Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Сравнение средних значений. Однофакторный дисперсионный анализ
Сравнение средних значений – это мощное аналитическое средство выявления статистически достоверных закономерностей. Суть подхода заключается в том, чтобы сравнить два средних значения по определенной переменной для разных выборок на предмет достоверности их различия.
Так, например, мы получили следующие результаты анализа. Среднее значение переменной, отражающей ответы студентов на вопрос «Связан ли у Вас творческий процесс с негативными переживаниями», равно 2,94. Измеряя средние значения отдельно для выборки студентов и выборки студенток, мы получили значения 2,89 и 2,96. Имеем ли мы право на этом основании сделать вывод об отсутствии гендерного фактора в изучаемом вопросе (наличие негативных переживаний, связанных с творчеством)? Сделать статистически достоверные выводы о различии позволяют специальные статистические методы. Прежде всего, необходимо определить, какой группой методов можно пользоваться. Выделяют методы параметрической (основанной на нормальном распределении) и непараметрической статистики. Давайте вначале рассмотрим группу методов параметрической статистики. Параметрические методы. T -тест для независимых выборок. Наиболее часто в исследованиях используется t-критерий Стьюдента. Основное требование к данным для применения этого критерия – представление переменных, по которым сравниваются выборки, в метрической шкале измерения. Если есть сомнения в соответствии этому требованию, то следует воспользоваться непараметрическими методами. Достоинство T-теста состоит в том, что он может быть применен и по отношению к малым выборкам (меньше 100) в том случае, если переменные нормально распределены (внутри групп), а дисперсии наблюдений в группах не слишком различны. Сравнение средних значений с помощью T-теста осуществляется следующим образом. Рассчитывается t-критерий, зависящий от объемов выборок, разброса данных. Затем найденное для данных значение t сравнивается с t критическим, которое определяется исходя из уровня заданной исследователем статистической достоверности (P). Обычно P принимается равным 0,05. Если t больше t критического, то делается вывод о статистически достоверном различии средних значений.
В пакетах статистических программ поступают несколько иным образом. Здесь рассчитывается t-критерий и критический уровень статистической значимости. По показателям этого уровня (обычно если он меньше 0,05) делается вывод о достоверности различий. Давайте последовательно проделаем необходимые этапы сравнения средних для разных выборок. Войдите в меню «Statistics» и выберите «Basic Statistics/Tables». Появится следующее диалоговое меню (рис. 3.1).
Рис. 3.1. Диалоговое меню Basic Statistics/Tables
Выберите статистический метод анализа «T-test, independent, by groups» – сравнение средних значений с помощью T-теста для двух независимых выборок. В появившемся окне задайте переменные для анализа (рис. 3.2).
Рис. 3.2. Диалоговое окно задания переменных для метода «t-test, independent, by groups»
В этом методе вам необходимо отметить две переменные: зависимую (dependent) и группирующую (grouping). Группирующую переменную мы выбираем V12_1 – пол респондентов. В качестве зависимой переменной берется метрическая переменная, относительно которой сравниваются средние значения. Здесь мы устанавливаем в качестве группирующей переменную V9 – степень связи творческого процесса с негативными переживаниями. Теперь T-тест будет сравнивать средние значения переменной V9 для двух групп респондентов, образованных категориями группирующей переменной V12_1 - male и female. Нажмите «OK». Перед вами появится диалоговое меню (рис. 3.3).
Рис. 3.3. Диалоговое меню метода «T-test, independent, by groups»
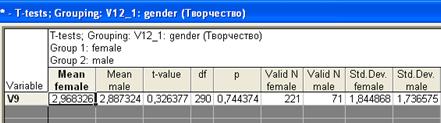
Нажмите «Summary: T-tests». В результате будет выведена таблица с необходимыми статистическими результатами анализа (рис 3.4).
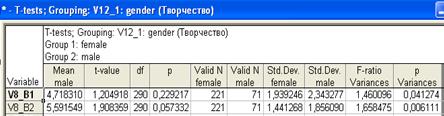
Рис. 3.4. Таблица с результатами T-теста
Наиболее значимые расчетные характеристики, на которые следует обратить внимание: «Mean female» и «Mean male» – средние значения переменной V9 для женской и мужской выборок; t-value – рассчитанное для данных выборок значение t-критерия; df – число степеней свободы; p-уровень статистической значимости t-критерия (значение p>0,05 указывает на то, что разность между средними значениями случайна); p-уровень равен вероятности, при которой можно ошибочно отвергнуть гипотезу о равенстве средних двух выборок, когда в действительности эта гипотеза имеет место;
Valid N femail –- объем (количество респондентов) выборки женщин; Valid N mail – объем выборки мужчин; F-ratio Variances – F-критерий, который используется для проверки предположения о равенстве дисперсий между сравниваемыми выборками, что является условием применения Т-теста; p Variances – если p < 0,05, то условия применимости t-критерия не выполнены и следует использовать непараметрические альтернативы t-критерия. Применительно к конкретному анализируемому случаю можно сказать следующее. Исходя из того, что p Variances > 0,05, считаем Т-тест применимым в данном случае. Значимость p = 0,74 больше 0,05. Делаем вывод, что между студентами и студентками по изучаемому признаку нет статистически достоверных различий. Теперь давайте выполним Т-тест сразу для списка зависимых переменных. Отметьте в диалоговом окне группу переменных V8_B1 – V8-B12 (интерес студентов к развитию определенных творческих способностей и компетентности). Группирующую переменную мы выбираем V12_1 – пол респондентов. Нажмите «Summary: T-tests». В результате будет выведена таблица с необходимыми статистическими результатами анализа (рис. 3.5).
Рис. 3.5. Таблица результатов выполнения T-теста В появившейся таблице результатов красным цветом выделены статистически достоверные различия по соответствующим переменным, что удобно при анализе большого количества переменных. Интерес студентов мужского и женского пола статистически достоверно различается к «умению импровизировать», «умению видеть уникальность мира, людей», «знанию техник творчества». Настроить параметры выделения красным цветом можно в «Options» посредством задания «p-level for highlightin». Непараметрические методы. Эта группа методов специально создана для того, чтобы с помощью определенных статистических процедур обрабатывать данные "низкого качества" из выборок малого объема с переменными, про распределение которых мало что или вообще ничего не известно. Говоря более специальным языком, непараметрические методы не основываются на оценке параметров (таких как среднее или стандартное отклонение) при описании выборочного распределения интересующей величины. Поэтому данные методы иногда также называются свободными от параметров. Непараметрическими альтернативами t-критерию для независимых выборок являются критерий серий Вальда–Вольфовица, U-критерий Манна–Уитни и двухвыборочный критерий Колмогорова–Смирнова. Рассмотрим более подробно применение критерия Манна–Уитни, который позволяет установить различия между двумя независимыми выборками для зависимой порядковой переменной. Критерий Манна–Уитни используют и в тех случаях, когда можно использовать t-критерий. Однако он менее чувствителен к различиям (менее мощный), чем t-критерий. Для анализа данных полученных с помощью нашей анкеты критерий Манна–Уитни будет правильно применить, например, к порядковым переменным: V6_1 – V6_4. В меню «Statistics» выберите из списка методов «Nonparametrics», затем – «Comparing two independent samples» (рис. 3.6).
Рис. 3.6. Меню методов непараметрической статистики В открывшемся диалоговом окне введите значения зависимой (V6_1 – V6_4) и группирующей (V12_1) переменных. Чтобы выполнить сравнение средних с помощью критерия Манна–Уитни, щелкните мышью по «Mann–Whitney U test». В результате будет выведена следующая таблица результатов (рис. 3.7).
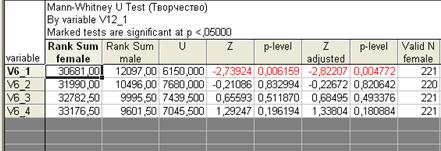
Рис. 3.7. Таблица результатов сравнения средних значений по критерию Манна–Уитни
Красным цветом в таблице выделена строка, относящаяся к переменной V6_1. Уровень статистической значимости (p-level) для этой переменной существенно меньше 0,05, что позволяет сделать вывод о наличии гендерных различий. Для остальных переменных гендерные различия не являются статистически достоверными. Что делать, если группирующая переменная имеет количество категорий больше, чем два? В этом случае необходимо специально определить, какие категории переменной следует взять для формирования групп, между которыми будут производиться сравнения. Например, переменная V12_2 (курс, на котором обучается студент) имеет пять категорий. В поле «Codes for groups» следует вписать названия кодов тех категорий, которые будут взяты для сравнения (рис. 3.8).
Рис. 3.8. Диалоговое окно «Comparing two independent samples»
|
|||||||
|
|
Последнее изменение этой страницы: 2021-01-08; просмотров: 209; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.219.63.90 (0.016 с.) |