Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Методические указания к расчетно-графической работе №1
1.2.1 Сжатие информации методом Шеннона-Фано. В качестве примера использования кода Шеннона – Фано рассмотрим порядок сжатия сообщения: «ИНН 637322757237». На первом этапе построения кода Шеннона – Фано формируется таблица абсолютных частот символов (таблица 1.2).
Таблица 1.2 – Этап определение абсолютной частоты символов
Заданный текст содержит избыточность, которая определяется по формуле:
где H – энтропия сообщения; n – длина кодовой комбинации при равномерном кодировании. Энтропия сообщения вычисляется по формуле: где N – объем алфавита источника (для русского алфавита N =33); pi – относительная частота (вероятность) появления символа в сообщении. Относительная частота встречаемости символа определяется как отношение абсолютной частоты появления символа в сообщении к общей длине сообщения (числу символов в сообщении):
где ωi – абсолютная частота встречаемости i-ого символа алфавита источника; m – число символов в сообщении. В данном случае энтропия сообщения равна:
H=2,781(бит/символ),
где
При необходимости расчёта логарифма по основанию два через логарифм по основанию десять можно воспользоваться соотношением:
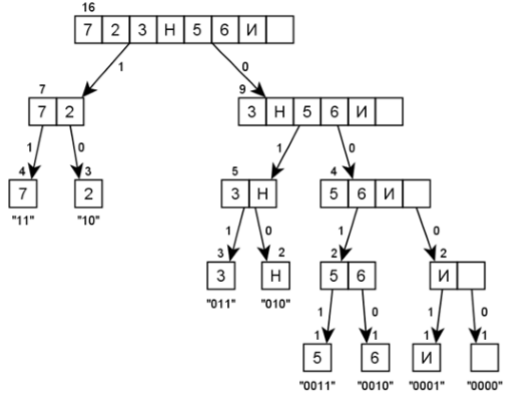
При использовании равномерного кода (например, СР-1251) длина кодовой комбинации определяется так:
В данном примере
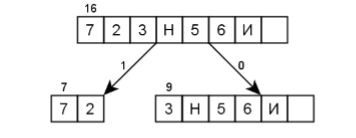
Для получения кодовых комбинаций строится кодовое дерево. При построении кода Шеннона-Фано дерево строится от корня к листьям (в отличие от настоящего дерева здесь корень располагается вверху, а листья – внизу). В качестве корня, используется множество всех символов алфавита сообщения (рисунок 1.1), упорядоченное по частоте встречаемости символов. Число сверху таблицы равно суммарной частоте символов в исходном сообщении (суммарное число символов в сообщении).
Рисунок 1.1 – Исходное сообщение
Затем множество символов делят на два подмножества так, чтобы новые множества имели равные, насколько это возможно, суммарные частоты встречаемости входящих в них символов. (Например, вес 11 желательно разделить на два подмножества 5 и 6. Если есть возможность разделения на 5 и 6, то деление на 4 и 7 будет ошибочным). Эти подмножества соединяются с корнем дерева ветвями, становясь потомками. Левая ветвь дерева обозначается символом 1, а правая ветвь – символом 0 (рисунок 1.2). Полученные подмножества также рекурсивно делятся до тех пор, пока не будут сформированы листья дерева – отдельные символы сообщения (рисунок 1.3).
Рисунок 1.2 – Построение ветвей дерева
Рисунок 1.3 – Дерево по методу Шеннона-Фано
Кодовые комбинации (на предыдущем рисунке они указаны в кавычках под соответствующими листьями) получаются при движении от корня дерева к кодируемому символу-листу путём сбора бит, присвоенных пройдённым ветвям дерева. Запись кодовой комбинации ведут в направлении от старших разрядов к младшим. При кодировании символа «3» сначала следует пройти по правой ветви к множеству {3, Н, 5, 6, И, Пробел} (к кодовой комбинации добавляется бит 0). Затем нужно пройти по левой ветви к множеству {3, Н} (к кодовой комбинации добавляется бит 1). Дальше необходимо пройти по левой ветви, чтобы достичь листа «3». Таким образом, получена кодовая комбинация «011». При декодировании биты считываются из входного потока и используются, как указатели направления движения по кодовому дереву от корня к искомому листу. При достижении листа найденный символ записывается в выходной поток, а движение по кодовому дереву снова начинают от корня.
Для декодирования комбинации «010» из потока считывается бит 0, следовательно, нужно пройти по правой ветви от корня дерева к узлу {3, Н, 5, 6, И, Пробел}. Следующий бит единичный, что требует пройти по левой ветви к множеству {3, Н}. Далее следующий бит 0 приводит декодер по правой ветви к листу «Н». В таблице1.3 приведены все разрешённые комбинации полученного кода Шеннона-Фано. Это так называемый словарь сообщения. Он передаётся на приёмную сторону вместе с архивом.
Таблица 1.3 – Разрешенные комбинации полученного кода
Закодированное сообщение (архив) будет иметь вид:
000101001000000010011110111010110011111001111
Общая длина закодированного сообщения составляет 45 бит. Средняя длина кодовой комбинации равна (напомним, что число символов в сообщении – 16):
Избыточность сообщения после применения кода Шеннона-Фано снизилась до значения:
Несложно убедиться, что применение кода Шеннона-Фано позволило существенно уменьшить избыточность сообщения. При равномерном кодировании рассмотренного сообщения с помощью кодовой таблицы CP-1251 пришлось бы передать 128 бит. 1.2.2 Сжатие информации методом Хаффмана. Построение кодового дерева по методу Хаффмана начинают с того, что формируют набор листьев, имеющих веса, равные частотам появления символов в исходном (сжимаемом) сообщении. Листья ранжируют в соответствии с их весами (записывают веса справа налево в порядке их возрастания). Запись листьев желательно вести в одну строчку. Затем выбирают пару узлов (листьев), имеющих наименьший вес, которые соединяют дугами с новым узлом, вес которого равен сумме весов присоединённых к нему потомков. Образовавшийся узел называется родителем. Новый узел (родитель) участвует в дальнейших построениях дерева. Процедура объединения свободных узлов ведётся до тех пор, пока не останется единственный узел (корень дерева). В отличие от метода Шеннона-Фано построение дерева ведётся не сверху-вниз, а снизу-вверх. Предположим, что требуется выполнить сжатие фразы «Проездной 7977977». Ниже приведена таблица абсолютных частот использованных символов в заданном сообщении.
Таблица 1.4 – Этап определение абсолютной частоты символов
В соответствии с построенным деревом составим словарь замен (таблица 1.5).
Таблица 1.5 – Словарь замен
Закодированное сообщение Проездной 7977977 будет иметь вид:
011101101010101010000110010101000100001110011111001111.
Общая длина закодированного сообщения составляет 54 бит. Энтропия сообщения имеет значение:
Н = 3,17 бит/символ.
Средняя длина кодовой комбинации составляет n = 3, 177 бит/символ. Примечание. 1 Кодовые комбинации по методу Шеннона-Фано и Хаффмана могут совпадать. 2 При формировании листьев по методу Шеннона-Фано, необходимо разделить веса ветвей дерева максимально равномерно. 3 Выбор ветвей со значением «0» и «1» выбираются по принципу: большему весу присваивается ветвь со значением «1», меньшему – «0». При совпадении комбинаций по методу Шеннона-фано с Хаффмана это условие можно не учитывать.
Рисунок 1.4 – Дерево кода по методу Хаффмана
1.3 Контрольные вопросы 1 В чем отличие метода Шеннона-Фано от Хаффмана? 2 Что такое оптимальный код? 3 Поясните алгоритм оптимального кодирования Шеннона-Фано. 4 Поясните алгоритм оптимального кодирования метода Хаффмана. 5 Понятие избыточности. Как осуществляется расчет избыточности? 6 Что такое энтропия? 7 Как создать словарь имен? 8 Что такое сжатие алфавита? 9 Что такое префиксные коды? 10 Сколько требуется двоичных знаков для записи кодированного сообщения?
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2021-01-08; просмотров: 184; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.142.40.43 (0.017 с.) |
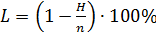 , (1.1)
, (1.1)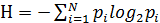 , (1.2)
, (1.2) , (1.3)
, (1.3)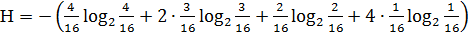 ,
,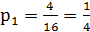 – относительная частота появления символа «7»;
– относительная частота появления символа «7»;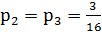 – относительная частота появления символов «2» и «3»;
– относительная частота появления символов «2» и «3»;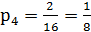 – относительная частота появления символа «Н»;
– относительная частота появления символа «Н»;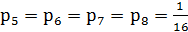 – относительная частота появления символов «5», «6», «И», Пробел.
– относительная частота появления символов «5», «6», «И», Пробел.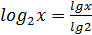 . (1.4)
. (1.4) , (1.5)
, (1.5) – функция округления аргумента до ближайшего целого значения, не меньшего, чем x.
– функция округления аргумента до ближайшего целого значения, не меньшего, чем x. бита. Избыточность сообщения при кодировании равномерным кодом равна:
бита. Избыточность сообщения при кодировании равномерным кодом равна: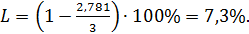
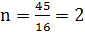 ,813 (бит/символ).
,813 (бит/символ).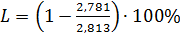 =1,13%.
=1,13%. 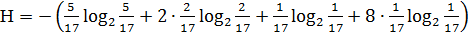 ,
,