Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Поиск в массивах: линейный поиск и двоичный поискСодержание книги Поиск на нашем сайте
Часто программисту приходится работать с большими объемами данных, хранящимися в виде массивов. Может оказаться необходимым определить, содержит ли массив значение, которое соответствует определенному ключевому значению. Процесс нахождения какого-то элемента массива называют поиском. В этом разделе мы обсудим два способа поиска — простой линейный поиск и более эффективный двоичный поиск — дихотомию.
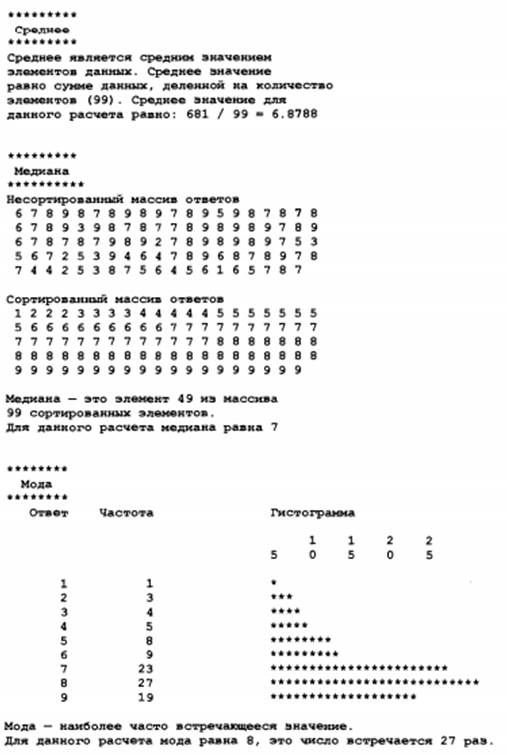
Рис.18 – Пример выполнения программы анализа данных обследования
Линейный поиск (рис.19) сравнивает каждый элемент массива с ключом поиска. Поскольку массив не упорядочен, вполне вероятно, что отыскиваемое значение окажется первым же элементом массива. Но в среднем, однако, программа должна сравнить с ключем поиска половину элементов массива.
Рис.19 – Линейный поиск в массиве
Метод линейного поиска хорошо работает для небольших или для несортированных массивов. Однако, для больших массивов линейный поиск неэффективен. Если массив отсортирован, можно использовать высокоэффективный метод двоичного поиска. Алгоритм двоичного поиска исключает половину еще непроверенных элементов массива после каждого сравнения. Алгоритм определяет местоположение среднего элемента массива и сравнивает его с ключом поиска. Если они равны, то ключ поиска найден и выдается индекс этого элемента. В противном случае задача сокращается на половину элементов массива. Если ключ поиска меньше, чем средний элемент массива, то дальнейший поиск осуществляется в первой половина массива, а если больше, то во второй половине. Если ключ поиска не совпадает со средним элементом выбранного подмассива (части исходного массива), то алгоритм повторно применяется и сокращает область поиска до четверти исходного массива. Поиск продолжается до тех пор, пока ключ поиска не станет равным среднему элементу или пока оставшийся подмассив содержит хотя бы один элемент, не равный ключу поиска (т.е. пока не найден ключ поиска). В наихудшем случае двоичный поиск в массиве из 1024 элементов потребует только 10 сравнений. Повторяющееся деление 1024 на 2 (поскольку после каждого сравнения мы можем исключить половину элементов массива) дает 512, 256, 128, 64, 32, 16, 8, 4, 2 и 1. Число 1024 (210) делится на 2 только десять раз. Деление на 2 эквивалентно одному сравнению в алгоритме двоичного поиска. Массив из 1048576 (2) элементов требует для нахождения ключа поиска самое большее 20 сравнений. Массив из одного миллиарда элементов требует для нахождения ключа поиска максимум 30 сравнений. Это огромное увеличение эффективности по сравнению с линейным поиском, который в среднем требует числа сравнений, равного половине числа элементов в массиве. Для миллиарда элементов выигрыш равен разнице между 500 миллионами сравнений и 30 сравнениями! Максимальное количество сравнений, необходимое для двоичного поиска в любом отсортированном массиве, может быть определено как первый показатель степени, при возведении в который числа 2 будет превышено число элементов в массиве.
Рисунок 20 представляет итеративную версию функции binarySearch. Функция получает четыре аргумента — массив целых чисел b, целое число searchKey, индекс массива low и индекс массива high. Если ключ поиска не соответствует среднему элементу массива, то устанавливается такое значение индекса low или high, что дальнейший поиск проводится в меньшем подмассиве. Если ключ поиска меньше среднего элемента, индекс high устанавливается как middle - 1, и поиск продолжается среди элементов от low до middle - 1. Если ключ поиска больше среднего элемента, индекс low устанавливается как middle + 1, и поиск продолжается среди элементов от middle + 1 до high. Программа использует массив из 15 элементов. Степень двойки для первого числа, большего, чем количество элементов в данном массиве, равна 4 (16 = 2), так что для нахождения ключа поиска нужно максимум четыре сравнения. Функция printHeader выводит на экран индексы массива, а функция printRow выводит каждый подмассив в процессе двоичного поиска. Средний элемент в каждом подмассиве отмечается символом звездочки (*), чтобы указать тот элемент, с которым сравнивается ключ поиска.
Рис.20 – Двоичный поиск в сортированном массиве (часть 1 из 3)
Рис.20 – Двоичный поиск в сортированном массиве (часть 2 из 3)
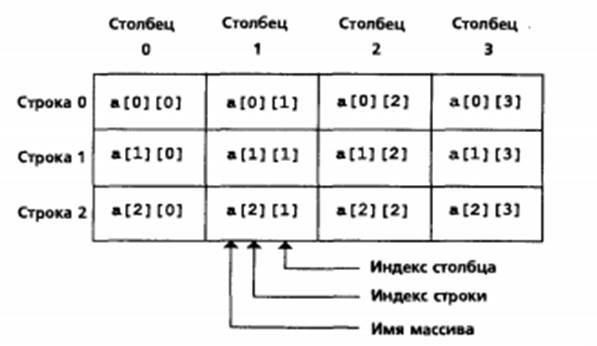
Рис.20 – Двоичный поиск в сортированном массиве (часть 2 из 3) Многомерные массивы Массивы в C могут иметь много индексов. Обычным представлением многомерных массивов являются таблицы значений, содержащие информацию в строках и столбцах. Чтобы определить отдельный табличный элемент, нужно указать два индекса: первый (по соглашению) указывает номер строки, а второй (по соглашению) указывает номер столбца. Таблицы или массивы, которые требуют двух индексов для указания отдельного элемента, называются двумерными массивами. Заметим, что многомерный массив может иметь более двух индексов. Компиляторы C поддерживают по меньшей мере 12- мерные массивы. Рис. 21 иллюстрирует двумерный массив а. Массив содержит три строки и четыре столбца, так что, как говорят, — это массив три на четыре. Вообще, массивы с m строками и n столбцами называют массивами m на n. Каждый элемент в массиве а определяется именем элемента в форме а[ i 1 [ j 1; а — это имя массива, a i и j — индексы, которые однозначно определяют каждый элемент в а. Заметим, что имена элементов первой строки имеют первый индекс 0; имена элементов в четвертом столбце имеют второй индекс 3.
Рис.21 – Двумерный массив с тремя строками и четырьмя столбцами
|
||||||
|
|
Последнее изменение этой страницы: 2021-04-14; просмотров: 117; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.145.43.92 (0.008 с.) |