Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Кафедра «Математика, информатика и общегуманитарные науки»
Контрольная работа На тему: ИТ бизнес-анализа
Студент группы: СМЛС17-1Б-БИ02 Семенков И.Г. Преподаватель: Морозов А.А.
Смоленск 2021 Содержание
Введение Бизнес-анализ - это набор задач, знаний и методов, необходимых для определения бизнес-потребностей и определения решений бизнес-задач предприятия. Хотя общее определение схоже, методы и процедуры могут различаться в разных отраслях. В индустрии информационных технологий решения часто включают компонент разработки систем, но могут также состоять из улучшения процессов или организационных изменений. Бизнес-анализ также может быть выполнен, чтобы понять текущее состояние организации или служить основой для определения потребностей бизнеса. Однако в большинстве случаев бизнес-анализ выполняется для определения и проверки решений, соответствующих бизнес-потребностям, целям или задачам. Организации используют бизнес-анализ по следующим причинам: · Понять структуру и динамику организации, в которой должна быть развернута система. · Понять текущие проблемы в целевой организации и выявить возможности улучшения. · Чтобы клиент, конечный пользователь и разработчики имели общее представление о целевой организации. На начальном этапе проекта, когда требования интерпретируются командами разработчиков и разработчиков, роль бизнес-аналитика заключается в рассмотрении документов решений, в тесном сотрудничестве с разработчиками решений (ИТ-командой) и менеджерами проектов для обеспечения того, чтобы требования понятны.
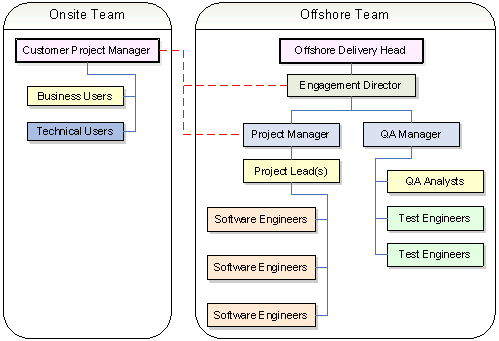
В типичной крупной ИТ-организации, особенно в среде разработки, вы можете найти как локальные, так и оффшорные группы доставки, выполняющие вышеупомянутые роли. Вы можете найти «бизнес-аналитика», который выступает в роли ключевого человека, который должен связать обе команды. Таблица 1 – пример проекта бизнес-аналитика
Иногда он взаимодействовал с бизнес-пользователями, а иногда и с техническими пользователями и, наконец, со всеми заинтересованными сторонами в проектах, чтобы получить одобрение и окончательное одобрение, прежде чем приступить к документации. Следовательно, роль БA очень важна для эффективного и успешного запуска любого проекта. Роль бизнес-аналитика начинается с определения и определения области деятельности организации, затем выявляет требования, анализирует и документирует требования, сообщает эти требования соответствующим заинтересованным сторонам, определяет правильное решение и затем проверяет решение, чтобы найти требования соответствуют ожидаемым стандартам. Жизненный цикл разработки программного обеспечения (SDLC) - это процесс, которому следует программный проект в рамках организации программного обеспечения. Он состоит из подробного плана, описывающего, как разрабатывать, поддерживать, заменять и изменять или улучшать конкретное программное обеспечение. Он определяет методологию повышения качества программного обеспечения и общего процесса разработки. Так же учитывает все сопутствующие аспекты тестирования программного обеспечения, анализа и постпроцессного обслуживания.
Рисунок 1 - этапы SDLC
· Этап планирования. Каждое мероприятие должно начинаться с плана. Отказ от планирования означает провал. Степень планирования отличается от одной модели к другой, но очень важно иметь четкое представление о том, что мы собираемся построить, создав спецификации системы.
· Определение этапа. На этом этапе мы анализируем и определяем структуру системы. Мы определяем архитектуру, компоненты и то, как эти компоненты сочетаются друг с другом для создания работающей системы. · Этап проектирования. При проектировании системы функции и операции проектирования подробно описаны, включая макеты экранов, бизнес-правила, диаграммы процессов и другую документацию. Выходные данные этого этапа будут описывать новую систему как набор модулей или подсистем. · Стадия строительства. Это фаза разработки. Мы начинаем генерацию кода на основе дизайна системы, используя компиляторы, интерпретаторы, отладчики, чтобы оживить систему. · Реализация. Реализация является частью этапа строительства. На этом этапе мы начинаем генерацию кода на основе проектирования системы с использованием компиляторов, интерпретаторов, отладчиков для оживления системы. · Стадия тестирования. Как разные части системы завершены; они проходят серию испытаний. оно проверяется на соответствие требованиям, чтобы убедиться, что продукт действительно отвечает потребностям, указанным на этапе требования. · Планы тестирования и тестовые наборы используются для выявления ошибок и обеспечения работы системы в соответствии со спецификациями. · На этом этапе выполняются различные типы тестирования, такие как модульное тестирование, ручное тестирование, приемочное тестирование и тестирование системы. · Развертывание. После завершения фазы тестирования система освобождается и входит в производственную среду. Как только продукт протестирован и готов к развертыванию, он официально выпускается на соответствующем рынке. Иногда внедрение продукта происходит поэтапно в соответствии с бизнес-стратегией организации. Продукт может быть сначала выпущен в ограниченном сегменте и протестирован в реальной бизнес-среде (UAT-пользовательское приемочное тестирование). Затем, основываясь на отзывах, продукт может быть выпущен как есть или с предлагаемыми улучшениями в сегменте таргетинга.
1.0 Понятие Business Intelligence. Методы и модели анализа данных. Задачи и содержание оперативного анализа данных. Business Intelligence, или BI-системы — это набор инструментов и технологий для сбора, анализа и обработки данных. Например, в компании для приёма заявок используют несколько каналов и нужно собрать единую статистику продаж. Или рекламные кампании охватывают несколько площадок и необходимо сравнить их эффективность. Все эти процессы можно настроить через BI-систему. Необработанную информацию из разных источников посредством BI преобразуют в удобную и понятную аналитику. BI-системы (Microsoft Power BI, Tableau, Qlik) можно применять в любой отрасли или сфере деятельности — как на уровне компании в целом, так и для подразделений или отдельных продуктов. Для обычного пользователя принцип действия BI-системы выглядит просто: к системе подключают источники данных, далее информация направляются в единое хранилище и обрабатываются, а затем демонстрируются в виде готовых отчётов. Источниками данных выступают различные системы — облачные (Oracle Cloud, Google BigQuery, Microsoft Azure и другие веб-подключения), файловые (Excel, XML, PDF и иные табличные файлы), реляционные (SQL Server, MySQL, Oracle).
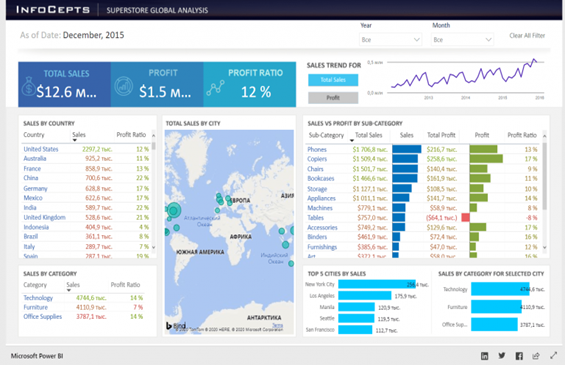
Рисунок -2 Пример отчета о глобальных продажах магазина в Power BI
Чтобы использовать BI-систему пользователю не нужно обладать специальными IT-познаниями. С помощью понятного интерфейса можно запросить нужный отчёт и получить доступ к аналитике. Система сформирует удобный дашборд — информационную панель, на которой визуально представленные данные сгруппированы по смыслу. Все данные на дашборде — интерактивные. Графики можно увеличивать и перестраивать. Можно просматривать источники информации и детально изучать показатели аналитики. Для отображения доступны разные форматы — отчёты, таблицы, графики, диаграммы. За простым использованием системы скрываются сложные процессы обработки данных и формирования расширенной аналитики. В состав BI-решения входят: · Инструменты интеграции и очистки данных (ETL). ETL извлекают информацию из внешних систем-источников, трансформируют её, очищают и загружают в единое хранилище. · Аналитическое хранилище данных. Это информационная база, которая умеет структурировать и анализировать данные. · Средства Data Mining. Эти инструменты обрабатывают данные и анализируются по различным срезам. Система выявляет зависимости и тренды. При этом могут использоваться самые разные методы обработки информации — от статистики и прогнозирования до семантического анализа. · Инструменты визуализации данных. Это отчёты, с которыми работают пользователи. В зависимости от задач отчёты могут строиться по утверждённому формату или быть аналитическими. При построении аналитических отчётов пользователи самостоятельно устанавливают перечень отображаемых показателей, сортируют данные и выстраивают фильтры. BI-системы поддерживают множество бизнес-решений — от операционных до стратегических. С помощью технологий анализируют огромные объёмы информации. Но внимание пользователя акцентируется только на ключевых факторах аналитики, которые позволяют смоделировать варианты последующих действий и бизнес-решений.
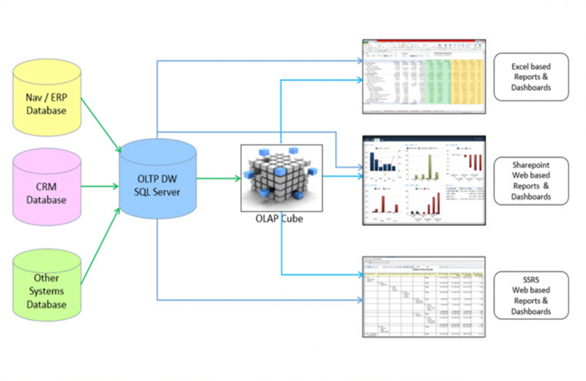
Рисунок – 3 Принцип работы BI-системы на примере Power BI
Важно, что любая компания может адаптировать BI-систему под свои потребности. Например, выбрать источники данных, задать принцип обработки информации, определить формат отчётности. BI-системы особенно полезны, если объединяют сведения с рынка и информацию из финансовых и производственных источников компании. Совокупность внешних и внутренних данных даёт полное представление ситуации в бизнесе. Такую картину невозможно получить при анализе одного источника и ограниченной аналитике.
1.1 Методы и модели анализа данных data mining Data Mining – это сочетание широкого математического инструментария (от классического статистического анализа до новых кибернетических методов) и последних достижений в сфере информационных технологий. В технологии Data Mining гармонично объединились строго формализованные методы и методы неформального анализа, т.е. количественный и качественный анализ данных. Data Mining (добыча данных, интеллектуальный анализ данных, глубинный анализ данных) — собирательное название, используемое для обозначения совокупности методов обнаружения в данных ранее неизвестных, нетривиальных, практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности. Термин введён Григорием Пятецким-Шапиро в 1989 году. Основу методов Data Mining составляют всевозможные методы классификации, моделирования и прогнозирования. К методам Data Mining нередко относят статистические методы (дескриптивный анализ, корреляционный и регрессионный анализ, факторный анализ, дисперсионный анализ, компонентный анализ, дискриминантный анализ, анализ временных рядов). Такие методы, однако, предполагают некоторые априорные представления об анализируемых данных, что несколько расходится с целями Data Mining (обнаружение ранее неизвестных нетривиальных и практически полезных знаний). Одно из важнейших назначений методов Data Mining состоит в наглядном представлении результатов вычислений, что позволяет использовать инструментарий Data Mining людьми, не имеющих специальной математической подготовки. В то же время, применение статистических методов анализа данных требует хорошего владения теорией вероятностей и математической статистикой. Знания, добываемые методами Data mining, принято представлять в виде моделей.
Рисунок – 3 Модели представления знаний Data Mining
Все методы Data Mining подразделяются на две большие группы по принципу работы с исходными обучающими данными. В этой классификации верхний уровень определяется на основании того, сохраняются ли данные после Data Mining либо они дистиллируются для последующего использования. 1. Непосредственное использование данных, или сохранение данных. В этом случае исходные данные хранятся в явном детализированном виде и непосредственно используются на стадиях прогностического моделирования и/или анализа исключений. Проблема этой группы методов - при их использовании могут возникнуть сложности анализа сверхбольших баз данных. Методы этой группы: кластерный анализ, метод ближайшего соседа, метод k-ближайшего соседа, рассуждение по аналогии. 2. Выявление и использование формализованных закономерностей, или дистилляция шаблонов. При технологии дистилляции шаблонов один образец (шаблон) информации извлекается из исходных данных и преобразуется в некие формальные конструкции, вид которых зависит от используемого метода Data Mining. Этот процесс выполняется на стадии свободного поиска, у первой же группы методов данная стадия в принципе отсутствует. На стадиях прогностического моделирования и анализа исключений используются результаты стадии свободного поиска, они значительно компактнее самих баз данных. Напомним, что конструкции этих моделей могут быть трактуемыми аналитиком либо нетрактуемыми ("черными ящиками").
Методы этой группы: логические методы; методы визуализации; методы кросс-табуляции; методы, основанные на уравнениях. Логические методы, или методы логической индукции, включают: нечеткие запросы и анализы; символьные правила; деревья решений; генетические алгоритмы. Методы этой группы являются, пожалуй, наиболее интерпретируемыми - они оформляют найденные закономерности, в большинстве случаев, в достаточно прозрачном виде с точки зрения пользователя. Полученные правила могут включать непрерывные и дискретные переменные. Следует заметить, что деревья решений могут быть легко преобразованы в наборы символьных правил путем генерации одного правила по пути от корня дерева до его терминальной вершины. Деревья решений и правила фактически являются разными способами решения одной задачи и отличаются лишь по своим возможностям. Кроме того, реализация правил осуществляется более медленными алгоритмами, чем индукция деревьев решений. Методы кросс-табуляции: агенты, баесовские (доверительные) сети, кросс-табличная визуализация. Последний метод не совсем отвечает одному из свойств Data Mining - самостоятельному поиску закономерностей аналитической системой. Однако, предоставление информации в виде кросс-таблиц обеспечивает реализацию основной задачи Data Mining - поиск шаблонов, поэтому этот метод можно также считать одним из методов Data Mining. Методы на основе уравнений. Методы этой группы выражают выявленные закономерности в виде математических выражений - уравнений. Следовательно, они могут работать лишь с численными переменными, и переменные других типов должны быть закодированы соответствующим образом. Это несколько ограничивает применение методов данной группы, тем не менее они широко используются при решении различных задач, особенно задач прогнозирования. Основные методы данной группы: статистические методы и нейронные сети Статистические методы наиболее часто применяются для решения задач прогнозирования. Существует множество методов статистического анализа данных, среди них, например, корреляционно-регрессионный анализ, корреляция рядов динамики, выявление тенденций динамических рядов, гармонический анализ. Другая классификация разделяет все многообразие методов Data Mining на две группы: статистические и кибернетические методы. Эта схема разделения основана на различных подходах к обучению математических моделей. Следует отметить, что существует два подхода отнесения статистических методов к Data Mining. Первый из них противопоставляет статистические методы и Data Mining, его сторонники считают классические статистические методы отдельным направлением анализа данных. Согласно второму подходу, статистические методы анализа являются частью математического инструментария Data Mining. Большинство авторитетных источников придерживается второго подхода. В этой классификации различают две группы методов: · Статистические методы, основанные на использовании усредненного накопленного опыта, который отражен в ретроспективных данных; · Кибернетические методы, включающие множество разнородных математических подходов. Недостаток такой классификации: и статистические, и кибернетические алгоритмы тем или иным образом опираются на сопоставление статистического опыта с результатами мониторинга текущей ситуации. Преимуществом такой классификации является ее удобство для интерпретации - она используется при описании математических средств современного подхода к извлечению знаний из массивов исходных наблюдений (оперативных и ретроспективных), т.е. в задачах Data Mining. Рассмотрим подробнее представленные выше группы. Статистические методы Data mining. В эти методы представляют собой четыре взаимосвязанных раздела: · предварительный анализ природы статистических данных (проверка гипотез стационарности, нормальности, независимости, однородности, оценка вида функции распределения, ее параметров и т.п.); · выявление связей и закономерностей (линейный и нелинейный регрессионный анализ, корреляционный анализ и др.); · многомерный статистический анализ (линейный и нелинейный дискриминантный анализ, кластерный анализ, компонентный анализ, факторный анализ и др.); · динамические модели и прогноз на основе временных рядов. Арсенал статистических методов Data Mining классифицирован на четыре группы методов: · Дескриптивный анализ и описание исходных данных. · Анализ связей (корреляционный и регрессионный анализ, факторный анализ, дисперсионный анализ). · Многомерный статистический анализ (компонентный анализ, дискриминантный анализ, многомерный регрессионный анализ, канонические корреляции и др.). · Анализ временных рядов (динамические модели и прогнозирование). · Кибернетические методы Data Mining Второе направление Data Mining - это множество подходов, объединенных идеей компьютерной математики и использования теории искусственного интеллекта. К этой группе относятся такие методы: · искусственные нейронные сети (распознавание, кластеризация, прогноз); · эволюционное программирование (в т.ч. алгоритмы метода группового учета аргументов); · генетические алгоритмы (оптимизация); · ассоциативная память (поиск аналогов, прототипов); · нечеткая логика; · деревья решений; · системы обработки экспертных знаний. Методы Data Mining также можно классифицировать по задачам Data Mining. В соответствии с такой классификацией выделяем две группы. Первая из них - это подразделение методов Data Mining на решающие задачи сегментации (т.е. задачи классификации и кластеризации) и задачи прогнозирования. В соответствии со второй классификацией по задачам методы Data Mining могут быть направлены на получение описательных и прогнозирующих результатов. Описательные методы служат для нахождения шаблонов или образцов, описывающих данные, которые поддаются интерпретации с точки зрения аналитика. К методам, направленным на получение описательных результатов, относятся итеративные методы кластерного анализа, в том числе: алгоритм k-средних, k-медианы, иерархические методы кластерного анализа, самоорганизующиеся карты Кохонена, методы кросс-табличной визуализации, различные методы визуализации и другие. Прогнозирующие методы используют значения одних переменных для предсказания/прогнозирования неизвестных (пропущенных) или будущих значений других (целевых) переменных. К методам, направленным на получение прогнозирующих результатов, относятся такие методы: нейронные сети, деревья решений, линейная регрессия, метод ближайшего соседа, метод опорных векторов и др.
1.2 Методы и модели анализа данных OLAP
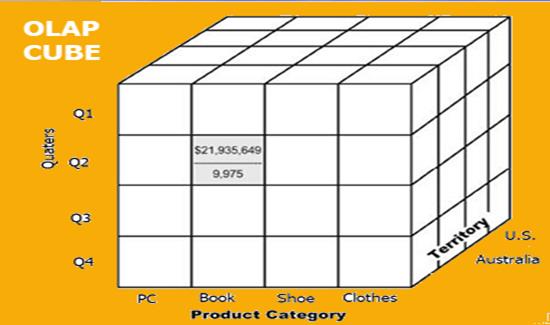
Оперативная аналитическая обработка (OLAP) — это категория программного обеспечения, которая позволяет пользователям одновременно анализировать информацию из нескольких систем баз данных. Это технология, которая позволяет аналитикам извлекать и просматривать бизнес-данные с разных точек зрения. Аналитики часто должны группировать, объединять и объединять данные. Эти операции в реляционных базах данных являются ресурсоемкими. Данные OLAP могут быть предварительно рассчитаны и агрегированы, что ускоряет анализ. Базы данных OLAP делятся на один или несколько кубов. Кубы разработаны таким образом, что создание и просмотр отчетов становится проще. OLAP означает онлайн-аналитическую обработку. В основе концепции OLAP лежит куб OLAP. OLAP-куб — это структура данных, оптимизированная для очень быстрого анализа данных (рисунок 4).
Рисунок - 4 OLAP-куб Куб OLAP состоит из числовых фактов, называемых мерами, которые классифицируются по измерениям. OLAP Cube также называют гиперкубом. Обычно операции с данными и анализ выполняются с использованием простой электронной таблицы, где значения данных располагаются в формате строк и столбцов. Это идеально подходит для двумерных данных. Однако OLAP содержит многомерные данные, причем данные обычно получают из другого и несвязанного источника. Использование электронной таблицы не является оптимальным вариантом. Куб может хранить и анализировать многомерные данные в логической и упорядоченной форме. Хранилище данных будет извлекать информацию из нескольких источников данных и форматов, таких как текстовые файлы, таблицы Excel, мультимедийные файлы и т. д. Извлеченные данные очищаются и преобразуются. Данные загружаются на сервер OLAP (или куб OLAP), где информация предварительно рассчитывается заранее для дальнейшего анализа.
Четыре типа аналитических операций в OLAP: 1. Свернуть 2. Срез 3. Кость
1. Свернуть: Свертывание также известно как «консолидация» или «агрегация». Операция свертки может быть выполнена двумя способами Уменьшение размеров Восхождение на концепцию иерархии. Иерархия понятий — это система группировки вещей в зависимости от их порядка или уровня. 2. Срез: При детализации данные разбиты на более мелкие части. Это противоположность процесса накопления. Это можно сделать через: Двигаясь вниз по иерархии понятий Увеличение размера 3. Кость: Эта операция похожа на срез. Разница в кости заключается в том, что вы выбираете 2 или более измерений, которые приводят к созданию вложенного куба. 4. Поворот: Вы вращаете оси данных, чтобы обеспечить альтернативное представление данных.
|
||||||||||||||
|
|
Последнее изменение этой страницы: 2021-07-19; просмотров: 106; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.12.153.110 (0.084 с.) |