Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Формулы оценки стоимости соединения SMJСодержание книги
Поиск на нашем сайте
C CPU =[ C SORTCPU (Q 1)]+[ C SORTCPU (Q 2)]+ C JOINCPU (Q 1, Q 2) C I / O =[ C SORTI / O (Q 1)]+[ C SORTI / O (Q 2)]+ C JOINI / O (Q 1, Q 2) C SORTCPU (R)= T (R)⋅log b (T (R)⌈ B (R)/ b ⌉)⋅(C comp + C move)+(log b B (R)−1)⋅ T (R)⋅(b ⋅ C comp + C move) C SORTI / O (R)=2⋅ B (R)⋅ C B Далее возможны варианты:
C JOINI / O =[ B (Q 1)]+[ B (Q 2)]+(T (Q 1) Q 2, a ⋅⌊ B (Q 1) I (Q 2, a)⋅ b ⌋⋅ b ⋅ min (I (Q 1, a), I (Q 2, a))⋅ C B здесь: T (Q 1), T (Q 2) - оценка числа записей в таблицах Q 1 и Q 2; B (Q 1), B (Q 2) - оценка числа блоков в этих же таблицах; I (Q 1, a), I (Q 2, a) - мощности атрибутов в соединении a тех же таблиц; b - число блоков в оперативной памяти, отводимое под сортировку этих таблиц, а также для выполнения соединения; C comp - среднее время соединения двух кортежей из записей этих таблиц в оперативной памяти; C move - время перемещения одной записи в оперативной памяти при сортировке; C B - время чтения/записи одного блока на диск; верхние неполные квадратные скобки - округление с избытком; нижние неполные квадратные скобки - округление с недостатком; обычные квадратные скобки - необязательность, значит уже отсортировано. Механизм сортировки таблиц Механизм сортировки таблиц Q 1 и Q 2:
Таким образом, на диске будет сохранено несколько файлов, и в каждом записи будут отсортированы. Эти файлы образуют первый уровень. Каждый файл можно рассматривать как стек записей. В буфере из b блоков сравниваются первые записи сохранённых на предыдущем этапе файлов (то есть, b файлов, если все сразу сравнивать не можем, потому что их сильно много). Минимальное среди сравниваемых записей значение пишется в файл следующего уровня, а стек, из которого это значение взяли, поднимается. На следующем уровне история повторяется, и так до тех пор, пока не получится один итоговый файл. Записи в нём будут идеально отсортированы. T (R)⌈ B (R)/ b ⌉ - оценка числа записей в одном файле первого уровня. T (R)⌈ B (R)/ b ⌉⋅ log 2 T (R)⌈ B (R)/ b ⌉ - число операций сравнений и перемещений записей при сортировке одного файла первого уровня. Но таких файлов B (R) b. Перемножая их, получаем общее число операций.
Лекция №13 - Оценки (продолжение)
Оптимизация SQL-запросов Физический план Методы соединения таблиц Метод сортировки слияния (SMJ, Sort Merge Join) Формулы оценки стоимости соединения Расчёт числа формул: l = B (R) b l =1, отсюда l =log b B (R) T (R)=log b B (R)−1 Для каждой записи нужно выполнить b ⋅ C COMP + C move - это объясняет второе слагаемое. Число уровней: log B b (R) Число блоков: B (R). Так как пишем и читаем, то B (R)×2 Теперь разбираемся со следующей формулой: I (Q 1, a)> I (Q 2, a) - мощность у первого больше. Смотрим первое слагаемое: (T (Q 1) I (Q 2, a)+2)⋅ T (Q 2) - происходит соединение каждой записи из Q 2 с каждой из Q 1 Смотрим второе слагаемое: T (Q 1) I (Q 2, ar)⋅(I (Q 1, a)− I (Q 2, a)) Следующая формула: [ B (Q 1)]... T (Q 1) I (Q 1, a)⋅⌊ B (Q 1) I (Q 2, a)⋅ b ⌋⋅ b ⋅ min (I (Q 1, a), I (Q 2, a)) На каждую запись нужно выполнить такое число операций чтения и записи в буфер. Метод хешированных соединений (Hash Join) Осуществляется по следующим шагам:
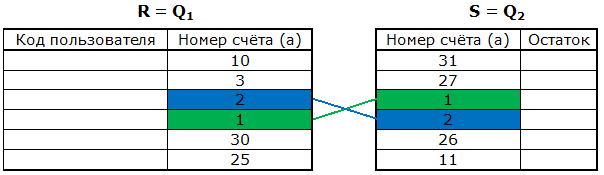
Пример хешированного соединения Предположим, заданы две таблицы (после выполнения подзапросов).
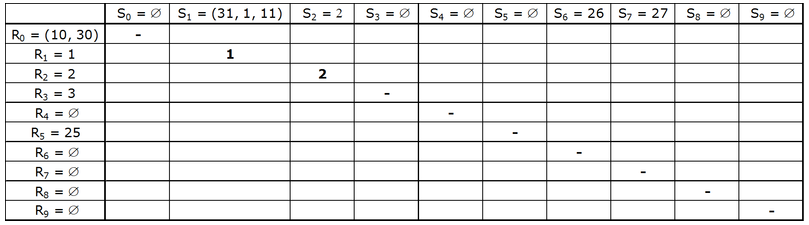
По шагам: 1) в качестве хеш-функции выберем остаток от деления на 10: h (a)= a mod 10 2) R i - подмножество номеров счетов из таблицы R, у которых значение хэш-функции равно i =0..9 S i - подмножество номеров счетов из таблицы S, у которых значение хэш-функции равно i =0..9 представим эти разделы в виде таблицы. Будет 9 разделов.
Разделы соединяются по диагонали. Потому что если остатки от деления разные, то и номера счетов разные. Остальные смотреть не смысла, потому что разные остатки. При значительных объёмах таблиц выигрыш от использования соединения методом хэширования может быть очень значительным, так как соединяемые разделы имеют намного меньшую размерность, чем сами таблицы. Реализация метода может быть различной. Однопроходной вариант реализации Разделы опорной таблицы R хранятся в оперативной памяти. Алгоритм:
Двухпроходной вариант реализации
Оперативной памяти может не хватать. Число размеров (точнее, хеш-функция) подбирается так, чтобы максимальный раздел таблицы R помещался в оперативной памяти. При таком подходе после хеширования таблиц R и S все разделы сохраняются на диске. Алгоритм:
|
||||||
|
|
Последнее изменение этой страницы: 2021-04-12; просмотров: 52; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 52.14.7.103 (0.007 с.) |