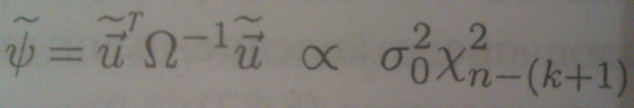Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Тест Голдфелда–Квандта гомоскедастичности случайных возмущений в схеме Гаусса – Маркова ⇐ ПредыдущаяСтр 8 из 8
Тест Голдфелда-Квандта предназначен для проверки предпосылки Var(u 1)=Var(u 2)=…=Var(un)= Ϭ 2 теоремы Гаусса-Маркова о гомоскедастичности случайного остатка в модели y = a 0 + a 1 x 1 + a 2 x 2 +…+ akxk + u (1) E(u | x)=0, E(u2 | x)= Ϭu 2 т.е. для проверки статистической гипотезы о равенстве дисперсий случайных остатков в уравнениях наблюдений y = X a + a: H0 : Var(u1)=Var(u2)=…=Var(un)= Ϭ 2 (2) Неадекватность гипотезы (2) порождает негативные для МНК-оценок a =f ⃰ (X, y)=f МНК (X, y)=M(X) y =(XTX)-1XT y
u12 + u22 + … + u n 2 Ϭu 2 = n – (k + 1) определённые последствия. Рассмотрим алгоритм теста (статистической процедуры) Голдфелда-Квандта, а затем проведём его обоснование. Тест Голдфелда-Квандта реализуется в итоге следующих шагов. Шаг 1. Уравнения наблюдений объекта y = X a + a следует упорядочить по возрастанию суммы модулей значений предопределённых переменных модели (1), т.е. по возрастанию значений z 1 = | x 1 i | + | x 1 i | +…+ | x 1 i | (3) Замечание. В этот пункт процедуры Голдфелда-Квандта заложена естественная предпосылка, что возможная гетероскедастичность случайного остатка в модели (1), т.е. зависимость его условий дисперсии Var(u) = E(u 2 | x) от объясняющих переменных модели, имеет специальный вид: E (u 2 | x) = f (| x 1 |+| x 2 |+…+| xk |) = f (z), (4) Причём функция f (z) является либо возрастающей, либо убывающей. Нужно подчеркнуть, что если случайный остаток гомоскедастичен, то любая зависимость Var(u) = E(u 2 | x) от x, а частности зависимость (4), отсутствует. Добавим, что после вычисления в отдельном столбце листа Excel величин (3) упорядочение уравнений наблюдений y = X a + a осуществляется командой «Сортировка по возрастанию» из категории «Данные». Шаг 2. По первым n ′ упорядоченным уравнениям наблюдений объекта (где n ′ удовлетворяет условиям k +1 < n ′, n ′ ≈ 0,3 n, (5) k +1 – количество оцениваемых коэффициентов функции регрессии) вычислить МНК-оценки параметров модели и величину n ′
ESS1 = ∑ ui2, (6) i =1 где ui = yi – yi = yi – (a 0 +a 1 x 1 i + … + akxki) - (7) МНК-оценка случайного возмущения ui. Замечание. Напомним, что функция ЛИНЕЙН Excel размещает величину ESS в ячейке B n +5, т.е. во втором столбце последней строки выделенного массива. Шаг 3. По последним n ′ упорядоченным уравнениям наблюдений вычислить МНК-оценку параметров модели и величину ESS, которую обозначим ESS 2. Шаг 4. Вычислить статистику ESS1 GQ = ESS 2 (8) Шаг 5. Задаться уровнем значимости ɑ и с помощью функции FРАСПОБР Excel при количествах степеней свободы ʋ1, ʋ2, где ʋ1 = ʋ2 = n ′ - (k +1), определить (1- ɑ)-квантиль, F крит= F 1- ɑ распределения Фишера. Шаг 6. Принять гипотезу (2), если справедливы неравенства GQ ≤ F крит (9) GQ -1 ≤ F крит т.е. при справедливых неравенствах (9) случайный остаток в модели (1) полагать гомоскедастичным. В противном случае гипотезу (2) отклонить как противоречащую реальным данным и сделать вывод о гетероскедастичности случайного остатка в модели (1). Замечание. Обсужденный выше тест корректен в ситуации, когда случайные остатки в уравнениях наблюдений y = X a + a распределены по нормальному закону и все другие предпосылки теоремы Гаусса-Маркова справедливы. Проведём обоснование теста Голдфелда-Квандта. Если вектор случайных остатков в уравнениях наблюдений имеет нормальный закон распределения и все предпосылки теоремы Гаусса-Маркова справедливы, то согласно
величины ESS 1 и ESS 2 являются случайными переменными и распределены (с точностью до множителя Ϭu 2) по закону хи-квадрат с количеством степеней свободы n ′ -(k +1). Кроме того, согласно предпосылке
Cov(ui, uj)=0, i ≠ j эти переменные независимые. Значит, и статистика (8), и обратная к ней величина GQ -1 являются случайной переменной и имеют распределение Фишера с количествами степеней свободы ʋ1, ʋ2. Следовательно, критерием гипотезы (2) может служить множество Z [ H 1]=(F 1- ɑ , +∞). (10) Если величина GQ (или величина GQ -1) попадает в множество (10), то гипотезу (2) следует отклонит ь в пользу альтернативной гипотезы H 1= H 0, (11) Представляющей отрицание гипотезы (2), т.е. означающей гомоскедастичность случайного остатка в модели (1). Второе условие (приближенное равенство) в (5) обеспечивает максимальную мощность критерия (9).
|
||||||
|
|
Последнее изменение этой страницы: 2021-03-10; просмотров: 122; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 13.58.121.131 (0.009 с.) |