Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Вбудований контролер пам'ятіСодержание книги
Поиск на нашем сайте
Постановка завдання Тема моєї курсової роботи «Організація віртуальної пам’яті в процесорах сімейства Nehalem». Мета курсової роботи вдосконалення теоретичних знань. Для більш детального розгляду цієї теми необхідно розглянути такі питання: 1.Архітектура Intel Core i (Nehalem) та її особливості 2.Технічні характеристики процесорів 2.1 Intel Core i3 2.2 Intel Core i5 2.3 Intel Core i7 3.Організація віртуальної пам’яті в процесорах Intel
Загальна частина Архітектура Nehalem Корпорація Intel уперше представила мікроархітектуру Nehalem в листопаді 2008 року. Процесори грунтувалися на мікроархітектурі Nehalem, вироблялися за технологією – 45 нм, містили 731 млн. транзисторів у ядрі, три рівня КЕШ-пам'яті (L3 КЕШ – 8 Мб, з технологією Smart Cache), вбудований контролер пам'яті, що підтримує пам'ять DDR3-800/1066 до 24 Гб, і встановлювалися в роз'єм LGA 1366. Працювали на тактовій частоті – 2,67-3,33 ГГц (з технологією Turbo Boost 2,93 - 3,6 ГГц), з шиною QPI. У процесорах використовувалися технології та набори інструкцій: MMX, SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2, Enhanced Intel SpeedStep Technology, Intel 64, XD bit, Intel VT-x, Hyper-threading, Turbo Boost, Smart Cache. Це були перші процесори, створені на основі нової мікроархітектури Nehalem. В процесори було внесено цілий ряд принципових змін. По-перше, було розроблено нове обчислювальне ядро, що базується на обчислювальному ядрі Core, але з низкою змінених або оптимізованих блоків, і на новій системній шині, в сукупності дозволили ядер процесора безпосередньо обмінюватися даними між собою. При цьому максимальна пропускна здатність системної шини становила 25.6 Гб в секунду. По-друге, в процесори був інтегрований трьохканальний контролер пам'яті, що дозволяє значно підняти продуктивність, за рахунок скорочення затримок, пов'язаних з роботою з пам'яттю. По-третє, серйозної переробки піддалася КЕШ-пам'ять. В результаті, КЕШ-пам'ять другого рівня стала індивідуальною для кожного ядра, і її обсяг зменшився до 256 Кб, а КЕШ-пам'ять третього рівня стала загальною для всіх ядер, при цьому за допомогою технології Smart Cache розмір КЕШ-пам'яті третього рівня, відведеної конкретному ядру, змінювався, залежно від навантаження на ядро. Був ще цілий ряд менш принципових змін. У сукупності всі інновації дозволили значно підняти продуктивність процесора навіть без зміни тактової частоти, яка також була немаленькою і досягала 3,33 ГГц, а з технологією Turbo Boost, що дозволяє короткочасно, при підвищенні навантаження на ядро, підвищувати тактову частоту, досягала 3,6 ГГц. В цій архітектурі були використані різні сучасні інновації, що забезпечують рекордне підвищення продуктивності, поліпшення енергозбереження та підвищення швидкодії при роботі в багатозадачному середовищі. Розібравшись з тим, які технології забезпечують підвищення продуктивності процесорів Intel Core i7, можна переходити до знайомства зі структурною схемою (рисунок 2.1), на якій відображені логічні особливості обробки даних.
Рисунок 1.1.1 Архітектура Nehalem
Архітектура Intel Core передбачає симетричний декодер 4-4-4-4, тобто кожен з чотирьох каналів декодера може декодувати інструкції, що породжують до чотирьох мікрооперацій. Більшість команд при декодуванні розбивається на дві-три мікрооперацій, однак зустрічаються і такі команди, для декодування яких потрібні були б десятки і навіть сотні мікрооперацій. Для цих цілей використовується спеціальна ROM-пам'ять (uCode ROM), в якій зберігаються програми, що складаються з послідовності мікрооперацій, причому кожна така програма відповідає одній декодованому інструкції. Після процесу декодування команд починається етап їх виконання. Спочатку відбувається перейменування і розподіл додаткових регістрів процесора (Allocate & Rename), які не визначені архітектурою набору команд. Перейменування регістрів дозволяє домогтися їх безконфліктного існування. На наступному етапі (Retirement Unit (ReOrder Buffer)) відбувається переупорядкування мікрооперацій не в порядку їх надходження (out of order) з тим, щоб згодом можна було реалізувати їх паралельне виконання на виконавчих блоках. Далі відбувається планування та розподіл мікрооперацій за виконавчими блокам. Планувальник (Scheduler) формує черги мікрооперацій, в результаті чого мікрооперацій потрапляють на один з п'яти портів функціональних пристроїв (dispatch ports). Цей процес називається диспетчеризацією (Dispatch), а самі порти виконують функцію шлюзу до функціональних пристроїв. Після того як мікрооперацій пройдуть порти диспетчеризації, вони завантажуються в блок регістрів для подальшого виконання. В архітектурі Intel Core є три порти ALU для операцій з плаваючою комою (Float Point) (FMUL / FPMove, FADD / FPMove, Branch / FPMove), а також по одному порту для запису (Store) і вивантаження (Load) даних з пам'яті. Крім арифметико-логічних та адресних функціональних пристроїв, в кожному процесорі є також пристрої завантаження і вивантаження (Store / Load), які здійснюють доступ до кешам даних і до оперативної пам'яті. Ці пристрої працюють асинхронно з іншими, і їх звичайно не зображують на блок-схемах. Логічно дані пристрої зв'язані з пристроями обчислення адрес читання / запису (AGU). Пристрої завантаження і вивантаження конвеєризовані і можуть одночасно обслуговувати велику кількість запитів. Вони також здійснюють попередню вибірку з оперативної пам'яті (копіювання в кеші тих даних, використання яких очікується найближчим часом). Процес безпосереднього виконання мікрооперацій у виконавчих пристроях відбувається на подальших ступенях конвеєра. Ефективна довжина конвеєра в архітектурі Intel Core становить 14 ступенів. Нова технологія Turbo Boost дозволяє розподіляти продуктивність ПК в залежності від загрузки, та збільшувати тактову частоту процесору на 267 МГц від номінальної. Технологія автоматично збільшує тактову частоту процесора понад номінальною, якщо при цьому не перевищуються обмеження потужності, температури і струму в складі розрахункової потужності (TDP). Це призводить до збільшення продуктивності Однопотокові і багатопоточних додатків. Фактично це технологія "саморазгона" процесора. Доступність технології Turbo Boost не залежить від кількості активних ядер, проте залежить від наявності одного або кількох ядер, що працюють з потужністю нижче розрахункової. Час роботи системи в режимі Turbo Boost залежить від робочого навантаження, умов експлуатації та конструкції платформи.
Трирівнева ієрархія кеша
Intel сконцентрувалася на продуктивності загального кеша L2, який став кращим рішенням для архітектури, яка націлювалася, головним чином, на двоядерні конфігурації. Але у випадку з Nehalem інженери почали з нуля і прийшли до такого ж висновку, що і конкуренти: загальний кеш L2 не дуже добре підходить для "рідної" чотирьохядерний архітектури. Різні ядра можуть занадто часто "вимивати" дані, необхідні іншим ядрам, що призведе до занадто багатьом проблемам з внутрішніми шинами і арбітражем, намагаючись забезпечити всі чотири ядра достатньою пропускною спроможністю із збереженням затримок на досить низькому рівні. Щоб вирішити ці проблеми, інженери оснастили кожне ядро власним кешем L2. Оскільки він виділений на кожне ядро і відносно малий (256 кбайт), вийшло забезпечити кеш дуже високою продуктивністю; зокрема, затримки істотно покращилися в порівнянні з Penryn - з 15 тактів до, приблизно, 10 тактів.
Рисунок 1.3.1 Трирівнева ієрархія кеша
Потім є величезна кеш-пам'ять третього рівня (8 Мбайт), що відповідає за зв'язок між ядрами. На перший погляд архітектура кеша Nehalem нагадує Barcelona, але робота кеша третього рівня дуже відрізняється від AMD - вона інклюзивна для всіх нижніх рівнів ієрархії кеша. Це означає, що якщо ядро спробує отримати доступ до даних, і вони відсутні в кеші L3, то немає необхідності шукати дані у власних кешах інших ядер - там їх немає. Навпаки, якщо дані присутні, чотири біта, пов'язані з кожним рядком кеш-пам'яті (один біт на ядро) показують, чи можуть дані потенційно присутнім (потенційно, але без гарантії) в нижньому кеші іншого ядра, і якщо так, то в якому.
Ця техніка дуже ефективна для забезпечення когерентності персональних кешей кожного ядра, оскільки вона зменшує потребу в обміні інформацією між ядрами. Є, звичайно, недолік у вигляді втрати частини кеш-пам'яті на дані, присутні в кешах інших рівнів. Втім, не все так страшно, оскільки кеші L1 і L2 відносно маленькі в порівнянні з кешем L3 - всі дані кешей L1 і L2 займають, максимум, 1,25 Мбайт в кеші L3 з доступних 8 Мбайт. Як і у випадку Barcelona, кеш третього рівня працює на інших частотах у порівнянні з самим чіпом. Отже, затримка доступу на даному рівні може мінятися, але вона повинна складати близько 40 тактів. Єдині розчарування в новій ієрархії кеша Nehalem пов'язані з кешем L1. Пропускна здатність кешу інструкцій не була збільшена - як і раніше 16 байт на такт у порівнянні з 32 у Barcelona. Це може створити "вузьке місце" в серверно-орієнтованій архітектурі, оскільки 64-бітові інструкції крупніше, ніж 32-бітові, тим більше що у Nehalem на один декодер більше, ніж у Barcelona, що сильніше навантажує кеш. Що стосується кеша даних, його затримка була збільшена до чотирьох тактів в порівнянні з трьома в Conroe, полегшуючи роботу на високих тактових частотах. Core i3 Core i3 (Clarkdale) - двоядерний процесор останнього покоління, призначений для настільних комп'ютерів початкового рівня. Вперше представлений 7 січня 2010 року. Встановлюється в роз'єм LGA1156. Виробляється за 32-нм технології. Оснащений вбудованим двоканальним контролером оперативної пам'яті DDR3-1066/1333 з напругою до 1,6 В. Модулі, розраховані на більш високу напругу, не будуть працювати з цим чіпом і навіть можуть його пошкодити. Забезпечений вбудованим контроллером PCI Express 2.0 x16, завдяки якому графічний прискорювач може підключатися безпосередньо до процесора. Для з'єднання з набором системної логіки застосовується шина DMI (Digital Media Interface) c пропускною спроможністю 2 Гбайт / с. В процесори Core i3 вбудовано графічне ядро GMA HD з дванадцятьма конвеєрами і тактовою частотою 733 Мгц. Базова тактова частота для всіх моделей Core i3 - 133 МГц, номінальні частоти досягаються застосуванням множників. Сумісні набори системної логіки: Intel H55 Express, H57 Express, P55 Express, Q57 Express Таблиця 2.1.2 МОДЕЛЬНИЙ РЯД
Core i5 Core i5 (Clarkdale або Lynnfield) - двох або чотирьохядерний процесор останнього покоління, призначений для настільних комп'ютерів середнього рівня. Вперше представлений 8 вересня 2009 року. Встановлюється в роз'єм LGA1156. Двоядерні Clarkdale проводиться по 32-нм технології, чотирьохядерні Lynnfield - по 45-нм технології. Оснащений вбудованим двоканальним контролером оперативної пам'яті DDR3-1066/1333 з напругою до 1,6 В. Модулі, розраховані на більш високу напругу, не будуть працювати з цим чіпом і навіть можуть його пошкодити. Забезпечений вбудованим контроллером PCI Express 2.0 x16, завдяки якому графічний прискорювач може підключатися безпосередньо до процесора. У моделях з вбудованим графічним ядром GMA HD до чіпу може підключатися одна відеокарта в режимі x16, в моделях без вбудованої графіки - дві відеокарти в режимі x8 кожна. Для з'єднання з набором системної логіки застосовується шина DMI (Digital Media Interface) c пропускною спроможністю 2 Гбайт / с. У двоядерних моделях (серія 6хх) вбудований графічний адаптер GMA HD і реалізована технологія Hyper-Threading, в чотирьохядерних (серія 7xx) графіки і Hyper-Threading немає. У моделях, номер яких закінчується на 1, тактова частота графіки становить 900 МГц, в моделях, номер яких закінчується на 0, графічне ядро працює на частоті 733 МГц. У всіх Core i5 реалізована технологія автоматичного підвищення тактової частоти Turbo Boost в ресурсномістких завданнях. Базова тактова частота для всіх моделей Core i5 - 133 МГц, номінальні частоти досягаються застосуванням множників. Сумісні набори системної логіки: Intel H55 Express, H57 Express, P55 Express, Q57 Express. Core i7 Core i7 (Bloomfield, Lynnfield або Gulftown) - чотирьох або шестиядерний процесор останнього покоління, призначений для настільних комп'ютерів вищого класу. Вперше представлений в листопаді 2008 року. Чотирьохядерні Bloomfield і Lynnfield проводиться по 45-нм технології, шестиядерні Lynnfield - по 32-нм технології. Випускаються в двох модифікаціях: серія 9хх (для роз'єму LGA1366) з вбудованим трьохканальним контролером пам'яті і шиною QPI і серія 8xx (для роз'єму LGA1156) c двоканальним контролером пам'яті, вбудованим контролером PCI Express 2.0 і шиною DMI) Підтримується оперативна пам'ять DDR3-1066/1333 з напругою до 1,6 В. Модулі, розраховані на більш високу напругу, не будуть працювати з цим чіпом і навіть можуть його пошкодити. Процесори для роз'єму LGA1366 оснащуються швидкісний шиною QPI, що працює на частоті 2,4 ГГц (до 4,8 Гбайт / с) в звичайних i7 і на частоті 3,2 ГГц (6,4 Гбайт / с) в модифікаціях Extreme (до них відносяться i7-965, i7-975 і i7-980X. Чіпи для роз'єму LGA1156 забезпечені вбудованим контроллером PCI Express 2.0 x16, завдяки якому графічний прискорювач може підключатися безпосередньо до процесора. Для з'єднання з набором системної логіки тут застосовується шина DMI (Digital Media Interface) c пропускною спроможністю 2 Гбайт / с. У всіх Core i7 реалізовані технологія автоматичного підвищення тактової частоти Turbo Boost в ресурсномістких завданнях, а також технологія Hyper-Threading. Базова тактова частота для всіх моделей Core i7 - 133 МГц, номінальні частоти досягаються застосуванням множників. У модифікаціях Core i7 Extreme множник розблоковано, що дозволяє безперешкодно підвищувати тактову частоту процесора. Сумісні набори системної логіки: серія 8xx - Intel H55 Express, H57 Express, P55 Express, Q57 Express, серія 9xx - Intel X58 Express. Зміна адрес та ізоляція У технології Intel VT-d використовується зміна адрес DMA для обмеження доступу DMA до певних доменів, пов'язаним з фізичними областями пам'яті. Апаратна логіка зміни адрес DMA в наборі мікросхем розміщується між периферійними пристроями з підтримкою DMA і фізичної пам'яттю. Архітектура Intel VT-d дозволяє системному програмному забезпеченню (VMM або операційній системі в Невіртуальна середовищах) створювати один або кілька захищених доменів DMA, що представляють собою ізольовані середовища, для яких виділені піднабору фізичної пам'яті (показання як кольорові галузі фізичної пам'яті на Малюнку 1). Захищений домен DMA може являти собою пам'ять, призначену віртуальній машині, або пам'ять DMA, виділену драйвером гостьової ОС, працюючим на віртуальній машині або на VMM. Системне програмне забезпечення призначає кожному пристрою вводу / виводу захищений домен. Весь доступ DMA з пристроїв введення / виводу перекладається на фізичні адреси вузла відповідно до призначеним влаштуванню доменом, запобігаючи доступ до пам'яті за меж призначеного домену. Зміна адрес дозволяє пристрою (і драйверу) працювати з адресами віртуальної машини замість адрес фізичної пам'яті.
Рисунок 3.4.1.1 Технологія — ВІРТУАЛІЗАЦІЯ INTEL
Для підвищення продуктивності зміни адрес часто використовувані запису структури зміни адрес, наприклад, прив'язка пристроїв введення / виводу до захищених доменам і запису в таблиці перетворення адрес DMA зберігаються в кеш-пам'яті (Малюнок 3). Майбутні версії технології Intel VT-d також будуть підтримувати стандарт PCI-SIG ATS, який визначає засоби дозволу кешування перетворень адрес DMA в кінцевих пристроях.
Рисунок 3.4.1.2 Архітектура технології віртуалізації Intel
Технологія Intel VT-d перетворить адреси DMA пристроїв введення / виводу в адреси фізичних пристроїв у відповідності з призначеними доменами. Для підвищення продуктивності часто використовувані структури зберігаються в кеш-пам'яті. Висновок Ми розглянули чергову революційну платформу, яка может підняти планку продуктивності на ще більший рівень. Nehalem — нова мікроархітектура для процесорів Bloomfield у виконанні LGA 1366, а також для процесорів Lynnfield у виконанні LGA 1156. Мікропроцесори продаються під торговою маркою Core i7 і Core i5. Дізналися, що технологія обробки віртуальної пам’яті в процесорах розроблена для багатозадачних операційних систем. При використанні даної технології для кожної програми використовуються незалежні схеми адресації пам'яті, які відображаються тим або іншим способом на фізичні адреси в пам'яті ЕОМ. Дозволяє збільшити ефективність використання пам'яті декількома одночасно працюючими програмами, організувавши безліч незалежних адресних просторів і забезпечити захист пам'яті між різними додатками. Також дозволяє програмісту використовувати більше пам'яті, ніж встановлено в комп'ютері, за рахунок відкачування не використовуваних сторінок на вторинне сховище (див. Підкачка сторінок). Ми дізналися, що при використанні віртуальної пам'яті спрощується програмування, так як програмісту більше не потрібно враховувати обмеженість пам'яті, або погоджувати використання пам'яті з іншими додатками. Для програми виглядає доступним і безперервним все допустиме адресний простір, поза залежністю від наявності в ЕОМ відповідного обсягу ОЗУ.
Література Електроні ресурси 1. Нечай О.И. «Технічні характеристики процесорів» [Електронний ресурс] Режим доступу до статті http://windxp.com.ru 2. Керри Джонс-Вано, Филиппу Ланке, Дэвиду Дж. Коупертвейту, Раджеша Санкарану, Кену Страндбергу, Роджеру Херрику «Технологія Intel ® Віртуалізація (Virtualization Technology)». Режим доступу до статті http://www.intel.com 3. «Мій персональний комп’ютер. Архітектура Intel i(Nehalem)» Доступ до статті http://dammlab.com Постановка завдання Тема моєї курсової роботи «Організація віртуальної пам’яті в процесорах сімейства Nehalem». Мета курсової роботи вдосконалення теоретичних знань. Для більш детального розгляду цієї теми необхідно розглянути такі питання: 1.Архітектура Intel Core i (Nehalem) та її особливості 2.Технічні характеристики процесорів 2.1 Intel Core i3 2.2 Intel Core i5 2.3 Intel Core i7 3.Організація віртуальної пам’яті в процесорах Intel
Загальна частина Архітектура Nehalem Корпорація Intel уперше представила мікроархітектуру Nehalem в листопаді 2008 року. Процесори грунтувалися на мікроархітектурі Nehalem, вироблялися за технологією – 45 нм, містили 731 млн. транзисторів у ядрі, три рівня КЕШ-пам'яті (L3 КЕШ – 8 Мб, з технологією Smart Cache), вбудований контролер пам'яті, що підтримує пам'ять DDR3-800/1066 до 24 Гб, і встановлювалися в роз'єм LGA 1366. Працювали на тактовій частоті – 2,67-3,33 ГГц (з технологією Turbo Boost 2,93 - 3,6 ГГц), з шиною QPI. У процесорах використовувалися технології та набори інструкцій: MMX, SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2, Enhanced Intel SpeedStep Technology, Intel 64, XD bit, Intel VT-x, Hyper-threading, Turbo Boost, Smart Cache. Це були перші процесори, створені на основі нової мікроархітектури Nehalem. В процесори було внесено цілий ряд принципових змін. По-перше, було розроблено нове обчислювальне ядро, що базується на обчислювальному ядрі Core, але з низкою змінених або оптимізованих блоків, і на новій системній шині, в сукупності дозволили ядер процесора безпосередньо обмінюватися даними між собою. При цьому максимальна пропускна здатність системної шини становила 25.6 Гб в секунду. По-друге, в процесори був інтегрований трьохканальний контролер пам'яті, що дозволяє значно підняти продуктивність, за рахунок скорочення затримок, пов'язаних з роботою з пам'яттю. По-третє, серйозної переробки піддалася КЕШ-пам'ять. В результаті, КЕШ-пам'ять другого рівня стала індивідуальною для кожного ядра, і її обсяг зменшився до 256 Кб, а КЕШ-пам'ять третього рівня стала загальною для всіх ядер, при цьому за допомогою технології Smart Cache розмір КЕШ-пам'яті третього рівня, відведеної конкретному ядру, змінювався, залежно від навантаження на ядро. Був ще цілий ряд менш принципових змін. У сукупності всі інновації дозволили значно підняти продуктивність процесора навіть без зміни тактової частоти, яка також була немаленькою і досягала 3,33 ГГц, а з технологією Turbo Boost, що дозволяє короткочасно, при підвищенні навантаження на ядро, підвищувати тактову частоту, досягала 3,6 ГГц. В цій архітектурі були використані різні сучасні інновації, що забезпечують рекордне підвищення продуктивності, поліпшення енергозбереження та підвищення швидкодії при роботі в багатозадачному середовищі. Розібравшись з тим, які технології забезпечують підвищення продуктивності процесорів Intel Core i7, можна переходити до знайомства зі структурною схемою (рисунок 2.1), на якій відображені логічні особливості обробки даних.
Рисунок 1.1.1 Архітектура Nehalem
Архітектура Intel Core передбачає симетричний декодер 4-4-4-4, тобто кожен з чотирьох каналів декодера може декодувати інструкції, що породжують до чотирьох мікрооперацій. Більшість команд при декодуванні розбивається на дві-три мікрооперацій, однак зустрічаються і такі команди, для декодування яких потрібні були б десятки і навіть сотні мікрооперацій. Для цих цілей використовується спеціальна ROM-пам'ять (uCode ROM), в якій зберігаються програми, що складаються з послідовності мікрооперацій, причому кожна така програма відповідає одній декодованому інструкції. Після процесу декодування команд починається етап їх виконання. Спочатку відбувається перейменування і розподіл додаткових регістрів процесора (Allocate & Rename), які не визначені архітектурою набору команд. Перейменування регістрів дозволяє домогтися їх безконфліктного існування. На наступному етапі (Retirement Unit (ReOrder Buffer)) відбувається переупорядкування мікрооперацій не в порядку їх надходження (out of order) з тим, щоб згодом можна було реалізувати їх паралельне виконання на виконавчих блоках. Далі відбувається планування та розподіл мікрооперацій за виконавчими блокам. Планувальник (Scheduler) формує черги мікрооперацій, в результаті чого мікрооперацій потрапляють на один з п'яти портів функціональних пристроїв (dispatch ports). Цей процес називається диспетчеризацією (Dispatch), а самі порти виконують функцію шлюзу до функціональних пристроїв. Після того як мікрооперацій пройдуть порти диспетчеризації, вони завантажуються в блок регістрів для подальшого виконання. В архітектурі Intel Core є три порти ALU для операцій з плаваючою комою (Float Point) (FMUL / FPMove, FADD / FPMove, Branch / FPMove), а також по одному порту для запису (Store) і вивантаження (Load) даних з пам'яті. Крім арифметико-логічних та адресних функціональних пристроїв, в кожному процесорі є також пристрої завантаження і вивантаження (Store / Load), які здійснюють доступ до кешам даних і до оперативної пам'яті. Ці пристрої працюють асинхронно з іншими, і їх звичайно не зображують на блок-схемах. Логічно дані пристрої зв'язані з пристроями обчислення адрес читання / запису (AGU). Пристрої завантаження і вивантаження конвеєризовані і можуть одночасно обслуговувати велику кількість запитів. Вони також здійснюють попередню вибірку з оперативної пам'яті (копіювання в кеші тих даних, використання яких очікується найближчим часом). Процес безпосереднього виконання мікрооперацій у виконавчих пристроях відбувається на подальших ступенях конвеєра. Ефективна довжина конвеєра в архітектурі Intel Core становить 14 ступенів. Нова технологія Turbo Boost дозволяє розподіляти продуктивність ПК в залежності від загрузки, та збільшувати тактову частоту процесору на 267 МГц від номінальної. Технологія автоматично збільшує тактову частоту процесора понад номінальною, якщо при цьому не перевищуються обмеження потужності, температури і струму в складі розрахункової потужності (TDP). Це призводить до збільшення продуктивності Однопотокові і багатопоточних додатків. Фактично це технологія "саморазгона" процесора. Доступність технології Turbo Boost не залежить від кількості активних ядер, проте залежить від наявності одного або кількох ядер, що працюють з потужністю нижче розрахункової. Час роботи системи в режимі Turbo Boost залежить від робочого навантаження, умов експлуатації та конструкції платформи.
Вбудований контролер пам'яті Intel включає цілих три контролера пам'яті DDR3. Якщо встановити пам'ять DDR3-1333, яку Nehalem теж буде підтримувати, це дасть пропускну спроможність до 32 Гбайт / с в деяких конфігураціях. Але перевага вбудованого контролера пам'яті криється не тільки в пропускній спроможності. Він істотно знижує затримки доступу до пам'яті, що не менш важливо, враховуючи, що кожен доступ коштує кілька сотень тактів. У контексті настільного використання зниження затримок вбудованого контролера пам'яті можна вітати, однак повну перевагу від більш масштабованої архітектури буде помітно в многосокетних серверних конфігураціях. Раніше при додаванні CPU доступна пропускна спроможність залишалася колишньою, проте тепер кожен новий додатковий процесор збільшує пропускну спроможність, оскільки кожен CPU володіє власною пам'яттю.
Рисунок 1.2.1 Вбудований контролер памяті
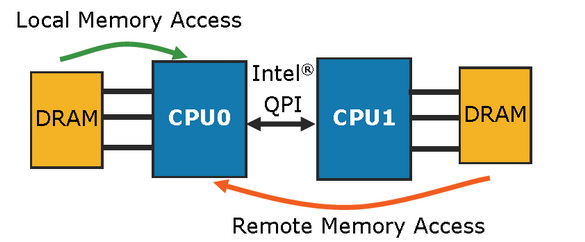
Звичайно, чудес чекати не слід. Перед нами конфігурація Non Uniform Memory Access (NUMA), тобто доступ до пам'яті буде обходитися з тих чи інших накладним розцінками, залежно від того, де дані розташовуються в пам'яті. Зрозуміло, що доступ до локальної пам'яті буде проводитися з самими низькими затримками і самої високою пропускною здатністю, оскільки доступ до віддаленої пам'яті відбувається через проміжний інтерфейс QPI, що знижує продуктивність.
Вплив на продуктивність передбачити складно, оскільки все залежить від програми та операційної системи. Intel стверджує, що падіння продуктивності при віддаленому доступі по затримкам становить близько 70%, а пропускна здатність знижується в два рази в порівнянні з локальним доступом. За інформацією Intel, навіть при віддаленому доступі через інтерфейс QPI, затримки будуть нижче, ніж на попередніх поколіннях процесорів, де контролер знаходився на північному мосту. Однак це стосується тільки серверних додатків, які вже досить тривалий час розробляються з урахуванням конфігурацій NUMA.
Трирівнева ієрархія кеша
Intel сконцентрувалася на продуктивності загального кеша L2, який став кращим рішенням для архітектури, яка націлювалася, головним чином, на двоядерні конфігурації. Але у випадку з Nehalem інженери почали з нуля і прийшли до такого ж висновку, що і конкуренти: загальний кеш L2 не дуже добре підходить для "рідної" чотирьохядерний архітектури. Різні ядра можуть занадто часто "вимивати" дані, необхідні іншим ядрам, що призведе до занадто багатьом проблемам з внутрішніми шинами і арбітражем, намагаючись забезпечити всі чотири ядра достатньою пропускною спроможністю із збереженням затримок на досить низькому рівні. Щоб вирішити ці проблеми, інженери оснастили кожне ядро власним кешем L2. Оскільки він виділений на кожне ядро і відносно малий (256 кбайт), вийшло забезпечити кеш дуже високою продуктивністю; зокрема, затримки істотно покращилися в порівнянні з Penryn - з 15 тактів до, приблизно, 10 тактів.
Рисунок 1.3.1 Трирівнева ієрархія кеша
Потім є величезна кеш-пам'ять третього рівня (8 Мбайт), що відповідає за зв'язок між ядрами. На перший погляд архітектура кеша Nehalem нагадує Barcelona, але робота кеша третього рівня дуже відрізняється від AMD - вона інклюзивна для всіх нижніх рівнів ієрархії кеша. Це означає, що якщо ядро спробує отримати доступ до даних, і вони відсутні в кеші L3, то немає необхідності шукати дані у власних кешах інших ядер - там їх немає. Навпаки, якщо дані присутні, чотири біта, пов'язані з кожним рядком кеш-пам'яті (один біт на ядро) показують, чи можуть дані потенційно присутнім (потенційно, але без гарантії) в нижньому кеші іншого ядра, і якщо так, то в якому.
Ця техніка дуже ефективна для забезпечення когерентності персональних кешей кожного ядра, оскільки вона зменшує потребу в обміні інформацією між ядрами. Є, звичайно, недолік у вигляді втрати частини кеш-пам'яті на дані, присутні в кешах інших рівнів. Втім, не все так страшно, оскільки кеші L1 і L2 відносно маленькі в порівнянні з кешем L3 - всі дані кешей L1 і L2 займають, максимум, 1,25 Мбайт в кеші L3 з доступних 8 Мбайт. Як і у випадку Barcelona, кеш третього рівня працює на інших частотах у порівнянні з самим чіпом. Отже, затримка доступу на даному рівні може мінятися, але вона повинна складати близько 40 тактів. Єдині розчарування в новій ієрархії кеша Nehalem пов'язані з кешем L1. Пропускна здатність кешу інструкцій не була збільшена - як і раніше 16 байт на такт у порівнянні з 32 у Barcelona. Це може створити "вузьке місце" в серверно-орієнтованій архітектурі, оскільки 64-бітові інструкції крупніше, ніж 32-бітові, тим більше що у Nehalem на один декодер більше, ніж у Barcelona, що сильніше навантажує кеш. Що стосується кеша даних, його затримка була збільшена до чотирьох тактів в порівнянні з трьома в Conroe, полегшуючи роботу на високих тактових частотах.
|
||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-04-08; просмотров: 317; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.15.12.133 (0.011 с.) |