликтов. Эффективность решения реальной практической задачи будет существенно зависеть от выбираемой стратегии.
Примеры хеш-функций Выбираемая хеш-функция должна легко вычисляться и создавать как можно меньше коллизий, т.е. должна равномерно распределять ключи на имеющиеся индексы в таблице. Конечно, нельзя определить, будет ли некоторая конкретная хеш-функция распределять ключи правильно, если эти ключи заранее не известны. Однако, хотя до выбора хеш-функции редко известны сами ключи, некоторые свойства этих ключей, которые влияют на их распределение, обычно известны. Рассмотрим наиболее распространенные методы задания хеш-функции. Метод деления. Исходными данными являются – некоторый целый ключ key и размер таблицы m. Результатом данной функции является остаток от деления этого ключа на размер таблицы. Общий вид функции: int h(int key, int m) { return key % m; // Значения } Для m = 10 хеш-функция возвращает младшую цифру ключа.
Для m = 100 хеш-функция возвращает две младшие цифры ключа.
Аддитивный метод, в котором ключом является символьная строка. В хеш-функции строка преобразуется в целое суммированием всех символов и возвращается остаток от деления на m (обычно размер таблицы m = 256). int h(char *key, int m) { int s = 0; while(*key) s += *key++; return s % m; } Коллизии возникают в строках, состоящих из одинакового набора символов, например, abc и cab. Данный метод можно несколько модифицировать, получая результат, суммируя только первый и последний символы строки-ключа. int h(char *key, int m) { int len = strlen(key), s = 0; if(len < 2) // Если длина ключа равна 0 или 1, s = key[0]; // возвратить key[0] else s = key[0] + key[len–1]; return s % m; } В этом случае коллизии будут возникать только в строках, например, abc и amc. Метод середины квадрата, в котором ключ возводится в квадрат (умножается сам на себя) и в качестве индекса используются несколько средних цифр полученного значения. Например, ключом является целое 32-битное число, а хеш-функция возвращает средние 10 бит его квадрата: int h(int key) { key *= key; key >>= 11; // Отбрасываем 11 младших бит return key % 1024; // Возвращаем 10 младших бит }
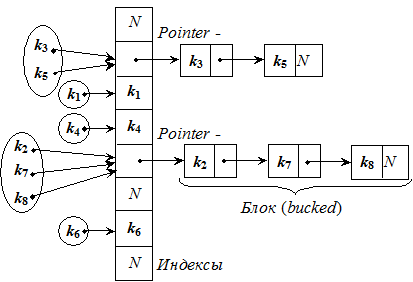
Метод исключающего ИЛИ для ключей-строк (обычно размер таблицы m =256). Этот метод аналогичен аддитивному, но в нем различаются схожие слова. Метод заключается в том, что к элементам строки последовательно применяется операция «исключающее ИЛИ». В мультипликативном методе дополнительно используется случайное действительное число r из интервала [0,1), тогда дробная часть произведения r * key будет находиться в интервале [0,1]. Если это произведение умножить на размер таблицы m, то целая часть полученного произведения даст значение в диапазоне от 0 до m –1. int h(int key, int m) { double r = key * rnd(); r = r – (int)r; // Выделили дробную часть return r * m; } В общем случае при больших значениях m индексы, формируемые хеш-функцией, имеют большой разброс. Более того, математическая теория утверждает, что распределение получается более равномерным, если m является простым числом. В рассмотренных примерах хеш-функция i = h (key) только определяет позицию, начиная с которой нужно искать (или первоначально – поместить в таблицу) запись с ключом key. Поэтому схема хеширования должна включать алгоритм решения конфликтов, определяющий порядок действий, если позиция i = h (key) оказывается уже занятой записью с другим ключом. Схемы хеширования В большинстве задач два и более ключей хешируются одинаково, но они не могут занимать в хеш-таблице одну и ту же ячейку. Существуют два возможных варианта: либо найти для нового ключа другую позицию, либо создать для каждого индекса хеш-таблицы отдельный список, в который помещаются все ключи, преобразованные в этот индекс. Эти варианты и представляют собой две классические схемы: – хеширование методом цепочек (со списками), или так называемое многомерное хеширование – chaining with separate lists; – хеширование методом открытой адресации с линейным опробыванием – linear probe open addressing. Метод открытой адресации с линейным опробыванием. Изначально все ячейки хеш-таблицы, которая является обычным одномерным массивом, помечены как не занятые. Поэтому при добавлении нового ключа проверяется, занята ли данная ячейка. Если ячейка занята, то алгоритм осуществляет осмотр по кругу до тех пор, пока не найдется свободное место («открытый адрес»), т.е. либо элементы с однородными ключами размещают вблизи полученного индекса, либо осуществляют двойное хеширование, используя для этого разные, но взаимосвязанные хеш-функции. В дальнейшем, осуществляя поиск, сначала находят по ключу позицию i в таблице, и, если ключ не совпадает, то последующий поиск осуществляется в соответствии с алгоритмом разрешения конфликтов, начиная с позиции i по списку. Метод цепочек используется чаще предыдущего.В этом случае полученный хеш-функцией индекс i трактуется как индекс в хеш-таблице списков, т.е. ключ key очередной записи отображается на позицию i = h (key) таблицы. Если позиция свободна, то в нее помещается элемент с ключом key, если же она занята, то отрабатывается алгоритм разрешения конфликтов, в результате которого такие ключи добавляются в список, начинающийся в i -й ячейке хеш-таблицы. Например, обозачив N – NULL:
В итоге имеем таблицу массива связных списков или деревьев. Процесс заполнения (считывания) хеш-таблицы прост, но доступ к элементам требует выполнения следующих операций: – вычисление индекса i; – поиск в соответствующей цепочке. Для улучшения поиска при добавлении нового элемента можно использовать алгоритма вставки не в конец списка, а – с упорядочиванием, т.е. добавлять элемент в нужное место. При решении задач на практике необходимо подобрать хеш-функцию i = h (key), которая по возможности равномерно отображает значения ключа key на интервал [0, m –1], m – размер хеш-таблицы. И чаще всего, если нет информации о вероятности распределения ключей по записям, используя метод деления, берут хеш-функцию i = h (key) = key % m. При решении обратной задачи – доступ (поиск) к определенному подмножеству возможен из хеш-таблицы (хеш-структуры), которая обеспечивает по хеш-адресу (индексу) быстрый доступ к нужному элементу.
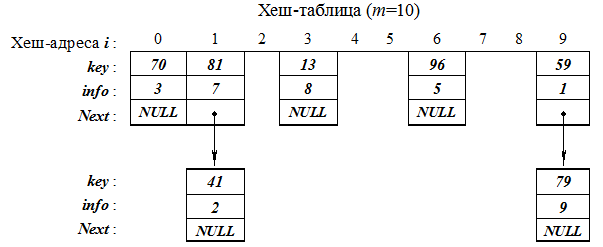
Примеры реализации схем хеширования Пример реализации метода прямой адресации с линейным опробыванием. Исходными данными являются 7 записей (для простоты информационная часть состоит из целых чисел) объявленного структурного типа: struct zap { int key; // Ключ int info; // Информация } data; {59,1}, {70,3}, {96,5}, {81,7}, {13,8}, {41,2}, {79,9}; размер хеш-таблицы m = 10. Выберем хеш-функцию i = h (data) = data. key %10; т.е. остаток от деления на 10 – i Î[0,9]. На основании исходных данных последовательно заполняем хеш-таблицу.
Хеширование первых пяти ключей дает различные индексы (хеш-адреса): i = 59 % 10 = 9; i = 70 % 10 = 0; i = 96 % 10 = 6; i = 81 % 10 = 1; i = 13 % 10 = 3. Первая коллизия возникает между ключами 81 и 41 – место с индексом 1 занято. Поэтому просматриваем хеш-таблицу с целью поиска ближайшего свободного места, в данном случае – это i = 2. Следующий ключ 79 также порождает коллизию: позиция 9 уже занята. Эффективность алгоритма резко падает, т.к. для поиска свободного места понадобилось 6 проб (сравнений), свободным оказался индекс i = 4. Общее число проб – 1–9 проб на элемент.
Реализация метода цепочек для предыдущего примера. Объявляем структурный тип для элемента однонаправленного списка: struct zap { int key; // Ключ int info; // Информация zap *Next; // Указатель на следующий элемент в списке } data; На основании исходных данных последовательно заполняем хеш-таблицу, добавляя новый элемент в конец списка, если место уже занято.
Хеширование первых пяти ключей, как и в предыдущем случае, дает различные индексы (хеш-адреса): 9, 0, 6, 1, и 3. При возникновении коллизии новый элемент добавляется в конец списка. Поэтому элемент с ключом 41 помещается после элемента с ключом 81, а элемент с ключом 79 – после элемента с ключом 59.
ЗАДАНИЕ 8. Обработка списков Вариант 1. Однонаправленные списки Написать программу по созданию, просмотру, добавлению и решению поставленной задачи для однонаправленного линейного списка (стек и/или очередь).
1. Создать список из случайных целых чисел, лежащих в диапазоне от 2. Создать список из случайных целых чисел и удалить из него записи с четными числами. 3. Создать список из случайных положительных и отрицательных целых чисел (от –10 до 10) и удалить из него отрицательные элементы. 4. Создать список из случайных целых чисел и поменять местами крайние элементы. 5. Создать список из случайных целых чисел и удалить элементы, заканчивающиеся на цифру 5. 6. Создать список из случайных целых чисел и поменять местами элементы, содержащие максимальное и минимальное значения. 7. Создать список из случайных целых чисел. Перенести в другой список все элементы, находящиеся между вершиной и элементом с максимальным значением. 8. Создать список из случайных целых чисел. Перенести в другой список все элементы, находящиеся между вершиной и элементом с минимальным значением. 9. Создать список из случайных чисел, определить количество элементов, находящихся между минимальным и максимальным элементами, и удалить их. 10. Создать список из случайных чисел и определить количество элементов, имеющих значения, меньше среднего значения от всех элементов, и удалить эти элементы. 11. Создать список из случайных чисел, вычислить среднее арифметическое и заменить им первый элемент. 12. Создать список из случайных целых чисел, разделить его на два: в первый поместить все четные, а во второй – нечетные числа. 13. Создать список из случайных целых чисел в диапазоне от 1 до 10, определить наиболее часто встречающееся число и удалить его. 14. Создать список из случайных целых чисел и удалить из него каждый второй элемент. 15. Создать список из случайных целых чисел и удалить из него каждый нечетный элемент.
Вариант 2. Двунаправленные списки Написать программу по созданию, просмотру, добавлению и решению поставленной задачи для двунаправленного линейного списка.
1. Создать список из случайных целых чисел. Найти минимальный элемент и сделать его первым. 2. Создать два списка из случайных целых чисел. В первом найти максимальный элемент и за ним вставить элементы второго. 3. Создать список из случайных целых чисел. Удалить из списка все элементы, находящиеся между максимальным и минимальным элементами. 4. Упорядочить элементы списка случайных целых чисел в порядке возрастания. 5. Создать список из случайных целых чисел. Удалить из списка все элементы, находящиеся до максимального элемента. 6. Создать список из случайных целых чисел. Удалить из списка все элементы, находящиеся после минимального элемента. 7. Создать список из случайных целых чисел. Из элементов, расположенных между максимальным и минимальным элементами, создать второй список, а из остальных – третий. 8. Создать список из случайных положительных и отрицательных целых чисел. Образовать из него два списка, первый должен содержать отрицательные числа, а второй – положительные. 9. Создать список из случайных целых чисел. Удалить из списка все элементы, находящиеся после максимального элемента. 10. Создать два списка из случайных целых чисел. Вместо элементов первого списка, заключенных между максимальным и минимальным элементами, вставить второй список. 11. Создать список из случайных целых чисел. Удалить из списка элементы с повторяющимися более одного раза значениями. 12. Создать список из случайных целых чисел и удалить все элементы, кратные 5. 13. Создать список из случайных целых чисел. Удалить из списка все элементы, большие среднего арифметического. 14. Создать список из случайных чисел. Преобразовать его в кольцо. Предусмотреть возможность движения по кольцу в обе стороны с отображением места положения текущего элемента. 15. Создать список из случайных целых чисел. Удалить из списка все элементы, находящиеся между максимальным и минимальным элементами. ЗАДАНИЕ 9. Деревья и польская запись
Вариант 1. Создание и обработка структур типа «дерево» Разработать проект для обработки дерева поиска, каждый элемент которого содержит целочисленный ключ и строку текста, содержащую, например, ФИО и номер паспорта (ввод исходной информации рекомендуется записать в файл). В программе должны быть реализованы следующие возможности: – создание дерева; – добавление новой записи; – поиск информации по заданному ключу; – удаление информации с заданным ключом; – вывод информации; – решение индивидуального задания; – освобождение памяти при выходе из программы. 1. Поменять местами информацию, содержащую максимальный и минимальный ключи. 2. Подсчитать число листьев в дереве. 3. Удалить из дерева ветвь с вершиной, имеющей заданный ключ. 4. Определить глубину дерева. 5. Определить число узлов на каждом уровне дерева. 6. Удалить из левой ветви дерева узел с максимальным значением ключа и все связанные с ним узлы. 7. Определить количество узлов с четными ключами. 8. Определить число листьев на каждом уровне дерева. 9. Определить число узлов в дереве, имеющих только одного потомка. 10. Определить количество узлов правой ветви дерева. 11. Определить количество записей в дереве, начинающихся с введенной с клавиатуры буквы. 12. Найти среднее значение всех ключей дерева и найти строку, имеющую ближайший к этому значению ключ. 13. Определить количество узлов левой ветви дерева. 14. Определить число узлов в дереве, имеющих двух потомков. 15. Найти запись с ключом, ближайшим к среднему значению между максимальным и минимальным значениями ключей.
Вариант 2. Создание и использование польской записи Написать программу формирования обратной польской записи и расчета полученного выражения. Предусмотреть возможности того, что идентификаторы могут состоять более чем из одного символа и могут быть использованы операции % и возведение в степень. Результат работы программы проверить на конкретном примере (табл. 15.1). Например, если ввести выражение (a + b)*(c – d)/ e и значения переменных а = 3, b = 5, c = 6, d = 9, е = 7, должны получиться следующие результаты: Постфиксная форма ab + cd – * e / Результат расчета – 3.42857 Таблица 15.1
ГЛАВА 16. Переход к ООП
При переходе от языка Си к языку С++ в стандарт ANSI были введены дополнительные механизмы, которые позволили в конечном итоге создать среду для разработки программ в объектно-ориентированном стиле. Рассмотрим некоторые из них.
Потоковый ввод-вывод Поток – это абстрактное понятие, которое относится к любому переносу данных от источника к приемнику. Потоки С++ обеспечивают надежную работу как со стандартными (stdin, stdout), так и с определенными пользователями типами данных. Поток определяется как последовательность байт, не зависящая от конкретного устройства. Для ввода-вывода в языке С++ используются два объекта класса iostream: cin (класс istream), cout (класс ostream) и две переопределенные операции побитового сдвига. Для их работы необходимо подключить заголовочный файл iostream.h. Формат записи операций помещения в поток << (вывод на экран) и извлечения из потока >> (ввод с клавиатуры) следующий: cout << ID переменной; cin >> ID переменной; Стандартный поток вывода cout по умолчанию связан со стандартным устройством вывода stdout (дисплей монитора), а ввода cin – со стандартным устройством ввода stdin, т.е. клавиатурой. Приведем пример: #include<iostream.h> void main (void) { int i, j, k; cout << “ Hello! ” << endl; // «end line» – переход на новую строку cout << “ Input i, j ”; cin >> i >> j; k = i + j; cout << “ Sum i, j = “ << k << endl; } Управление выводом В стандарте языка Си ANSI ввод-вывод данных осуществляется при помощи стандартных библиотечных функций. Управление выводом осуществляется при помощи использования форматов и управляющих символов. Для форматирования и управления выводом данных в потоке введен механизм манипуляторов – специальных функций для модификации работы потока, предназначенных для форматирования данных, как при выводе, так и в оперативной памяти.
Использование манипуляторов Манипуляторы – специальные функции, возвращающие модифицированные данные потока. В большинстве случаев их использование позволяет форматировать данные, как при выводе, так и в оперативной памяти. Для их использования необходимо вместо файла iostream.h подключить заголовочный файл iomanip.h (манипуляторы для вывода потоками). Рассмотрим работу некоторых манипуляторов на конкретном примере. #include<iomanip.h> main() { int a = 157; double b = 1.55555; cout << setw(10) << a << endl; /* Манипулятор setw (n) – устанавливает ширину поля, т.е. n позиций, для вывода объекта. На экране объект а будет выводиться с 8-й позиции, первые 7 позиций – пустые: 157 (заполнение пробелами неиспользуемой части). Действует только для следующего за ним объекта. */ cout << setw(10) << setfill(‘z’) << a << endl; /* Манипулятор setwfill (kod) – устанавливает заполнитель пробелов, заданный символом или его кодом (можно было указать 122 – код символа ' z '). На экране: zzzzzzz157. Действует до изменения или отмены setwfill (0).*/ cout << oct << a << endl; /* Манипулятор oct – выполняет преобразование объекта в 8-ричную форму представления. На экране: 235 */ cout << hex << a << endl; // hex – преобразует объект в 16-ричную форму. На экране: 9d cout << dec << a << endl; // dec – преобразует обратно в 10-тичную. На экране: 157 cout << b << endl; // На экране: 1.55555 cout << setprecision(3) << b << endl; /* setprecision (n) – устанавливает n значащих цифр после запятой с учетом точки или без нее, в зависимости от системы программирования. На экране: 1.56 или 1.556 */ return 0; }
Флажки Помимо манипуляторов для управления выводом данных используются специальные флажки, принадлежащие классу ios, которые также позволяют формировать потоки вывода. Установить флажок позволяет функция setiosflags (ios:: flag); Снять флажок позволяет функция resetiosflags (ios:: flag); Причем можно установить сразу несколько флажков, используя для этого побитовую операцию «|» (поразрядное ИЛИ) для их объединения в одну группу. Следующий пример показывает приемы работы с некоторыми флажками механизма вывода потоками. #include<iostream.h> #include<iomanip.h> #include<conio.h> void main(void) { int a = 157; cout<<setiosflags(ios:: showbase)<<a<<“ “<<oct<<a<< “ “ <<hex<<a<< endl; /* showbase – показать, в какой системе счисления выводится число. На экране: 157 0235 0х9d */ double a1 = 12.99, a2 = 15; cout << setiosflags(ios:: showpoint | ios:: fixed) /* showpoint – печатать десятичную точку, fixed – выводить в форме с фиксированной десятичной точкой */ << setprecision(2) << setfill(‘*’) << setiosflags(ios:: right) // right – выравнивать вывод по правому краю (по левому – left) << “ a1 “ << setw(10) << a1 << “ a2 “ << setw(10) << a2 << endl; // На экране: a1 *****12.99 a2 *****15.00 double pi = 3.14159; cout << “ Pi “ << setw(15) << setfill(‘_’) // Символ заполнения ‘_’ – знак подчеркивания << setiosflags(ios:: showpos | ios:: scientific) << setprecision(5) << pi << endl; /* showpos – явно показать знак «+», scientific – вывод в форме с плавающей десятичной точкой. На экране: Pi _ _ _ +3.14159e+00 */ }
В заключение отметим, что можно создавать свои собственные манипуляторы, которые будут выполнять запрограммированные действия.
16.3. Проблема ввода-вывода кириллицы в среде Visual C++ Работа в среде Visual C++ 6.0 (в режиме консольных приложений) сопряжена с определенными неудобствами. Например, попытка вывести фразу на русском языке, как стандартными функциями вывода, так и с помощью ввода-вывода потоками, терпит неудачу. Создадим в среде Visual C++ 6.0 консольное приложение и наберем следующий текст: #include <iostream.h> int main() { cout << "Welcome to C++!" << endl; cout << "Добро пожаловать в C++!" << endl; return 0; } В результате на экране получим нечто следующее: Welcome to C++! ─юсЕю яюцрыютрЄ№ т C++! Press any key to continue То есть вместо фразы на русском языке получается бессмысленный набор символов. Это вызвано различными стандартами кодировки символов кириллицы в операционных системах MS DOS и Windows. Весь ввод-вывод в консольном окне идет в кодировке стандарта ASCII. Данный стандарт является международным только в первой половине кодов, т.е. для кодов от 0 до 127, а вторая половина кодов от 128 до 255 предназначена для национальных шрифтов. Так, например, в бывшем СССР помимо альтернативной кодировки ГОСТа (Alt), использовались – основная кодировка ГОСТа (Mai), болгарская кодировка (MIC), кодировка КОИ-8 (KOI), у которых символы кириллицы имеют разные коды. Сейчас в России – альтернативная кодировка ASCII. Текст же
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-04-19; просмотров: 6583; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.113 (0.011 с.) |