Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Однородные и неоднородные СУРБДСодержание книги
Поиск на нашем сайте
Распределённые системы часто строятся путём «интеграции» разнородных аппаратных и программных средств. Следовательно, должен быть сделан выбор между однородной и неоднородной вычислительной системой. В случае однородных СУБД нет проблем ни с моделями данных, ни с языками запросов, ни с другими средствами. Всё это совпадает с тем, что поддерживается несколько СУБД. Для неоднородных СУБД вопросы усложняются. Использования неоднородных СУБД обычно является следствием формирования распределенной БД из ряда существовавших ранее автономных баз данных. Стоящая перед разработчиками цель – достичь прозрачного доступа, что представляет собой нечто большее, чем простое обеспечение доступа к удалённым СУБД и их базам данных.
Однородные распределенные системы баз данных имеют в своей основе один продукт СУБД, обычно с единственным языком баз данных (например, SQL с расширениями для управления распределенными данными). СУБД с поддержкой однородного распределения являются сильно связанными системами, их встроенные средства поиска данных и средства обработки запросов оптимизированы и настроены для достижения максимальной производительности и пропускной способности.
Противоположностью однородных систем распределенных БД являются неоднородные распределенные системы БД. Неоднородные системы включают два или более существенно различающихся продукта управления данными (например, реляционные СУБД от разных поставщиков, таких, как Oracle и Digital Equipment Corp., или СУБД одного поставщика, но функционирующие на разных платформах и использующие различные структуры баз данных, такие, как DB2 и SQL/DS компании IBM). На рис. 2.2 показана типичная конфигурация неоднородной распределенной базы данных.
Однородные распределенные системы баз данных обычно проектируются методом «сверху вниз»; неоднородные же, напротив, чаще всего строятся «снизу вверх» с целью создать общую среду управления над существовавшими ранее разрозненными информационными ресурсами.
5. Методы построения РБД "сверху вниз" и "снизу вверх". Фрагментация и тиражирование.
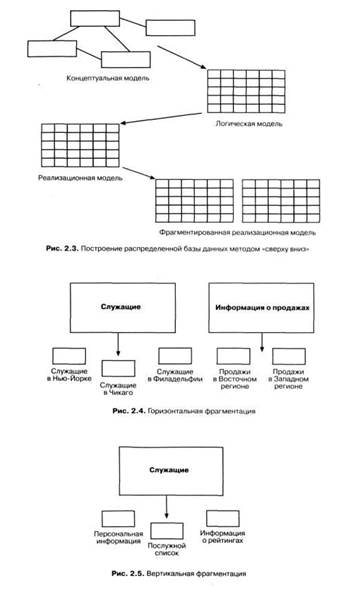
Рассмотрим сначала процесс построения распределенных баз данных методом "сверху вниз", поскольку он концептуально наиболее прост для понимания. Проектирование РаБД "сверху вниз" осуществляется в целом аналогично проектированию централизованных баз данных. В идеале оно проводится с помощью одной из формальных методологий, которые включают создание концептуальной модели базы данных, отображение ее в логическую модель данных и, наконец, создание (и настройку) специфических для конкретной СУБД структур (например, таблиц базы данных
Однако при проектировании РаБД методом "сверху вниз" предполагается, что ее объекты не будут сосредоточены в одном месте, а распределятся по нескольким вычислительным системам. Распределение проводится путем фрагментации или тиражирования.
Фрагментация означает декомпозицию объектов базы данных, таких, как реляционные таблицы, на две или более частей, которые размещаются на разных компьютерных системах. Классический пример, который обычно используют для иллюстрации этого понятия, - таблица с данными о сотрудниках или о заказах на продажу, разделенная на фрагменты по географическому или другому характеристическому признаку.
На рис. 2.4 показана горизонтальная фрагментация, когда в таблице делаются горизонтальные "срезы" в соответствии со значением, скажем, какого-либо столбца таблицы. Строки данных о сотрудниках могут разбиваться на подмножества, соответствующие филиалам. Данные о продажах фрагментируются по магазинам, где эти продажи производились.
Альтернативная модель фрагментации - вертикальная - означает разбиение таблицы не по строкам, а по столбцам (рис 2.5). В этом случае некоторая часть информации о каждом сотруднике хранится в одном месте, а другая часть (относящаяся к той же таблице) - в другом.
Независимо от того, применяется горизонтальная или вертикальная фрагментация, поддерживается глобальная схема, позволяющая воссоздать из имеющихся фрагментов логически централизованную таблицу или другую структуру базы данных.
Тиражирование (или репликация) означает (как вы могли, вероятно, догадаться) создание дубликатов данных. Репликаты - это множество различных физических копий некоторого объекта базы данных (обычно таблицы), для которых в соответствии с определенными в базе данных правилами поддерживается синхронизация (идентичность) с некоторой "главной" копией. Теоретически значения всех данных в тиражированных объектах должны автоматически и незамедлительно синхронизироваться друг с другом. (На практике это правило обычно несколько ослабляется.) В некоторых системах копии используются исключительно в режиме чтения и обновляются в соответствии с заданным расписанием. В других средах допускается модификация отдельных значений в копиях, и эти изменения распространяются в соответствии с процедурами планирования и координации. На рис 2.6 показаны различные модели тиражирования.
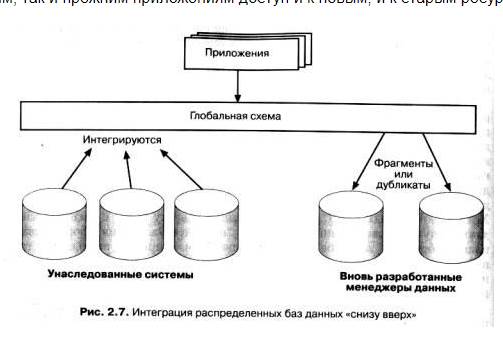
Идеология построения распределенных баз данных по принципу "сверху вниз" применима только к однородным РаБД, для которых вначале определяется глобальная схема, а затем производится распределение объектов базы данных. Такой подход оправдан при создании новых приложений, но гораздо вероятнее, что вашей организации придется решать задачу создания интегрированной среды путем объединения существующих баз данных и соответствующих информационных менеджеров, возможно, в дополнение к некоторым вновь проектируемым компонентам баз данных. В этом случае разработчики не могут позволить себе "роскошь" проектирования "сверху вниз". Здесь приходится прибегать к проектированию "снизу вверх", где основной проблемой становится объединение схем уже существующих баз данных, чтобы предоставить как новым, так и прежним приложениям доступ и к новым, и к старым ресурсам данных.
Типы РБД. Распределённая база данных (англ. distributed database, DDB) — база данных, составные части которой размещаются в различных узлах компьютерной сети в соответствии с каким-либо критерием.
Распределенная база данных состоит из нескольких, возможно пересекающихся или даже дублирующих друг друга частей, хранимых в различных ЭВМ вычислительной сети. Работа с такой базой осуществляется с помощью системы управления распределенной базой данных (СУРБД). По способу доступа к данным базы данных разделяются на базы данных с локальным доступом и базы данных с удаленным (сетевым) доступом. Типы (модели) РБД:
Локальные +Автономна; - с БД работает 1 человек, сложно обновлять при большом количестве пользователей. БД и СУБД находятся на одном компьютере
Файл-серверные + несколько человек работают с одной БД; - Основную работу выполняют рабочие станции, копируя всю БД на ПК-нагрузка на сеть, слабая защита от взлома. БД находятся на сервере сети, а СУБД на ПК пользователя (MS Access, Borland Paradox).
Клиент-серверные +Основная работа выполняется на сервере; Защита на сервере; Разделение доступа; Модернизация только на сервере; - Сложность настройки. БД и СУБД на сервере. Клиент СУБД на рабочей станции посылает запрос и выводит результат на экран (PostgreSQL, MySQL, MS SQL Server).
|
||||
|
|
Последнее изменение этой страницы: 2021-07-18; просмотров: 239; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.12.146.108 (0.007 с.) |