Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Модели представления знаний.Содержание книги Поиск на нашем сайте
Введение Настоящий курс посвящен одному из важных направлений современной информатики – искусственному интеллекту. Основой всех систем искусственного интеллекта является представление знаний, т.е. информации о свойствах и закономерностях тех или иных предметных областей. Предметная область – это некий фрагмент окружающего нас реального мира, процессов развития современного общества, научная теория и пр. Для представления знаний используются различные формальные модели, позволяющие не рассматривать бесконечное разнообразие предметной области, а сосредоточиться на наиболее существенных ее особенностях. В литературе можно найти много различных определений самого понятия искусственного интеллекта (ИИ). Вот некоторые из них: ИИ – это свойство автоматических или автоматизированных систем брать на себя отдельные функции интеллекта человека, т.е., например, выбирать и принимать оптимальные решения на основе ранее накопленного опыта и рационального анализа внешних воздействий. ИИ – это программные системы, выполняющие функции, которые традиционно считаются прерогативой человека. Интеллектуальная система способна решать задачи, традиционно считающиеся творческими, принадлежащие конкретной предметной области, знания о которой хранятся в памяти такой системы. Структура интеллектуальной системы включает три основных блока — базу знаний, решатель и интеллектуальный интерфейс. Одним из наиболее успешных направлений ИИ являются экспертные системы (ЭС). ЭС – это программная система, в которую включены знания специалистов (экспертов) о некоторой предметной области и которая в пределах этой области способна принимать экспертные решения. В рамках экспертных систем к настоящему моменту достигнуты успехи в таких областях, как медицинская диагностика, обнаружение неисправностей в электронном оборудовании финансовая сфера и пр. Обычно ЭС используется как электронный консультант, который с помощью советов и рекомендаций помогает пользователю находить правильные решения возникающих у него проблем. Хорошо разработанная ЭС действует как эксперт-профессионал в данной предметной области. В 1950-м году английский математик и логик Алан Тьюринг предложил тест (иногда называемый «английской гостиной»), с помощью которого можно оценить «интеллектуальные» способности компьютера. Вот его описание:
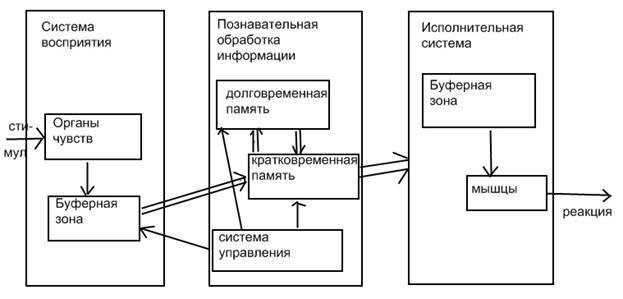
«Человек взаимодействует с одним компьютером и одним человеком. На основании ответов на вопросы он должен определить, с кем он разговаривает: с человеком или компьютерной программой. Задача компьютерной программы — ввести человека в заблуждение, заставив сделать неверный выбор». Все участники теста не видят друг друга. Если судья не может сказать определенно, кто из собеседников является человеком, то считается, что машина прошла тест. Отметим два принципиально различных подхода к разработке систем ИИ. Согласно первому при создании систем ИИ не ставится задача моделирования мыслительной деятельности человека. Согласно второму, наоборот, требуется, чтобы системы ИИ решали задачи так, как это делает человек. Большинство систем ИИ было разработано в соответствии с первым подходом. Однако в настоящее время значение второго подхода стало расти. Процесс мышления, или, иначе говоря, работа головного мозга, до сих пор до конца не изучен и в настоящем курсе предлагается лишь самая простая его модель, позаимствованная из одного из литературных источников. Одна ячейка человеческого глаза способна выполнить за 10 мсек обработку, эквивалентную решению 500 нелинейных дифференциальных уравнений со 100 переменными. Суперкомпьютеру для решения подобной системы потребуется несколько минут. В глазе 10 миллионов ячеек, которые работают параллельно. Суперкомпьютер потратит много лет, чтобы выполнить работу глаза за 1 секунду. Простейшая схема областей головного мозга, участвующих в обработке информации, выглядит так:
В долговременной памяти хранятся объекты и связи между ними. В кратковременную память все время поступает информация. Обработка ее быстрая (отдергиваем руку от горячего, играем в мяч и пр.). Перевод информации из кратковременной памяти в долговременную занимает 15 – 20 минут. Это проверено на травмированных людях. В мозгу хранятся символьные образы. Они объединяются в так называемые чанки – наборы фактов и связей между ними. Чанки воспринимаются как единое целое. В каждый момент времени человек может обработать от 4 до 7 чанков.
Успехи человека в деятельности в предметной области во многом зависят от его способности образовывать чанки. Эксперт соединяет в чанки большие объемы данных, устанавливает иерархические связи. Таким образом, объем знаний эксперта зависит от величины чанков. Средний специалист в предметной области помнит 50 – 100 тысяч чанков. Это требует 10 – 20 лет обучения.
Представление знаний. Данные – это отдельные факты, характеризующие объекты, процессы и явления предметной области, а также их свойства. В компьютере данные трансформируются, условно проходя следующие этапы: 1) D1 – данные как результат измерений и наблюдений. 2) D2 – данные на материальных носителях информации (таблицы, протоколы, справочники). 3) D3 – модели (структуры) данных в виде диаграмм, графиков, функций. 4) D4 – данные в компьютере на языке описания данных. 5) D5 – база данных на машинных носителях информации.
Знания основаны на данных, полученных, в основном, эмпирическим путем. Они представляют собой результат мыслительной деятельности человека, направленной на обобщение его опыта, полученного в результате практической деятельности.
Знания – это закономерности предметной области (принципы, связи, законы), полученные в результате теоретических исследований, практической деятельности и профессионального опыта, позволяющие специалистам ставить и решать задачи в этой области. При обработке в компьютере знания трансформируются аналогично данным: 1) K1 – знания в памяти человека как результат мышления. 2) K2 – знания на материальных носителях (учебники, методические пособия). 3) K3 – поле знаний, т.е. условное описание основных объектов предметной области, их атрибутов и связывающих их закономерностей. 4) K4 – знания, описанные на языках представления знаний (языки логического программирования, продукционные языки и др.). 5) K5 – база знаний на машинных носителях информации. Часто используются следующие определения знаний через данные: Знания– это хорошо структурированные данные. Знания – это метаданные (данные о данных).
Способы определения понятий: 1) С помощью интенсионала, т.е. определение через соотнесение с понятием более высокого уровня абстракции с указанием специфических свойств. Например: Персональный компьютер – это небольшая относительно дешевая ЭВМ, которую можно поставить на стол. 2) С помощью экстенсионала, т.е. через соотнесение с понятием более низкого уровня абстракции или через перечисление фактов, относящихся к определяемому объекту. Например: Персональный компьютер – это IBM PC, Mac, Sincler и т.д. Для хранения знаний используются базы знаний. Это относительно небольшие, но дорогие информационные массивы.
Знания могут классифицироваться следующим образом: 1) Поверхностные, т.е. знания о видимых взаимосвязях между отдельными объектами предметной области (ПО). 2) Глубинные, т.е. абстракции, аналогии, схемы, отображающие структуру и природу процессов, протекающих в ПО. Эти знания объясняют явления и могут использоваться для прогнозирования поведения объектов ПО. Современные ЭС в основном работают с поверхностными знаниями. Процедурные и декларативные знания. Понятие декларативного языка (представления знаний).
Понятие логического вывода.
Логический вывод – это решение проблемы дедукции с помощью резолюционных методов (прямая дедукция) или метода Маслова (обратная дедукция). Особенности языка
Пролог имеет два главных отличия от процедурных языков: 1) Программирование на Прологе по-преимуществу является символьным. Данные в этом языке – это символы, которые никак не интерпретируются, и числа. (исключение – числа). 2) Так как Пролог относится к парадигме декларативного программирования, алгоритмы решения задач не задаются. Формулируется лишь условие задачи, после чего она решается с помощью встроенного (в интерпретатор) универсального алгоритма логического вывода, основанного, как уже упоминалось, на входной линейной резолюции. Программа на Прологе состоит из описания предметной области и вопроса. Предметная область задается описанием объектов и отношений между ними с помощью фактов и правил. Факты и правила представляются хорновскими дизъюнктами: факты – унитарными позитивными дизъюнктами, правила – точными дизъюнктами. При этом с помощью фактов указываются тождественно истинные утверждения – представленные предикатами со значениями аргументов (термов), при которых они являются истинными. С помощью правил задаются средства установления новых фактов. Каждое правило интерпретируется так: если истинными являются все предикаты, представленные негативными литерами, то истинным считается и предикат, представленный позитивной литерой. Вопросы указывают на необходимость установить наличие в БЗ указанных в них фактов или попытаться вывести эти факты в качестве новых. Вопросы представляются негативными дизъюнктами. Характерными чертами языка Пролог считаются: 1) наличие алгоритма вывода с поиском и возвратом, который осуществляется с помощью стековой памяти и используется для перебора всех возможных вариантов вывода; возврат часто называется откатом, а перебор вариантов с откатом выполняется процедурой, называемой бэктрекингом. 2) наличие встроенного механизма сравнения с образцом (для реализации процедуры унификации); 3) простые синтаксис и структура данных. Синтаксис языка. Синтаксическими элементами языка являются: Термы: константы, переменные, сложные термы. Константы: целые и вещественные числа, атомы (любые цепочки символов, не начинающиеся с заглавных букв или любые цепочки символов в кавычках). Целые числа представляются последовательностями цифр с возможным знаком «+» или «-». Вещественные числа представляются в двух форматах:
1) В виде десятичной дроби, например: 10.12, -0.25, +35.1234. В некоторых случаях целые числа могут интерпретироваться как десятичные дроби – это зависит от контекста, в котором находится число. 2) В виде мантиссы и десятичного порядка: <десятичная дробь>Е<целое>, например: 1.012E1, -0.95Е+3, 125Е-2. Как видно из примеров, перед вещественными числами могут находиться знаки «+» или «-» Переменные: цепочки букв, цифр и знака подчеркивания («_»), начинающиеся с заглавной буквы или знака подчеркивания. Особая переменная – анонимная. Она представляется знаком подчеркивания. Сложный терм это: 1) структура, состоящая из атома-предиката ( или функтора) и компонент, т.е. термов в скобках через запятую; при этом компоненты сами могут являться сложными термами; например информация о книгах библиотеки может состоять из следующих данных: автор, название, издательство, год выпуска – книга(“Л.Н. Толстой”, “Война и мир”, “Художественная литература”, “2002”). 2) список, т.е. упорядоченный набор связанных между собой термов; имеется возможность работать как целиком со списком, так и с отдельными входящими в него термами. Константы и структуры представляют объекты предметной области, а списки – упорядоченные наборы объектов. Роль структур заключается в группировке некоторых объектов, представляющих составной объект. База знаний, описывающая предметную область, задается фактами и правилами. Факты – это отдельные предикаты, состоящие из имени предиката и, возможно, термов, представляющих его аргументы. Правила имеют вид: p 1 (…): – p 2 (…), …, pn (…), n ≥ 2, где pi – предикаты. Приведем примеры простых баз знаний, пояснив кроме синтаксиса также их семантику. Фрагмент словаря синонимов и антонимов может быть представлен следующей базой знаний: synonym("храбрый","отважный"). synonym("храбрый","бесстрашный"). synonym("современный","новый"). synonym("редкий","неупотребительный"). antonym("храбрый","трусливый"). antonym("честный","бесчестный"). antonym("современный","старый"). antonym("редкий","частый"). Фрагмент описания предметной области «Дифференцирование», который представляет правило дифференцирования суммы, может быть представлен следующими фактом и правилом: diff(Х,Х,1). diff (U+V, X, A+B): – diff (U, X, A), diff (V, X, B). Отметим, что в первом из этих примеров мы использовали только факты. Все они представляют два предиката, для имен которых использованы функторы synonym и antonym. Вы можете без труда заметить, что их компоненты подобраны так, что они действительно являются, соответственно, синонимами и антонимами друг друга в общепринятом понимании этих терминов. Во втором примере имеется факт diff(Х,Х,1). Он отражает простейшее правило дифференцирования, согласно которому производная по X функции F(X) = X равна 1. Правило второго примера интерпретируется так: если производная по X функции U равна A, а производная по X функции V равна B, то производная по X суммы U+V равна A+B. Вопросы представляются в виде одного или нескольких предикатов, называемых целями:
?- p 1 (…), p 2 (…), …, pn (…), n ≥ 1. Список целей, заданный этим вопросом, таков: p 1 (…), p 2 (…), …, pn (…). Если вопрос состоит из одного предиката, то он называется простым, в противном случае – составным. Активная цель – это первая цель списка (в нашем примере p 1). После осуществления логического вывода активной цели, она исключается из списка, который в случае нашего примера примет вид: p 2 (…), …, pn (…). В этом случае говорят, что цель доказана или достигнута и активной становится цель p 2. Работа заканчивается либо после достижения последней цели списка pn (в случае наличия решений), либо при возникновении тупиковой ситуации, когда вывод какой-нибудь активной цели оказывается невозможным. Программы на Прологе состоят из двух частей – описания предметной области и вопроса: 1) Факты и правила, описывающие предметную область. 2) Вопрос. Например, приписав вопрос ?- synonym("храбрый",X), antonym("храбрый", Y) к базе знаний первого примера, получим программу. Ответы на вопросы пользователей формируются в процессе выполнения программ и в разных версиях языка представляются по-разному. Мы примем следующий вариант. Если ответ должен быть положительным или отрицательным, то он представляется в форме Yes и No соответственно. Если же требуется указать выполненные в процессе логического вывода подстановки, вместо переменных, входящих в цели, то они перечисляются в ответе, после чего указывается число найденных решений. Например, ответ на приведенный выше вопрос выглядит так: X = "отважный", Y = "трусливый" X = "бесстрашный", Y = "трусливый" 2 Solutions
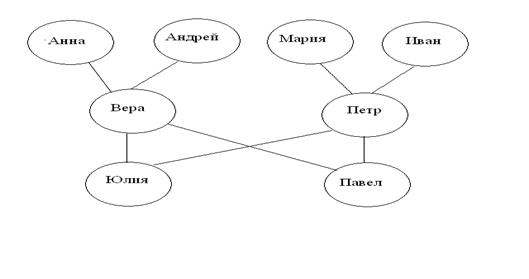
Типы вопросов. В зависимости от вида вопросы языка Пролог делятся на несколько типов. Тип вопроса влияет как на его обработку алгоритмом логического вывода, так и на вид ответа. Различные варианты вопросов удобно рассмотреть на примере предметной области, представляющей родственные отношения (для удобства будем нумеровать предложения, описывающие предметную область).
Граф родственных отношений, представленный этой таблицей, выглядит следующим образом (верхние вершины дуг – родители, нижние – дети):
Рассмотрим типы вопросов. 1) Вопросы, в целях которых отсутствуют переменные. С помощью таких вопросов пользователь может спросить, верно или нет некоторое предположение (свойство, отношение). Например: «Верно ли, что отцом Юлии является Петр?» На Прологе: ? – отец(«Петр», «Юлия») Или: «Верно ли, что Павел является дедушкой Марии?» На Прологе: ? – дед(«Павел», «Мария») На первый вопрос должен быть дан положительный ответ, который система выдаст в виде: Yes. Ответ на второй вопрос отрицательный: No. Вопросы этого типа могут быть и составными, например: «Верно ли, что Анна является бабушкой, а Андрей дедушкой Юлии?» ? – бабка(«Анна», «Юлия»), дед(«Андрей», «Юлия»). Ответ: Yes. Или: «Верно ли, что отцом и матерью Петра являются Иван и Мария?» ? – отец(«Иван», «Петр»), мать(«Мария», «Петр»). Ответ: No. Заметим, что во втором вопросе первая цель представлена правильным предположением, а вторая – неправильным. Так как для положительного ответа требуется, чтобы все предположения были правильными, в данном случае дается отрицательный ответ. 2) Вопросы с использованием переменных (не анонимных). Семантика этих вопросов совсем другая. С их помощью пользователь может узнать, для каких объектов предметной области выполнены свойства или отношения, указанные в вопросе. Например: «Кто является отцом Юлии?». На Прологе: ? – отец (Х, «Юлия»). Или: «Укажите дедушек и бабушек Павла». На Прологе: ? – дед(Х, «Павел»), бабка(Y, «Павел»). В ответах на вопросы этого типа перечисляются значения переменных, при которых предикаты вопросов являются истинными. На первый вопрос будет дан ответ: Х = «Петр». 1 Solution. На второй вопрос будет получен ответ: Х = «Андрей», Y = «Анна» Х = «Иван», Y = «Мария». 2 Solutions. Вопрос может быть таким, что вариантов ответов на него нет, например: «Кто является дедушкой Петра?» ? – дед(Х, «Петр»). Тогда ответ системы будет выглядеть так: No Solution. 3) Вопросы, в которых используется анонимная переменная. Анонимная переменная играет в Прологе особую роль. С ее помощью пользователь может узнать, существуют ли в предметной области такие объекты, для которых его предположение оказывается истинным. При этом его интересует лишь существование таких объектов, но не они сами. Например: «Известен ли хоть один дедушка Юлии?» Или: «Указаны ли в предметной области внуки Петра?» На Прологе: ? – дед(_, «Юлия»). ? – дед(«Петр», _). Ответы на подобные вопросы представляются в такой же форме, как в случае вопросов первого типа: Yes и No соответственно. Как видно из приведенных типов вопросов, при отсутствии анонимных переменных их обработка предполагает полный перебор выводов (так как необходимо найти все варианты ответов). Если в вопросе используется анонимная переменная, перебор может быть сокращен. Так, обрабатывая вопрос? – дед(_, «Юлия»),системе достаточно обнаружить одного деда, хотя как видно из схемы родственных отношений примера, в БЗ их двое. Приведем пример работы алгоритма логического вывода, представив ее в виде таблицы со следующими полями: 1) №№ варианта и шага вывода. Так как потребуется перебор, будет осуществляться возврат на уже выполненные шаги с целью поиска других вариантов их выполнения. Возврат будет осуществляться с помощью процедуры бэктрекинга. 2) Список целей. 3) № предложения (факта или правила), выбранного для резолюции. 4) Унификатор 5) Стек возвратов, используемый процедурой бэктрекинга. Задается в виде: пар: № шага, на который нужно вернуться, и № первого предложения, с которого нужно продолжить просмотр. 6) Примечания. Пусть пользователь ввел вопрос:? – дед(«Иван»,Х). Работа алгоритма логического вывода может быть представлена следующей таблицей:
Так как после шага 1.7 стек возвратов оказался пустым, полный перебор осуществлен и алгоритм логического вывода заканчивает работу. В результате будет сформирован ответ: Х = «Юлия» Х = «Павел» 2 Solutions.
Встроенные предикаты Встроенным предикатом называется стандартный предикат, доступный пользователям системы программирования, базирующейся на Прологе. Процедуры его обработки встроены в интерпретатор или компилятор языка. Встроенный предикат не нужно явно включать в базу знаний. Совокупность встроенных предикатов во многом определяет возможности программной системы, а многие из них абсолютно необходимы для разработки приложений, имеющих практическую ценность. Важной особенностью большинства встроенных предикатов является так называемый побочный эффект. Поясним это понятие простым примером. Предположим, нам необходимо вывести на экран монитора некоторую информацию, полученную во время выполнения программы на Прологе. Для этого мы можем воспользоваться встроенным предикатом write. Этот предикат является тождественно истинным, однако, становясь активной целью, он инициирует вывод на экран дисплея или в файл значений тех термов, которые являются его аргументами. Встроенных предикатов Пролога много и в разных реализациях они не всегда совпадают друг с другом. Поэтому здесь мы остановимся лишь на некоторых, наиболее важных.
Арифметика
Хотя Пролог не очень приспособлен для решения задач вычислительного характера, он включает в себя стандартные средства вычислений. Арифметические операции реализуются в Прологе с помощью хорошо известных операторов: +, -, *, /, div, mod. Операнды первых четырех из них могут быть как целыми, так и вещественными, последние два определены только для целых операндов. Арифметические выражения строятся в Прологе по правилам, не отличающимся от общепринятых. Вот примеры выражений, не требующие комментариев: (A+B)*C/2, ((3.1*A-12)/(B-1)+2.5)*2 и т.д. Выражения не являются предикатами. Они должны быть частью оператора присваивания, либо операндами сравнений, которые представлены встроенными предикатами особого типа, синтаксис которых отличается от синтаксиса других предикатов. Важной особенностью этих предикатов является то, что они представлены в инфиксной форме: <аргумент1> <имя предиката> <аргумент2>
Сначала остановимся на операторе присваивания. Это особая конструкция Пролога для рассмотрения которой необходимо ввести понятия конкретизированной и свободной переменных. Конкретизированной называется переменная, которой было присвоено некоторое значение. В большинстве случаев значение переменной присваивается при унификации. Пусть, например, активная цель имеет вид: p (a, Y) и сопоставляется с правилом базы знаний вида: p (X, Y):- q 1 (X, Z), …, qn (t 1, …, tm). Наиболее общий унификатор таков: {(X, a)} и поэтому после резолюции образуется список целей: q (a, Z), …. Таким образом, применение унификации позволило определить значение всех вхождений переменной X в приведенное правило, и, следовательно, эта переменная оказалась конкретизированной. Важно помнить, что областью действия конкретизации X является правая часть правила, использованного для резолюции, иначе говоря, список целей q 1 (X, Z),…, qn (t 1, …, tm). В то же время значения переменных Y и Z остались неопределенными. Такие переменные называются свободными. Синтаксис оператора присваивания таков: A = <обобщенный терм>, либо <обобщенный терм> = A, где A – свободная переменная, а <обобщенный терм> – арифметическое выражение или терм. Обратите внимание, что переменная, которой присваивается значение, может быть расположена как слева, так и справа от знака равенства. Если в операторе используется арифметическое выражение, то переменной присваивается его численное значение. В противном случае переменной присваивается значение терма. Если А – конкретизированная переменная, а обобщенный терм – не свободная переменная, то данная синтаксическая конструкция является предикатом сравнения на равенство, о котором речь пойдет в следующем разделе. После обзора необходимых стандартных предикатов вам будут предложены примеры. Предикаты сравнения Предикаты сравнения – это стандартные предикаты, реализующие хорошо известные операции отношений. Как уже упоминалось, особенностью этих предикатов является то, что они имеют инфиксную форму вида <аргумент1> <отношение> <аргумент2>. Здесь аргументы – это сравниваемые термы, а отношение обозначается обычными синтаксическими знаками: <, <=, =, >, >=. Таким образом, предикат сравнения по виду не отличается от отношений процедурных языков. Отметим, что сравнивать необходимо термы одинаковых типов, например, числа с числами, строки со строками и т.д. Предикаты принимают значение «истина», если для аргументов выполнено соответствующее отношение. Особенностью предиката равенства является то, что обозначающий его синтаксический знак (=) двузначен: как уже было сказано выше, он применяется не только для данного предиката, но и для оператора присваивания. Однако правило его использования простое: если среди аргументов нет свободной переменной, то соответствующая конструкция интерпретируется как предикат равенства.
Предикаты ввода-вывода Обширная группа стандартных предикатов предназначена для ввода, вывода, организации хранения данных, а также для связи с базами данных.Для связи с внешним миром в Пролог включены специальные стандартные предикаты. Они позволяют ввести с экрана монитора или из файла компьютера необходимые данные, например, конкретизировать переменные, а также вывести на экран или записать в файл результаты работы программы. Ряд предикатов предназначен для работы с файлами и базами данных. Мы рассмотрим лишь те из них, которые применяются для ввода и вывода данных Предикаты, имена которых начинаются строкой букв read, предназначены для ввода данных. Например, readint служит для ввода целых, readreal – вещественных чисел, readln – символьную строку и т.д.Вообще говоря, эти предикаты могут вводить данные из разных источников. Но по умолчанию они вводятся с экрана монитора, для чего в большинстве реализаций предусмотрено специальное окно.Аргументами этих предикатов должны быть свободные переменные, число их неограниченно. Предикат write – это универсальный предикат вывода, он позволяет вывести значения всех типов. Аргументами этого предиката должны быть константы или конкретизированные переменные, число аргументов неограниченно. Примеры использования этих и других встроенных предикатов вы найдете в конце данного раздела. Предикат Ln используется для перехода на новую строку при выводе. Рассмотренные предикаты этой группы являются тождественно истинными.
Предикат отсечения
Важнейшим из встроенных предикатов является предикат отсечения, который часто называют просто отсечением. Это тождественно истинный предикат, не имеющий аргументов. Изображается он чаще всего восклицательным знаком: «!». Побочный эффект этого предиката позволяет программно управлять перебором. Пусть активная цель представлена предикатом p и он унифицировался с предикатом из правила (аргументы предикатов в данном случае несущественны): p:- p 1, …, pm,!, pm +1, …, p n. Таким образом, список целей приобрел вид: p 1, …, pm,!, pm +1, …, p n, … Предположим также, что в базе знаний после данного правила имеется еще несколько правил и/или фактов для данного предиката, например: p:- q 11, …, qk . … p. … p:- q 21, …, ql и т.д. Пусть цели p 1, …, pm достигнуты, и предикат отсечения оказался активной целью: !, pm +1, …, p n, … Так как «!» – это тождественно истинный предикат, данная активная цель будет достигнута, а его побочный эффект отключает механизм возвратов для перебора других вариантов вывода целей p 1, …, pm, а также выводы первоначальной цели p с помощью правил и фактов, расположенных в базе знаний после правила, содержащего отсечение. В то же время, перебор выводов целей pm +1, …, p n, … будет выполнен в полном объеме. Отсечение применяется, в основном, в следующих трех случаях: для устранения бесконечных циклов, при наличии в базе знаний взаимоисключающих предложений и при необходимости неудачного доказательства цели. Ниже мы проиллюстрируем эти случаи примерами.
Тождественно ложный предикат Предикат fail является тождественно ложным предикатом, не имеющим побочного эффекта. Этот предикат применяется в ряде случаев, например, при так называемом «откате после неудачи».
Примеры 1) Рассмотрим пример использования функторов при моделировании предметной области «Библиотечные каталоги», содержащей сведения о личных библиотеках. Будем считать, что в базу знаний включены имена владельцев библиотек, и данные о книгах: автор, название, издательство, год выпуска. Последние естественно объединить функтором. Таким образом, база знаний должна состоять из фактов, перечисляющих единицы хранения библиотек и их владельцев. Для ее формирования достаточно использовать единственный предикат collection: collection("Анисимова", book("Программирование на языке Пролог", "Клоксин У., Меллиш К.", "Мир",1987)). collection("Анисимова", book("Логика в решении проблем", "Ковальски Р.", "Наука",1990)). collection("Анисимова", book("Язык программирования Пролог", "Стобо Дж.", "Радио и связь",1993)). collection("Анисимова", book("Системы продукций", "Яхно Т.М.", "АН СССР. Сиб. отделение",1990)). collection("Братчиков", book("Синтаксис языков программирования", "Братчиков И.Л.", "Наука",1975)). collection("Братчиков", book("Введение в МПролог", "Иванова Г.С., Тихонов Ю.В.", "МГТУ",1990)). collection("Братчиков", book("Принципы искусственного интеллекта", "Нильсон Н.", "Радио и связь",1985)). collection("Братчиков", book("Реализация экспертных систем", "Клещев А.С.", "Препринт ДВО АН СССР",1988)). collection("Братчиков", book("Компиляторы", "Ахо А., Сети Р., Ульман Дж. ", "Вильямс", 2003)).
2)«ОБЕЗЬЯНА И БАНАН». Построим базу знаний для моделирования поведения обезьяны в следующей ситуации. Обезьяну впускают в комнату, в которой имеется ящик, стоящий у окна, а посередине комнаты к потолку подвешен банан. Обезьяна хочет достать банан, но для этого ей нужно подойти к ящику, перетащить его на середину комнат и залезть на ящик.
База знаний примера:
1) ход(состояние (середина, на-ящике, середина, не-имеет), схватить, состояние(середина, на-ящике, середина, имеет).
2) ход(состояние (Р, на-полу, Р, Н), залезть, состояние(Р, на-ящике, Р, Н).
3) ход(состояние (Р1, на-полу, Р1, Н), подвинуть(Р1,Р2), состояние(Р2, на-полу, Р2, Н).
4) ход(состояние (Р1, на-полу, В, Н), перейти (Р1,Р2), состояние(Р2, на-полу, В, Н).
5) может_завладеть(состояние(_, _, _, имеет)).
6) может_завладеть (С1):-- ход (С1, Ход, С2), может_завладеть (С2).
Здесь «состояние» – это функтор, определяющий состояние, в котором находится система. Компоненты функтора: расположение обезьяны в комнате, вертикальное расположение обезьяны (на полу или на ящике), расположение ящика в комнате и указание на то, схватила ли обезьяна банан. В базе знаний используются два предиката. Предикатом «ход» определяются возможные действия обезьяны. Три аргумента предиката задают состояние системы до действия обезьяны, само действие (тоже функтор, в зависимости от действия либо без компонентов, либо с двумя компонентами) и состояние после действия. Предикат «может_завладеть» имеет один аргумент – состояние системы. Цель, представленная этим предикатом, достигается, если при данном состоянии обезьяна, действуя правильно, может схватить банан. Для правильного понимания семантики базы знаний следует помнить, что все слова, начинающиеся с больших букв, являются переменными (С, С1, Ход и пр.). Рассмотрим работу алгоритма поиска логического вывода для приведенной базы знаний и следующего вопроса (для сокраще
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2021-03-10; просмотров: 93; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.138.102.163 (0.013 с.) |