Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Неопределенность знаний и данных.
Неопределенность используемой информации в ЭС в большинстве случаев имеет два источника: а) недостаточно полное знание предметной области; б) неполная информация о текущей ситуации. В практической деятельности мы сталкиваемся с ситуацией, когда имеющаяся в нашем распоряжении информация неполна, неопределенна, требует детализации и пр. Например, могут быть несколько теорий о происхождении и проявлениях того или иного явления, имеющиеся сведения могут быть недостаточно четко и формально сформулированы и пр. Примеров подобных обстоятельств молжно привести много. Наконец, даже если знания о предметной области достаточно полны, эксперт может предпочесть точным эвристические методы решения проблем. Помимо неточных знаний неопределенность может быть внесена и неточными или ненадежными данными о конкретной ситуации. Измерительные приборы имеют ограниченную точность и не 100-процентную надежность; при анализе ситуации могут использоваться недостоверные или даже ошибочные данные. Итак, эксперты вынуждены пользоваться неточными методами по двум главным причинам: 1) точных методов не существует; 2) точные методы существуют, но не могут применяться из-за недостаточного объема данных или невозможности их накопления по соображениям стоимости, отсутствия необходимого времени и пр.
Таким образом, неточные методы играют значительную роль впри разработке ЭС, но мнения, какие именно методы использовать, разделились. Имеются два подхода к этой проблеме: применение теории вероятностей и нечеткая логика.
ЭС и теория вероятностей. Условная вероятность.
Условная вероятность события d при данном событии s – это вероятность наступления d при условии, что наступило s. В традиционной теории вероятностей для вычисления условной вероятности используется формула: P(d|s) = P(d Ù s) / P(s) (1) или P(s|d) = P(d Ù s) / P(d) или P(d Ù s) = P(s|d)P(d) Поделим обе части последней формулы на P (s) и воспользуемся первой формулой: P(d|s) = P(s|d)P(d) / P(s). (2) Эта формула часто называется инверсной формулой условной вероятности, она представляет правило Байеса в простейшем виде. Суть формулы в том, что условная вероятность P (d | s) может быть вычислена через «инверсную» условную вероятность P (s | d), которую мы считаем известной. Иногда P (d) называют априорной вероятностью события d, а P (d | s) –апостериорной вероятностью.
В ЭС формула (2) удобнее формулы (1). Покажем это на примере. Пусть у пациента наблюдается боль в груди и необходимо оценить вероятность у него инфаркта миокарда (учитывая, что боль в груди может быть следствием совсем другого заболевания). Итак d – и.м., s – б.г. Для вычисления искомой вероятности по формуле (1) нужно знать, сколько человек в мире страдают б.г. и сколько из них страдают б.г. потому, что больны и.м. Обычно такая информация отсутствует, особенно та, которая необходима для вычисления P (d Ù s). Эта трудность послужила основанием для негативной оценки роли ТВ в ИИ. Однако, существует и так называемая «субъективистская» точка зрения на ТВ, которая позволяет иметь дело с оценками вероятностей наступления событий, а не с их частотой. Например, врач-эксперт может оценить, у какой части инфарктников наблюдается боль в груди и на этом основании дать оценку условной вероятности Р(и.м.|б.г.). А оценку вероятности заболевания и.м. можно взять из публикуемой статистики. Если имеется некое множество n симптомов S и множество m возможных заболеваний D, то для вероятности каждого заболевания d нужно использовать правило Байеса в более общей форме: P(d|s1 Ù … Ù sk) = P(s1 Ù … Ù sk|d)P(d) / P(s1 Ù … Ù sk).
Вычисление этой вероятности достаточно трудоемко, так как для вычисления P (s 1 Ù … Ù sk) нужно предварительно вычислить произведение P (s 1 | s 2 … Ù sk) P (s 2 | s 3 … Ù sk) … P (sk). Однако если предположить, что некоторые симптомы независимы друг от друга, то объем вычислений снижается. Действительно, если si и sj независимы, то P (si) = P (si | sj), а отсюда следует, что P (si Ù sj) = P (si) P (sj). Если все симптомы независимы, то объем вычислений не будет существенно отличаться от случая учета одного симптома. Наконец, если независимость симптомов теоретически не подтверждается, эксперт может воспользоваться условной независимостью, опираясь на свой профессиональный опыт. Например, если в автомобиле не работает освещение и нет горючего, то эксперт может смело сказать, что эти симптомы независимы. Но если не работает освещение и машина не заводится, то эти симптомы нельзя считать независимыми, так как они могут быть вызваны разрядкой аккумулятора.
Таким образом, использование ТВ ставит перед разработчиками ЭС следующие проблемы: – можно предположить, что все данные (симптомы) независимы и использовать менее трудоемкие методы вычислений, но при этом достоверность результатов будет снижаться; – для получения более достоверных результатов нужно отслеживать зависимости данных друг от друга и оперативно обновлять соответствующую информацию, т.е. использовать значительно более трудоемкие методы.
Коэффициенты уверенности. Альтернативным подходом к оценке достоверности тех или иных заключений основан на так называемых правилах влияния, которые в общем случае можно представить так:
Коэффициент уверенности t принимает значения в диапазоне [-1, 1]. Если t = +1, это означает, что при соблюдении всех указанных в правиле условий эксперт абсолютно уверен в правильности заключения d. Если t = -1, это означает, что эксперт абсолютно уверен в ошибочности заключения. Значения t > 0 указывают на степень уверенности эксперта в правильности заключения, а значения t < 0 – степень уверенности в ошибочности заключения. Формулы указанного вида применяются для того, чтобы заменить громоздкие вычисления условных вероятностей P (d | s 1 Ù … Ù sk) легко вычисляемой приближенной оценкой и тем самым приблизить процесс принятия решений ЭС к способу принятия решений экспертом. Пусть CF (d, s 1 Ù … Ù sk Ù t 1 Ù … Ù tm) – коэффициент уверенности в достоверности заключения d, зависящий от коэффициентов уверенности в достоверности симптомов s 1,…, sk и значений фоновых условий t 1,…, tm; CF (si) и SF (tj) – коэффициенты уверенности в достоверности соответствующих симптомов и фоновых условий. Тогда вычисление коэффициента уверенности в достоверности заключения вычисляется по следующей формуле: CF(d,s1 Ù … Ù sk Ù t1 Ù … Ù tm) = t ´ min(CF(s1), …, CF(sk), SF(t1), …, SF(tm)).
НЕЧЕТКАЯ ЛОГИКА Нечеткая логика, опирающаяся на понятие нечетких множеств, представляет альтернативу вероятностному подходу к работе с мягкими знаниями. Отнесение конкретного объекта к определенной категории в большинстве случаев не может быть категоричным: объект может обладать частью необходимых признаков, частью не обладать ими. Сами признаки могут быть размыты, например, такие как «большой», «маленький», «красивый» и т.п. Предложенная американским логиком Заде теория нечетких множеств (fuzzy set theory) представляет формализм для формирования суждений о таких объектах и соответствующих им категориях. В классической теории множеств объект может принадлежать или не принадлежать некоторому множеству. Соответственно выражение а Î А может быть либо истинным, либо ложным. Такие множества получили название жестких. В противоположность им в нечетких множествах допускается степень принадлежности объекта множеству. Эта характеристика представляется функцией f (X), где Х – некоторый объект. Функция может принимать значения в интервале [0,1]. Нечеткие множества тесно связаны с субъективным восприятием реального мира различными индивидами. Это восприятие зависит от характерологических особенностей индивидуума, его профессии, материального положения и пр. Например, рассмотрим множество быстрых автомобилей. Для владельца «Жигулей» автомобиль, развивающий предельную скорость 160 км/час, в большинстве случаев будет казаться быстрым. Для владельца «Мерседеса» критерий быстрого автомобиля будет существенно иным. Итак, если f (X) = 1, то объект Х безусловно входит в множество, для которого определена функция f. При f (X) = 0 f (X) = 1 объект безусловно не входит в множество. Все промежуточные значения функции означают степень членства объекта в множестве. Таким образом, членами нечеткого множества становятся пары (объект, степень). Например множество быстрых автомобилей может быть определено так:
FAST - CAR = { (Порше, 0.9), (Мерседес, 0.8), …, (Жигули, 0.1)}.
Нечеткая логика тесно связана с нечеткими множествами. В ней высказывания и предикаты могут принимать значения в интервале [0, 1]. При этом значения 0 и 1 соответствуют false и true классической логики, а промежуточные – степени уверенности в истинности соответствующих высказываний или предикатов. Естественно, для вычисления значений формул (например, исчисления предикатов) были разработаны соответствующие правила. Вот они: ù f(X) = 1 – f(X); f(X) Ù g(X) = min (f(X), g(X)); f(X) Ú g(X) = max (f(X), g(X)). Приведенные операции обладают теми же свойствами, что и соответствующие операции классической логики: коммутативности, ассоциативности, взаимной дистрибутивности. Как и в классической логике к ним применим принцип композитивности, т.е. значения составных выражений вычисляются только по значениям выражений-компонентов.
Теория возможности
Нечеткая логика применяется тогда, когда мы имеем дело с нечетко очерченными понятиями. Однако, иногда мы просто не уверены в самих фактах, хотя последние являются вполне четкими. Например, на вопрос «Находится ли в настоящее время Иван в Москве?» мы можем не знать точный ответ. Здесь неопределенность заложена не в понятиях, а в самом высказывании. Теория возможностей как раз и применяется при обработке точно сформулированных вопросов, базирующихся на неточных знаниях. Рассмотрим пример.
Пусть в ящике находятся 10 шаров, причем нам известно, что несколько из них являются красными. Какова вероятность того, что из ящика будет вынут красный шар? Очевидно, она зависит от того, какое количество красных шаров подходит под определение «несколько». Определим нечеткое множество: SEVERAL = {(3, 0.2), (4, 0.6), (5, 1.0), (6, 1.0), (7, 0.6), (8, 0.3)}.
Здесь коэффициент, как и прежде означает субъективную степень членства объекта в множестве. Например, есть полная уверенность, что в множество SEVERAL попадают числа 5 и 6, а 3 и 8 – попадают с низкой степенью уверенности. Обозначим вероятность извлечения красного шара через P (RED). Тогда, разделив числа из множества на 10, получим следующее распределение вероятностей:
{(0.3, 0.2), (0.4, 0,6), (0.5, 1.0), (0,6, 1.0), (0.7, 0.6), (0.8, 0.3)}. ПЕРЦЕПТРО́Н (неверно: пер с ептрон, англ. per с eptron от лат. perсeptio — восприятие) Перцептрон – это математическая и компьютерная модель восприятия информации мозгом (кибернетическая модель мозга), предложенная Фрэнком Розенблаттом в 1957 году и реализованная в виде электронной машины «Марк-1» в 1960 году. Перцептрон стал одной из первых моделей нейросетей, а «Марк-1» — первым в мире нейрокомпьютером. Несмотря на свою простоту, перцептрон способен обучаться и решать довольно сложные задачи.
Перцептрон состоит из трёх типов элементов: поступающие от сенсоров сигналы передаются ассоциативным элементам, а затем реагирующим элементам. Таким образом, перцептрон позволят создать набор «ассоциаций» между входными стимулами и необходимой реакцией на выходе. В биологическом плане это соответствует преобразованию, например, зрительной информации в физиологический ответ от двигательных нейронов. Согласно современной терминологии, перцептроны могут быть классифицированы как искусственные нейронные сети: 1. с одним скрытым слоем; 2. с пороговой передаточной функцией; 3. с прямым распространением сигнала. На фоне «романтизма» нейронных сетей, в 1969 году вышла книга М. Минского и С. Паперта, которая показала принципиальные ограничения перцептронов. Это привело к смещению интереса исследователей искусственного интеллекта в противоположную от нейросетей область — символьных вычислений. Кроме того, из-за сложности математического анализа перцептронов, а также отсутствия общепринятой терминологии, возникли различные неточности и заблуждения. Впоследствии интерес к нейросетям, и в частности, работам Розенблатта, возобновился. В 1943 году в своей статье «Логическое исчисление идей, относящихся к нервной активности» У. Мак-Каллок и У. Питтс предложили понятие искусственной нейронной сети. В частности, ими была предложена модель искусственного нейрона. Д. Хебб в работе «Организация поведения» 1949 года описал основные принципы обучения нейронов. Эти идеи несколько лет спустя развил американский нейрофизиолог Фрэнк Розенблатт. Он предложил схему устройства, моделирующего процесс человеческого восприятия, и назвал его перцептроном. Перцептрон передавал сигналы от фотоэлементов, представляющих собой сенсорное поле, в блоки электромеханических ячеек памяти. Эти ячейки соединялись между собой случайным образом в соответствии с принципами коннективизма. В 1957 году в Корнелльской Лаборатории Аэронавтики успешно были завершено моделирование работы перцептрона на компьютере IBM 704, а два года спустя, 23 июня 1960 года в Корнелльском университете, был продемонстрирован первый нейрокомпьютер — «Марк-1», который был способен распознавать некоторые из букв английского алфавита.
Чтобы «научить» перцептрон классифицировать образы, был разработан специальный итерационный метод обучения проб и ошибок, напоминающий процесс обучения человека. Кроме того, при распознании той или иной буквы перцептрон мог выделять характерные особенности буквы, статистически чаще встречающиеся, чем малозначимые отличия в индивидуальных случаях. Тем самым перцептрон был способен обобщать буквы, написанные различным образом (почерком), в один обобщённый образ. Однако возможности перцептрона были ограниченными: машина не могла надежно распознавать частично закрытые буквы, а также буквы иного размера, расположенные со сдвигом или поворотом, нежели те, которые использовались на этапе ее обучения. Отчёт по первым результатам появился ещё в 1958 году — тогда Розенблаттом была опубликована статья «Перцептрон: Вероятная модель хранения и организации информации в головном мозге». Но подробнее свои теории и предположения относительно процессов восприятия и перцептронов он описывает 1962 году, в книге «Принципы нейродинамики: Перцептроны и теория механизмов мозга». В книге он рассматривает не только уже готовые модели перцептрона с одним скрытым слоем, но и многослойных перцептронов с перекрёстными (третья глава) и обратными (четвёртая глава) связями. В книге также вводится ряд важных идей и теорем, например, доказывается теорема сходимости перцептрона. Марвин Минский и Сеймур Паперт опубликовали в 1969 г. книгу «Перцептроны», где математически показали, что перцептроны, подобные розенблаттовским, принципиально не в состоянии выполнять многие из тех функций, которые приписывал перцептронам Розенблатт. Эта книга существенно повлияла на пути развития науки об искусственном интеллекте, так как переместила научный интерес и субсидии правительственных организаций США на другое направление исследований — символьный подход в ИИ. В 80-х годах интерес к кибернетике возродился, так как сторонники символьного подхода в ИИ так и не смогли подобраться к решению вопросов о «Понимании» и «Значении», из-за чего машинный перевод и техническое распознавание образов до сих пор обладает неустранимыми недостатками. Сам Минский публично выразил сожаление, что его выступление нанесло урон концепции перцептронов, хотя книга лишь показывала недостатки отдельно взятого устройства и некоторых его вариаций. Но в основном ИИ стал синонимом символьного подхода, который выражался в составлении все более сложных программ для компьютеров, моделирующих сложную деятельность человеческого мозга. ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ ПЕРЦЕПТРОНОВ Серьезное ознакомление с теорией перцептронов требует знания базовых определений и теорем, совокупность которых и представляет собой базовую основу для всех последующих видов искусственных нейронных сетей. Но как минимум необходимо, понимание хотя бы с точки зрения теории сигналов, являющиеся оригинальным, то есть описаное автором перцептрона Ф. Розенблаттом. Описание на основе сигналов
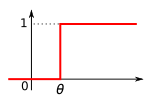
Пороговая функция, реализуемая простыми S- и A-элементами.
Пороговая функция, реализуемая простым R-элементом. Для начала определим составные элементы перцептрона, которые являются частными случаями искусственного нейрона с пороговой передаточной функцией.
Если на выходе любого элемента мы получаем 1, то говорят, что элемент активен или возбуждён. Все рассмотренные элементы называются простыми, так как они реализуют скачкообразные функции. Розенблатт утверждал также, что для решения более сложных задач могут потребоваться другие виды функций, например, линейная. В результате Розенблатт ввёл следующие определения:
|
|||||||||||||
|
|
Последнее изменение этой страницы: 2021-03-10; просмотров: 128; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.117.183.150 (0.041 с.) |