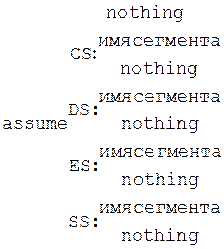Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Стандартные директивы сегментации
Для задания сегментов/секций в тексте программы наряду с упрощенными директивами (.STACK,.DATA,.CODE) может также использоваться директива SEGMENT, которая определяет начало любого сегмента/секции. Синтаксис: name SEGMENT align combine dim ‘class’ ... name ENDS Директива ENDS определяет конец сегмента. Физически сегмент представляет собой область памяти, занятую командами и (или) данными, адреса которых вычисляются относительно значения в соответствующем сегментном регистре. Функциональное назначение сегмента несколько шире, чем простое разбиение программы на блоки кода, данных и стека. Сегментация является частью более общего механизма, связанного с концепцией модульного программирования. Она предполагает унификацию оформления объектных модулей, создаваемых компилятором, в том числе с разных языков программирования. Это позволяет объединять программы, написанные на разных языках. Именно для реализации различных вариантов такого объединения и предназначены операнды в директиве SEGMENT. - Атрибут выравнивания сегмента (тип выравнивания) align сообщает компоновщику о том, что нужно обеспечить размещение начала сегмента на заданной границе. Это важно, поскольку при правильном выравнивании доступ к данным в процессорах i8086 выполняется быстрее. Допустимые значения этого атрибута следующие: BYTE — выравнивание не выполняется. Сегмент может начинаться с любого адреса памяти; WORD — сегмент начинается по адресу, кратному двум, то есть последний (младший) значащий бит физического адреса равен 0 (выравнивание на границу слова); DWORD — сегмент начинается по адресу, кратному четырем, то есть два последних (младших) значащих бита равны 0 (выравнивание на границу двойного слова); PARA — сегмент начинается по адресу, кратному 16, то есть последняя шестнадцатеричная цифра адреса должна быть 0h (выравнивание на границу параграфа); PAGE — сегмент начинается по адресу, кратному 256, то есть две последние шестнадцатеричные цифры должны быть 00h (выравнивание на границу страницы размером 256 байт); MEMPAGE — сегмент начинается по адресу, кратному 4 Кбайт, то есть три последние шестнадцатеричные цифры должны быть 000h (адрес следующей страницы памяти размером 4 Кбайт); По умолчанию тип выравнивания имеет значение PARA.
- Атрибут комбинирования сегментов (комбинаторный тип) combine сообщает компоновщику, как нужно комбинировать сегменты различных модулей, имеющие одно и то же имя. По умолчанию атрибут комбинирования принимает значение PRIVATE. Значениями атрибута комбинирования сегмента могут быть: PRIVATE — сегмент не будет объединяться с другими сегментами с тем же именем вне данного модуля; PUBLIC — заставляет компоновщик соединить все сегменты с одинаковым именем. Новый объединенный сегмент будет целым и непрерывным. Все адреса (смещения) объектов, а это могут быть, в зависимости от типа сегмента, команды или данные, будут вычисляться относительно начала этого нового сегмента; COMMON — располагает все сегменты с одним и тем же именем по одному адресу. Все сегменты с данным именем будут перекрываться и совместно использовать память. Размер полученного в результате сегмента будет равен размеру самого большого сегмента; AT xxxx — располагает сегмент по абсолютному адресу параграфа (параграф — объем памяти, кратный 16, поэтому последняя шестнадцатеричная цифра адреса параграфа равна 0). Абсолютный адрес параграфа задается выражением хххx. Компоновщик располагает сегмент по заданному адресу памяти (это можно использовать, например, для доступа к видеопамяти или области ПЗУ), учитывая атрибут комбинирования. Физически это означает, что сегмент при загрузке в память будет расположен, начиная с этого абсолютного адреса параграфа, но для доступа к нему в соответствующий сегментный регистр должно быть загружено заданное в атрибуте значение. Все метки и адреса в определенном таким образом сегменте отсчитываются относительно заданного абсолютного адреса; seg_name SEGMENT AT 0FE00h ;располагает seg_name по адресу 0FE00h STACK — определение сегмента стека. Заставляет компоновщик соединить все одноименные сегменты и вычислять адреса в этих сегментах относительно регистра SS. Комбинированный тип STACK (стек) аналогичен комбинированному типу PUBLIC, за исключением того, что регистр SS является стандартным сегментным регистром для сегментов стека. Регистр SP устанавливается на конец объединенного сегмента стека. Если не указано ни одного сегмента стека, компоновщик выдаст предупреждение, что стековый сегмент не найден. Если сегмент стека создан, а комбинированный тип STACK не используется, программист должен явно загрузить в регистр SS адрес сегмента (подобно тому, как это делается для регистра DS).
- Атрибут размера сегмента dim. Для процессоров i80386 и выше сегменты могут быть 16- или 32-разрядными. Это влияет прежде всего на размер сегмента и порядок формирования физического адреса внутри него. Атрибут может принимать следующие значения: USE16 — это означает, что сегмент допускает 16-разрядную адресацию. При формировании физического адреса может использоваться только 16-разрядное смещение. Соответственно, такой сегмент может содержать до 64 Кбайт кода или данных; USE32 — сегмент будет 32-разрядным. При формировании физического адреса может использоваться 32-разрядное смещение. Поэтому такой сегмент может содержать до 4 Гбайт кода или данных. - Атрибут класса сегмента (тип класса) ‘class’ — это заключенная в кавычки строка, помогающая компоновщику определить соответствующий порядок следования сегментов при сборке программы из сегментов нескольких модулей. Компоновщик объединяет вместе в памяти все сегменты с одним и тем же именем класса (имя класса, в общем случае, может быть любым, но лучше, если оно будет отражать функциональное назначение сегмента). Типичным примером использования имени класса является объединение в группу всех сегментов кода программы (обычно для этого используется класс «code»). С помощью механизма типизации класса можно группировать также сегменты инициализированных и неинициализированных данных. Все сегменты сами по себе равноправны, так как директивы SEGMENT и ENDS не содержат информации о функциональном назначении сегментов. Для того чтобы использовать их как сегменты кода, данных или стека, необходимо предварительно сообщить транслятору об этом, для чего используют специальную директиву ASSUME. Синтаксис:
Эта директива сообщает транслятору о том, какой сегмент к какому сегментному регистру привязан. В свою очередь, это позволит транслятору корректно связывать символические имена, определенные в сегментах. Привязка сегментов к сегментным регистрам осуществляется с помощью операндов этой директивы, в которых имя_сегмента должно быть именем сегмента, определенным в исходном тексте программы директивой SEGMENT или ключевым словом nothing. Если в качестве операнда используется только ключевое слово nothing, то предшествующие назначения сегментных регистров аннулируются, причем сразу для всех шести сегментных регистров. Но ключевое слово nothing можно использовать вместо аргумента имя сегмента; в этом случае будет выборочно разрываться связь между сегментом с именем имя_сегмента и соответствующим сегментным регистром. Директива SEGMENT может применяться с любой моделью памяти. При использовании директивы SEGMENT с моделью flat потребуется указать компилятору на то, что все сегментные регистры устанавливаются в соответствии с моделью памяти flat. Это можно сделать при помощи директивы ASSUME: ASSUME CS:FLAT, DS:FLAT, SS:FLAT, ES:FLAT, FS:ERROR, GS:ERROR Регистры FS и GS программами не используются, поэтому для них указывается атрибут ERROR.
МАКРОКОМАНДЫ
При программировании достаточно серьезной задачи, появляются повторяющиеся участки кода. Они могут быть небольшими, а могут занимать и достаточно много места. В последнем случае эти фрагменты будут существенно затруднять чтение текста программы, снижать ее наглядность, усложнять отладку и служить неисчерпаемым источником ошибок. В языке ассемблера есть несколько средств, решающих проблему дублирования участков программного кода. К ним относятся: · макроассемблер; · механизм процедур; · механизм прерываний. Макрокоманда представляет собой строку, содержащую некоторое символическое имя — имя макрокоманды, предназначенную для того, чтобы быть замещенной одной или несколькими другими строками. Имя макрокоманды может сопровождаться параметрами. Для написания макрокоманды вначале необходимо задать ее шаблон-описание, который называют макроопределением. Синтаксис макроопределения следующий: имя_макрокоманды macro список_формальных_аргументов тело макроопределения endm Макроопределение обрабатывается транслятором особым образом. Для того чтобы использовать описанное макроопределение в нужном месте программы, оно должно быть активизировано с помощью макрокоманды указанием следующей синтаксической конструкции: имя_макрокоманды список_фактических_аргументов Результатом применения данной синтаксической конструкции в исходном тексте программы будет ее замещение строками из конструкции тела макроопределения. Но это не простая замена. Обычно макрокоманда содержит некоторый список аргументов — список_фактических_аргументов, которыми корректируется макроопределение. Места в теле макроопределения, которые будут замещаться фактическими аргументами из макрокоманды, обозначаются с помощью так называемых формальных аргументов. Таким образом, в результате применения макрокоманды в программе формальные аргументы в макроопределении замещаются соответствующими фактическими аргументами; в этом и заключается учет контекста. Процесс такого замещения называется макрогенерацией, а результатом этого процесса является макрорасширение. Макрокоманды в ассемблере схожи с директивой #define в языке Си, но, в отличие от нее, могут принимать аргументы. Есть три варианта размещения макроопределений: · в начале исходного текста программы, до кода и данных с тем, чтобы не ухудшать читаемость программы. Этот вариант следует применять в случаях, если определяемые макрокоманды актуальны только в пределах одной этой программы;
· в отдельном файле. Этот вариант подходит при работе над несколькими программами одной проблемной области. Чтобы сделать доступными эти макроопределения в конкретной программе, необходимо в начале исходного текста этой программы записать директиву include имя_файла, например: .586 .model flat, stdcall include show.inc;сюда вставляется текст файла show.inc · в макробиблиотеке. Универсальные макрокоманды, которые используются практически во всех программах целесообразно записать в так называемую макробиблиотеку. Сделать актуальными макрокоманды из этой библиотеки можно также с помощью директивы include. Недостаток этого и предыдущего способов в том, что в исходный текст программы включаются абсолютно все макроопределения. Для исправления ситуации можно использовать директиву purge, в качестве операндов которой через запятую перечисляются имена макрокоманд, которые не должны включаться в текст программы. К примеру: include iomac.inc purge outstr,exit В данном случае в исходный текст программы перед началом трансляции MASM вместо строки include iomac.inc вставит строки из файла iomac.inc. Но вставленный текст будет отличаться от оригинала тем, что в нем будут отсутствовать макроопределения outstr и exit. Каждый фактический аргумент представляет собой строку символов, для формирования которой применяются следующие правила: 1. Строка может состоять: · из последовательности символов без пробелов, точек, запятых, точек с запятой; · из последовательности любых символов, заключенных в угловые скобки: <...>. В этой последовательности можно указывать как пробелы, так и точки, запятые, точки с запятыми. 2. Для того чтобы указать, что некоторый символ внутри строки, представляющей фактический параметр, является собственно символом, а не чем-то иным, например, некоторым разделителем или ограничивающей скобкой, применяется специальный оператор «!». Этот оператор ставится непосредственно перед описанным выше символом, и его действие эквивалентно заключению данного символа в угловые скобки. 3. Если требуется вычисление в строке некоторого константного выражения, то в начале этого выражения нужно поставить знак %: %константное_выражение — значение константное_выражение вычисляется и подставляется в текстовом виде в соответствии с текущей системой счисления. В процессе генерации макрорасширения транслятор ассемблера ищет в тексте тела макроопределения последовательности символов, совпадающие с теми последовательностями символов, из которых состоят формальные параметры. После обнаружения такого совпадения формальный параметр из тела макроопределения замещается соответствующим фактическим параметром из макрокоманды. Этот процесс называется подстановкой аргументов. В общем случае список формальных аргументов содержит не только перечисление формальных элементов через запятую, но и некоторую дополнительную информацию. Полный синтаксис формального аргумента следующий:
имя_формального_аргумента[: тип] где тип может принимать значения: · REQ – требуется обязательное явное задание фактического аргумента при вызове макрокоманды; · =<любая_строка> — если аргумент при вызове макрокоманды не задан, то в соответствующие места в макрорасширении будет вставлено значение по умолчанию, соответствующее значению любая_строка. Символы, входящие в любая_строка, должны быть заключены в угловые скобки. Но не всегда ассемблер может распознать в теле макроопределения формальный аргумент. Это, например, может произойти в случае, когда он является частью некоторого идентификатора. В этом случае последовательность символов формального аргумента отделяют от остального контекста с помощью специального символа &. Этот прием часто используется для задания модифицируемых идентификаторов и кодов операций. Например, .686p .model flat, stdcall def_table macro t:REQ, len:=<1> tabl_&t d&t len dup(5) endm .data def_table d, 10 def_table b .code main proc mov al, [tabl_b] mov ah, [tabl_b+1] mov ebx, [tabl_d] ret main endp end main После трансляции текста программы, содержащего строки секции данных, получится def_table d, 10 ;tabl_d dd 10 dup(5) def_table b ;tabl_b db 1 dup(5) Заметим, что строка программы mov ah, [tabl_b+1] поместит в ah число отличное от 5, поскольку память для tabl_b распределена только под 1 элемент массива длиной 1 байт со значением 5. Символ & можно применять и для распознавания формального аргумента в строке, заключенной в кавычки "". Если тело макроопределения содержит метку или имя в директиве резервирования и инициализации данных, и в программе данная макрокоманда вызывается несколько раз, то в процессе макрогенерации возникнет ситуация, когда в программе один идентификатор будет определен несколько раз, что, естественно, будет распознано транслятором как ошибка. Для выхода из подобной ситуации применяют директиву local, которая имеет следующий синтаксис: local список_идентификаторов Эту директиву необходимо задавать непосредственно за заголовком макроопределения. Результатом работы этой директивы будет генерация в каждом экземпляре макрорасширения уникальных имен для всех идентификаторов, перечисленных в список_идентификаторов. Эти уникальные имена имеют вид??хххх, где хххх — шестнадцатеричное число. Для первого идентификатора в первом экземпляре макрорасширения хххх=0000, для второго — хххх=0001 и т. д. Контроль за правильностью размещения и использования этих уникальных имен берет на себя ассемблер. Для примера использования макроопределений рассмотрим программу вывода имени в диалоговое окно. .686P .MODEL FLAT, STDCALL PrintName macro Name local STR1, STR2, METKA jmp METKA STR1 DB "Программа",0 STR2 DB "Меня зовут: &Name ",0 METKA: PUSH 0 PUSH OFFSET STR1 PUSH OFFSET STR2 PUSH 0 CALL MessageBoxA@16 endm Init macro EXTERN MessageBoxA@16:NEAR endm Init .CODE START: PrintName <Лена> PrintName <Таня> PrintName <Алёша> RET END START При использовании макроопределений код программы становится более читаемым. Функционально макроопределения похожи на процедуры. Сходство их в том, что и те, и другие достаточно один раз где-то описать, а затем вызывать их многократно специальным образом. Различия макроопределений и процедур в зависимости от целевой установки можно рассматривать и как достоинства, и как недостатки: · в отличие от процедуры, текст которой неизменен, макроопределение в процессе макрогенерации может меняться в соответствии с набором фактических параметров. При этом коррекции могут подвергаться как операнды команд, так и сами команды. Процедуры в этом отношении менее гибки; · при каждом вызове макрокоманды ее текст в виде макрорасширения вставляется в программу. При вызове процедуры микропроцессор осуществляет передачу управления на начало процедуры, находящейся в некоторой области памяти в одном экземпляре. Код в этом случае получается более компактным, хотя быстродействие несколько снижается за счет необходимости осуществления переходов. ПРОЦЕДУРЫ (ФУНКЦИИ) Процедура (подпрограмма) — это основная функциональная единица декомпозиции (разделения на несколько частей) некоторой задачи. Процедура представляет собой группу команд для решения конкретной подзадачи и обладает средствами получения управления из точки вызова задачи более высокого приоритета и возврата управления в эту точку. В простейшем случае программа может состоять из одной процедуры. Процедуру можно определить и как правильным образом оформленную совокупность команд, которая, будучи однократно описана, при необходимости может быть вызвана в любом месте программы. Функция – процедура, спопобная возвращать некоторое значение. Процедуры ценны тем, что могут быть активизированы в любом месте программы. Процедурам могут быть переданы некоторые аргументы, что позволяет, имея одну копию кода в памяти, изменять ее для каждого конкретного случая использования. Для описания последовательности команд в виде процедуры в языке ассемблера используются две директивы: PROC и ENDP. Синтаксис описания процедуры: имя_процедуры PROC [язык] [расстояние] команды, директивы; тело процедуры ; языка ассемблера [имя_процедуры] ENDP В заголовке процедуры (директиве PROC) обязательным является только задание имени процедуры. Атрибут [расстояние] может принимать значения near или far и характеризует возможность обращения к процедуре из другого сегмента кода. По умолчанию атрибут [расстояние] принимает значение near. Процедура может размещаться в любом месте программы, но так, чтобы на нее случайным образом не попало управление. Если процедуру просто вставить в общий поток команд, то микропроцессор будет воспринимать команды процедуры как часть этого потока и, соответственно, будет осуществлять выполнение команд процедуры. Учитывая это обстоятельство, есть следующие варианты размещения процедуры в программе: · в начале программы (до первой исполняемой команды); · в конце (после команды, возвращающей управление операционной системе); · промежуточный вариант — тело процедуры располагается внутри другой процедуры или основной программы; · в другом модуле. Размещение процедуры в начале сегмента кода предполагает, что последовательность команд, ограниченная парой директив PROC и ENDP, будет размещена до метки, обозначающей первую команду, с которой начинается выполнение программы. Эта метка должна быть указана как параметр директивы END, обозначающей конец программы: ... .code myproc proc near ret my_proc endp start proc call myproc ... start endp end start В этом фрагменте после загрузки программы в память управление будет передано первой команде процедуры с именем start. Объявление имени процедуры в программе равнозначно объявлению метки, поэтому директиву PROC в частном случае можно рассматривать как форму определения метки в программе. Размещение процедуры в конце программы предполагает, что последовательность команд, ограниченная директивами PROC и ENDP, будет размещена после команды, возвращающей управление операционной системе. Промежуточный вариант расположения тела процедуры предполагает ее размещение внутри другой процедуры или основной программы. В этом случае возможна необходимость предусмотреть обход тела процедуры, ограниченного директивами PROC и ENDP, с помощью команды безусловного перехода jmp: ... .code start proc jmp ml my_proc proc near ret myproc endp ml: ... start endp end start Последний вариант расположения описаний процедур — в отдельном сегменте кода — предполагает, что часто используемые процедуры выносятся в отдельный файл (модуль). Файл с процедурами должен быть оформлен как обычный исходный файл и подвергнут трансляции для получения объектного кода. Впоследствии этот объектный файл утилитой LINK можно объединить с файлом, где процедуры используются. Этот способ предполагает наличие в исходном тексте программы еще некоторых элементов, связанных с особенностями реализации концепции модульного программирования в языке ассемблера. Вариант расположения процедур в отдельном модуле используется также при построении Windows-приложений на основе выхова API-функций. Так как имя процедуры обладает теми же атрибутами, что и обычная метка в команде перехода, то обратиться к процедуре можно с помощью любой команды перехода. Но есть одно важное свойство, которое можно использовать благодаря специальному механизму вызова процедур. Суть состоит в возможности сохранения информации о контексте программы в точке вызова процедуры. Под контекстом понимается информация о состоянии программы в точке вызова процедуры. В системе команд микропроцессора есть две команды, осуществляющие работу с контекстом. Это команды call и ret: call имя_процедуры@num — вызов процедуры (подпрограммы). ret [число] — возврат управления вызывающей программе. [число] — необязательный параметр, обозначающий количество элементов, удаляемых из стека при возврате из процедуры. @num – количество байтов, которое занимают в стеке переданные аргументы для процедуры (параметр является особенностью использования компилятора MASM). Особого внимания заслуживает вопрос размещения процедуры в другом модуле. Так как отдельный модуль — это функционально автономный объект, то он ничего не должен, знать о внутреннем устройстве других модулей, и наоборот, другим модулям также ничего не известно о внутреннем устройстве данного модуля. Но каждый модуль должен иметь такие средства, с помощью которых он извещал бы транслятор о том, что некоторый объект (процедура, переменная) должен быть видимым вне этого модуля. И наоборот, нужно объяснить транслятору, что некоторый объект находится вне данного модуля. Это позволит транслятору правильно сформировать машинные команды, оставив некоторые их поля незаполненными. Позднее, на этапе компоновки, программа LINK или программа компоновки языка высокого уровня произведут настройку модулей и разрешат все внешние ссылки в объединяемых модулях. Для того чтобы объявить о видимых извне объектах, программа должна использовать две директивы MASM: extern и public. Директива extern предназначена для объявления некоторого имени внешним по отношению к данному модулю. Это имя в другом модуле должно быть объявлено в директиве public. Директива public предназначена для объявления некоторого имени, определенного в этом модуле и видимого в других модулях. Синтаксис этих директив следующий: extern имя:тип,..., имя:тип public имя,...,имя Здесь имя — идентификатор, определенный в другом модуле. В качестве идентификатора могут выступать: · имена переменных; · имена процедур; · имена констант. Тип определяет тип идентификатора. Указание типа необходимо для того, чтобы транслятор правильно сформировал соответствующую машинную команду. Действительные адреса будут вычислены на этапе редактирования, когда будут разрешаться внешние ссылки. Возможные значения типа определяются допустимыми типами объектов для этих директив: · если имя — это имя переменной, то тип может принимать значения byte, word, dword, qword и tbyte; · если имя — это имя процедуры, то тип может принимать значения near или far; в компиляторе MASM после имени процедуры необходимо указывать число байтов в стеке, которые занимают аргументы функции: extern p1@0:near · если имя — это имя константы, то тип должен быть abs. Пример использования директив extern и public для двух модулей
Исполняемый модуль находится в программе Модуль 1, поскольку содержит метку start, с которой начинается выполнение программы (эта метка указана после директивы end в программе Модуль 1). Программа вызывает процедуру p1, внешнюю, содержащуюся в файле Модуль 2. Процедура p1 не имеет аргументов, поэтому описывается в программе Модуль 1 с помощью директивы extern p1@0:near @0 – количество байт, переданных функции в качестве аргументов near – тип функции (для плоской модели памяти всегда имеет тип near). Вызов процедуры осуществляется командой call p1@0.
|
|||||||||||
|
|
Последнее изменение этой страницы: 2020-12-09; просмотров: 169; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 13.59.61.119 (0.089 с.) |