Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Представление структур данных в памяти ЭВМСтр 1 из 11Следующая ⇒
Основные понятия банков данных. Представление структур данных в памяти ЭВМ. Механизмы агрегирования данных. Общие свойства структур данных. Основные понятия банков данных Банк данных (БнД) является современной формой организации хранения и доступа к информации. Банк данных — это система специальным образом организованных данных (баз данных), программных, технических, языковых, организационно-методических средств, предназначенных для обеспечения централизованного накопления и коллективного многоцелевого использования данных.
В этом определении также обозначены и основные отличительные особенности банков данных: -Базы данных создаются обычно для многоцелевого использования. -Базы данных отражают определенную часть реального мира. Надо стремиться, чтобы вся информация, описывающая предметную область, фиксировалась в базе данных однократно, накапливалась и поддерживалась в актуальном состоянии централизовано, а все пользователи, которым эта информация нужна, должны иметь возможность работать с ней. -Базы данных — это специальным образом организованные данные. Эти особенности в организации данных заключаются, прежде всего, в том, что БД представляют собой системы взаимосвязанных данных, единство и целостность которых поддерживается специальными программными средствами. -Для функционирования БнД необходимо наличие специальных языковых и программных средств (называемых СУБД — Система Управления Базами Данных), облегчающих для пользователей выполнение всех операций, связанных с организацией хранения данных, их корректировки и доступа к ним.
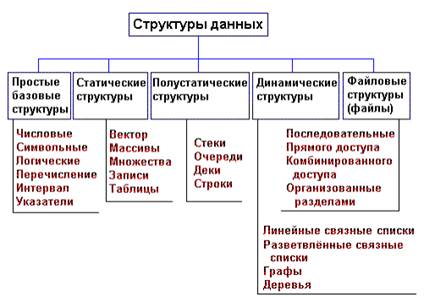
Представление структур данных в памяти ЭВМ
Под структурой данных в общем случае понимают множество элементов данных и множество связей между ними. При этом различают физическую и абстрактную структуры данных. Понятие физическая структура данных отражает способ физического представления данных в памяти машины и называется еще структурой хранения, внутренней структурой или структурой памяти. Рассмотрение структуры данных без учета ее представления в машинной памяти называется абстрактной или логической структурой. Рассмотрим классификацию структур данных.
Различаются ПРОСТЫЕ (базовые) структуры данных и СЛОЖНЫЕ (интегрированные). Простыми называются такие структуры данных, которые не могут быть расчленены на составные части, большие, чем биты. Сложными называются такие структуры данных, составными частями которых являются другие структуры данных - простые или в свою очередь сложные. Сложные структуры данных конструируются программистом с использованием средств интеграции данных, предоставляемых языками программирования.
Механизмы агрегирования данных.
В результате агрегирования большое количество записей о каждом событии в бизнес-процессе заменяется относительно небольшим количеством записей, содержащих агрегированные значения.
Распределённые базы данных (РБД). Системы управления распределенными базами данных (СУРБД). Фундаментальные правила создания РБД.
Распределённые базы данных (РБД) — совокупность логически взаимосвязанных баз данных, распределённых в компьютерной сети. Система управления распределенной базой данных - это программная система, которая обеспечивает управление распределенной базой данных и прозрачность ее распределения для пользователей (MySQL, MS SQL Server).
Модели РБД. Однородные и неоднородные СУРБД. Модели РБД
Логическая модель РБД строится на 3-х уровнях (слоях) абстракции данных: представления информации, обработки (бизнес-логики) и хранения. Слои образуют строгую иерархию: слой бизнес -логики взаимодействует со слоями хранения и представления. Физически, слои могут входить в состав одного программного модуля, или же распределяться на нескольких параллельных процессах в одном или нескольких узлах сети.
Слой бизнес-логики Связующий, именно он определяет функциональность и работоспособность системы в целом. Блоки программного кода распределены по сети и могут использоваться многократно (CORBA, DCOM) для создания сложных распределенных приложений.
Слой хранения данных Обеспечивает физическое хранение, добавление, модификацию и выборку данных. На данный слой также возлагается проверка целостности и непротиворечивости данных, а также реализацию разделенных транзакций.
Слои распределенной системы могут быть по-разному реализованы и исполняться в разных узлах сети. Обычно рассматриваются следующие архитектуры
Типы РБД. Распределённая база данных (англ. distributed database, DDB) — база данных, составные части которой размещаются в различных узлах компьютерной сети в соответствии с каким-либо критерием.
Распределенная база данных состоит из нескольких, возможно пересекающихся или даже дублирующих друг друга частей, хранимых в различных ЭВМ вычислительной сети. Работа с такой базой осуществляется с помощью системы управления распределенной базой данных (СУРБД). По способу доступа к данным базы данных разделяются на базы данных с локальным доступом и базы данных с удаленным (сетевым) доступом. Типы (модели) РБД:
Локальные +Автономна; - с БД работает 1 человек, сложно обновлять при большом количестве пользователей. БД и СУБД находятся на одном компьютере
Файл-серверные + несколько человек работают с одной БД; - Основную работу выполняют рабочие станции, копируя всю БД на ПК-нагрузка на сеть, слабая защита от взлома. БД находятся на сервере сети, а СУБД на ПК пользователя (MS Access, Borland Paradox).
Клиент-серверные +Основная работа выполняется на сервере; Защита на сервере; Разделение доступа; Модернизация только на сервере; - Сложность настройки. БД и СУБД на сервере. Клиент СУБД на рабочей станции посылает запрос и выводит результат на экран (PostgreSQL, MySQL, MS SQL Server).
Пользователи базы данных
Каждый пользователь проходит два этапа проверки системы безопасности при попытке доступа к данным: — Этап 1 – аутентификация, — Этап 2 – получение доступа к данным Первый этап относится к уровню работы всего сервера СУБД. На первом этапе пользователь идентифицирует себя с помощью логического имени (login) и пароля (password). Логическое имя и пароль хранятся на сервере СУБД в виде учетной записи (account). Если данные были введены правильно, то считается, что процедура аутентификации пройдена, и данный сервер СУБД разрешает попытку доступа к конкретной базе данных. Однако сама по себе аутентификация не дает пользователю права доступа к каким бы то ни было данным. Для получения доступа к данным необходимо, чтобы учетной записи пользователя соответствовал некоторый пользователь базы данных (database user). Пользователь базы данных – совокупность разрешений и запретов на работу с данными в конкретной базе данных. На втором этапе (авторизации) учетная запись пользователя отображается в пользователя базы данных, и получает все привилегии, соответствующие этому пользователю базы данных. Второй этап задействует систему безопасности конкретной базы данных, а не всего сервера СУБД. В разных базах данных одной и той же учетной записи могут соответствовать одинаковые или разные имена пользователя базы данных с разными правами доступа. В том случае, когда учетная запись пользователя не отображается в пользователя базы данных, клиент все же может получить доступ к базе данных под гостевым именем guest (если оно не запрещено администратором БД). Гостевой вход позволяет минимальный доступ к данным только в режиме чтения.
Пользователи баз данных могут объединяться в роли (группы) для упрощения управления системой безопасности.
Создание и использование хранимых процедур. Пример.
Хранимая процедура – объект БД, хранящийся на сервере. Может возвращать одно значение и набор значений, а также не возвращать значения вовсе. Процедуры выполняются отдельно, их нельзя вызвать в запросах и других изображениях. Процедуры нужны для инкапсуляции повторяющихся действий, разделения бизнес-логики с клиентскими приложениями (часть логики реализована на стороне БД, часть – реализовывается в приложениях), для повышения безопасности БД, для сокращения сетевого трафика в вопросе обмена данными между клиентскими приложениями и СУБД. В хранимые процедуры можно помещать часто используемые запросы. Функция отличается от процедуры тем, что её можно вызывать в запросах и других выражениях. Всегда возвращает только одно значение.
Пример:
CREATE PROCEDURE components AS SELECT * FROM component; EXECUTE components; --///Процедура для вывода всех используемых компонентов для ремонта устройств go CREATE PROCEDURE componentspara @name char(40) AS SELECT * FROM component where name_component= @name; EXECUTE componentspara "Дисплей"; --///Процедура для вывода компонентов c именем "Дисплей"
Пользовательские функции. Создание и использование скалярных функций. Пример.
Скалярные пользовательские функции возвращают скалярный (однозначный) результат, такой как строка или число. Запрещается использовать нескалярные типы, такие как курсоры и таблицы. Кроме того, скалярные функции не могут возвращать значения с типом timestamp, text, ntext или image, а также значения, имеющие тип данных, определенный пользователем, даже если базовый тип при этом является скаляром.
CREATE FUNCTION providerdata (@provider varchar(150)) RETURNS varchar(150) AS BEGIN declare @fulldata varchar(150) select @fulldata = city + '-' + street_home + '-' +telefone from provider where vendor = @provider; RETURN (@fulldata) end go select dbo.providerdata ('ООО МобКомплект'); --///Функция получения и вывода данных поставщика по его названию
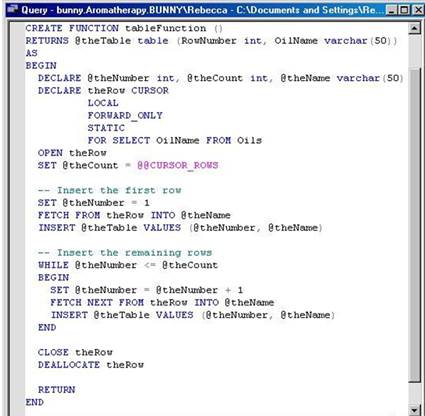
Создание и использование табличных функций. Пример.
Табличные пользовательские функции возвращают таблицу. Оператор CREATE FUNCTION поддерживает создание двух различных типов табличных функций: подставляемых и многооператорных. Тело подставляемой табличной функции состоит из единственного оператора SELECT, в то время как многооператорная табличная функция может состоять из любого числа операторов Transact-SQL.
Синтаксис для подставляемой табличной функции является усеченной разновидностью оператора CREATE FUNCTION. Блок BEGIN...END отсутствует, и нет никаких других операторов, кроме RETURN. Синтаксис оператора CREATE FUNCTION для многооператорной табличной функции сочетает элементы синтаксиса для скалярной и для подставляемой функций:
CREATE FUNCTION имя_функции (список_параметров) RETURNS @локальная_табличная_переменная TABLE (определение_таблицы) AS BEGIN операторы_tsql RETURN END Подобно скалярным функциям, в многооператорной табличной функции команды Transact-SQL располагаются внутри блока BEGIN...END. Поскольку блок может содержать несколько операторов SELECT, в фразе RETURNS вы должны явно определить таблицу, которая будет возвращаться. Поскольку оператор RETURN в многооператорной табличной функции всегда возвращает таблицу, заданную во фразе RETURNS, он должен выполняться без аргументов, – например, RETURN, а не RETURN @myTable.
CREATE FUNCTION orderclientdata (@surname varchar(50)) RETURNS table AS RETURN (select * from client where surname = @surname) go select * from orderclientdata ('Сорин'); --///Табличная функция для получения и вывода данных клиента по его фамилии
Создание триггера типа DELETE. Пример.
create trigger clientInsteadof on client instead of delete as print 'Удаление клиентских данных запрещено'; delete from client; --///Триггер, выводящий сообщение о запрете удаления данных из таблицы client.
Создание триггера типа INSERT. Пример.
GO CREATE TABLE AuditClient( UserName CHAR(16) NULL, Date DATETIME NULL, ClientNew FLOAT NULL );
GO CREATE TRIGGER trigger_ModifyClient ON client AFTER INSERT AS BEGIN DECLARE @clientNew INT SELECT @clientNew = (SELECT id_client FROM inserted) INSERT INTO AuditClient VALUES (USER_NAME(), GETDATE(), @clientNew) END --///Триггер, контролирующий добавление записей в таблицу "Клиент" с фиксацией пользователя, внесшего запись, даты внесения и идентификатора нового клиента.
INSERT INTO client(surname, name, mid_name,mob_telefone) values ('Денисенко', 'Григорий', 'Алексеевич', '79981521310');
select * from AuditClient;
Создание триггера типа UPDATE. Пример.
GO CREATE TABLE AuditStatusOrder (
UserName CHAR(16) NULL, Date DATETIME NULL, statusOld INT NULL, statusNew INT NULL );
GO CREATE TRIGGER trigger_ModifyStatusOrder ON zakaz AFTER UPDATE AS IF UPDATE(id_status) BEGIN DECLARE @statusOld INT DECLARE @statusNew INT
SELECT @statusOld = (SELECT id_status FROM deleted) SELECT @statusNew = (SELECT id_status FROM inserted)
INSERT INTO AuditStatusOrder VALUES (USER_NAME(), GETDATE(), @statusOld, @statusNew) END
update zakaz set id_status = 3, date_issues='2020-12-13', price_repair = 1750.0 where id_order = 8; select * from AuditStatusOrder;
--///Триггер, контролирующий изменение статуса заказа в таблице "Заказы"
Фрагментация. Фрагментация – это разбиение базы данных на фрагменты и размещение их по разным узлам сети. Фрагментация является основным способом организации реляционная база данных. Она позволяет хранить данные на том узле, где они наиболее часто используются. Основные проблемы, которые при этом возникают – это прозрачность написания запросов к данным и, возможно, поддержка распределенных ограничений целостности. Фрагментации могут подвергаться не только база данных в целом, но и отдельные отношения БД.
Схема фрагментации отношения должна удовлетворять трем условиям:
1) Полнота. Если экземпляр отношения разбивается на фрагменты, то каждый элемент данных, присутствующий в данном отношении, должен присутствовать хотя бы в одном из созданных фрагментов. Данное правило гарантирует, что какие-либо данные не будут утрачены в результате выполнения фрагментации. 2) Восстановилось. Должна существовать операция реляционной алгебры, позволяющая восстановить отношение из его фрагментов. Это правило гарантирует сохранение функциональной зависимости. 3) Непересекаемость. Если элемент данных присутствует во фрагменте отношения, то он не должен одновременно присутствовать в каком-либо ином фрагменте. Исключением из этого правила является операция вертикальной фрагментации, поскольку в этом случае в каждом фрагменте должны присутствовать атрибуты первичного ключа, необходимые для восстановления исходного отношения. Данное правило гарантирует минимальную избыточность данных во фрагментах. В случае горизонтальной фрагментации элементом данных является кортеж, а в случае вертикальной фрагментации – атрибут. Существуют два основных типа фрагментации отношений: горизонтальная и вертикальная., а. Горизонтальная фрагментация: горизонтальный фрагмент является результатом селекции. Данный тип фрагмента определяется с помощью операции выборки реляционной алгебры (запросы) Вертикальная фрагментация: Вертикальный – результатом проекции. (затрагиваются первичные ключи). Суть: в различные фрагменты объединяются атрибуты, используемые отдельными приложениями. Данный тип фрагмента определяется с помощью операции выборки реляционной алгебры (запросы) Еще есть Смешанная фрагментация: Смешанный фрагмент образуется либо посредством дополнительной вертикальной фрагментации созданных ранее горизонтальных фрагментов, либо за счет вторичной горизонтальной фрагментации предварительно определенных вертикальных фрагментов. Смешанная фрагментация определяется с помощью операций выборки и проекции реляционной алгебры.
Причины, вызывающие необходимость фрагментации отношений. 1) Условия использования. Чаще всего приложения работают с некоторыми представлениями, а не с полными базовыми отношениями. Следовательно, с точки зрения распределения данных, целесообразнее организовать работу приложений с определенными фрагментами отношений, выступающими как распределяемые элементы. 2) Эффективность. Данные хранятся в тех местах, в которых они чаще всего используются. Кроме того, исключается хранение данных, которые не используются локальными приложениями. 3) Параллельность. Поскольку фрагменты являются распределяемыми элементами, транзакции могут быть разделены на несколько подзапросов, обращающихся к различным фрагментам. Такой подход дает возможность повысить уровень параллельности обработки в системе, т.е. позволяет транзакциям, которые допускают это, безопасно выполняться в параллельном режиме. 4) Защищенность. Данные, не используемые локальными приложениями, не хранятся на сайтах, а значит, неавторизированные пользователи не смогут получить к ним доступ. Механизму фрагментации свойственны два основных недостатка: 1)Производительность. Производительность приложений, требующих доступа к данным из нескольких фрагментов, расположенных на различных сайтах, может оказаться недостаточной. 2)Целостность данных. Поддержка целостности данных может существенно осложняться, поскольку функционально зависимые данные могут оказаться фрагментированными и размещаться на различных сайтах.
Репликация.
Репликация – это поддержание двух и более идентичных копий (реплик) данных на разных узлах реляционной базы данных. Реплика может включать всю базу данных (полная репликация), одно или несколько взаимосвязанных отношений или фрагмент отношения. К основным достоинствам механизма репликации можно отнести повышение доступности и надежности данных и повышение локализации ссылок на реплицируемые данные. Основным недостатком репликации является сложность поддержания идентичности реплик: если в одну копию данных вносятся изменения, то эти изменения также должны быть внесены в другие копии. Это называется распространение изменений и реализуется службой тиражирования. Служба тиражирования должна выполнять следующие функции: 1. Обеспечение масштабируемости, т.е. эффективная обработки больших и малых объемов данных. 2. Преобразование типов и моделей данных. 3. Репликация объектов БД, например, индексов, триггеров и т.п. 4. Инициализация вновь создаваемой реплики. 5. Обеспечение возможности "подписаться" на существующие реплики, чтобы получать их в определенной периодичностью. Существуют различные подходы к организации репликации: Репликация с основной копией. Существуют следующие варианты: 1 Классический подход заключается в наличии одной основной копии, в которую можно вносить изменения; остальные копии создаются с определением read only. 2 Асимметричная репликация: основная копия фрагментирована и распределена по разным узлам РБД, и другие узлы могут являться подписчиками отдельных фрагментов (read only). 3 Рабочий поток. При использовании этого подхода право обновления не принадлежит постоянно одной копии, а переходит от одной копии в другой в соответствии с потоком операций. В каждый момент времени обновляться может только одна копия.
Два основных его механизма распространения изменений: 1 синхронный: изменения во все копии вносятся в рамках одной транзакции; Его плюсы в том, что идет полная согласованность копий и отсутствие конфликтов обновления. Недостатки трудоемкость, большая длительность модификации данных и низкая надежность работы системы. 2 асинхронный: подразумевает отложенный характер внесения изменений в удаленные копии.
Могут возникать конфликты обновлений такие как: 1 Добавление двух записей с одинаковыми первичными или уникальными ключами. Для предотвращения таких ситуаций обычно каждому узлу реляционной базы данных выделяется свой диапазон значений ключевых (уникальных) полей. 2 Конфликты удаления: одна транзакция пытается удалить запись, которая в другой копии уже удалена другой транзакцией. Если такая ситуация считается конфликтом, то она разрешаются вручную. 3 Конфликты обновления: две транзакции в разных копиях обновили одну и ту же запись, возможно, по-разному, и пытаются распространить свои изменения. Для идентификации конфликтов обновления необходимо передавать с транзакцией дополнительную информацию: старое и новое содержимое записи. Если старая запись не может быть обнаружена, налицо конфликт обновления. Для настройки реакции на конфликты некоторые СУБД позволяют выделить в каждой таблице столбец (группу столбцов), и описать для них способ разрешения конфликтов (т.н. группа обновления). Существуют различные варианты реализации распространения изменений. Один из них заключается в использовании триггеров. Другой способ реализации механизма распространения изменений – поддержка журналов изменений для реплицируемых данных. Рассылка этих изменений входит в задачу сервера СУБД или сервера тиражирования (входящего в состав СУБД). Основные принципы, которых необходимо придерживаться при этом: 1 Для сохранения согласованности данных должен соблюдаться порядок внесения изменений. 2 Информация об изменениях должна сохраняться в журнале до тех пор, пока не будут обновлены все копии этих данных. Распределенные запросы. Распределенным называется запрос, который обращается к двум и более узлам реляционной базы данных, но не обновляет на них данные. Запрашивающий узел должен определить, что в запросе идет обращение к данным на другом узле, выделить подзапрос к удаленному узлу и перенаправить его этому узлу. Сложная проблема выполнения таких запросов является оптимизация,т.е. поиск оптимального плана выполнения запроса. Информация распределена по узлам. Если эту информацию соберет центральный узел, построит оптимальный план и отправит его на выполнение, то теряется свойство локальной автономности. Поэтому обычно распределенный запрос выполняется так: запрашивающий узел собирает все данные, полученные в результате выполнения подзапросов, у себя, и выполняет их соединение (или объединение), что может занять очень много времени.
Распределенные транзакции. Распределенные транзакции обращаются к двум и более узлам и обновляют на них данные. Основная проблема распределенных транзакций – соблюдение логической целостности данных. Транзакция на всех узлах должна завершиться одинаково: или фиксацией, или откатом. Выполнение распределенных транзакций осуществляется с помощью специального алгоритма, который называется двухфазная фиксация.
12. ACID-свойства транзакций.
Характеристики транзакций описываются в терминах ACID (Atomicity, Consistency, Isolation, Durability – неделимость, согласованность, изолированность, устойчивость). · Транзакция неделима в том смысле, что представляет собой единое целое. Все ее компоненты либо имеют место, либо нет. Не бывает частичной транзакции. Если может быть выполнена лишь часть транзакции, она отклоняется. · Транзакция является согласованной, потому что не нарушает бизнес-логику и отношения между элементами данных, что обеспечивает целостность данных. Это свойство очень важно при разработке клиент-серверных систем, поскольку в хранилище данных поступает большое количество транзакций от разных подсистем и объектов. Если хотя бы одна из них нарушит целостность данных, то все остальные могут выдать неверные результаты. · Транзакция всегда изолирована, поскольку ее результаты самодостаточны. Они не зависят от предыдущих или последующих транзакций – это свойство называется сериализуемостью и означает, что транзакции в последовательности независимы (каждая транзакций отделена от эффекта других транзакций). · Транзакция устойчива. После своего завершения она сохраняется в системе и выполняется фиксация транзакции, означающая, что ее действие постоянно даже при сбое системы. При этом подразумевается некая форма хранения информации в постоянной памяти как часть транзакции. Ядро базы данных должно быть спроектировано так, чтобы даже в случае выхода из строя устройства данных, БД можно было восстановить до состояния последней подтвержденной перед сбоем транзакции. +Указанные выше правила выполняет СУБД-сервер. Согласованность состояния баз данных при параллельном выполнении нескольких транзакций обеспечивается механизмами блокировок и временных отметок: механизм блокировки создает такие условия, что график параллельного выполнения транзакций будет эквивалентен некоторому варианту последовательного выполнения этих транзакций (в режиме ожидания последующей транзакцией завершения предыдущей) механизм обработки временных меток гарантирует, что график параллельного выполнения транзакций будет эквивалентен конкретному варианту последовательного выполнения этих транзакций в соответствии с их временными отметками (альтернатива - приоритеты) Аномалии транзакций При параллельном выполнении транзакций возникают различные проблемы, связанные с логикой работы с операциями. Рассмотрим наиболее распространенные из них на примерах из SQL сервера: 1. Потерянное обновление. При обновлении поля двумя транзакциями одно из изменений теряется.
2. Грязное чтение. Чтение данных, полученных в результате действия транзакции, которая после этого откатится.
3. Неповторяющееся чтение. Возникает, когда в течение одной транзакции при повторном чтении данные оказываются перезаписанными.
4. Фантомное чтение. Отличие от предыдущей аномалии в том, что при повторном чтении одна и та же выборка дает разные множества строк. SQL Server реализует уровни изоляции с помощью блокировок. Так как блокировки влияют на производительность, то следует искать компромисс между установленным уровнем изоляции и производительностью. Принятый по умолчанию уровень изоляции Read Commited является своеобразным балансом, подходящим большинству проектов. Уровень 1. Read Uncommited - наименее строгий уровень изоляции не предотвращает никаких ошибок транзакций. Этот режим лучше всего подходит для отчетов и приложений чтения данных. Уровень 2. Read Сommited - позволяет избежать самой опасной ошибкитранзакций, но не нагружает систему излишними блокировками. Уровень 3. Repeatable Read - предотвращая грязное чтение и неповторяющееся чтение, этот уровень обеспечивает повышенную изоляцию транзакций без чрезмерных блокировок, характерных для уровня изоляции 4. Уровень 4. Serializable - наиболее строгий уровень изоляции, позволяющий избежать всех ошибок транзакций. Он больше всего подходит базам данных, для которых абсолютная целостность транзакций важнее производительности. Обычно этот уровень изоляции используется в банковских, бухгалтерских базах, а также в очень загруженных приложениях продаж. Выйдя за пределы стандарта ANSI, разработчики SQL Server добавили еще один уровень изоляции – Snapshot, который создает еще одну копию данных в своем собственном физическом пространстве. Эта копия абсолютно изолирована от других транзакций. Уровень изоляции Snapshot реализует блокировку на уровне базы данных. Если данные хранятся в одной централизованной БД, то транзакция к ней рассматривается как локальная. В Реляционной БД транзакция, выполнение которой заключается в обновлении данных на нескольких узлах сети, называется глобальной или распределенной транзакцией. Распределенная транзакция включает в себя несколько локальных транзакций, каждая из которой завершается двумя путями – фиксируется или откатывается. Распределенная транзакция фиксируется только в том случае, когда зафиксированы все локальные транзакции, составляющие ее, то есть когда каждая локальная транзакция будет подтверждена локальным процессором данных DP.
Механизм блокировок. Уровни блокирования. Уровни блокировки: Могут устанавливаться на трех уровнях: 1) Уровень строк - уровень по умолчанию. 2) Уровень страницы - используется для более эффективного использования ресурсов и в случае если в данной странице много строк с этой блокировкой. 3) Уровень таблицы - используется при операциях над таблицей и в случае эскалации блокировок.
Управление блокировками. Пользователю чаще всего не нужно предпринимать никаких действий по управлению блокировками. Всю работу по установке, снятию и разрешению конфликтов выполняет специальный компонент сервера, называемый менеджером блокировок. MS SQL Server поддерживает различные уровни блокирования объектов (или детализацию блокировок), начиная с отдельной строки таблицы и заканчивая базой данных в целом. Менеджер блокировок автоматически оценивает, какое количество данных необходимо блокировать, и устанавливает соответствующий тип блокировки. Это позволяет поддерживать равновесие между производительностью работы системы блокирования и возможностью пользователей получать доступ к данным. Блокирование на уровне строки позволяет наиболее точно управлять таким доступом, поскольку блокируются только действительно изменяемые строки. При блокировке на уровне таблицы производительность системы блокирования резко увеличивается, так как необходимо установить лишь одну блокировку и снять ее только после завершения транзакции. Уровни изоляции. Уровень изоляции задает степень защищенности выбираемых транзакцией данных от возможности изменения другими транзакциями. Уровень изоляции READ UNCOMMITTED Уровень изоляции READ UNCOMMITTED предоставляет самую простую форму изоляции между транзакциями, поскольку он вообще не изолирует операции чтения других транзакций. Когда транзакция выбирает строку при этом уровне изоляции, она не задает никаких блокировок и не признает никаких существующих блокировок. Считываемые такой транзакцией данные могут быть несогласованными. В таком случае транзакция читает данные, которые были обновлены какой-либо другой активной транзакцией. А если для этой другой транзакции позже выполняется откат, то значит, что первая транзакция прочитала данные, которые никогда по-настоящему не существовали. Из четырех проблем одновременного конкурентного доступа к данным, описанных в предшествующем разделе, уровень изоляции READ UNCOMMITTED допускает три: грязное чтение, неповторяемое чтение и фантомы. Применение уровня изоляции READ UNCOMMITTED обычно крайне нежелательно и его следует применять только в тех случаях, когда точность данных не представляет важности или когда данные редко подвергаются изменениям. Уровень изоляции READ COMMITTED Уровень READ COMMITTED имеет две формы. Первая форма применяется в пессимистической модели одновременного конкурентного доступа, а вторая - в оптимистической. Транзакция, которая читает строку и использует уровень изоляции READ COMMITTED, выполнят проверку только на наличие монопольной блокировки для данной строки. Если такая блокировка отсутствует, транзакция извлекает строку. образом предотвращается чтение транзакцией данных, которые не были подтверждены и которые могут быть позже отменены. После того, как данные были прочитаны, их можно изменять другими транзакциями. Уровень изоляции READ COMMITTED для компонента Database Engine является уровнем изоляции по умолчанию. Уровень изоляции REPEATABLE READ В отличие от уровня изоляции READ COMMITTED, уровень REPEATABLE READ устанавливает разделяемые блокировки на все считываемые данные и удерживает эти блокировки до тех пор, пока транзакция не будет подтверждена или отменена. Поэтому в этом случае многократное выполнение запроса внутри транзакции всегда будет возвращать один и тот же результат. Недостатком этого уровня изоляции является дальнейшее ухудшение одновременного конкурентного доступа, поскольку период времени, в течение которого другие транзакции не могут обновлять те же самые данные, значительно дольше, чем в случае уровня READ COMMITTED. Этот уровень изоляции не препятствует другим инструкциям вставлять новые строки, которые включаются в последующие операции чтения, вследствие чего могут появляться фантомы. Уровень изоляции SERIALIZABLE Уровень изоляции SERIALIZABLE является самым строгим, потому что он не допускает возникновения всех четырех проблем параллельного одновременного конкурентного доступа, перечисленных ранее. Этот уровень устанавливает блокировку на всю область данных, считываемых соответствующей транзакцией. Поэтому этот уровень изоляции также предотвращает вставку новых строк другой транзакцией до тех пор, пока первая транзакция не будет подтверждена или отменена. Уровень изоляции SERIALIZABLE реализуется, используя метод блокировки диапазона ключа. Суть этого метода заключается в блокировке отдельных строк включительно со всем диапазоном строк между ними. Блокировка диапазона ключа блокирует элементы индексов, а не определенные страницы или всю таблицу. В этом случае любые операции модификации другой транзакцией невозможны, вследствие невозможности выполнения требуемых изменений элементов индекса, чем выше уровень изоляции, тем меньше степень одновременного конкурентного доступа. Таким образом, уровень изоляции READ UNCOMMITTED меньше всего уменьшает одновременный конкурентный доступ. С другой стороны, он также предоставляет наименьшую изоляцию параллельных конкурентных транзакций. Уровень изоляции SERIALIZABLE наиболее сильно уменьшает степень одновременного конкурентного доступа, но гарантирует полную изоляцию параллельных конкурентных транзакций.
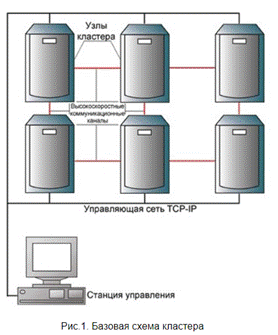
Виды кластерных систем. Кластер – это группа вычислительных машин, которые связаны между собою и функционируют как один узел обработки информации и для конечного пользователя выглядят как один компьютер.
По своей функциональной классификации, кластеры могут быть поделены на три основные группы: 4) Высокопроизводительные (High Performance) кластеры: Такие системы предназначены в первую очередь для выполнения сложных расчетов. Они применяются для таких операций, как физическое и химическое моделирование, промышленные математические, геологические и другие задачи, рендеринг изображений, видео и звука и многих других. Для максимальной эффективности используемое программное обеспечение должно поддерживать многопоточную работу. Основная трудность при создании высокопроизводительных кластерных систем сос
|
|||||||||
|
|
Последнее изменение этой страницы: 2021-07-18; просмотров: 565; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.14.83.223 (0.156 с.) |